5137
Unsupervised deep learning with variational autoencoder for image quality improvement in ultrafast cardiac cine MRI: Initial results1MR Clinical Science, Philips Health Technology, Suzhou, China, 2RWTH University Aachen, Aachen, Germany, 3Diagnostic and Interventional Radiology, University Hospital RWTH Aachen, Aachen, Germany, 4Philips Japan, Tokyo, Japan, 5Philips Market DACH, Hamburg, Germany
Synopsis
Keywords: Myocardium, Cardiovascular
Ultrafast imaging with high acceleration in cardiac MRI is of great clinical interest, but so far often results in inferior image quality that prevents its use in routine diagnosis. In this work, we aim to establish an unsupervised deep learning neural network based on vector quantized variational autoencoder for noise reduction and image quality improvement. Initial results on both public and clinical data promise a new approach to the existing methods. Further investigations with focus on its effectiveness of performance in real world applications are warranted.Introduction
Cine magnetic resonance imaging (MRI) has important clinical value in investigation of cardiac function and heart diseases1. State-of-the-art techniques require typically physiology-synchronized and k-space segmented acquisitions with ECG gating and breath holding in combination with retrospective data sorting to achieve a good balance between temporospatial resolutions to resolve cardiac motions and signal-to-noise ratio (SNR) to maintain reasonable image quality. Although accelerations via further undersampling, either with advanced reconstructions such as compressed sensing2 or for consecutive imaging such as real-time imaging3,4, is possible, these often come with a cost of impaired image quality with decreased SNR. So far deep learning based supervised learning strategies have been widely used for image quality improvement5, which requires a large number of training datasets and the manually generated labels for myocardial segmentation. In our work, we aimed at establishing an unsupervised neural discrete representation learning through a Vector Quantized-Variational Qutoencoder (VQ-VAE)6 to extract cardiac morphological features from publicly available dataset and apply the model in clinically obtained ultrafast cardiac imaging to examine its initial performance for image quality improvement.Method
The variational autoencoder is a generative model based on discrete Latent variables, and the architecture of the VQ-VAE is shown in Figure 1. It is composed of an encoder, a decoder, and an embedding table, formulated as $$$E=[e_1,e_2,…,e_K]$$$, where K is the number of these embedding vectors $$$e_i$$$, and the size of $$$e_i$$$ is 1 × D. In this work, we set K=64 and D=128. The continuous vector $$$z_e$$$ was calculated through an encoder, and the discretization of $$$z_e$$$ was performed by mapping it to the latent variable space and snapping it to the nearest element of the embedding table $$$E$$$, resulting in the discrete vector $$$z$$$. Finally, the decoder was applied on $$$z$$$ to recover the input information.A publicly available dataset (Data Science Bowl) was used in the training and testing of the neural network. In total, 5098 two-dimensional cine series, each with 30 frames or cardiac phases, were included in the training process. 80% of the samples were chosen as training dataset and the remaining 20% as validation dataset. In addition, a separate series of 1982 samples served as an independent testing set. Rician noises were added to the training images7 with different noise levels {70dB, 60dB, 50dB}. Robustness of the de-noising performance of the VQ-VAE network was evaluated.
Additional clinical ultrafast real-time cardiac images were acquired on a whole-body system (1.5T Ambition, Philips Healthcare, Best, The Netherlands) with standard torso phase-array receiver coil in healthy volunteers, under informed consent. Interleaved radial sampling was employed with the following scan parameters: field-of-view FOV 256 x 256 mm2, matrix 128 x 128, slice thickness 8 mm, repetition time TR / echo time TE 2.7 / 1.3 ms, flip angle 12 deg for T1-weighted turbo-field echo (T1-TFE) and 60 deg for balanced steady-state free precession TFE (B-TFE), radial spokes 15 x 5, effective temporal resolution 41 ms. The generalization feature of the trained network was investigated. Two metrics were employed to measure the distance between the de-noised images and the ground truth images: peak signal noise ratio (PSNR) and structural similarity index measurement (SSIM). The PSNR and SSIM for images with different levels of noise added were calculated and compared.
Results and Discussion
Results using the public dataset are presented in Figure 2. The output of the unsupervised deep learning VQ-VAE network (predicted) exhibits a clear image quality improvement, in comparison to the simulated noise-added data (Rician noise, 60 dB noise level). Table 1 illustrated quantification of the de-noising performance from the VQ-VAE network at different noise levels. For all noise-added images with SNR ≥ 60 dB, good image quality was achieved (PSNR = 25.65±1.66, SSIM = 0.80±0.05). Results using a set of clinical cardiac images are shown in Figure 3. Compared to autoencoder learning, the unsupervised VQ-VAE neural network learns an additional coding table in the training process, which maps the extracted high-dimensional features to a corresponding vector in the coding table. Although its de-noising performance was only evaluated in public dataset with obvious visual improvement, in general no manual labelling was needed for network training, and the model is reasonably robust to noise levels equal to or above of 60 dB.Conclusion
In this study, we established an unsupervised deep learning neural network based on a VQ-VAE model for noise reduction and image quality improvement in cardiac cine MRI. Initial performance in both public and clinical data demonstrates promise and warrants further investigation, with the focus on effectiveness in real world applications.Acknowledgements
No acknowledgement found.References
Figures
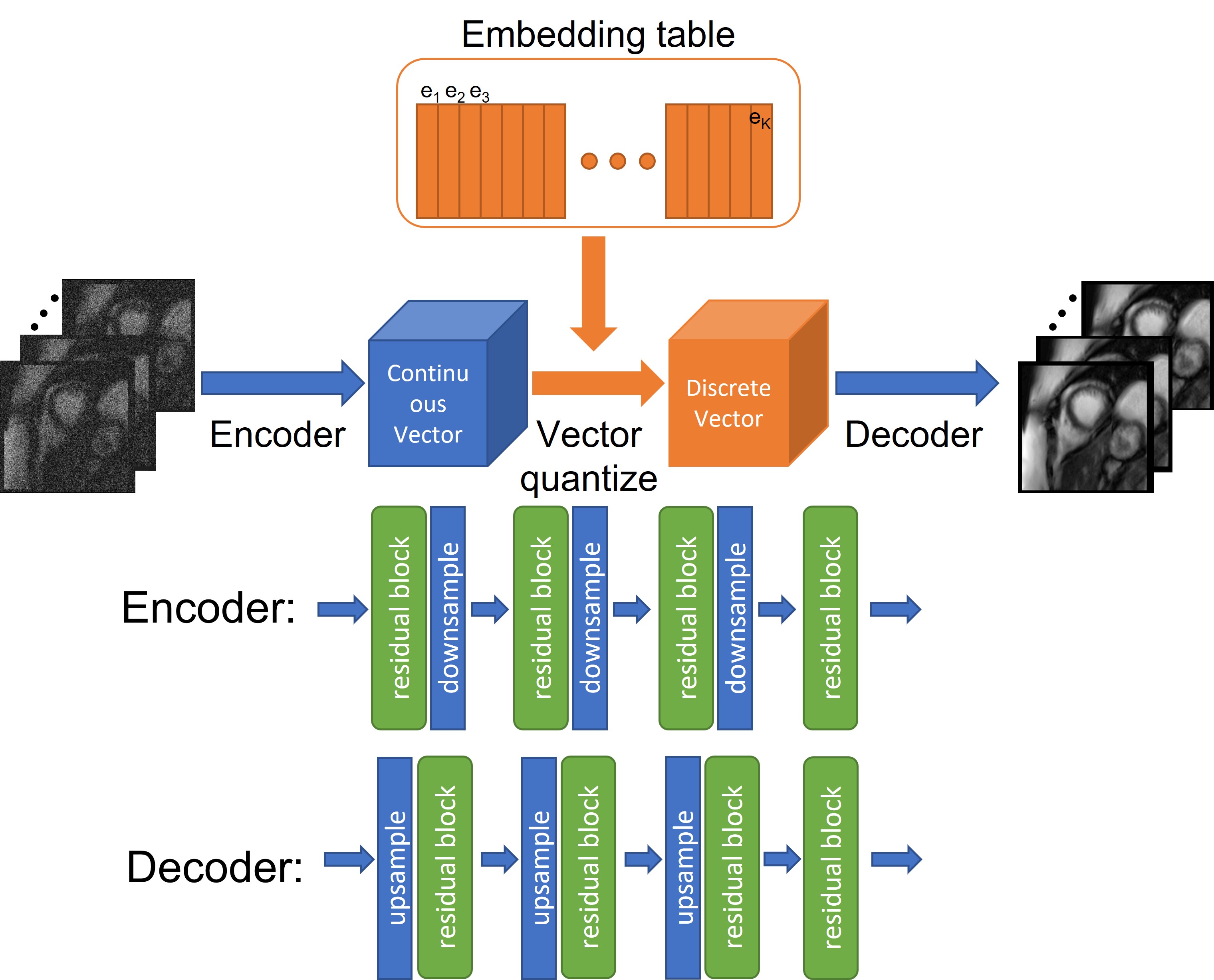
Figure 1 The VQ-VAE network architecture used in this work. It consists of an encoder, a decoder and an embedding table. Details see text.

Figure 2 Output of the unsupervised deep-learning VQ-VAE network based on the public data shows clearly improved image quality (predicted) in comparison to the simulated noise-added images (Rician noise, 60 dB noise level). Original images are also presented (ground truth).

Table 1 The mean and standard deviation of the PSNR and SSIM for the simulated noise added cardiac cine images.

Figure 3 Output of the unsupervised deep-learning VQ-VAE network based on the clinical data (Improved). Eight consecutive image frames from the same natural cardiac cycle were presented and shown here. With zoomed view of frame 1 and frame 8, the improved image quality was observed especially around the septum area between left and right ventricles (pointed out by arrows).