4194
Knowledge Distillation Enables Efficient Neural Network for Better Generalizability in MR Image Denoising and Super Resolution1University of Southern California, Los Angeles, CA, United States, 2Subtle Medical Inc., Menlo Park, CA, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Machine Learning/Artificial Intelligence, Knowledge Distillation
In this work, knowledge distillation (KD) is investigated to improve model generalizability for image enhancement tasks. KD can allow a 35× faster convolutional network to achieve similar performance as a Transformer based model in image denoising tasks. In addition, KD can enable a single image enhancement model for both denoising and super-resolution tasks that outperforms the conventional multi-task model trained with mixed data. KD potentially allows efficient image enhancement models to achieve better generalization performance for clinical translation.Introduction
Rapid MR exams can improve clinical workflow, but may result in image quality degradation. Previous work has shown that deep learning (DL) based denoising (DNE) and super-resolution (SRE) enhancement can restore the diagnostic quality1,2. However, it remains unclear the generalizability of DL models in a broader clinical application, especially in a low field scanner or other parts of the body other than the training domain. Knowledge Distillation (KD) is a method that trains a student model from a teacher model to approximate its performance of the teacher model3. In this study, two paradigms were investigated for model compression and/or model generalizability improvement: 1. model-based KD: transfer the better generalizability from a complex Transformer model into a light-weighted convolutional neural network (CNN) for faster inference; 2. task-based KD: transfer task-specific (e.g. DNE, SRE) expert models into a single model for multi-task image enhancement.Methods
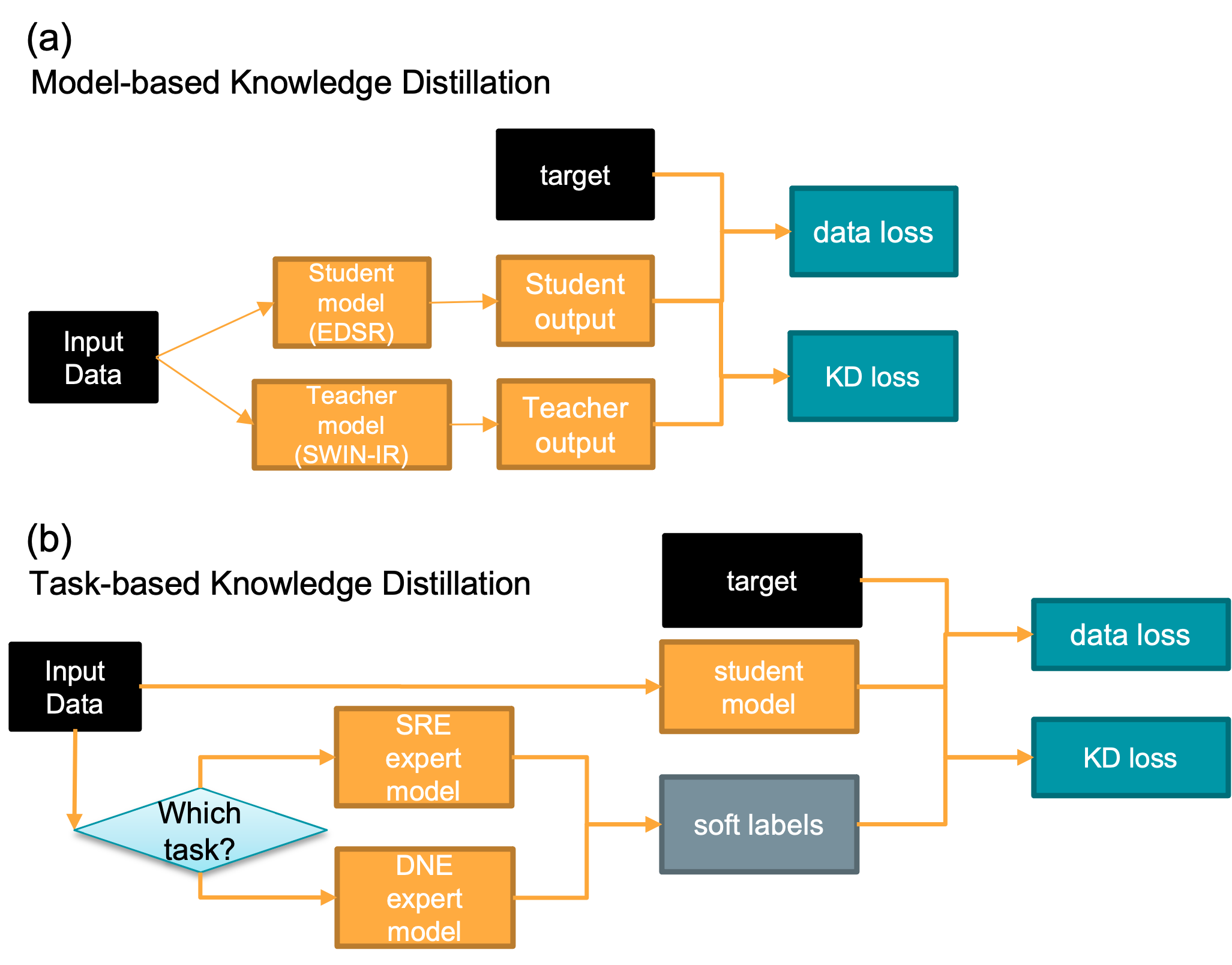
Knowledge Distillation PipelineFigure 1 illustrates the pipeline for model-based KD and task-based KD. In model-based KD, a more complex Transformer-based model (SWIN-IR) 4 was pre-trained as the teacher model to guide the CNN-based student model (EDSR) 5. In task-based KD, two expert EDSR models were firstly trained with the data pairs from one specific task (i.e. DNE or SRE), while the student model was trained with data from both tasks under the supervision of pre-trained task-specific teacher models.
MR Data
240 paired fully sampled and under-sampled (i.e. fewer phase encodings or number of averages (NSA)) brain MR images were used as training data. Non-brain (3 breast, 22 spine, and 13 musculoskeletal) images with reduced NSA from 3 different sites (22 at 1T, 3 at 1.16T, and 13 at 1.5T) were collected as test data. For multi-task performance evaluation, a separate MR brain data set was collected (8 DNE pairs: 6 at 1.5T, 2 at 3T; 8 SRE pairs: 6 at 1.5T, 2 at 3T). All data were collected under HIPAA compliance.
Model Training and Knowledge Distillation Loss
All of the model training was performed in Pytorch. Data augmentation includes random image flipping and rotation. For denoising model training, random k-space noise was added to the input images for improving generalizability. Models were trained on cropped patches. In teacher model training, a composite data loss, including L1, SSIM and perceptual loss terms, was used to measure the difference between the ground truth and the model output. In student model training, another KD loss term was introduced to measure the difference between outputs from the student model and the teacher model, shown in eq1.
$$
Loss = \alpha \times KD \; loss + (1-\alpha) \times Data \; loss \ [eq1]
$$
By adjusting $$$\alpha$$$, models with different levels of KD loss can be trained. $$$ \alpha $$$ was chosen from 0:0.25:1 in our experiments, where $$$ \alpha $$$=0 means the model was trained on only the input-reference data pairs. For task-based KD, the conditional variable to select the task-specific teacher model is produced according to the type of the training data pairs.
Performance Evaluation
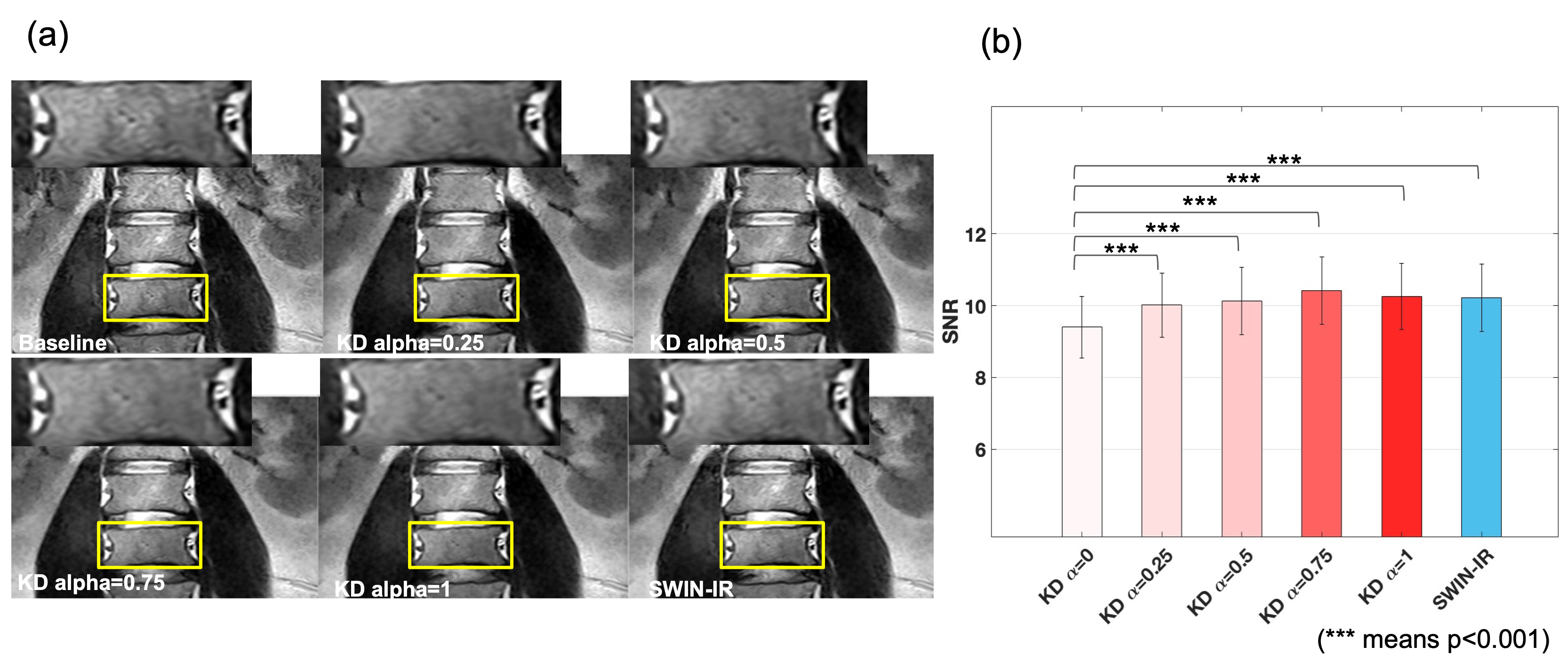
For model-based KD, 95 ROIs were drawn to evaluate SNR performance. We used a linear random effects model to compare the SNR difference between SWIN-IR and EDSR models with various levels of KD loss. We also measured SWIN-IR and EDSR model inference time on the test set 20 times, and compared the difference with paired t-test. For task-based KD, image quality was compared from different model outputs for DNE and SRE tasks.
Results and discussion
Model-based KDThe average inference speed for EDSR (0.145±0.002 sec/slice) was significantly faster than SWIN-IR (5.162±0.008 sec/slice), (35×, p<0.001). The performance of KD models was shown in Figure 2. The average SNR in the ROIs of our test MR images was 6.46±0.69. SWIN-IR can increase the SNR to 10.21±0.93. Without KD loss, the average SNR on the EDSR results was statistically lower at 9.40±0.86 (p<0.001). However, with KD loss, EDSR can achieve comparable SNR as SWIN-IR ($$$\alpha$$$=0.25, 10.01±0.89, p=0.16; $$$\alpha$$$=0.5, 10.12±0.94, p=0.53; $$$\alpha$$$=0.75, 10.41±0.95, p=0.16; $$$\alpha$$$=1, 10.25±0.92, p=0.79).
Task-based KD
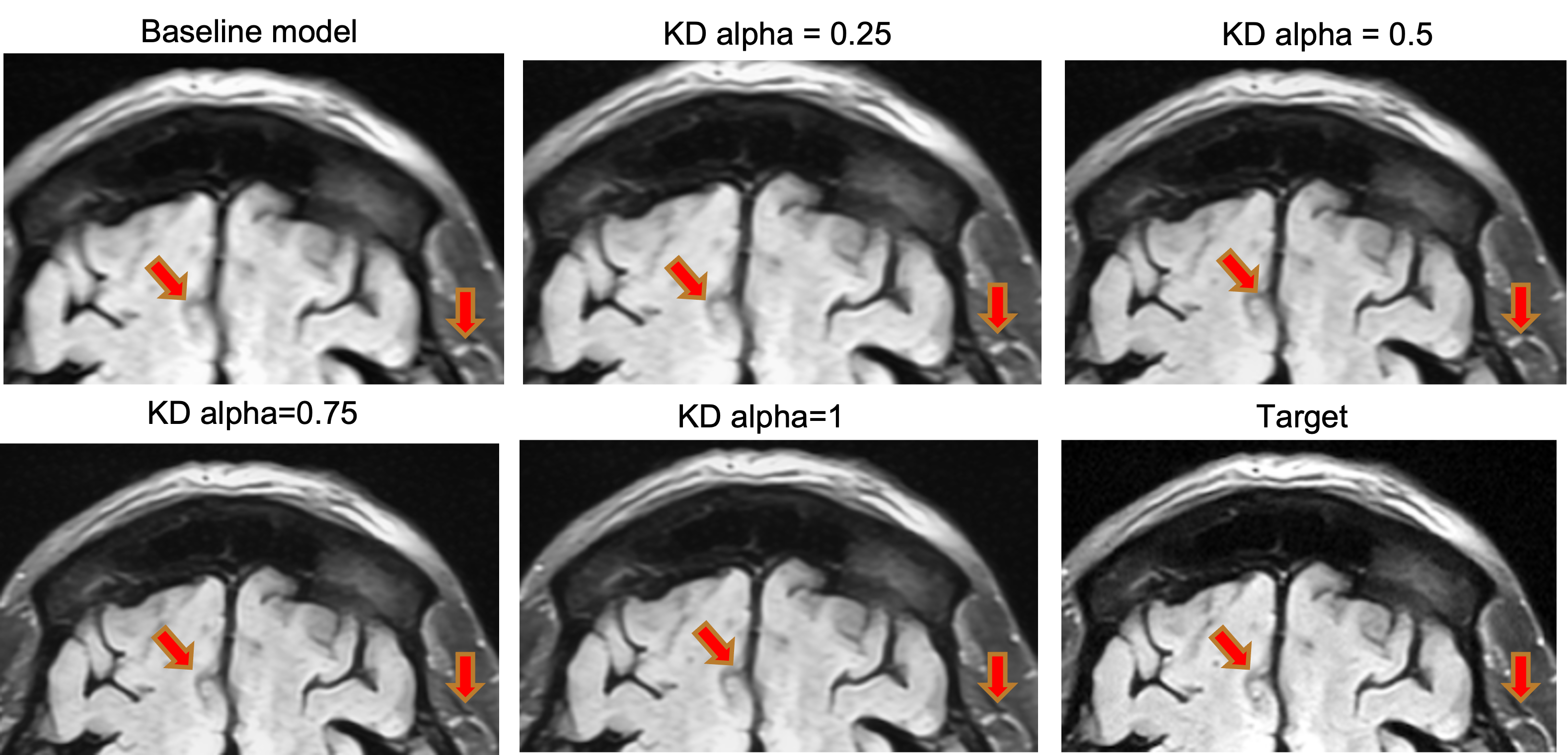
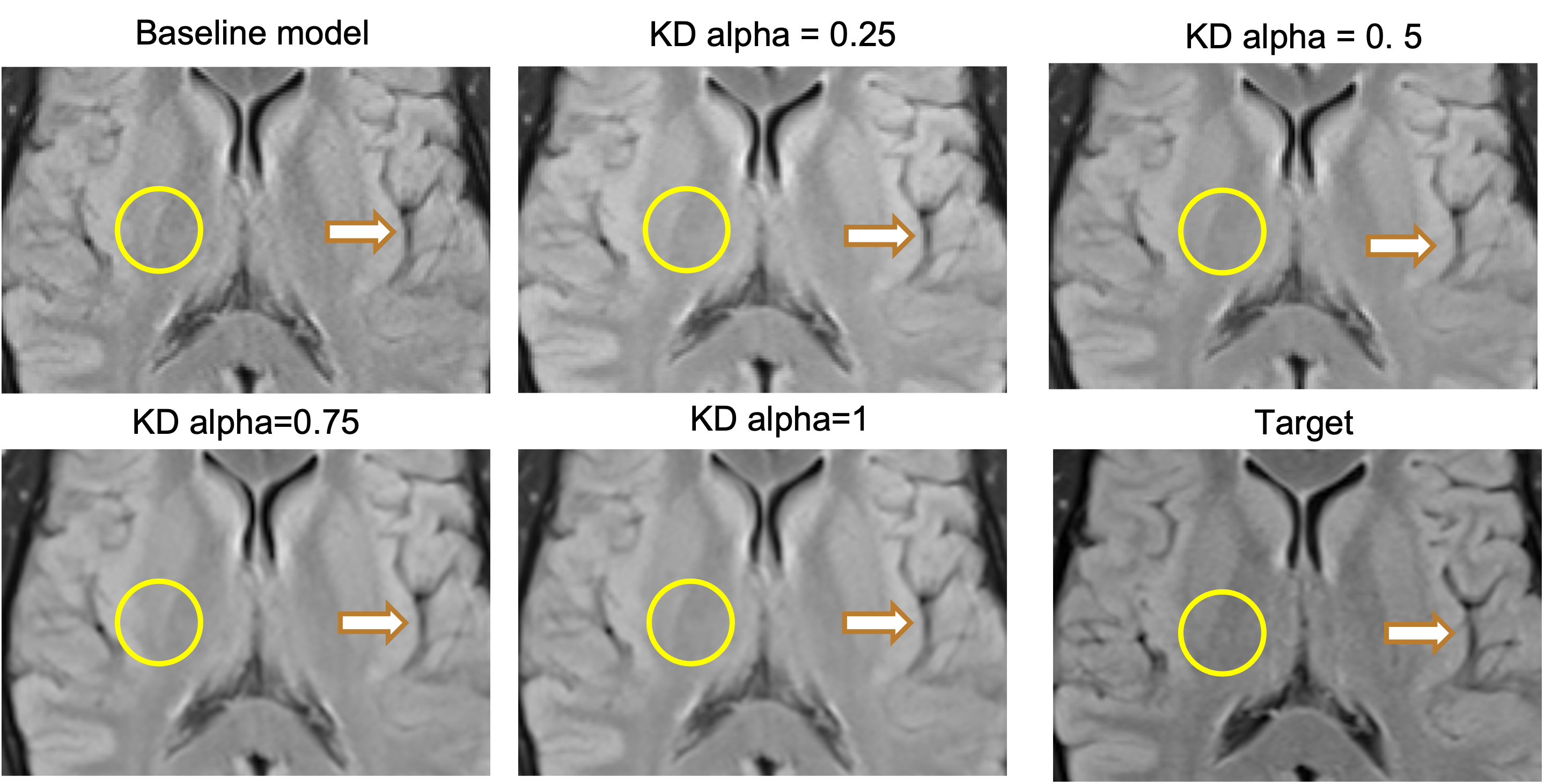
In the SRE task, the multi-task EDSR model with $$$\alpha$$$ = 0.75 showed improved boundary restoration compared to the baseline EDSR SRE expert model, and was more close to the target (Figure 3). Similarly in the DNE task, the same multi-task EDSR model outperformed the EDSR DNE expert model in terms of the residual noise suppression within the central brain region (Figure 4). This may be because soft labels provided by the expert models can eliminate the spatial intensity misalignments between the separately acquired input and label.
Conclusion
We were able to achieve a 35× faster CNN with similar performance to a Transformer based model using model-based KD. Also, we were able to achieve a multi-task image enhancement model for both denoising and super-resolution through task-based KD. KD potentially allows more efficient image enhancement models to achieve better generalization performance for clinical translation.Acknowledgements
No acknowledgement found.References
[1] Kaur, Prabhpreet, Gurvinder Singh, and Parminder Kaur. "A review of denoising medical images using machine learning approaches." Current medical imaging 14.5 (2018): 675-685.
[2] Li, Y., Bruno Sixou, and F. Peyrin. "A review of the deep learning methods for medical images super resolution problems." Irbm 42.2 (2021): 120-133.
[3] Ganesh, Prakhar, et al. "Compressing large-scale transformer-based models: A case study on bert." Transactions of the Association for Computational Linguistics 9 (2021): 1061-1080.
[4] Liang, Jingyun, et al. "Swinir: Image restoration using swin transformer." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[5] Lim, Bee, et al. "Enhanced deep residual networks for single image super-resolution." Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2017.
Figures