0038
Multi-scale plug-and-play energy framework for inverse problems1University of Iowa, Iowa city, IA, United States
Synopsis
Keywords: Image Reconstruction, Data Processing
Motivation: Unrolled algorithms provide high quality image reconstruction. However, their training is memory-intensive and is sensitive to forward model mismatches.
Goal(s): To develop a memory-efficient plug-and-play algorithm, whose performance is comparable to unrolled algorithms and can be used with arbitrary forward models.
Approach: We propose a memory-efficient energy-based multi-scale framework. We model the negative log prior with different smoothnesses using Convolutional Neural Networks (CNN). This approach enables us to relax the constraints on the CNN, while the multi-scale strategy improves the convergence to the global minimum.
Results: The enhancements improves performance, making it comparable to end-to-end methods, while being robust to model mismatch.
Impact: The proposed framework is memory-efficient compared to unrolled algorithms, paving the way for its usage in large-dimensional inverse problems. Its flexibility enables recovery of images with arbitrary forward operators.
Introduction
Unrolled algorithms[1], which train Convolutional Neural Network (CNN) blocks in an End-to-End (E2E) fashion, offer state-of-the-art performance in MR image recovery. Unfortunately, it is challenging to use these methods for 3D and higher dimensional applications because the unrolling strategy makes the training procedure memory intensive. In addition, the learned model is vulnerable to mismatches in the forward model. We introduce a Multi-Scale Energy (MuSE) Plug-and-Play framework to overcome these challenges. Similar to Plug-and-Play[2] (PnP) methods, the proposed approach is memory-efficient and can be used with arbitrary forward models. The main distinction of this approach from PnP methods is the energy-based formulation, which eliminates the contraction constraint on the CNN that is needed by current PnP models for convergence. The relaxation is expected to improve performance. In addition, we rely on a multi-scale strategy to improve the convergence to global minimum that further improves performance and makes them comparable with E2E methods.Proposed Method
Plug-and-Play Energy Model:We model the prior $$$p(\mathbf{x})$$$ of the MR images $$$\mathbf{x}\in\mathbb{C}^{m}$$$ as:
$$ p_{\theta}(\mathbf{x})=\dfrac{1}{\mathbf{Z}_\theta}\exp\left(-\boldsymbol E_{\boldsymbol{\theta}}(\mathbf{x})\right)\hspace{20mm}(1)$$ where the energy $$$\boldsymbol {E}_{\boldsymbol{\theta}}(\mathbf{x}):\mathbb{C}^{m}\rightarrow\mathbb{R}$$$ and $$$\mathbf{Z}_\boldsymbol\theta$$$ is the normalization constant. We represent $$$E_\boldsymbol\theta(\mathbf x) =\dfrac{\|\mathbf{x}-\psi_\boldsymbol\theta(\mathbf{x})\|^{2}}{2\sigma^2}$$$ and model $$$\psi_\boldsymbol\theta(\mathbf{x}):\mathbb{C}^{m}\rightarrow\mathbb{C}^{m}$$$ using a CNN. The gradient of the energy is equal to $$$\nabla_{\mathbf{x}} \log p_{\theta}({\mathbf{x}})$$$ and is referred to as the score. In our setting, the score denoted by $$$H_\boldsymbol\theta(\mathbf{x}):\mathbb{C}^{m}\rightarrow\mathbb{C}^{m}$$$ is the gradient of the energy and therefore, a conservative vector field. We illustrate the computation of energy and score in Fig. 1.
Learning the energy:
We learn the parameters of the energy using Denoising Score Matching[3] (DSM), which minimizes the Fisher divergence between scores of the proposed and the smoothed distribution $$$p_{\sigma}(\tilde{\mathbf{x}})$$$:
$$\begin{equation}L_{\sigma}(\boldsymbol\theta)=\mathbb E_{p_{\sigma}(\tilde{\mathbf{x}})}\|\nabla_{\tilde{\mathbf{x}}} \log p_{\theta}(\tilde{\mathbf{x}}) - \nabla_{ \tilde{\mathbf{x}}} \log p_\sigma(\tilde{\mathbf{x}})\|^2\end{equation}\hspace{20mm}(2)$$
where $$$\begin{equation}p_{\sigma}(\tilde{\mathbf{x}}) = p(\mathbf{x})\ast{N}(0,\sigma^{2}\mathbf{I})\end{equation}$$$ or equivalently $$$\tilde{\mathbf{x}}=\mathbf{x}+\sigma\mathbf{z}$$$ where $$$\mathbf{z}$$$ is drawn from a unit Normal distribution. Note that, $$$p_{\sigma}(\tilde{\mathbf{x}}) \rightarrow p(\mathbf{x})$$$ as $$$\sigma \rightarrow 0$$$. The minimization of the cost function in (2) is equivalent to solving[3]:
$$\begin{eqnarray}\nonumber \boldsymbol\theta^{*} &=& \arg \min_{\boldsymbol\theta} \mathbb E_{p_{\sigma}(\tilde{\mathbf{x}})}\left\|-H_\theta (\mathbf{x}+\sigma \mathbf{z}) + \underbrace{\sigma \mathbf{z}}_{\mathbf{n}} \right\|^2 \end{eqnarray}\hspace{20mm}(3)$$
Problem formulation and optimization:
Once the energy parameters are learned, the MR image is recovered from its noisy under-sampled measurements $$$\mathbf{b}\in\mathbb{C}^{n}$$$ by solving the following non-convex problem:
$$\begin{equation} \mathbf{x}^* = \arg \min_\mathbf{x} \dfrac{1}{2\eta^{2}} \|\mathbf{A}\mathbf{x}-\mathbf{b}\|_{2}^2 + \dfrac{ \|\mathbf{x}-\psi_\boldsymbol\theta(\mathbf{x})\|^{2}}{2\sigma^2}\end{equation}\hspace{45mm}(4)$$
where $$$\mathbf{A}\in\mathbb{C}^{n \times m}$$$ is a known linear operator. The Gradient Descent (GD) or the Majorization Minimization (MM) framework with the update rule as shown in (5) and (6), respectively can be used to arrive at a local minimum of (4):
$$ \begin{equation} \begin{array}{ll} \mathbf{x}_{n+1}= \mathbf{x}_{n}- \gamma\left(\dfrac{\mathbf{A}^{H}(\mathbf{A}\mathbf{x}_{n}-\mathbf{b})}{\eta^{2}} + \dfrac{H_\boldsymbol{\theta}(\mathbf{x}_{n})}{\sigma^{2}}\right) \end{array}\end{equation}\hspace{45mm}(5)$$
$$\begin{equation} \mathbf{x}_{n+1} = \left(\dfrac{\mathbf{A}^{H}\mathbf{A}}{\eta^{2}}+\dfrac{L}{\sigma^{2}}\mathbf{I}\right)^{-1}\left(\dfrac{\mathbf{A}^{H}\mathbf{b}}{\eta^{2}} + \dfrac{L \mathbf{x}_{n} - \boldsymbol H_{\theta}( \mathbf{x}_{n})}{\sigma^{2}}\right)\end{equation} \hspace{25mm}(6) $$
where the step-size $$$\begin{equation} \gamma = \dfrac{1}{\dfrac{1}{\eta^{2}}+\dfrac{L}{\sigma^2}}\end{equation}$$$ and $$$L$$$ is the Lipschitz constant of the energy $$$\boldsymbol {E}_{\boldsymbol{\theta}}(\mathbf{x})$$$.
To encourage the convergence to the global minimum, we use a continuation strategy. We consider a sequence of smooth approximations of the true energy, parameterized by the scale $$$\sigma$$$. We start with a coarse scale and gradually reduce $$$\sigma$$$. The solution at each scale is obtained using either GD or MM algorithm. The solution at a specific scale is used as initialization for the subsequent finer scale.
Results
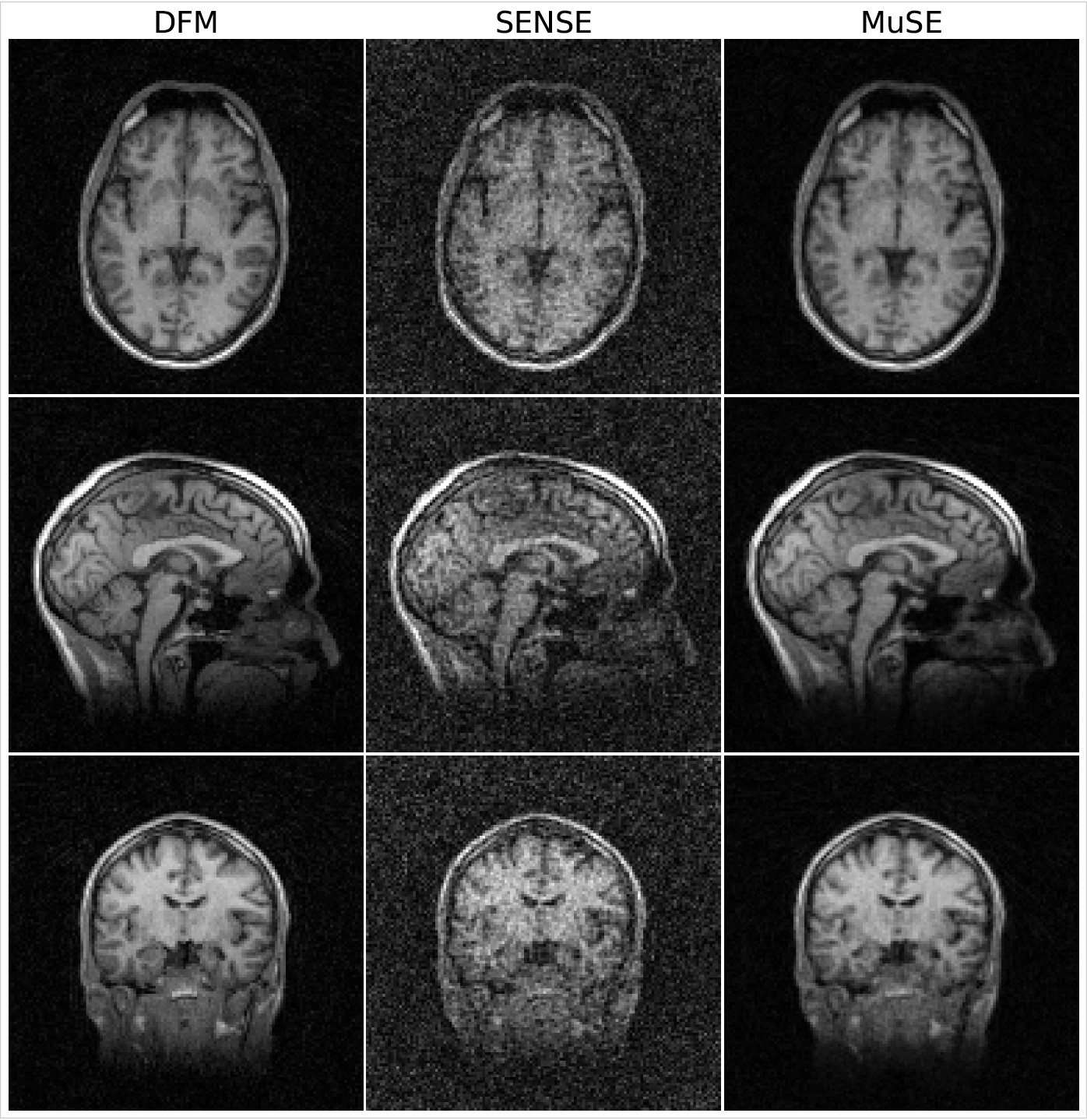
We compare MuSE with PnP-Energy at single scale (E-SS) using update rule (6), E2E-MoDL, and PnP-ISTA[4] on fastMRI[5] knee dataset using 1D nonuniform variable-density undersampling with different acceleration factors. The reconstruction results are shown in Fig. 2. We observe that MuSE and E2E-MoDL have comparable reconstruction performance, while the memory demand of MuSE is 10x smaller. The lower performance of PnP-ISTA is because of the contraction constraint. We demonstrate the sensitivity of E2E-MoDL to mismatches in the forward model in Fig. 3. The proposed PnP-energy approach can be used with arbitrary forward models.We study the preliminary utility of MuSE in a 3D application in Fig. 4, where we recover a 3D volume from MPnRAGE[6] Look-Locker acquisition. The model was trained using reconstructions from an unsupervised deep factor model (DFM)[7] as reference; DFM jointly recovers the images corresponding to all inversion times and is computationally expensive. In this work, we consider the recovery of a single inversion-time of $$$966.24$$$ ms. Fig. 4 shows the comparison of MuSE with SENSE[8] and DFM. The experiment shows the feasibility of using MuSE for a 3D application, where it offers improved performance over SENSE.
Conclusions
We proposed MuSE, a PnP multi-scale energy framework whose negative log-prior was modeled using a CNN. MuSE offers comparable performance to that of the E2E-trained model. Unlike the E2E models, MuSE inherits the desirable features of PnP, including flexibility and memory efficiency.Acknowledgements
This work is supported by NIH R01AG067078.References
1. H. K. Aggarwal, M. P. Mani, and M. Jacob, “Modl: Model-based deep learning architecture for inverse problems,” IEEE transactions on medical imaging, vol. 38, no. 2, pp. 394–405, 2018
2. R. Ahmad, C. A. Bouman, G. T. Buzzard et al., “Plug-and-play methods for magnetic resonance imaging: Using denoisers for image recovery,” IEEE signal processing magazine, vol. 37, no. 1, pp. 105–116, 2020.
3. P. Vincent, “A connection between score matching and denoising autoencoders,” Neural computation, vol. 23, no. 7, pp. 1661–1674, 2011.
4. E. Ryu, J. Liu, S. Wang et al., “Plug-and-play methods provably converge with properly trained denoisers,” in International Conference on Machine Learning, 2019.
5. J. Zbontar, F. Knoll, A. Sriram et al., “Fastmri: An open dataset and benchmarks for accelerated MRI,” arXiv preprint arXiv:1811.08839, 2018.
6. S. Kecskemeti et al., "MPnRAGE: A technique to simultaneously acquire hundreds of differently contrasted MPRAGE images with applications to quantitative T1 mapping," Magnetic resonance in medicine, 75(3), pp.1040-1053, 2016.
7. Chen et al., "Deep Factor Model: A Novel Approach for Motion Compensated Multi-Dimensional MRI," arXiv preprint arXiv:2304.00102, 2023.
8. P. Pruessmann et al., “Sense: sensitivity encoding for fast mri,” Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine, vol. 42, no. 5, pp. 952–962, 1999.
Figures
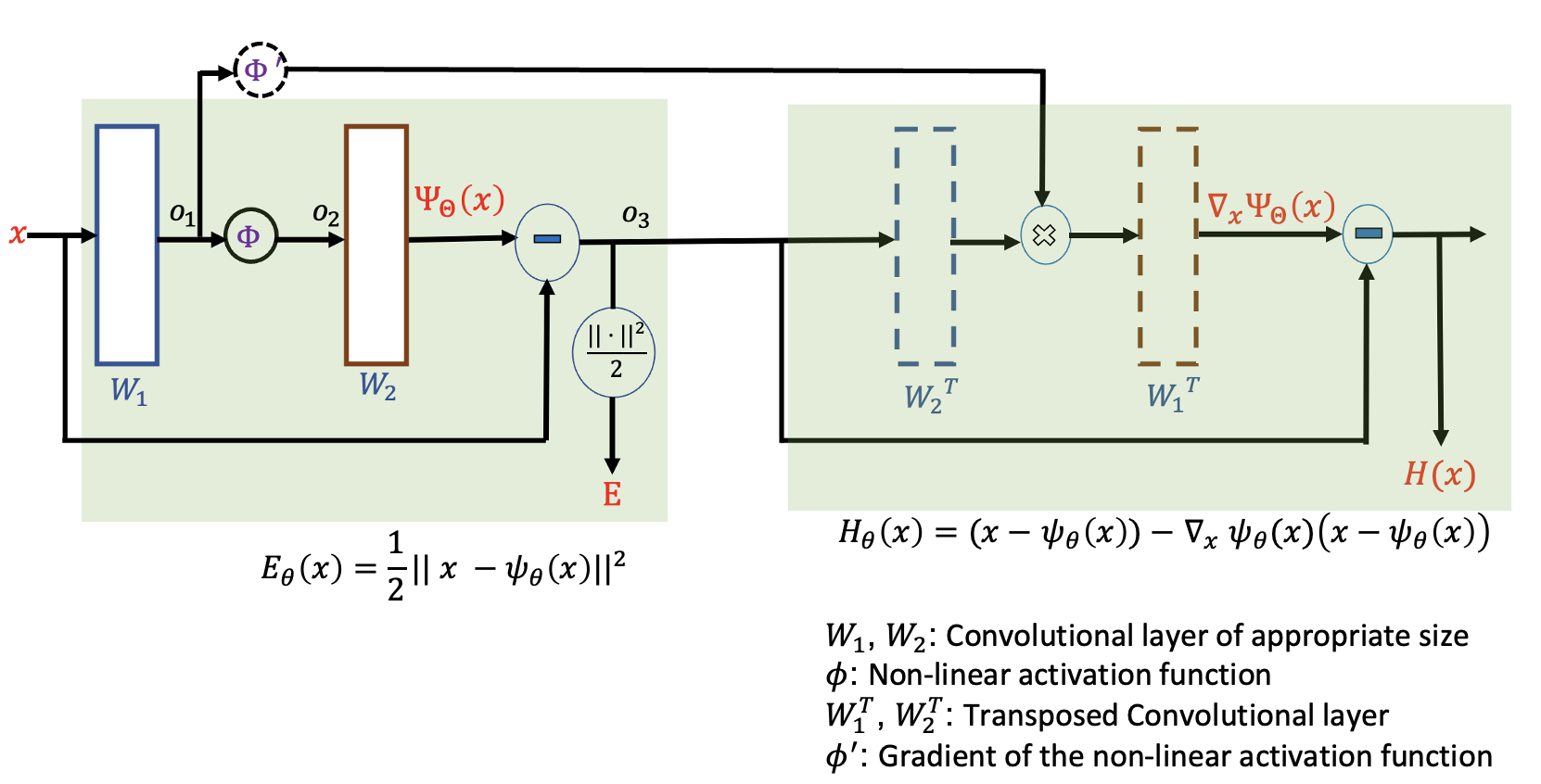
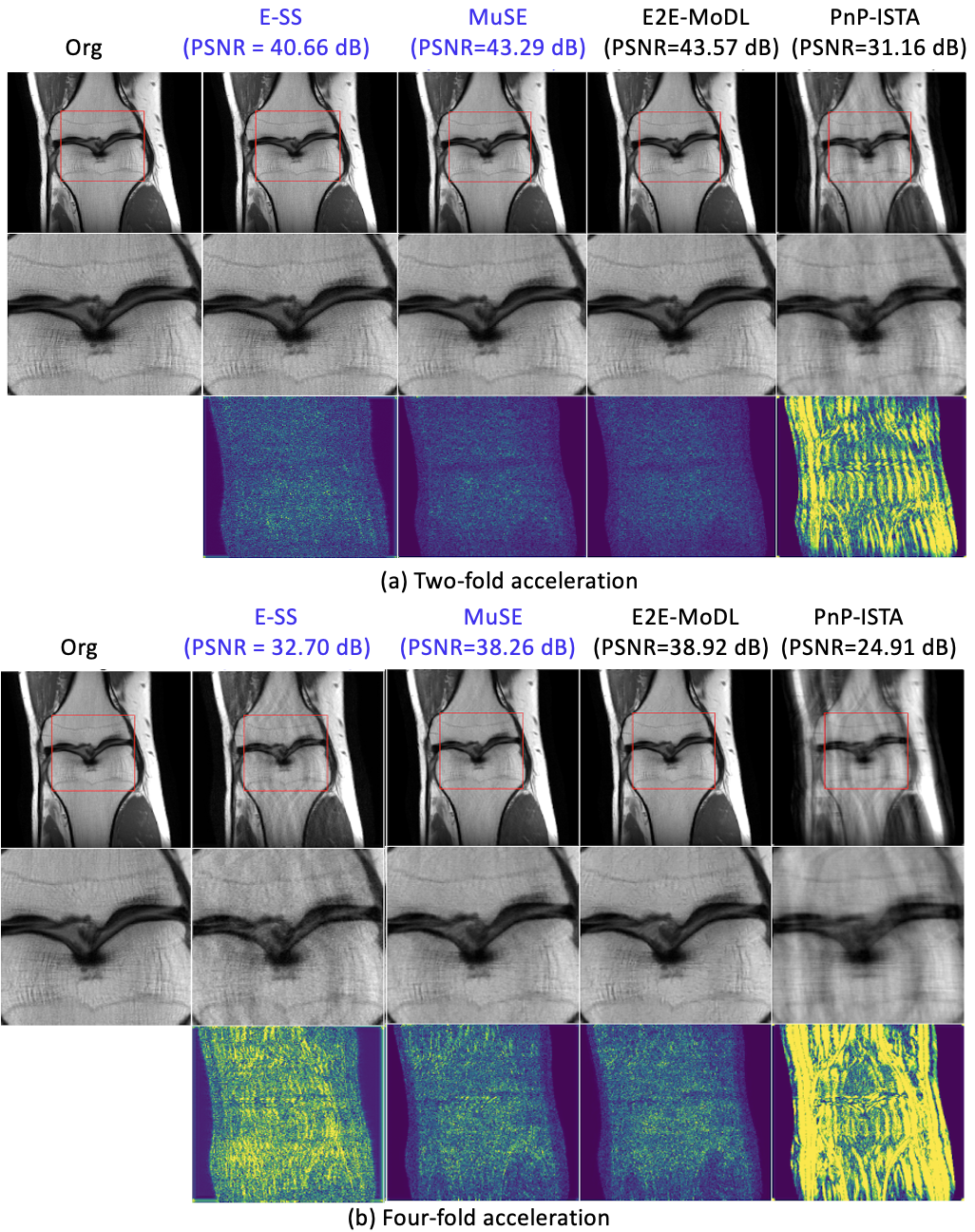
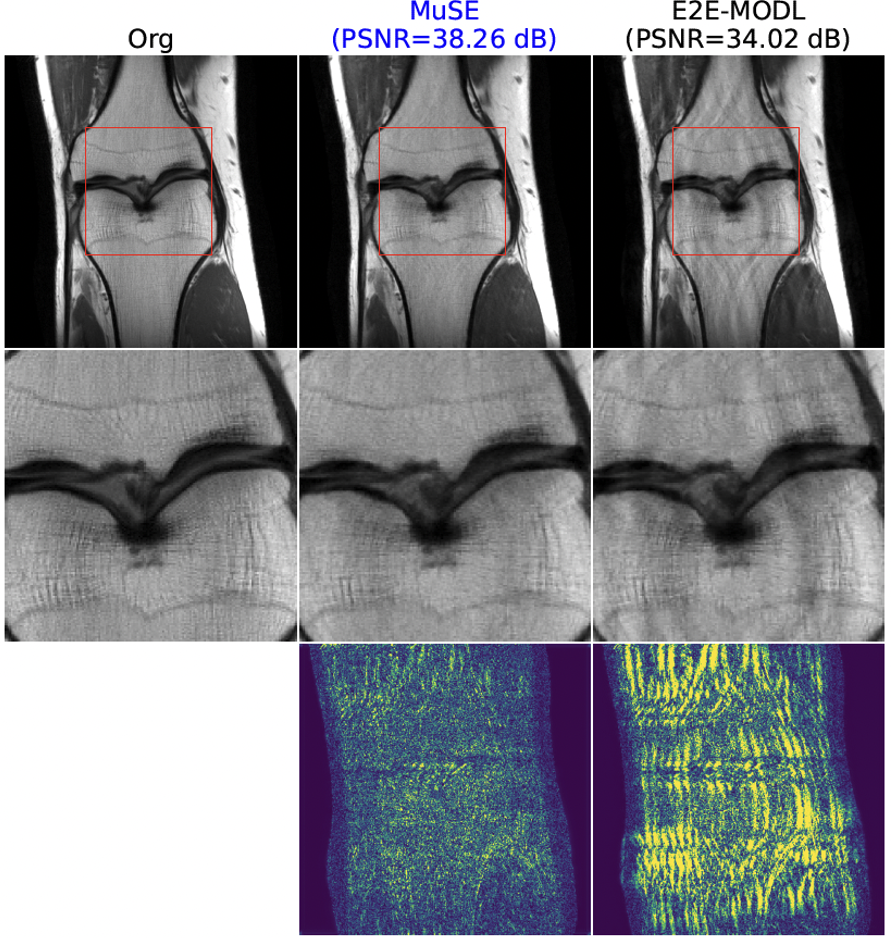
Figure 3: Insensitivity of MuSE to forward models. We compare E2E-MoDL network trained on two-fold undersampling and tested on four-fold data. The changes in the $$$A$$$ operator result in a drop in the performance of E2E-MoDL compared to MuSE, whose energy network is agnostic to the forward operator. The ability of MuSE to be used with arbitrary forward models makes it attractive compared to unrolled algorithms that need to be trained for different settings.