4775
CS-MRI Reconstruction Using an Improved Generative Adversarial Network with Channel Attention Mechanism
Xia Li1, Hui Zhang2, and Tie-Qiang Li3
1Information Engineering, China Jiliang University, Hangzhou, China, 2Information Engineering, China Jiliang University, HANGZHOU, China, 3Karolinska Institute, Stockholm, Sweden
1Information Engineering, China Jiliang University, Hangzhou, China, 2Information Engineering, China Jiliang University, HANGZHOU, China, 3Karolinska Institute, Stockholm, Sweden
Synopsis
Keywords: Image Reconstruction, Brain, Compressed sensing MRI
Generative adversarial network (GAN) has emerged as one of the most prominent approaches for fast CS-MRI reconstruction. However, most deep-learning models achieve performance by increasing the depth and width of the networks, leading to prolonged reconstruction time and difficulty to train. We have developed an improved GAN-based model to achieve quality performance without increasing complexity by implementing the following: 1) dilated-residual structure with different dilation rates at different depth of the networks; 2) CAM to adjust the allocation of network resources; 3) multi-scale information fusion module to achieve feature fusion. Experiment data have confirmed the validity for the modules.INTRODUCTION
Compressed sensing (CS) is a promising approach that employs the sparsity property as a precondition for signal recovery (1). CS-based techniques have been increasingly applied to improve MRI time efficiency. Recently, deep-learning technique in general (2) and generative adversarial network (GAN) in particular (3) (4) has emerged as one of the most prominent approaches for fast CS-MRI reconstruction. Once trained, deep-learning based methods can outperform conventional reconstruction algorithms in both reconstruction speed and imaging quality (5). However, most deep-learning based reconstruction models achieve performance improvement by increasing the depth and width of the networks (6), leading to prolonged reconstruction time and difficulty for convergency (7). In this study, we have developed an improved GAN-based model to achieve quality performance without increasing complexity of the model.METHODS
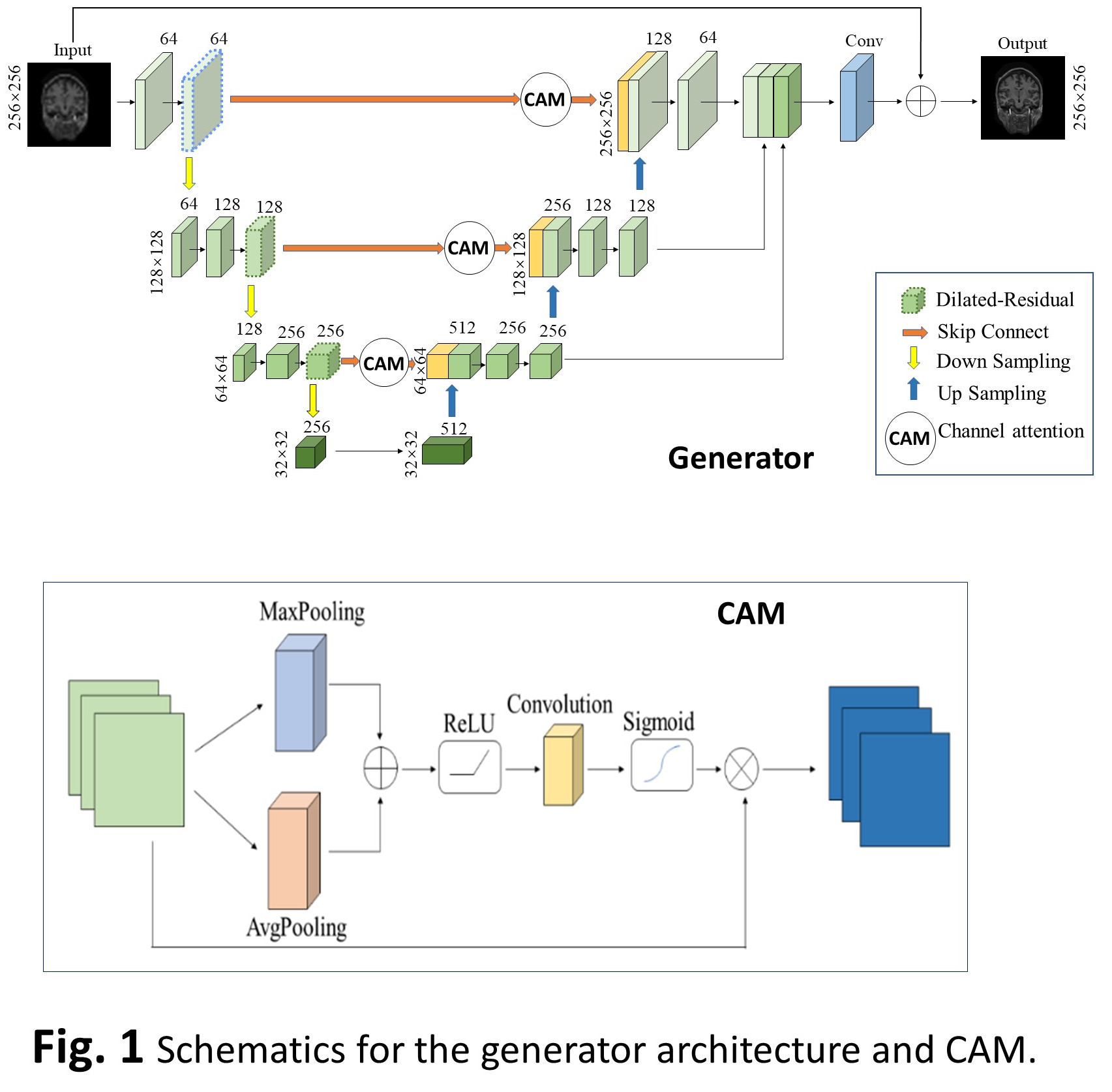
For model training and validation, we used145 different datasets from a large open-source dataset - Open Access Series of Imaging Studies (OASIS) and shuffled them randomly, using 70% of the MR image files for training and the remaining 30% for testing. To simulate the CS under sampling, we converted the images to fully sampled k-space data in the complex domain using inverse Fourier transform and then applied different degrees of under sampling masks ranged from 50-10%. As shown in Fig. 1, the generator network was implemented by modifying a U-net structure with dilated-residual blocks at different depths to expand the receptive field o without increasing the number of parameters or the computation of the network. Leveraging on the idea of TridenNet's receptive field matching (8), our generator structure used three dilated residual blocks with the dilation rates of 1, 2, and 4, respectively. Unlike the standard U-net structure with a simple superposition of shallow and deep features along the channel direction, which does not focus effective resources on the significant features for CS-MRI reconstruction, we implemented a channel attention mechanism (CAM), whose structure is shown in Fig. 1b. The CAM is able to establish the dependency relationship between channels to achieve suppression of background information and focus on key features. The discriminator consisted of a series of convolutions, and batch-normalization was appended after each convolution to normalize the input. Following the architectural guidelines summarized by Radford et al (9), we avoided the use of max-pooling layers and instead varied the convolution stride to achieve feature down sampling. The model was implemented on a workstation equipped with an NVIDA Tesla V100 GPU using the development environment is PyTorch. The model has a total number of parameters of 41.84 MB. We chose to use a small learning rate as the initial value to avoid network oscillations (10). The small learning ratefacilitated the network reaching a better initialization position. Then, we adjusted to a higher learning rate to speed up the network convergence. The learning rate was linearly increased to within the first 30 epochs, and then kept at this maximum rate in next 30 epochs. In the last 40 epochs of network training, the learning rate was ramped down linearly. Through early stop strategy, the network was trained for around 100 epochs, each epoch contained 1549 steps and each step toke about 1.43 s. Therefore, each epoch toke for about 40 min including the calculation of PSNR, SSIM, and MSE for the validation sets. For comparison, we implemented also 4 reference networks including CRNN, DAGAN, and RefineGAN (11).RESULTS
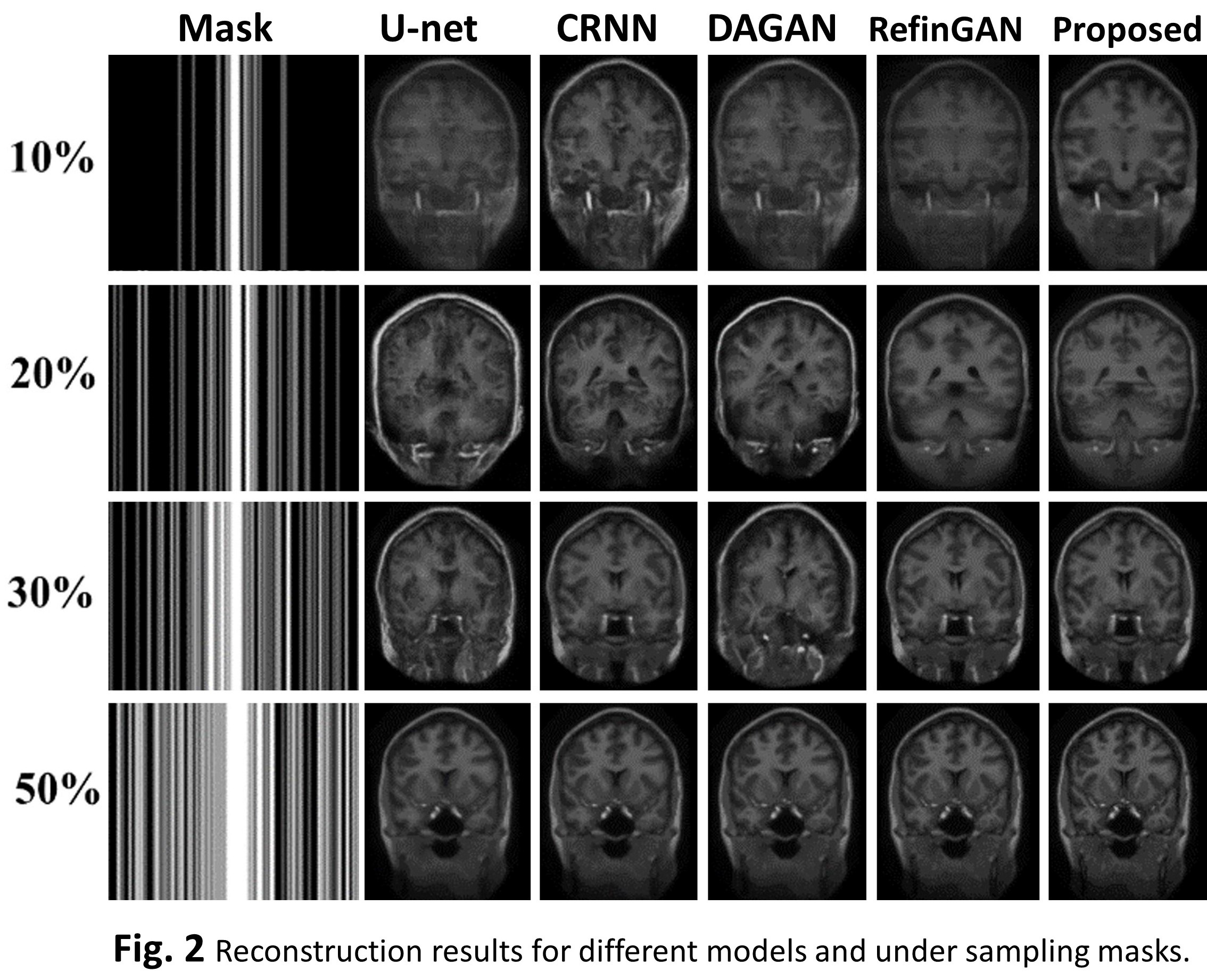
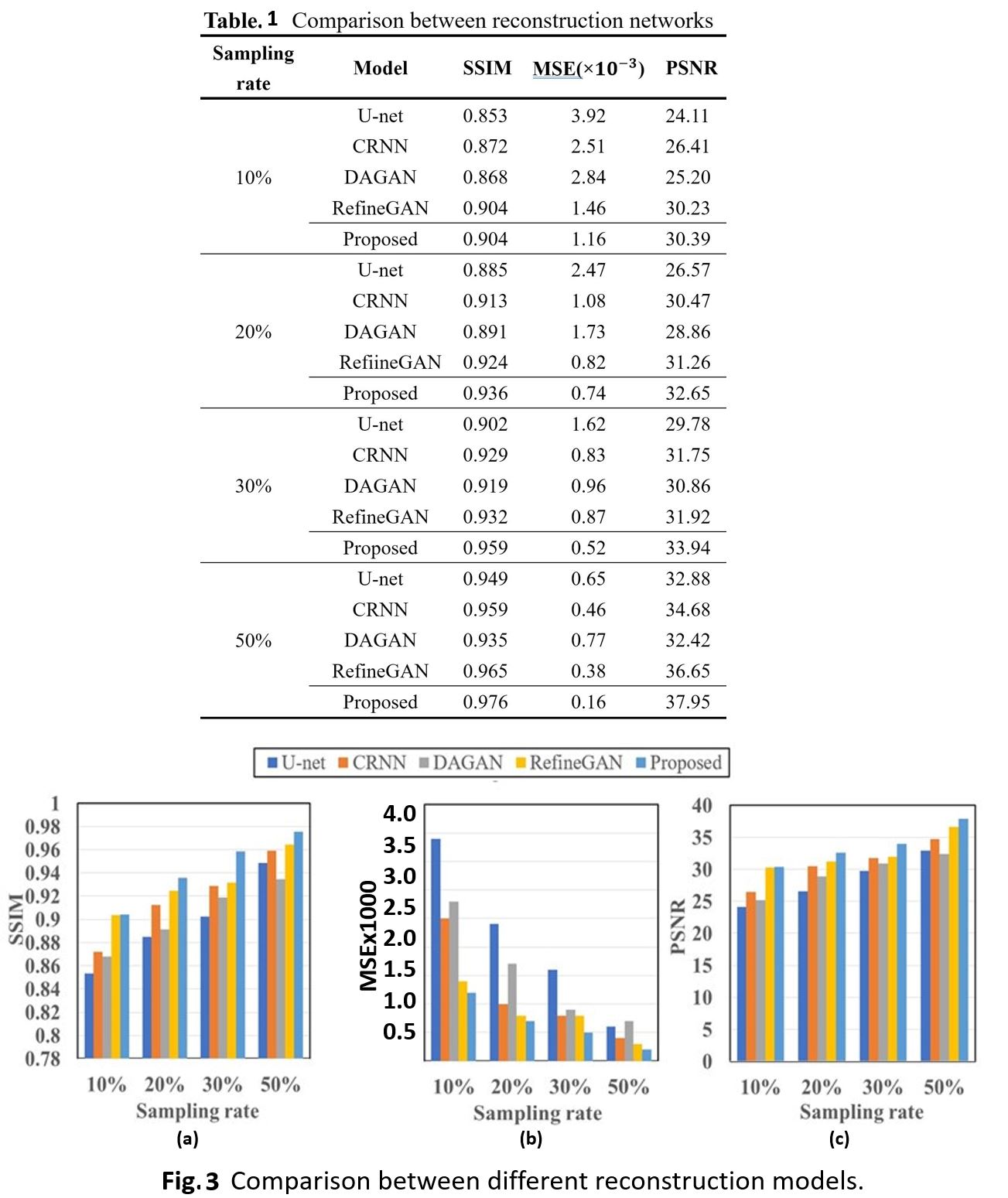
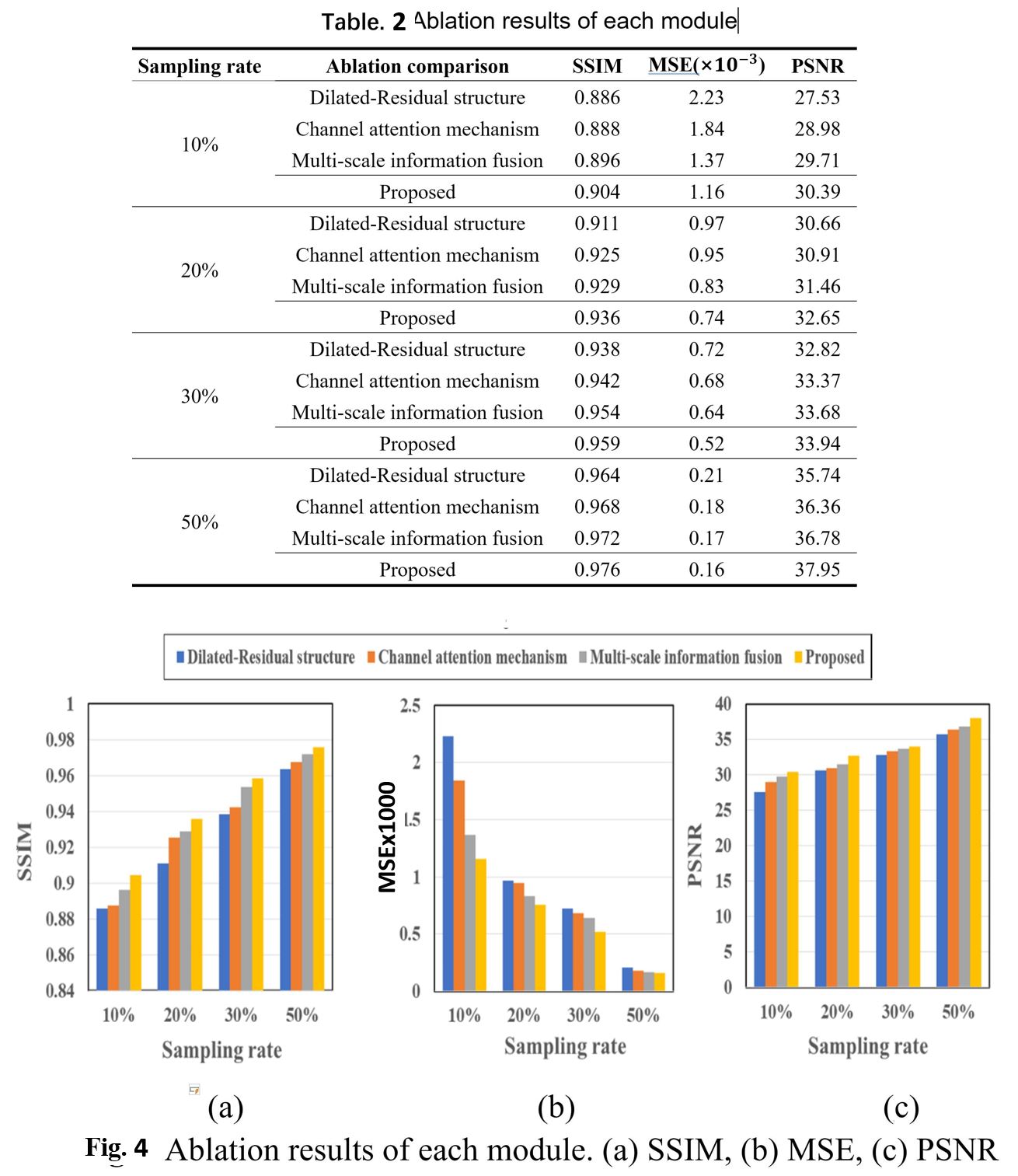
Fig. 2 shows a typical set of reconstructed images of coronal slice of the brain including results for 5 different models and 4 different degrees of under sampling. Quantitative assessments of the image quality are summarized in Table 1 and Fig. 3. Overall, these deep-learning models have demonstrated good performance even at high under sampling rates. It is also apparent the different quality metrics (PSNR, SSIM, and MSE) follow the sample trend. Our proposed has demonstrated outstanding performance with good stability. For further dissection of the model performance, we conducted ablation tests. Table. 2 and Fig. 4 depict the quantitative data for the ablation experiments for the three-evaluation metrics of SSIM, MSE, and PSNR for sampling masks based on 1D Gaussian distribution. It shows that the full model outperforms other sub-model variations, which indicated that the current configurations in our proposed network architecture are effective.CONCLUSION
In this study, we adopted a U-net structure to construct an improved GAN network for fast CS-MRI reconstruction. We achieved the goal of improving reconstruction quality without increasing the complexity of the model by implementing the following features into the architecture: 1) the dilated-residual structure with different dilation rates at different depth of the networks to achieve adequate the receptive field; 2) CAM to adjust the allocation of network resources; 3) multi-scale information fusion module to aggregate multiple intermediate layers achieving feature fusion. Ablation experiments have confirmed the validity of the modified modules we proposed in the network.Acknowledgements
No acknowledgement found.References
1. L. B. Montefusco, D. Lazzaro, S. Papi, C. Guerrini, A fast compressed sensing approach to 3D MR image reconstruction. IEEE transactions on medical imaging 30, 1064-1075 (2010). 2. A. Pal, Y. Rathi, A review of deep learning methods for MRI reconstruction. arXiv preprint arXiv:2109.08618, (2021). 3. M. Lustig, D. L. Donoho, J. M. Santos, J. M. Pauly, Compressed sensing MRI. IEEE signal processing magazine 25, 72-82 (2008). 4. H. Zhang, I. Goodfellow, D. Metaxas, A. Odena, in International conference on machine learning. (PMLR, 2019), pp. 7354-7363. 5. T. K. Jhamb, V. Rejathalal, V. Govindan, A review on image reconstruction through MRI k-space data. International journal of image, graphics and signal processing 7, 42 (2015). 6. S. S. Chandra et al., Deep learning in magnetic resonance image reconstruction. Journal of Medical Imaging and Radiation Oncology 65, 564-577 (2021). 7. M. JIANG et al., Robust Reconstruction of Magnetic Resonance Images with Fine-Tuning Wasserstein Generative Adversarial Network. IEEE Access in press, (2019). 8. Y. Li, Y. Chen, N. Wang, Z. Zhang, in Proceedings of the IEEE/CVF International Conference on Computer Vision. (2019), pp. 6054-6063. 9. A. Radford, L. Metz, S. Chintala, Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, (2015). 10. I. Loshchilov, F. Hutter, Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, (2016). 11. T. M. Quan, T. Nguyen-Duc, W.-K. Jeong, Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss. IEEE transactions on medical imaging 37, 1488-1497 (2018).Figures
.
.
.
.
DOI: https://doi.org/10.58530/2023/4775