0012
A self-supervised feature learning strategy for training reconstruction networks on undersampled data in cardiac Cine MRI1Medical Image and Data Analysis (MIDAS.lab), Department of Diagnostic and Interventional Radiology, University of Tuebingen, Tuebingen, Germany, 2School of computation, Information and Technology, Technical University of Munich, Munich, Germany, 3Department of Computing, Imperial College London, London, United Kingdom, 4Klinikum Rechts der Isar, Technical University of Munich, Munich, Germany, 5Department of Radiology, Stanford University, Stanford, CA, United States
Synopsis
Keywords: AI/ML Image Reconstruction, Cardiovascular, Self-Supervised learning, Feature learning
Motivation: Most existing deep learning-based MR image reconstruction methods are supervised learning, relying on fully-sampled images, which is challenging to acquire in practice.
Goal(s): We aim to leverage undersampled data in a self-supervised reconstruction framework to enhance expressibility and model performance.
Approach: We use information maximization methods to learn sampling-invariant features from undersampled images and incorporate them in a self-supervised reconstruction network.
Results: The proposed method can learn sampling-invariant features from undersampled data, which enhance the reconstruction performance, enabling self-supervised MR image reconstruction for up to 16× undersampling.
Impact: The proposed self-supervised feature learning strategy can extract sampling-invariant features from undersampled images, effectively assisting the reconstruction of undersampled cardiac cine MR imaging without requiring fully-sampled images. This feature learning strategy may also be advantageous for other downstream tasks.
Introduction
Cardiac Cine MRI is crucial for assessing cardiac function but requires long acquisition times. Recently, deep learning-based MR image reconstruction methods have improved reconstruction speed and quality but most are supervised learning1-11, relying on high-quality fully-sampled images, which can be impractical. Besides, variations between individuals and accelerations can lead to unstable performance.This motivates us to explore self-supervised feature learning, which can be categorized into contrastive learning12,13 and information maximization methods14,15. While some methods16,17 have incorporated contrastive loss as an additional regularization loss in MR image reconstruction, they lack a dedicated feature learning network for explicitly capturing data structure. Moreover, contrastive learning demands many dissimilar samples within each batch, posing computational challenges for dynamic MR images.
This work proposes a self-supervised feature learning strategy for training reconstruction networks on undersampled images in cardiac Cine MRI. The core concept involves: (1) self-supervised feature learning using information maximization methods15, and (2) incorporating learned features in a self-supervised reconstruction network. Results demonstrate that the proposed method can effectively extract sampling-invariant features from undersampled dataset, which in turn enhances the reconstruction performance. The proposed method surpasses other self-supervised reconstruction methods16,18, achieving results on par with supervised learning.
Methods
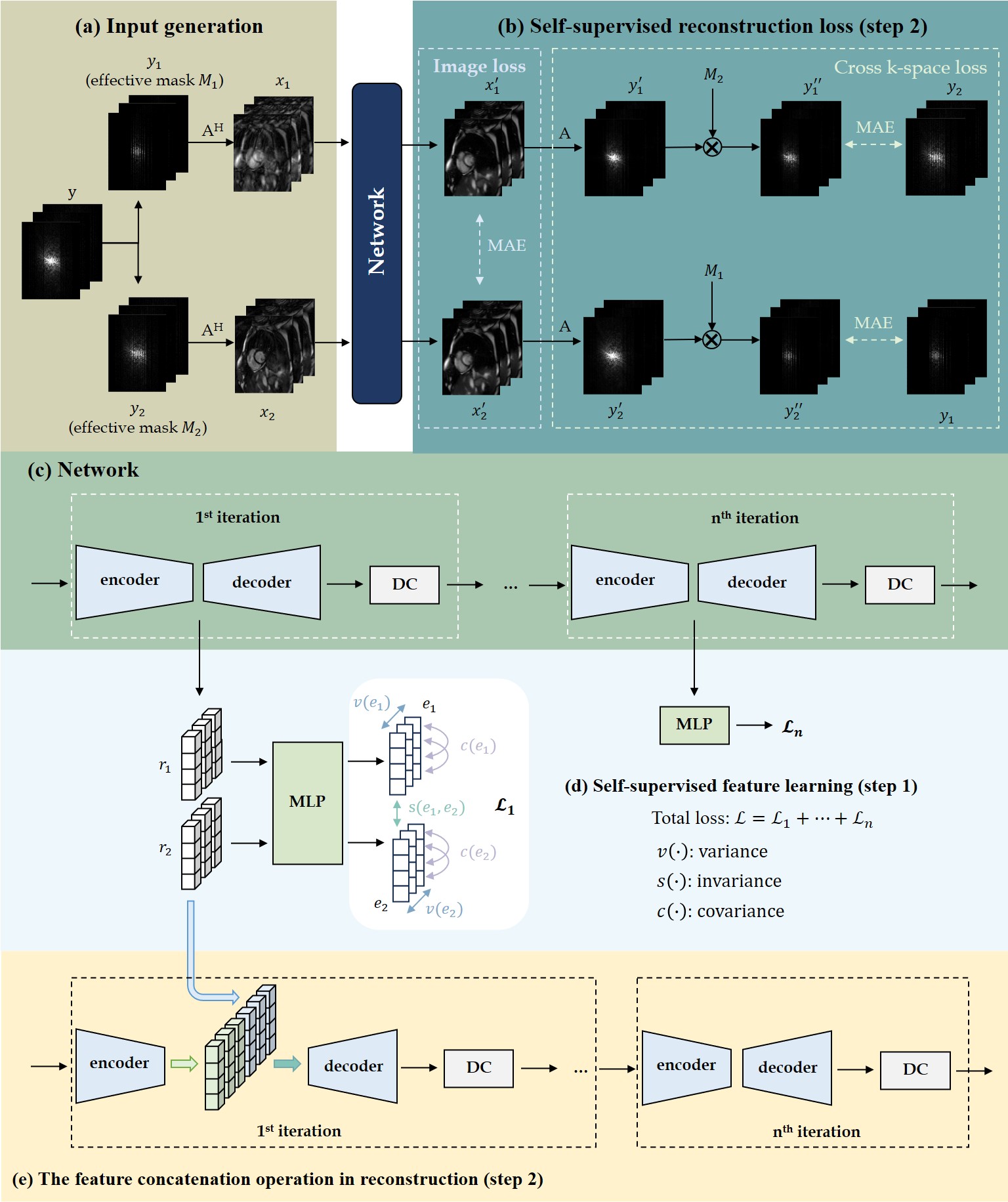
The proposed method has two steps: (1) Self-supervised feature learning, (2) Self-supervised reconstruction.Self-supervised feature learning
Given an image, we augment it using two random sampling masks to create two undersampled images. The common and similar features inherent in these images represent the latent sampling-invariant and subject-specific embeddings.
To learn features at different noise levels consistent with the subsequent reconstruction network, we deploy the same unrolled network architecture in both steps (Fig.1(c)). In each iteration, an encoder generates representations r1 and r2 of two inputs, projected by an MLP into an embedding space e1 and e2 for loss calculation (Fig.1(d)), which follows variance-invariance-covariance regularization(VICReg)15:
$$\mathfrak{L}_{i} = \lambda s \left ( e_{1}, e_{2} \right ) + \mu \left [ v\left ( e_{1} \right ) + v\left ( e_{2} \right ) \right ] + \nu \left [ c\left ( e_{1} \right ) + c\left ( e_{2} \right ) \right]$$
The invariance s(·) encourages two embeddings to be close, the variance v(·) enforces the distribution of embeddings to prevent information collapse, and the covariance c(·) decorrelates features in different dimensions to ensure richer features. After training, all MLPs are discarded, and the encoder-extracted representations are used for reconstruction.
Self-supervised reconstruction
To demonstrate the effectiveness of the learned features, we employ them in the reconstruction network. As shown in Fig.1(a), two undersampled images are obtained by re-undersampling the accelerated k-space with distinct masks. To aid reconstruction, input images undergo the pre-trained feature extraction network, and extracted features are concatenated with the reconstruction network's features in the bottleneck (Fig.1(e)). We hypothesize that this feature concatenation provides a good initialization and alleviates the interference of artifacts caused by high undersampling rates. The loss calculation (Fig.1(b)) follows our previous work19, consisting of image consistency loss and cross k-space loss.
In-house 2D cardiac Cine dataset were acquired on a 1.5T MRI (TE/TR=1.06/2.12ms, flip angle=52°, bandwidth=915Hz/px, spatial resolution=1.9×1.9mm2, slice thickness=8mm, cardiac phases=25, GRAPPA 2×). We used VISTA undersampling20 with random acceleration between 2$$$\sim$$$16× for both steps. However, as the initial image being 2× undersampled, the effective acceleration for reconstruction ranges from 2$$$\sim$$$28×.
We compared the proposed framework to a supervised learning and other self-supervised methods: SSDU18 and PARCEL16. Ablation experiments were performed using the same network without pre-trained feature assistance. For a fair comparison, we maintain uniformity in the network (iterations=3) and sampling strategy for all comparisons.
Results and Discussion
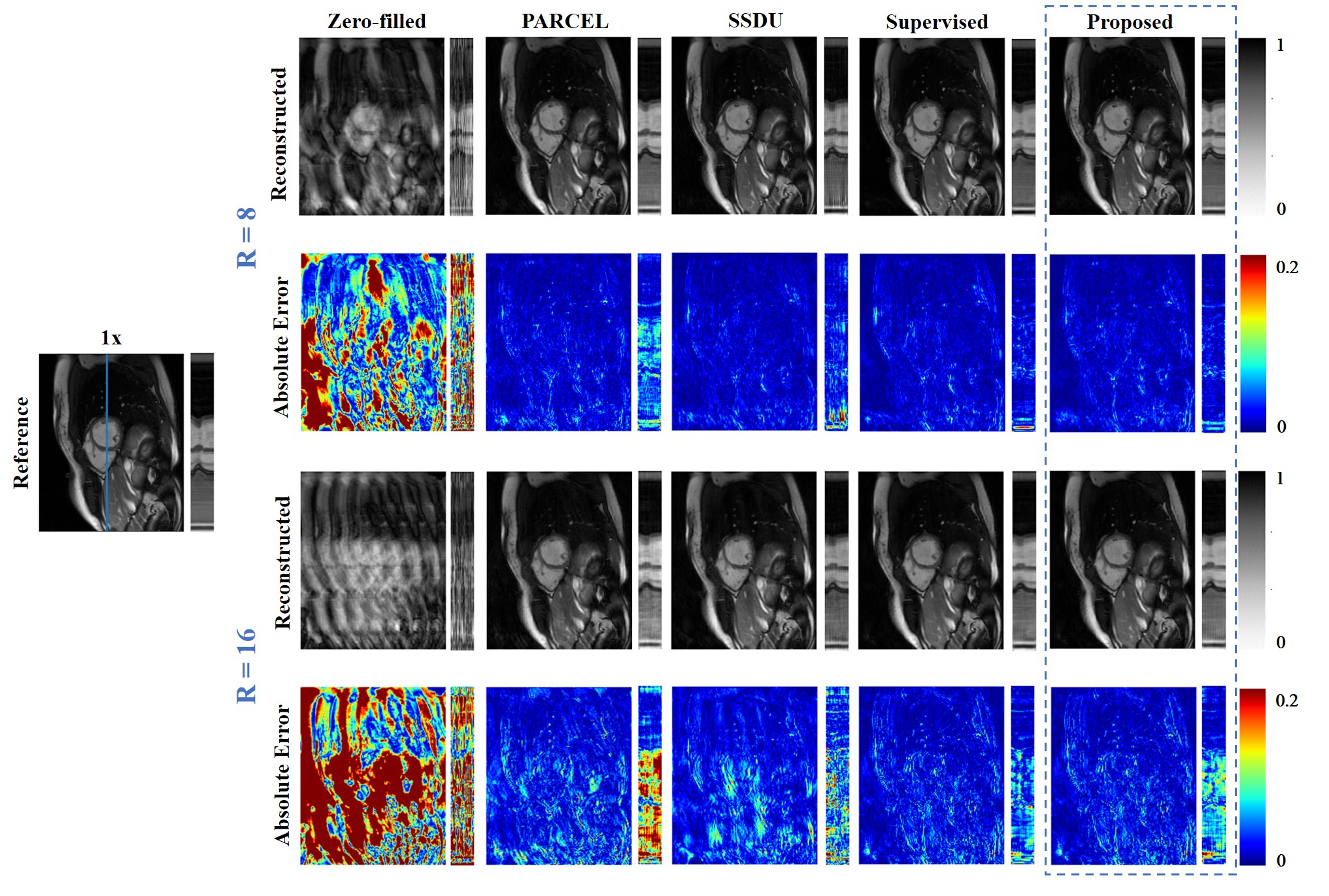
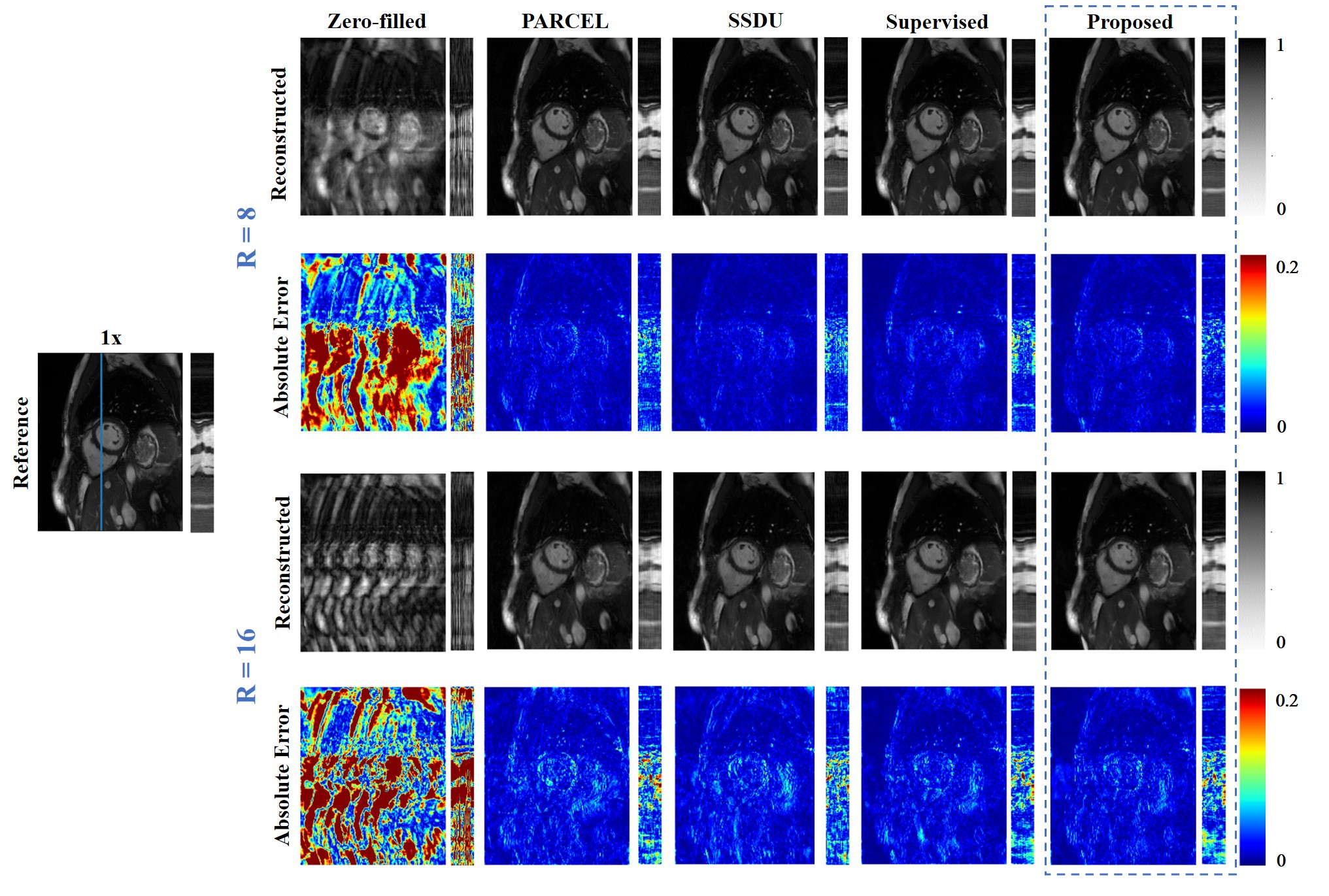
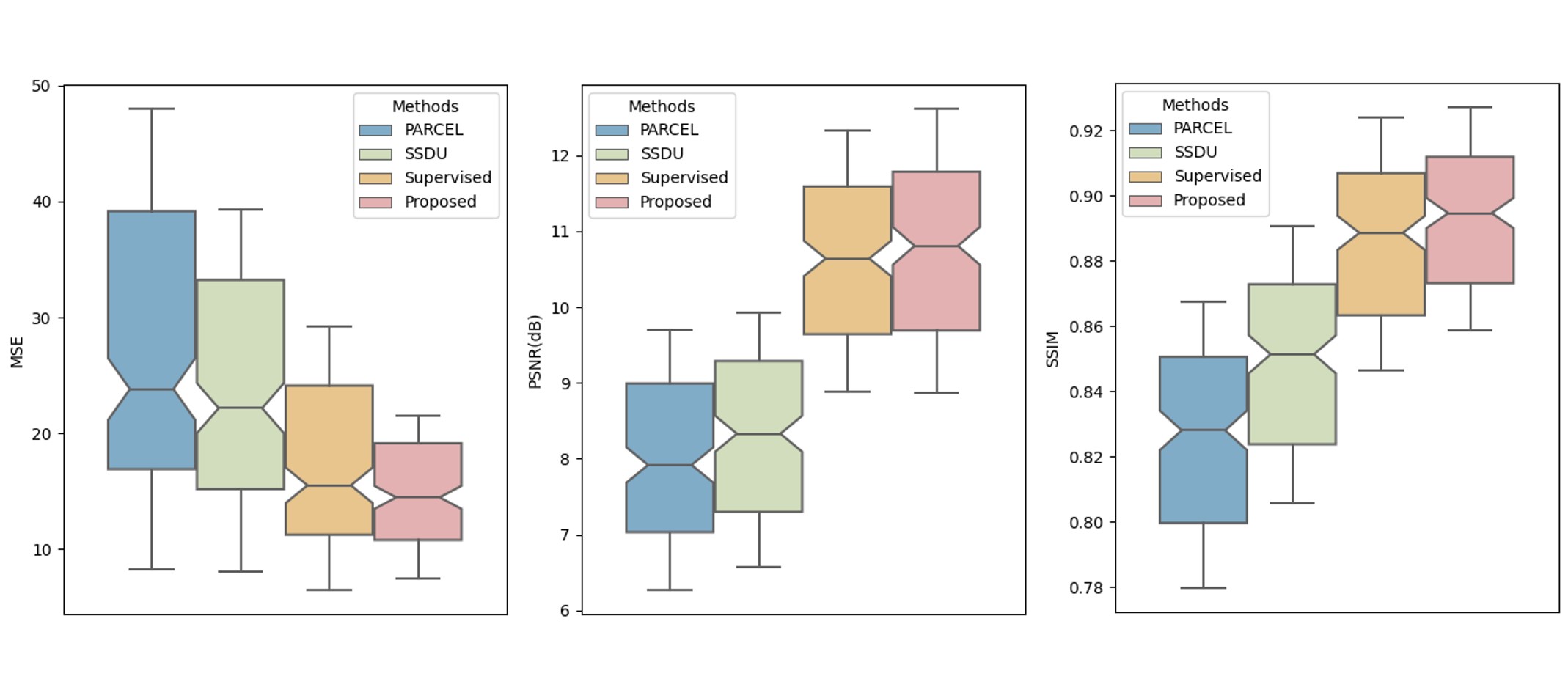
The reconstructions of a patient and a healthy subject from test dataset are shown in Fig.2 and Fig.3, we observe obvious residual artifacts in PARCEL and SSDU under 16× accelerations whereas our method achieves comparable performance to a supervised learning.We calculated MSE, PSNR, SSIM for all slices across all test subjects under 16× acceleration (Fig.4). The proposed method outperforms other self-supervised methods, and even shows more stable and improved performance compared to the supervised learning, demonstrating that feature learning helps the network to understand the data structure and exhibits superior generalization.
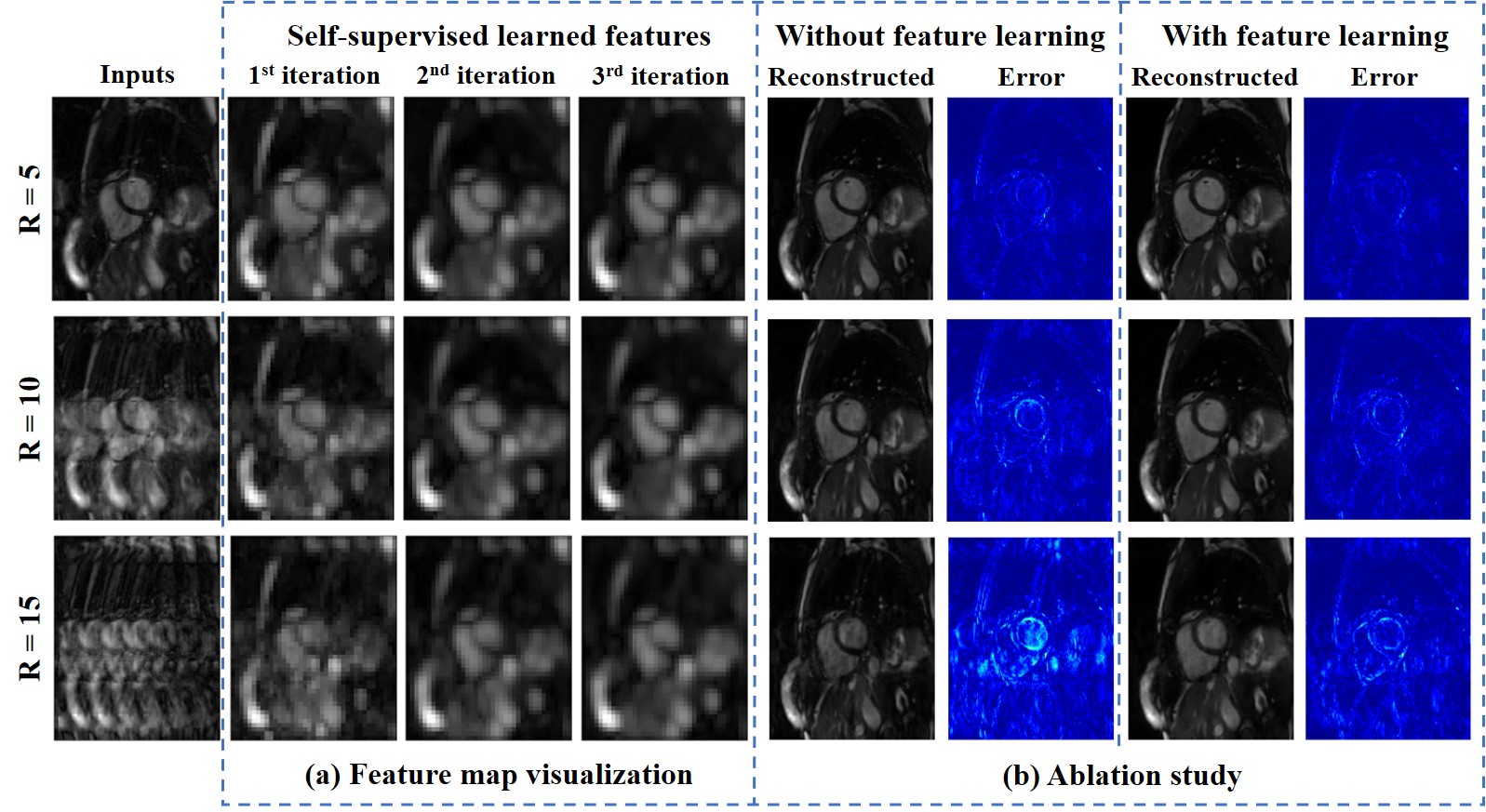
Fig.5(a) shows the learned features of one kernel under different accelerations, and Fig.5(b) compares the ablated experiments without the pre-trained feature extractor. The network could learn sampling-invariant features, which helps remove aliasing artifacts under high accelerations.
Conclusion
The proposed self-supervised feature learning strategy can learn sampling-invariant features from undersampled images. The learned features are concatenated in the self-supervised reconstruction network to assist the network in achieving better performance. The proposed framework can achieve similar performance on par with supervised learning with better generalization ability but being trained only on undersampled data.Acknowledgements
No acknowledgement found.References
1. J. Schlemper et al., "A deep cascade of convolutional neural networks for dynamic mr image reconstruction", IEEE Trans Med Imaging, 2017, 37(2), 491-503.
2. T. Eo et al., "Kiki-net: cross-domain convolutional neural networks for reconstructing undersampled magnetic resonance images", Magn Reson Med, 2018, 80(5), 2188-201.
3. K. Hammernik et al., "Learning a variational network for reconstruction of accelerated mri data", Magn Reson Med, 2018, 79(6), 3055-71.
4. D. Lee et al., "Deep residual learning for accelerated mri using magnitude and phase networks", IEEE Trans on Biomedical Engineering, 2018, 65(9), 1985-95.
5. H. Aggarwal et al., "MoDL: Model-Based Deep Learning Architecture for Inverse Problems", IEEE Trans Med Imaging, 2019, 38(2), 394-405.
6. M. Akçakaya et al., "Scan-specific robust artificial-neural-networks for k-space interpolation (raki) reconstruction: Database-free deep learning for fast imaging", Magn Reson Med, 2019, 81(1), 439-53.
7. A. Hauptmann et al., "Real-time cardiovascular mr with spatio-temporal artifact suppression using deep learning–proof of concept in congenital heart disease", Magn Reson Med, 2019, 81(2), 1143-56.
8. A. Kofler et al., "Spatio-temporal deep learning-based undersampling artefact reduction for 2d radial cine mri with limited training data", IEEE Trans Med Imaging, 2019, 39(3), 703-17.
9. T. Küstner et al., "Cinenet: deep learning-based 3d cardiac cine mri reconstruction with multi-coil complex-valued 4d spatio-temporal convolutions", Sci Rep, 2020, 10(1), 13710.
10. H. El-Rewaid et al., "Multi-domain convolutional neural network (md-cnn) for radial reconstruction of dynamic cardiac mri", Magn Reson Med, 2021, 85(3), 1195-208.
11. W. Huang et al., "Deep low-Rank plus sparse network for dynamic MR imaging", Med Image Anal., 2021, 73, 102190.
12. K. He et al., "Momentum contrast for unsupervised visual representation learning", Proc of the IEEE/CVF conference on computer vision and pattern recognition, 2020, 9729-38.
13. T. Chen et al., "A simple framework for contrastive learning of visual representations”, ICML, 2020, 1597-607.
14. J. Zbontar et al., "Barlow twins: Self-supervised learning via redundancy reduction", ICML, 2021, 12310-20.
15. A. Bardes et al., "VICReg: Variance-invariance-covariance regularization for self-supervised learning", ICLR, 2022.
16. S. Wang et al., "Parcel: Physics-based unsupervised contrastive representation learningfor multi-coil mr imaging", IEEE/ACM Trans on Computational Biology and Bioinformatics, 2022.
17. Q. Yi et al., "Contrastive learning for local and global learning mri reconstruction", ArXiv, 2021, bs/2111.15200.
18. B. Yaman et al., "Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data", Magn Reson Med, 2020, 84(6), 3172-91.
19. S. Xu et al., "Self-supervised contrastive learning for MR image reconstruction of cardiac CINE on accelerated cohorts", Proc ISMRM Annu Meeting Exhibit, 2023.
20. R. Ahmad et al., "Variable density incoherent spatiotemporal acquisition (VISTA) for highly accelerated cardiac MRI", Magn Reson Med, 2015, 74(5), 1266-78.
Figures