0344
Deep-learning based motion-compensated A-LIKNet for cardiac Cine MRI reconstruction1Medical Image and Data Analysis (MIDAS.lab), Department of Diagnostic and Interventional Radiology, University of Tuebingen, Tuebingen, Germany, 2School of computation, Information and Technology, Technical University of Munich, Munich, Germany, 3Department of Diagnostic and Interventional Radiology, University of Tuebingen, Tuebingen, Germany, 4Department of Computing, Imperial College London, London, United Kingdom, 5Klinikum Rechts der Isar, Technical University of Munich, Munich, Germany, 6Department of Radiology, Stanford University, Stanford, CA, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Cardiovascular, Motion-compensated reconstruction
Motivation: Cardiac Cine MRI is commonly used for assessing cardiac function. However, extended acquisition times may cause patient discomfort or can result in respiratory motion artifacts and slice misalignments due to multiple breath-holds.
Goal(s): We aim to accelerate data acquisition into a single breath-hold ($$$\sim$$$24×) with spatial-temporal sharing along the cardiac cycle for accurate morphological and functional reconstruction.
Approach: We integrated inter-frame motion field estimations with a deep learning-based reconstruction. The motion-compensated A-LIKNet was trained on 115 subjects and tested on 14 subjects.
Results: The proposed method reconstructs high-quality images, especially improving morphological accuracy, and thus enables cardiac Cine imaging in a single breath-hold.
Impact: The proposed deep learning-based motion-compensated A-LIKNet can efficiently reconstruct highly undersampled cardiac Cine MRI for up to 24× accelerated acquisitions of a single breath-hold. Results demonstrate higher morphological authenticity, sharper details, and reduced artifacts compared to other methods.
Introduction
Recently, many deep learning-based MRI reconstruction methods have been proposed1-6, significantly improving reconstruction speed and quality. These methods implicitly learn cardiac motion, focusing on reconstructing motion-resolved images without explicitly modeling cardiac or respiratory motion. Some methods have been proposed to jointly estimate motion and reconstruct images but with long inference times or limited achievable accelerations7,8. Additionally, the motion estimation in these methods relies on previously reconstructed images. Hence, inaccuracies in the reconstruction can further amplify errors in motion estimation.Our previous work proposed A-LIKNet9, which implicitly learns motion during the reconstruction by sharing low-rank, image, and k-space information with attention mechanisms. A-LIKNet achieved high-quality reconstruction of dynamic images, surpassing existing methods. However, we observed a decreased performance during the systolic cardiac phases. This can impair clinical diagnosis, such as ejection fraction calculations. We speculate that the following reasons cause these challenges:
1. During the systolic phase, the fast myocardial movement results in large inter-frame displacements. The implicit motion handling can not compensate for this fast expansion/contraction movement.
2. In a normal cardiac cycle, the diastolic phase is longer than the systolic phase, imbalancing the training data to implicitly learn the cardiac motion. Additionally, the in-house training cohort contains many patients with weakened myocardial contractility.
To address these challenges, we propose motion-compensated A-LIKNet (MC-A-LIKNet), aiming to improve reconstruction performance by leveraging motion information. The highlights are summarized as: (1) Self-supervised motion estimation10 avoids the dependence on reconstructed images. (2) We introduce motion fields from adjacent frames into the data consistency (DC) layer, enhancing available spatial-temporal information. Experiments demonstrate that MC-A-LIKNet exhibits superior performance regarding morphology, function and artifact removal, successfully addressing the issues observed in the systolic phases.
Methods
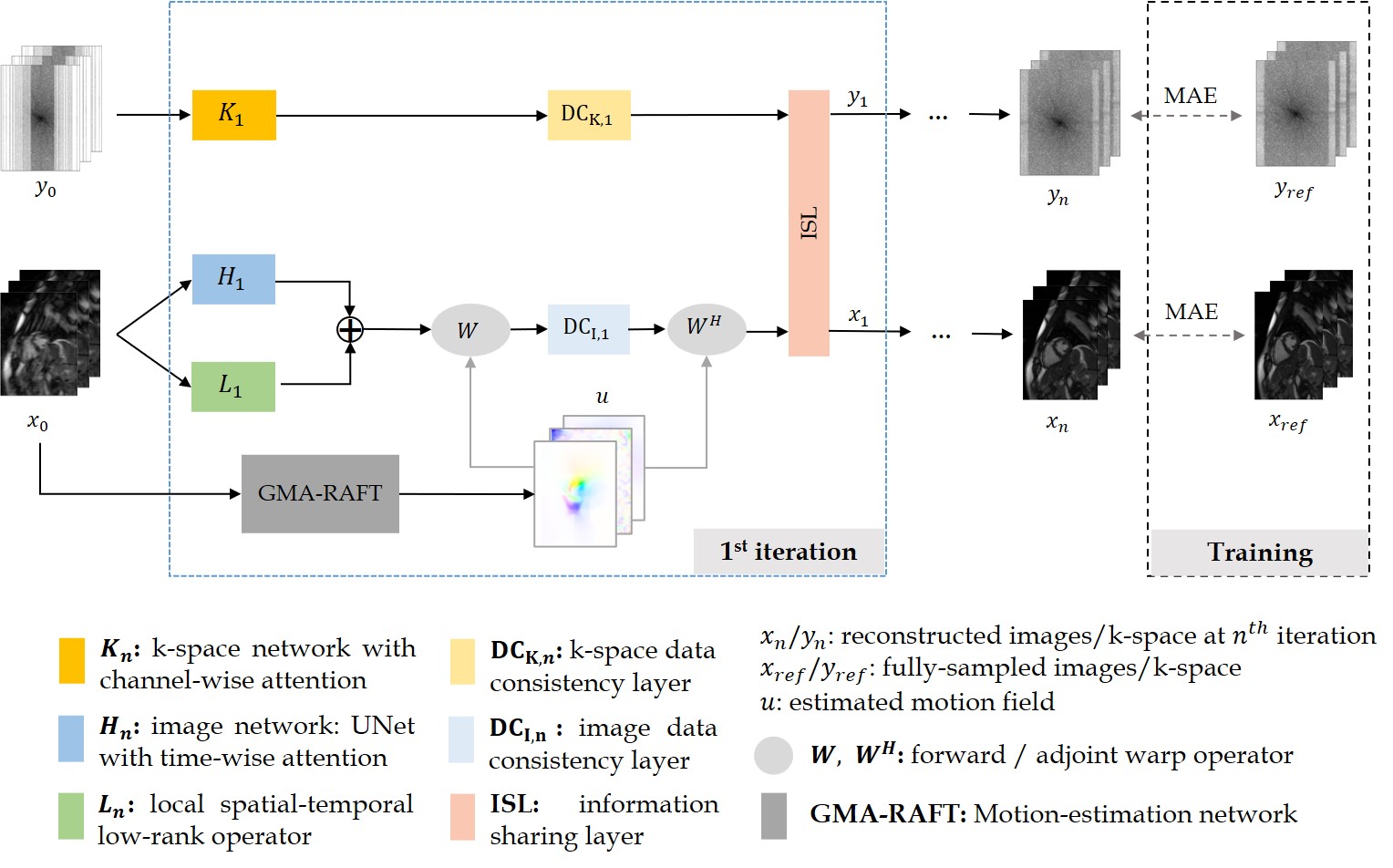
The proposed MC-A-LIKNet comprises two steps: (1) self-supervised motion estimation using our previous motion registration network10, and (2) motion-compensated reconstruction. The reconstruction framework is shown in Fig.1.To consider motion information, we incorporate the estimated motion field into the encoding operator in the DC layer of the image branch. Specifically, for cardiac phase tn, warping is performed using motion fields from neighboring ±n frames, resulting in 2n+1 warped images. These images are passed through a DC operator, which employs the conjugate gradient algorithm. Subsequently, the motion-compensated DC output is obtained through the adjoint warp operator.
Investigations are carried out on an in-house 2D cardiac Cine database acquired with a bSSFP sequence (TE/TR=1.06/2.12ms, α=52°, resolution=1.9×1.9mm2, slice thickness=8mm) on a 1.5T MRI. The dataset contains 129 subjects (38 healthy subjects and 91 patients). We split it into 115 training and 14 test subjects. Undersampling is implemented by VISTA11 with random accelerations between 2× to 24×. An Adam optimizer with a learning rate=10-4 and batch size=1 is used. We compare the proposed method to MoDL1 and L+S-Net6. In ablations, we compare MC-A-LIKNet to A-LIKNet9, which is the same architecture but without motion-compensation. All networks are unrolled 4 times, and motion fields from ±2 neighbouring frames are leveraged.
Results and Discussion
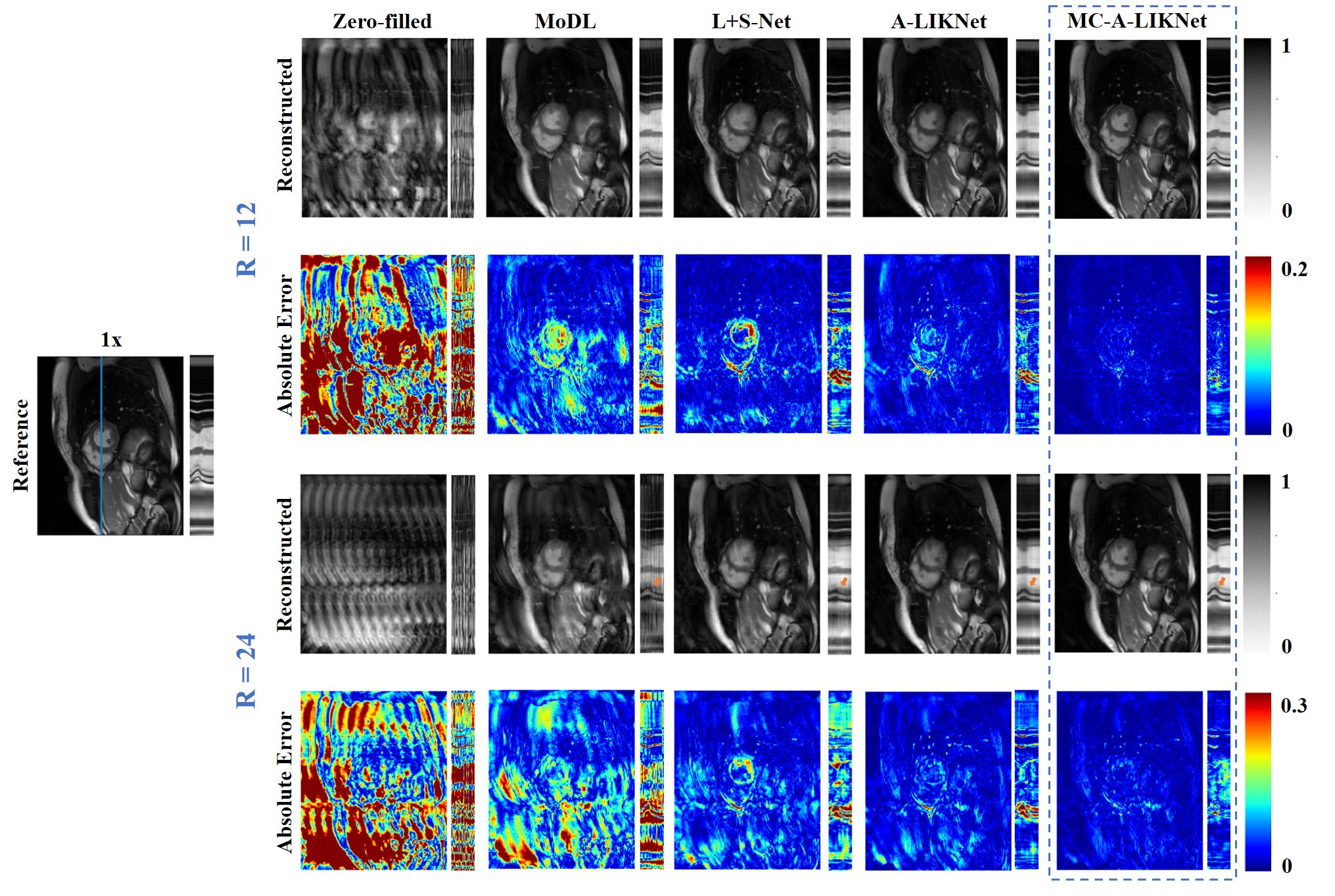
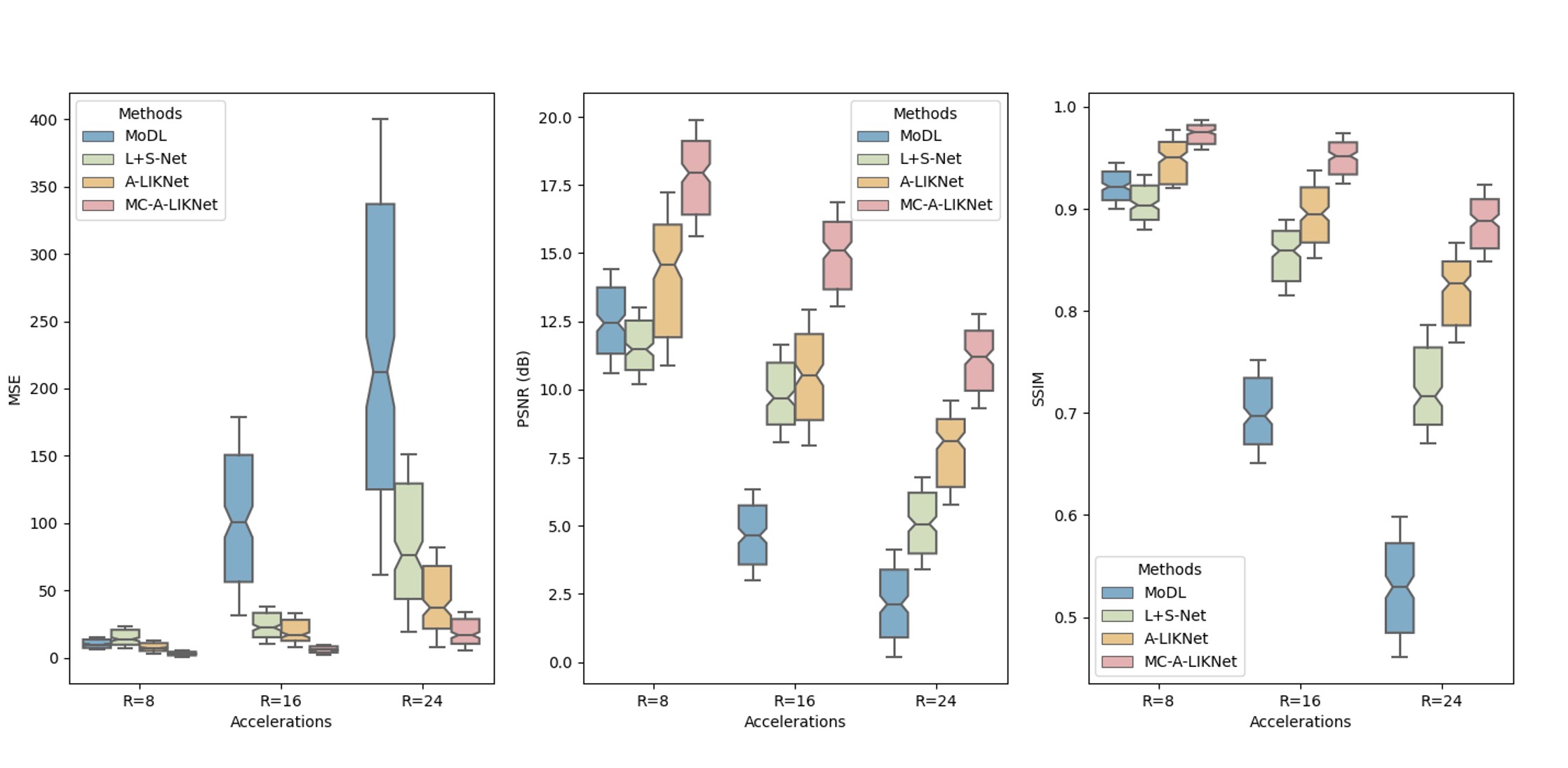
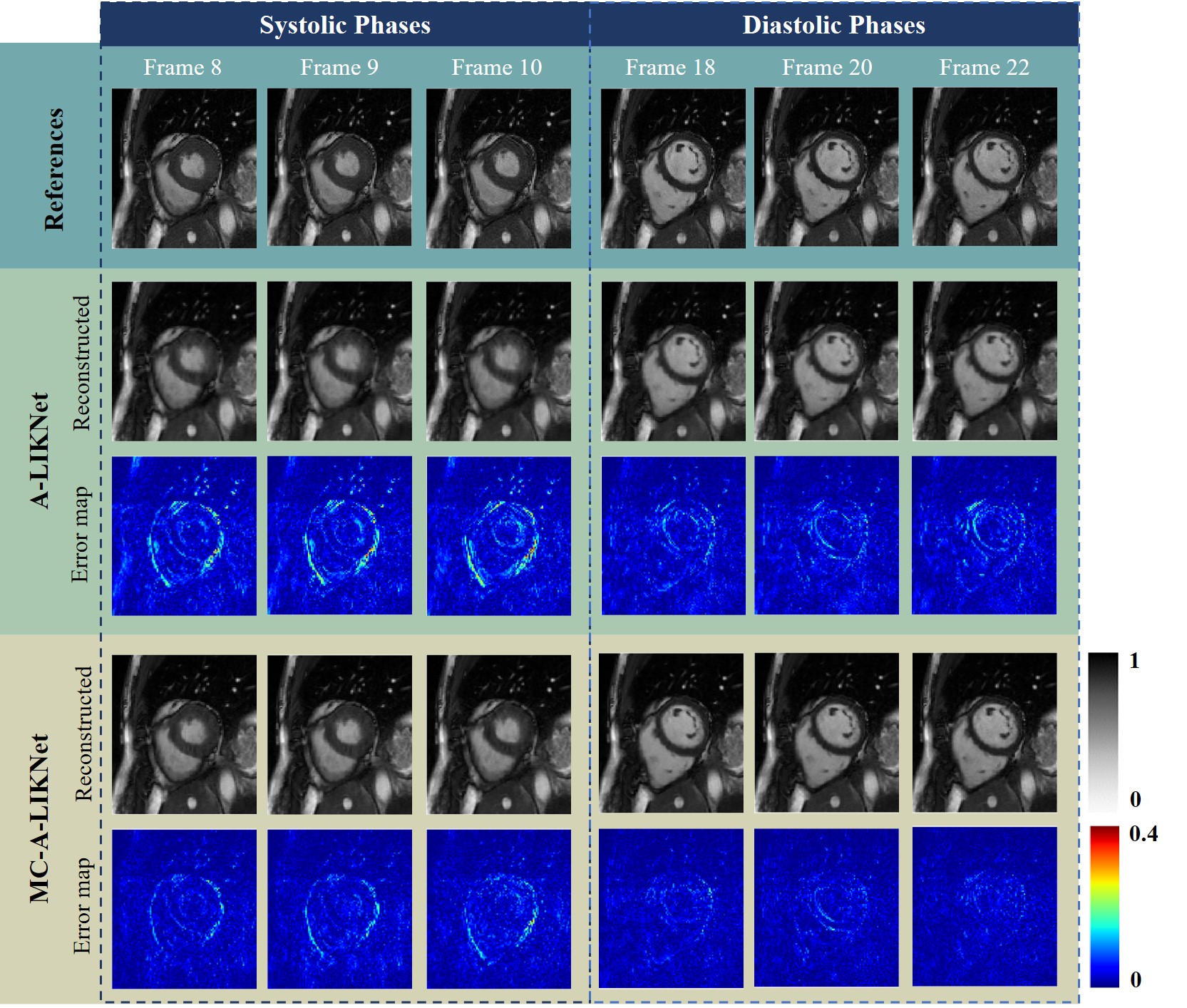
Reconstructions of a systolic frame for a patient with 12× and 24× retrospectively undersampling are shown in Fig.2, and reconstructions of different frames for a healthy subject with 16× retrospectively undersampling are shown in Fig.3. We observed that MC-A-LIKNet outperforms other methods with a more accurate depiction of myocardial morphology, improved and more homogeneous contrast in the cardiac regions, and reduced remaining aliasing artifacts throughout the cardiac cycle. As indicated by orange arrows in Fig.2, MC-A-LIKNet offers the most accurate dynamics throughout the cardiac cycle.The quantitative assessment (MSE, PSNR, SSIM) for all methods evaluated over all test subjects under 8×, 16×, 24× accelerations showed superior performance of MC-A-LIKNet in all metrics (Fig.4).
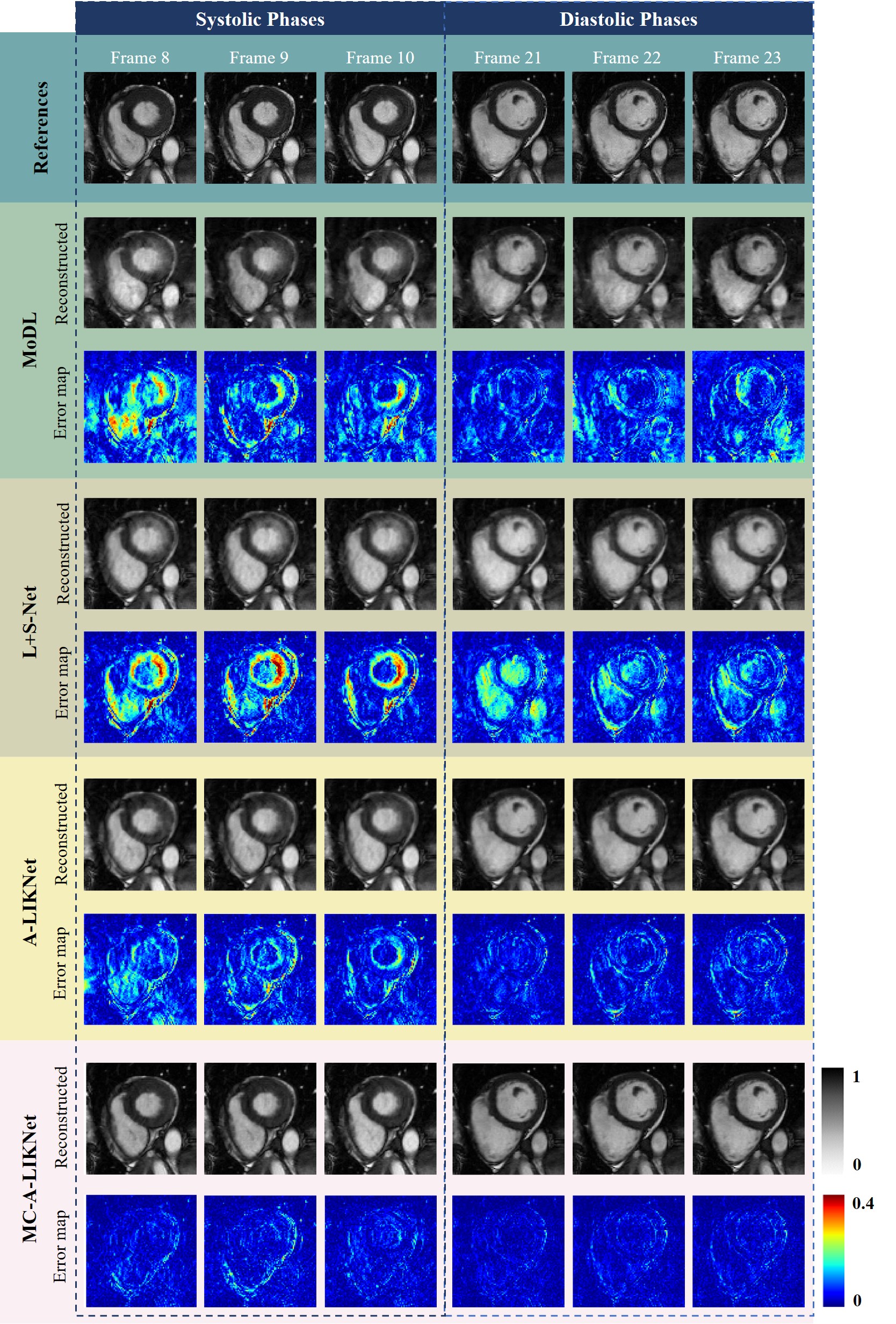
In the ablation study, we compared A-LIKNet and MC-A-LIKNet (Fig.5). We attempted to balance the dataset by reducing the diastolic frames, but this did not effectively resolve the decreased performance in systolic cardiac phase. However, with motion-compensation, MC-A-LIKNet delineates the myocardium morphology more accurately, especially in the systolic phases, which is vital for clinical ejection fraction calculations. Additionally, MC-A-LIKNet performs better in removing artifacts and reconstructing sharper details in both phases.
We acknowledge the limitations that we focused on retrospective undersampling and did not involve cardiac function assessment. In the future, we plan to collect prospectively undersampled data for reconstruction and assessment.
Conclusion
This paper proposed motion-compensated A-LIKNet which builds upon our previous work for cardiac Cine MRI reconstruction. By incorporating motion fields into the data consistency layer, it provides inter-frame displacement information. MC-A-LIKNet efficiently addresses the challenges in reconstructing systolic phases. It effectively reconstructs 2D cardiac Cine under high accelerations that will enable single breath-hold imaging.Acknowledgements
No acknowledgement found.References
1. H. Aggarwal et al., "MoDL: Model-Based Deep Learning Architecture for Inverse Problems", IEEE Trans Med Imaging, 2019, 38(2), 394-405.
2. J. Schlemper et al., "A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction", IEEE Trans Med Imaging, 2018, 37(2), 491-503.
3. A. Hauptmann et al., "Real-time cardiovascular MR with spatio-temporal artifact suppression using deep learning–proof of concept in congenital heart disease", Magn Reson Med, 2019, 81, 1143-56.
4. K. Hammernik et al., "Dynamic multicoil reconstruction using variational networks", Proc. ISMRM 27th Annu. Meeting Exhibit, 2019, 4656.
5. T. Küstner et al., "CINENet: deep learning-based 3D cardiac CINE MRI reconstruction with multi-coil complex-valued 4D spatio-temporal convolutions", Sci Rep, 2020, 10(1), 13710.
6. W. Huang et al., "Deep low-Rank plus sparse network for dynamic MR imaging", Med Image Anal., 2021, 73, 102190.
7. J. Pan et al., "Learning-based and unrolled motion-compensated reconstruction for cardiac mr cine imaging", International Conference on Medical Image Computing and Computer-Assisted Intervention, 2022, 686-96.
8. G. Cruz et al., "Single-heartbeat cardiac cine imaging via jointly regularized nonrigid motion-corrected reconstruction", NMR in Biomedicine, 2023, e4942.
9. S. Xu et al., "Attention mechanisms for sharing low-rank, image and k-space information during MR image reconstruction", Proc. ISMRM Annu. Meeting Exhibit, 2023.
10. A. Ghoul et al., "Attention-guided network for image registration of accelerated cardiac CINE", Proc. ISMRM Annu. Meeting Exhibit, 2023.
11. R. Ahmad et al., "Variable density incoherent spatiotemporal acquisition (VISTA) for highly accelerated cardiac MRI", Magn Reson Med, 2015, 74(5), 1266-78.
Figures