5191
Quantitative DCE-MRI parameter estimation using Deep Learning Framework in the Brain Tumor Patients1Centre for Biomedical Engineering, Indian Institute of Technology Delhi, New Delhi, India, 2Department of Radiology, Fortis Memorial Research Institute, Gurugram, India, 3Yardi School of Artificial Intelligence, Indian Institute of Technology Delhi, New Delhi, India, 4Department of Biomedical Engineering, All India Institute of Medical Sciences, New Delhi, India
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Brain
Tracer Kinetic (TK) parametric maps are obtained from Dynamic Contrast Enhanced (DCE) - MRI which aid in the detection and grading of brain tumors. Conventionally, TK maps are obtained using Non-Linear-Least-Square (NLLS) fitting approach, which is time consuming and data noise. In the current study, we implemented a deep learning framework whose backbone is attention networks to estimate TK parametric maps. Transfer learning was performed to extend work from synthetic data to high-grade glioma (HGG) patients’ DCE-MRI data to obtain better quality TK maps in lesser time.Introduction
TK maps obtained from DCE-MRI have shown potential for the detection and grading of brain tumors such as gliomas1. Various types of compartmental models such as TKM, GTKM, LTKM, etc. are being used for quantitative analysis of DCE-MRI data2. In general, these models are fitted using NLLS fitting approach for the computation of TK maps, which involves a long computation time depending upon the data dimension. This has limited immediate access to quantitative TK maps for clinical evaluation. Moreover, computed maps are also quite noisy, particularly in the area of low concentration of contrast agents.Recently, some attempts have been made for faster estimation of TK maps using deep-learning (DL) 3-6. All of them worked on signal intensity time curves (SITC), which is not absolute scale and machine dependent.
In the current study, we propose a DL framework for direct estimation of TK maps that should be built on concentration-time-curves (CTC) rather than SITC (conversion of SITC to CTC is a quick process). Estimation of TK maps from CTC will reduce dependencies and eliminate the NLLS fitting.
Methods
The proposed architecture uses a combination of Long-Short-Term-Memory (LSTM) and attention layers (self-attention, temporal-attention and deformable cross attention)7,8. Initially the features were fused and finally dense layer was used to estimate TK parameters (Ktrans, Ve & Vp) from the output of the attention network (Figure 1).Tofts GTKM model was used as a reference model and a physics-informed loss function was used as introduced by Ottens et. al.5. The training was done in a batch size of 2, AdamW optimizer9, 200 epochs and the learning rate was 2×10-4 with a decay of 10-4.
Synthetic Data
We generated synthetic data of 177,156,100 CTCs with synthetic noise (Signal-to-Noise Ratio [SNR] = 5-80). Simulated CTC were generated using GTKM with values ranging from rate constant for influx of gadolinium (Ktrans) [1×10-5 – 2×10-1 min-1], plasma volume fraction (Vp) [0.0005 - 1] and extravascular extracellular space (Ve) [0.04-06], which are in the reported physiological range of TK parameters. Each CTC consisted of 32 time points with temporal resolution of 0.025 min. These CTC were subjected to different noise levels to mimic experimental data. Ground truth TK values remain the same for noisy CTC as for the base CTC without noise.
Patient Data
DCE-MRI data of 36 pre-operative patients (age: 49.39 ± 15.53 years) with HGG was used in this study. Imaging was performed on a 3.0T MRI scanner (Ingenia, Philips Healthcare, and The Netherlands). Imaging included conventional MRI, pre-contrast T1 map data, and DCE-MRI data acquired using 3D T1-weighted Fast Field Echo (FFE) sequence with FOV=230x230, TR/TE=3.0/6.27s, FA=10°, CSENSE=4, 20 slices and 32 time points. DCE-MRI data were converted into CTC maps using pre-contrast T1 map.
Synthetic data and patient data were split in randomly 80:20 for training and testing. First model was trained and tested on synthetic data and transfer learning was done on 28 randomly selected patients’ data. One DL network was trained for Ktrans and Vp values and another for Ve values separately. We assessed the performance based on the root-mean-square error (RMSE) and structure similarity index measure (SSIM) to assess the performance of the networks. Optimizations of the DL frameworks were also carried out.
Results
The training and testing results for synthetic data showed the best results for predicted Vp values. Similar performance was seen in patient data as well (Table 1). The maps obtained were less noisy as compared to conventional ones (Figure 2). The processing time was reduced from 77 min to 5.3 min to process one patient data on Intel Xenon(R), 64 GB Ram, Nvidia Quadro K600.Figure 3 shows that the predicted Ktrans map shows the difference in the highlighted region which is cross-checked with FLAIR, Post Contrast T1 and R2 map, which confirms that the predicted Ktrans map is more accurate than the conventional Ktrans map, suggesting that the proposed network was good at picking the accurate and precise tumor regions and with reduced computation time.
Discussion
The proposed network successfully predicted the TK maps from DCE-MRI data (CTC) with substantially faster and better performance than the NLLS method. The performance observed on patient data showed that maps were less noisy and captured significant information in various tissues.The mismatch between the Ktrans map of predicted and actual (NLLS), shows how important the synthetic data was to establish a pre-trained network. This architecture has been trained and tested on HGG patients only (Figure 3). One of the limitations of the study is lack of true ground truth for experimental data. However, alternative approaches have been used for evaluating accuracy. In future, proposed framework will also be evaluated for other brain tumors data and from multiple centres.
Conclusion
The current study suggest that the proposed architecture can estimate TK maps from DCE-MRI with more accuracy and precision than conventional NLLS fitting in lesser time for HGG patients.Acknowledgements
Authors acknowledge the funding support of SERB, DST (project number: CRG/2019/005032).References
1. J. Zhang et al., “Clinical applications of contrast-enhanced perfusion MRI techniques in gliomas: Recent advances and current challenges,” Contrast Media Mol. Imaging, vol. 2017, Mar. 2017, doi: 10.1155/2017/7064120.
2. S. P. Sourbron and D. L. Buckley, “Classic models for dynamic contrast-enhanced MRI,” NMR Biomed., vol. 26, no. 8, pp. 1004–1027, Aug. 2013, doi: 10.1002/NBM.2940.
3. K. Fang et al., “Convolutional neural network for accelerating the computation of the extended Tofts model in dynamic contrast-enhanced magnetic resonance imaging,” J. Magn. Reson. Imaging, vol. 53, no. 6, pp. 1898–1910, Jun. 2021, doi: 10.1002/JMRI.27495.
4. Q. Zeng and W. Zhou, “An Attention Based Deep Learning Model for Direct Estimation of Pharmacokinetic Maps from DCE-MRI Images,” Proc. - 2021 IEEE Int. Conf. Bioinforma. Biomed. BIBM 2021, pp. 2368–2375, 2021, doi: 10.1109/BIBM52615.2021.9669582.
5. T. Ottens et al., “Deep learning DCE-MRI parameter estimation: Application in pancreatic cancer,” Med. Image Anal., vol. 80, p. 102512, Aug. 2022, doi: 10.1016/J.MEDIA.2022.102512.
6. R. Rasti, M. Teshnehlab, and S. L. Phung, “Breast cancer diagnosis in DCE-MRI using mixture ensemble of convolutional neural networks,” Pattern Recognit., vol. 72, pp. 381–390, Dec. 2017, doi: 10.1016/J.PATCOG.2017.08.004.
7. Y. Wang et al., “End-to-End Video Instance Segmentation with Transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8741–8750, Accessed: Nov. 09, 2022. [Online]. Available: https://git.io/VisTR.
8. X. Zhu, W. Su, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” Accessed: Nov. 09, 2022. [Online]. Available: https://arxiv.org/pdf/2010.04159.pdf.
9. I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regularization,” 2019.
Figures
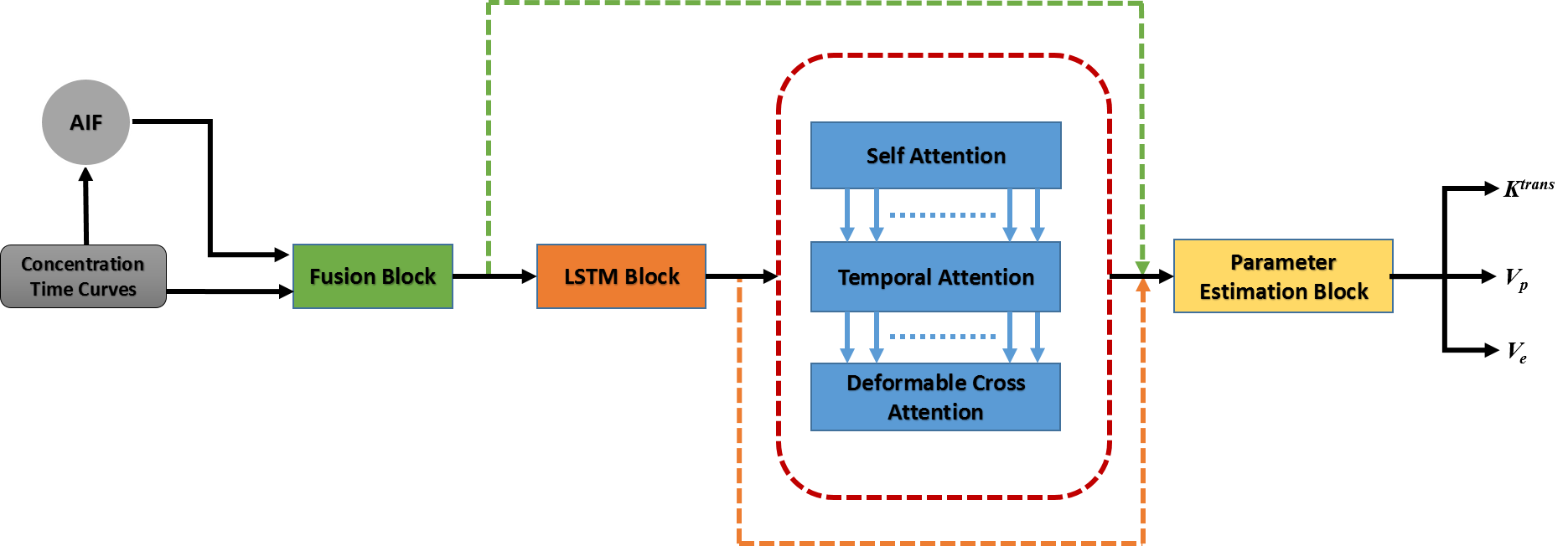
Figure 1: Proposed Architecture Overview
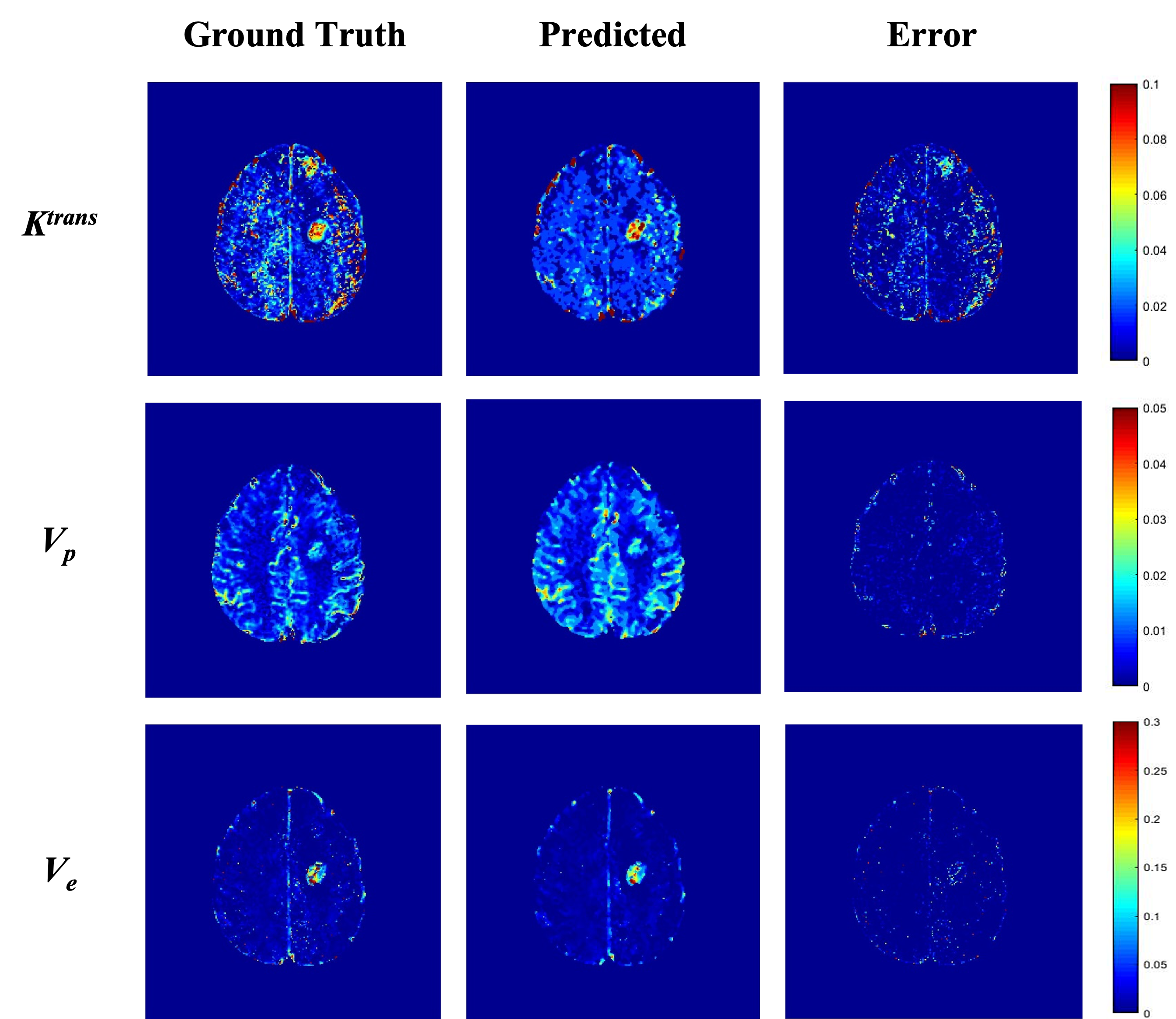
Figure 2: TK Parametric maps: each row shows ground truth, predicted and error maps of Ktrans, Vp & Ve respectively of a representative case of Brain Tumor
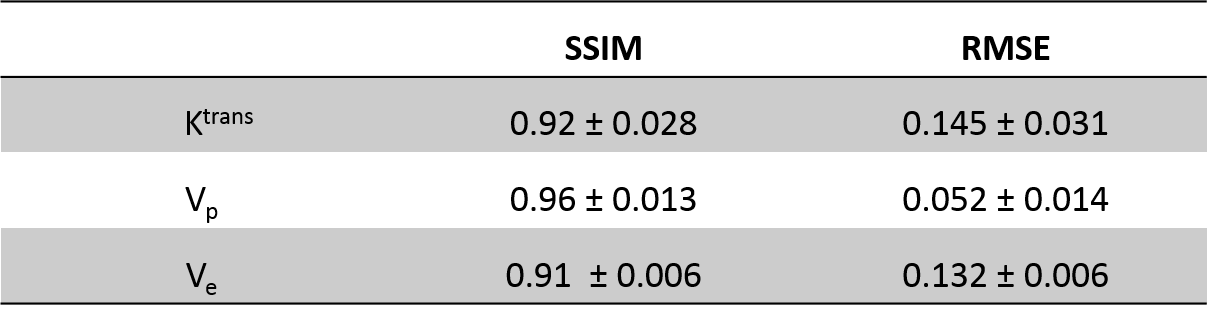
Table 1: SSIM & RMSE values of predicted TK parametric maps (Ktrans, Vp & Ve respectively) on the test patient data
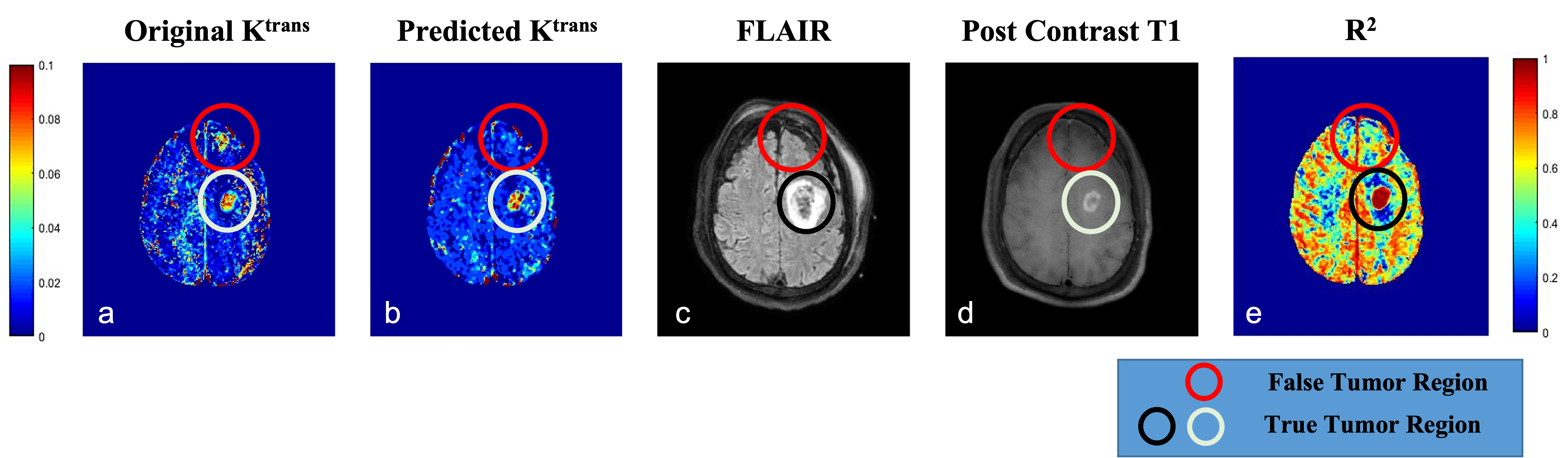
Figure 3: Comparison of original (a) & predicted (b) Ktrans map with FLAIR (c), Post Contrast T1 (d) MRI and R2 maps(e) for identification of true tumor lesion