4198
Improvement of canine brain FLAIR image using super-resolution GAN1Medical Imaging AI Research Center, Canon Medical Systems Korea, Seoul, Korea, Republic of, 2College of Veterinary Medicine, Chungnam National University, Daejeon, Korea, Republic of, 3College of Medicine, Seoul National University, Seoul, Korea, Republic of, 4Magnetic Resonance Business Unit, Canon Medical Systems Korea, Seoul, Korea, Republic of
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Machine Learning/Artificial Intelligence
Most veterinary imaging has been achieved using human MRI scanners. Therefore, extensive averaging is required to obtain high-resolution images with high SNR for the animals, thereby leading to a long scan time. Veterinary MRI is typically performed under general anesthesia to minimize the level of stress and movement during image scanning. Therefore, long anesthetic conditions could affect animal normal physiology and be life-threatening, especially for patients in veterinary medical field. Here, we aimed to obtain higher image quality with short scanning time using super-resolution generative adversarial network (SRGAN) in the canine brain MRI.Purpose
FLAIR (Fluid-attenuated inversion recovery)1 is a useful MRI sequence to assess abnormal changes in both human and animals. Although awake image protocols have been recently proposed for small animals including rat and mouse, veterinary MRI is typically performed under general anesthesia to minimize the level of stress and movement during image scanning. Since the most veterinary imaging can be applied on human MRI scanners, extensive averaging is required to obtain images with high signal-to-noise ratio (SNR) in high-resolution imaging for the animals, which leads to a long scan time. Unfortunately, long anesthetic conditions could affect animal normal physiology and be life-threatening, especially for patients in veterinary medical field. The previous animal-based MRI image reconstruction studies investigated the possibility of transforming low-resolution with low-SNR images into high-resolution images using deep learning (DL) techniques2,3. The possibility of obtaining images with higher spatial resolution and SNR using DL techniques has not been examined in veterinary MRI. Here, we aimed to obtain higher image quality with short scanning time using super-resolution generative adversarial network (SRGAN)4 in the canine brain MRI with FLAIR sequence.Materials & Methods
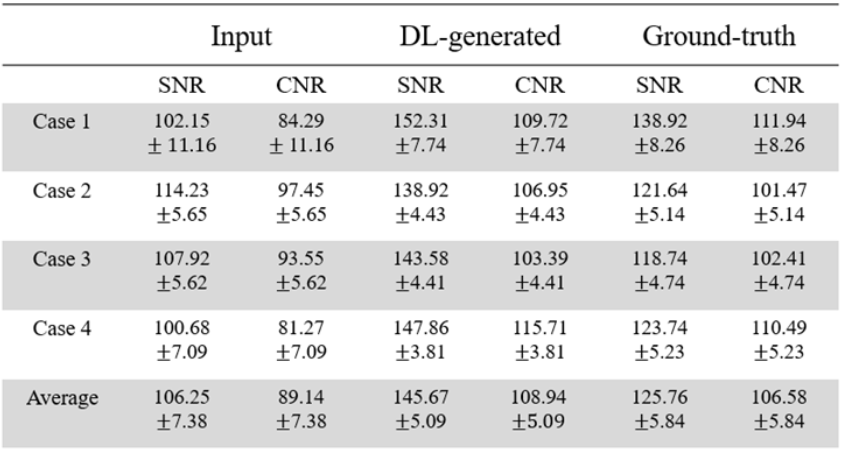
Four healthy canines (3 male and 1 female, age ranged between 3-10 years) were scanned using FLAIR sequence on a 1.5 T MRI (Canon Medical Systems, Vintage Elan, Otawara-shi, Japan) with a 16-channel flexible coil. Canines were positioned in sternal recumbency with isoflurane inhalation anesthesia. For the image training, lower spatial resolution and SNR images were used for input data while the higher spatial resolution and SNR images were used for ground-truth. Scan parameters for FLAIR imaging were as follows: TR/TE = 8000/120 ms, inversion time = 2450 ms, slice thickness = 2.5 mm, number of slices = 27, FOV = 200 mm, matrix size = 96 × 96 for input data and 192 × 192 for ground-truth, number of averages = 1 for input data and 5 for ground-truth, total scan time = 1 min 20 sec for input data and 8 min 16 sec for ground-truth.To compare input, ground-truth, and high-resolution images generated by SRGAN (DL-generated), SNR and tSNR were evaluated from the 5 slices around center at the same position. The SNR was calculated by dividing each mean value of gray matter by standard-deviation of back-ground noise (ROI; 50 mm2). CNR was measured was the difference between the mean of gray matter and that of the muscle, which was then divided by the back-ground noise.
In SRGAN algorithm, the architecture of our generator (Fig.1A) consists of 16 residual blocks. The residual block consists of convolution layers used 3 x 3 kernel, Batch Normalization, and PReLU. The architecture of our discriminator (Fig.1B) consists of LeakyReLU (α=0.2), 8 convolution layers used 3 x 3 kernel, 2 dense layers, and sigmoid. The weights of the model were initialized with Xavier and the ADAM (initial learning rate: 0.0001) optimizer was used. All training was done using a GeForce RTX 3060ti GPU with PyTorch library, 20,000 epochs.
Results
Figure.2 shows the high-resolution images generated from SRGAN (DL-generated) compared with input and ground-truth images of canine brain FLAIR. The DL-generated images demonstrated a significantly improved image quality with higher sharpness than input images. Table.1 represents the SNR and CNR values for input, DL-generated and ground-truth images from 4 canines. The SNR and CNR of input provided a similar to that of ground truth due to larger voxel size. However, the DL-generated image not only reduced the acquisition time by about 1/6 compared to the ground truth image, but also provided a higher SNR than the ground truth image (145.67±5.09 vs. 125.76±5.84).Discussion & Conclusion
In this study, we proposed the SRGAN that can increase spatial resolution with qualitative and quantitative improvements in the canine brain FLAIR images. Conventional studies have been designed to minimize Mean Square Error (MSE) between DL-reconstructed images and ground-truth. Furthermore, our SRGAN has trained the perceptual similarity metrics with functions of feature reconstruction loss and style reconstruction loss. It is still necessary to collect more data sets to improve the learning network, and further studies for generalization such as application to other contrast images and organs are required. In conclusion, DL-generated image resulted in clearer perceptually and higher image quality compared with input data.Acknowledgements
No acknowledgement found.References
1. HAJNAL, Joseph V., et al. Use of fluid attenuated inversion recovery (FLAIR) pulse sequences in MRI of the brain. Journal of computer assisted tomography, 1992, 16: 841-841.
2. MEJIA, Jose, et al. Small animal PET image super-resolution using Tikhonov and modified total variation regularisation. The Imaging Science Journal, 2017, 65.3: 162-170.
3. HAUBOLD, Johannes, et al. Contrast Media Reduction in Computed Tomography With Deep Learning Using a Generative Adversarial Network in an Experimental Animal Study. Investigative Radiology, 2022, 10.1097.
4. LEDIG, Christian, et al. Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 4681-4690.
Figures
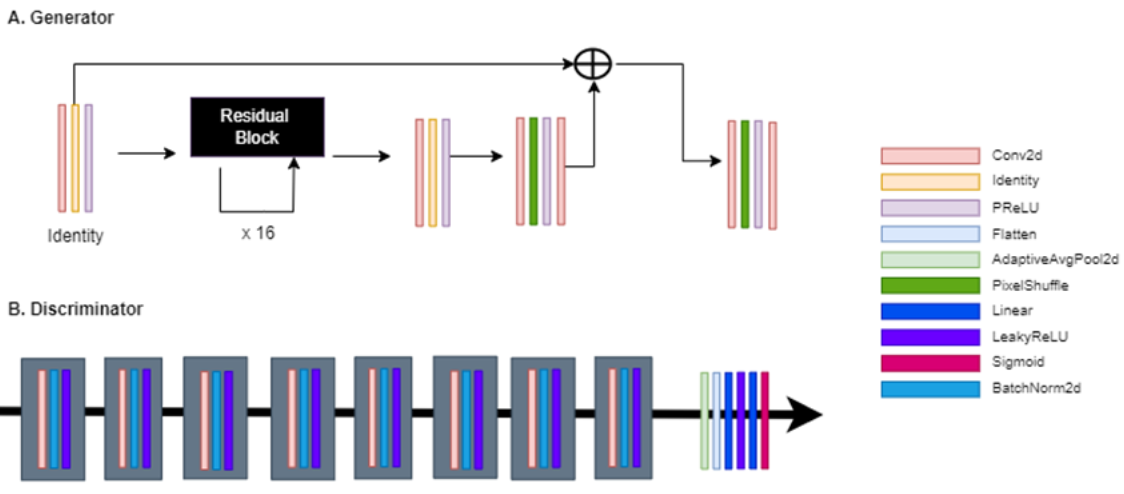
Figure 1: SRGAN architecture.
A. The Generator of SRResNet. It consists of 16 Residual blocks, PReLU, PixelShuffle, etc.
B The Discriminator of SRResNet. It consists of 8 convolution layers, AdaptiveAvgPool2d, LeakyReLU, Batch Normalization, Flatten, sigmoid, etc.
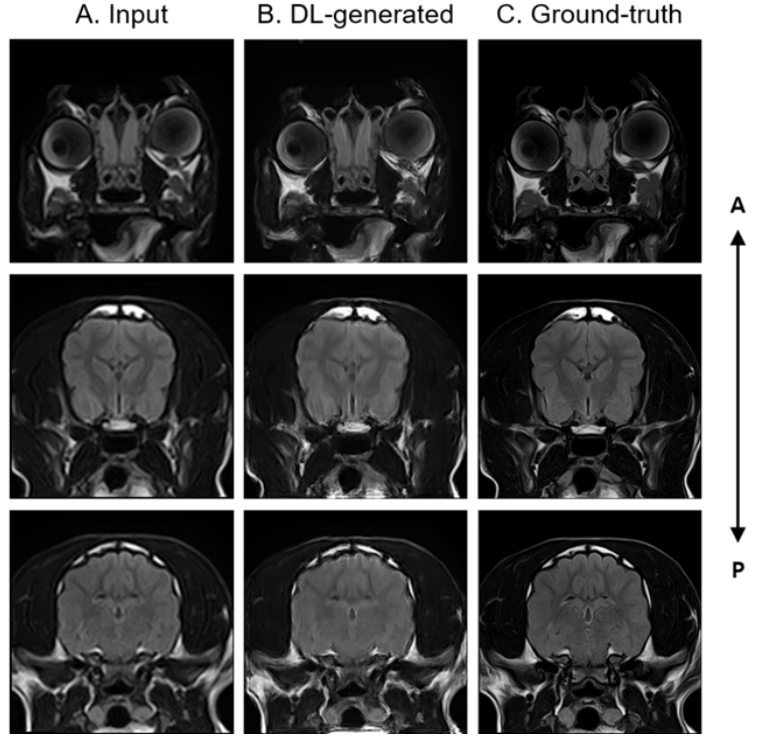
Figure 2: Generation of high-resolution image with high SNR from low-resolution input with low SNR using SRGAN