0009
Cardiac Cine MRI with Dimension-Reduced Deep Separable Spatiotemporal Learning1Xiamen University, Xiamen, China, 2Fudan University, Shanghai, China, 3Xiamen University of Technology, Xiamen, China, 4Department of Electronic Science, Xiamen University, Xiamen, China
Synopsis
Keywords: AI/ML Image Reconstruction, Machine Learning/Artificial Intelligence, Cardiovascular MRI
Motivation: Cardiac cine MRI reconstruction is a natural high-dimensional problem that poses great challenges to deep learning.
Goal(s): To develop a new deep learning method that can work efficiently in cardiac cine MRI, even with limited training data.
Approach: In this work, the proposed method DeepSSL significantly alleviates training and generalization challenges of deep learning in cardiac cine MRI through efficient dimension-reduced separable learning and spatiotemporal modeling.
Results: Extensive results show that DeepSSL can work efficiently even with highly limited training data (5~10 cases), and provides state-of-the-art reconstructions while reduces data demand by up to 75%. It further shows robustness in prospective real-time MRI.
Impact: The proposed deep separable spatiotemporal learning (DeepSSL) significantly alleviates the training and generalization challenges of deep learning in high-dimensional cardiac cine MRI through efficient dimension-reduced separable learning and spatiotemporal modeling.
Purpose
Cardiac cine MRI reconstruction is a natural high-dimensional problem. Although existing deep learning methods [1-3] have achieved promising performance in cardiac cine MRI, most of them always solve such complicated problems directly and thus require numerous training data [4]. However, cardiac cine MRI data collection is often time-consuming and highly susceptible to the cardiac/respiratory-induced motion [5-6], leading to the scarcity of available training data. In this work, we propose a dimension-reduced separable learning scheme to work efficiently even with highly limited training data (5~10 cases). We further integrate it with spatiotemporal priors to develop a Deep Separable Spatiotemporal Learning network (DeepSSL), which unrolls an iteration process of a reconstruction model with both temporal low-rankness and spatial sparsity. Our DeepSSL provides comparable reconstructions to state-of-the-art deep learning methods, while reduces the data demand by up to 75% (From 100 to 25 cases).Method
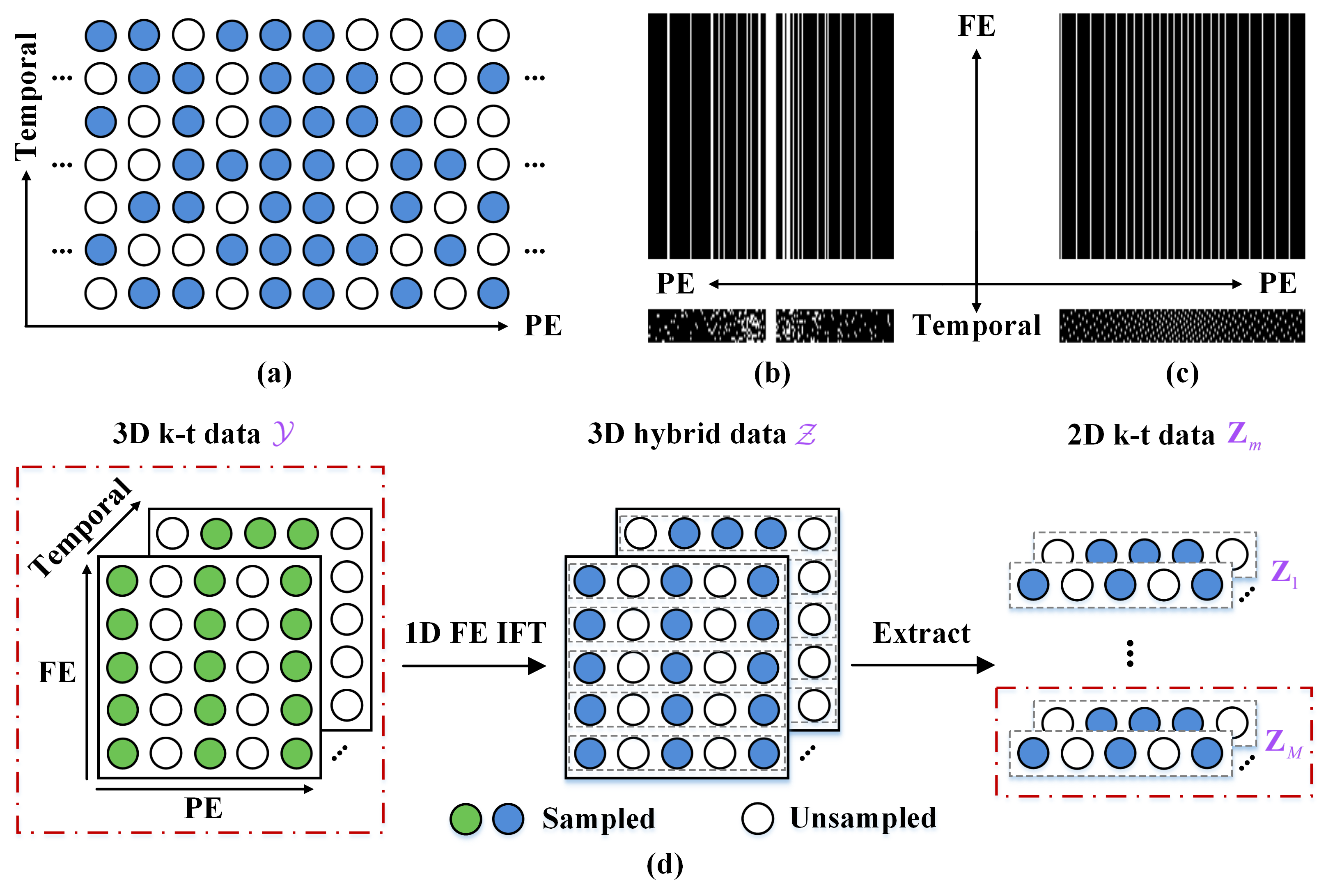
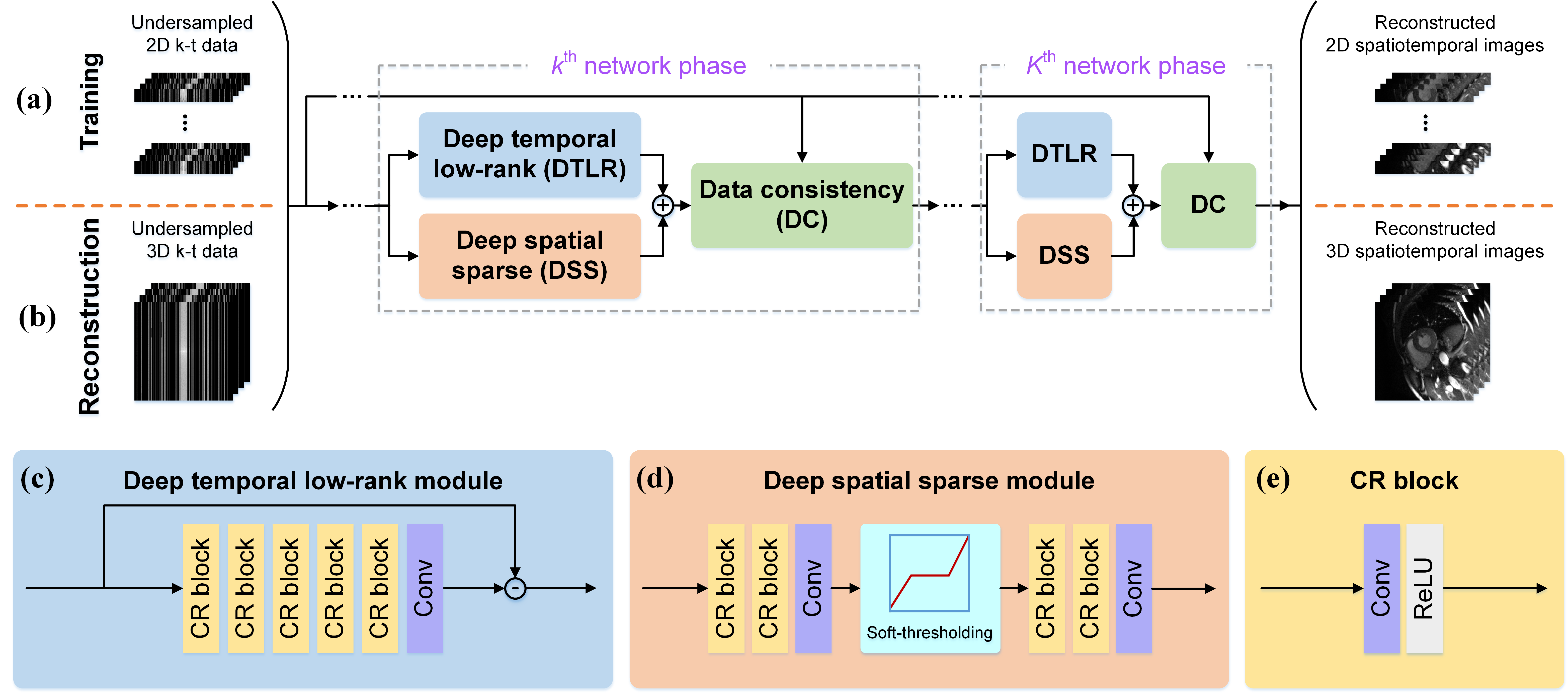
This idea is primarily inspired by the recent success of 1D learning on static MRI reconstruction [7-8]. Specifically, for the Cartesian 2D cardiac cine MRI (3D k-t data), the frequency encoding (FE) direction is always fully sampled, while the imaging acceleration happens in the phase encoding-temporal (PE-t) space by randomly skipping the PE for each temporal frame (Figs. 1(a)-(b)). Then, by taking the 1D inverse Fourier transform (IFT) along the FE, the 3D k-t data can be separated into many 2D k-t data. It is easy to find that all 2D k-t data actually have the same undersampling scenario (Fig. 1(c)), so we can train a deep network on 2D samples instead of the whole 3D ones, to alleviate the computational challenges. In addition to reducing the scale of the reconstruction problem from 3D to 2D, it also leads to significant data enlargement with a factor equal to the dimension of FE.Moreover, we integrate the dimension-reduced separable learning scheme with spatiotemporal priors to develop a Deep Separable Spatiotemporal Learning network (DeepSSL). It formulates both temporal low-rank [9-10] and spatial sparse [11-12] priors as regularized terms in an optimization model and unrolls its iteration process into a deep network, which has three modules (Fig. 2): Deep temporal low-rank module for temporal null space projection and elimination, deep spatial sparse module for spatial anti-aliasing, and data consistency module for measured data alignment.
In the reconstruction stage, for given undersampled 3D k-t data, we can reconstruct them through the trained DeepSSL. As shown in Fig. 2(b), the 1D FE IFT is first performed on the undersampled k-space, then all rows of it form a batch that is then reconstructed in parallel and stitched back together to yield the final 3D spatiotemporal image.
Results
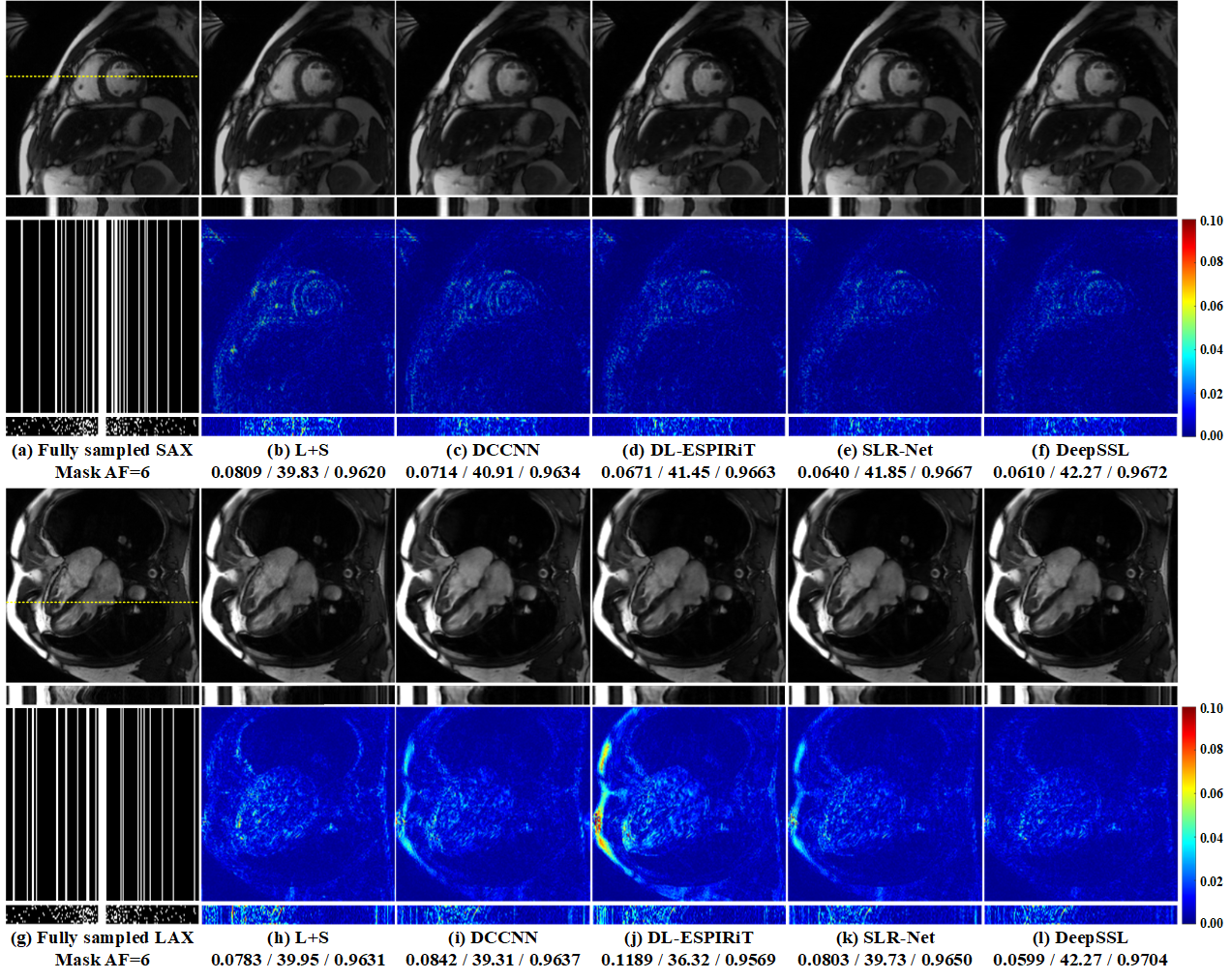
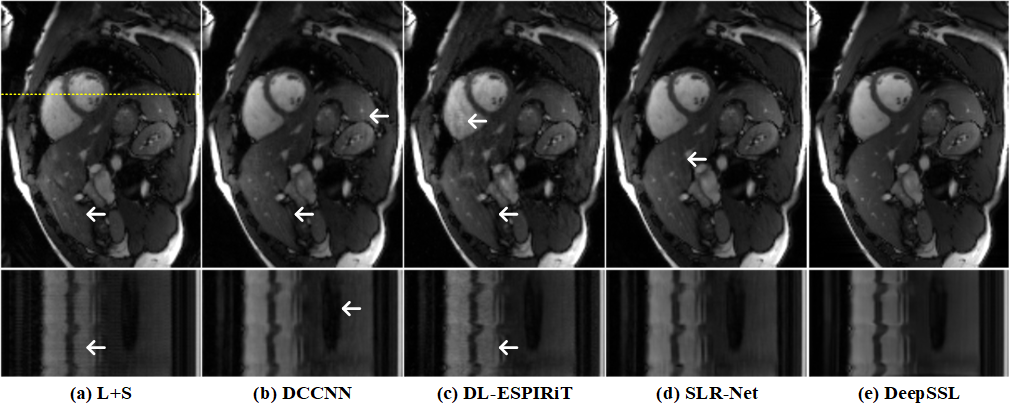
The cardiac cine CMRxRecon dataset [5] is mainly used for training and test in our experiments. Another free-breathing prospective real-time cardiac cine data from OCMR dataset [6] is also used for robustness evaluation. We compare the proposed DeepSSL with three state-of-the-art deep learning methods: DCCNN [1], DL-ESPIRiT [2], and SLR-Net [3]. The training schemes of them are direct learning with 3D k-t data, which is different from our proposed separable learning with 2D k-t data. L+S [13] is used as the reconstruction baseline. To quantitatively evaluate the reconstruction performance, three objective criteria including the relative l2 norm error (RLNE) [14], peak signal-to-noise ratio (PSNR), and structural similarity index (SSIM) [15] are utilized.(i) Reconstruction under a varied number of training cases: Fig. 3 shows that our separable learning DeepSSL consistently outperforms other direct learning networks. Even with a highly limited number of training cases (NTC ≤ 10), DeepSSL already provides far superior reconstructions than the baseline L+S. Representative reconstructions using 100 training cases (Fig. 4) show that DeepSSL has a good ability for artifacts suppression and details preservation. These results imply that DeepSSL can work efficiently and provide comparable reconstructions of different cardiac views to state-of-the-art deep learning methods, while reduce the data demand by up to 75% (From 100 to 25 cases).
(ii) Prospective study on real-time cardiac cine MRI: We further explored the robustness of the proposed method to prospective free-breathing real-time MRI reconstruction, without any fine-tuning. Fig. 5 shows that DeepSSL is superior to other compared methods in terms of artifacts suppression and details preservation, and captures the organ motion precisely. Other methods still exhibit streaking artifacts and spatial blurring.
Conclusion
We believe that the success of dimension-reduced separable learning with nice robustness in cardiac cine MRI is of great significance for clinical applications, because it alleviates challenges of deep learning in solving high-dimensional problems and training on limited data.Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under grants 62331021, 62122064, 61971361, and 61871341, Natural Science Foundation of Fujian Province of China under grants 2023J02005 and 2021J011184, President Fund of Xiamen University under grant 20720220063, and Xiamen University Nanqiang Outstanding Talents Program. The authors thank Drs. Michael Lustig, Ricardo Otazo, Jo Schlemper, Christopher M. Sandino, and Dong Liang for sharing their codes online.
The correspondence should be sent to Prof. Xiaobo Qu (Email: quxiaobo@xmu.edu.cn)
References
[1] J. Schlemper, J. Caballero, J. V. Hajnal, A. N. Price, and D. Rueckert, "A deep cascade of convolutional neural networks for dynamic MR image reconstruction," IEEE Transactions on Medical Imaging, vol. 37, no. 2, pp. 491-503, 2018.
[2] C. M. Sandino, P. Lai, S. S. Vasanawala, and J. Y. Cheng, "Accelerating cardiac cine MRI using a deep learning-based ESPIRiT reconstruction," Magnetic Resonance in Medicine, vol. 85, no. 1, pp. 152-167, 2021.
[3] Z. Ke et al., "Learned low-rank priors in dynamic MR imaging," IEEE Transactions on Medical Imaging, vol. 40, no. 12, pp. 3698-3710, 2021.
[4] Q. Yang, Z. Wang, K. Guo, C. Cai, and X. Qu, "Physics-driven synthetic data learning for biomedical magnetic resonance: The imaging physics-based data synthesis paradigm for artificial intelligence," IEEE Signal Processing Magazine, vol. 40, no. 2, pp. 129-140, 2023.
[5] C. Wang et al., "CMRxRecon: An open cardiac MRI dataset for the competition of accelerated image reconstruction," arXiv:2309.10836, 2023.
[6] C. Chen et al., "OCMR (v1.0)--Open-access multi-coil k-space dataset for cardiovascular magnetic resonance imaging," arXiv:2008.03410, 2020.
[7] Z. Wang et al., "One-dimensional deep low-rank and sparse network for accelerated MRI," IEEE Transactions on Medical Imaging, vol. 42, no. 1, pp. 79-90, 2023.
[8] Z. Wang et al., "One for multiple: Physics-informed synthetic data boosts generalizable deep learning for fast MRI reconstruction," arXiv: 2307.13220, 2023.
[9] K. H. Jin, D. Lee, and J. C. Ye, " A general framework for compressed sensing and parallel MRI using annihilating filter based low-rank Hankel matrix," IEEE Transactions on Computational Imaging, vol. 2, no. 4, pp. 480-495, 2016.
[10] M. Jacob, M. P. Mani, and J. C. Ye, "Structured low-rank algorithms: Theory, magnetic resonance applications, and links to machine learning," IEEE Signal Processing Magazine, vol. 37, no. 1, pp. 54-68, 2020.
[11] M. Lustig, D. Donoho, and J. M. Pauly, "Sparse MRI: The application of compressed sensing for rapid MR imaging," Magnetic Resonance in Medicine, vol. 58, no. 6, pp. 1182-1195, 2007.
[12] Y. Yang, F. Liu, Z. Jin, and S. Crozier, "Aliasing artefact suppression in compressed sensing MRI for random phase-encode undersampling," IEEE Transactions on Biomedical Engineering, vol. 62, no. 9, pp. 2215-2223, 2015.
[13] R. Otazo, E. Candès, and D. K. Sodickson, " Low-rank plus sparse matrix decomposition for accelerated dynamic MRI with separation of background and dynamic components," Magnetic Resonance in Medicine, vol. 73, no. 3, pp. 1125-1136, 2015.
[14] X. Qu, Y. Hou, F. Lam, D. Guo, J. Zhong, and Z. Chen, "Magnetic resonance image reconstruction from undersampled measurements using a patch-based nonlocal operator," Medical Image Analysis, vol. 18, no. 6, pp. 843-856, 2014.
[15] W. Zhou, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, "Image quality assessment: From error visibility to structural similarity," IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600-612, 2004.
Figures