4039
MR reconstruction in k-space using Vision Transformer boosted with Masked Image Modeling
Jaa-Yeon Lee1 and Sung-Hong Park2
1Korea Advanced Institute of Science & Technology, Daejeon, Korea, Republic of, 2Korea Advanced Institute of Science & Technology, Daejoen, Korea, Republic of
1Korea Advanced Institute of Science & Technology, Daejeon, Korea, Republic of, 2Korea Advanced Institute of Science & Technology, Daejoen, Korea, Republic of
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Machine Learning/Artificial Intelligence, Vision Transformer, Masked Image Modeling
Masked image modeling (MIM) skim has recently been shown to pre-train vision transform (ViT) and works as an effective data augmentation. In this study, we proposed MR reconstruction algorithm using ViT with MIM in k-space. The proposed method showed better performance than the original 1D and 2D ViT. Our study showed that MIM can be used to enhance the reconstruction quality to help learn the data distribution and that combining the loss in both k-space and spatial domain reconstructs images with better perceptuality.Introduction
Magnetic resonance Imaging (MRI) is a dominantly used medical imaging technique for diagnosis because of its superb contrast on soft tissues. However, due to the long scanning time to get sufficient data for high-quality images, there are lots of effort into MR reconstruction with reduced scanning time. The Convolutional Neural Network (CNN) based algorithm has been used actively for MR reconstruction on the image domain. Currently, Vision Transformer (ViT)1 in computer vision outperforms CNN in various fields such as classification, segmentation, and super-resolution. While CNN shows excellent performance in capturing the inductive bias on adjacent pixels, it is not suitable for reconstructing k-space directly since inductive bias is less important in k-space. However, ViT can model long-range dependency between whole pixels1. It may be suitable for k-space reconstruction because it is possible to better capture the symmetrical feature of overall k-space domain relative to the origin. Recently, Masked Image Modeling (MIM) skim has been shown to pre-train ViT 2,3. Predicting the masked patches from input works as an effective data augmentation learning the data distribution. Based on this finding, we propose k-space MR reconstruction using ViT with additional MIM task in this study. In this proposed method, the additional masked prediction task from acquired data further helps to enhance the reconstruction quality.Methods
Overall ArchitectureThe ViT structure with further MIM augmentation was used for k-space reconstruction. The patch was divided into 16x16 and went into the encoder of ViT with 2-dimensional sin-cos positional encoding. The 1 convolution layer was used for patch embedding from 2 channels to 768 channels. Each encoder and decoder was composed of 4 ViT Blocks. Each ViT block had 12 numbers of multi-head attention. The encoder output vector contains contextual information across the whole k-space. For decoder input, the erased masked region was restored and an additional 2-dimensional sin-cos positional encoding was added. The decoder aims to fully reconstruct the full-sampled data with L1 loss. The overall architecture was shown in Fig.1. In the inference, the masked prediction task was neglected and overall patches of under-sampled data were used in the input of the encoder.
Masked Image Modeling
The additional masking was conducted only on high-frequency regions randomly on 25% of patches. The remained masked patches were added to the decoder input as a zero-filled vector. The network was designed to predict the masked region with L1 loss.
Training
The L1 loss between model output and fully acquired data was used in both k-space and spatial domain. The spatial domain L1 loss was added with 0.1 weight. The cosine-annealing learning rate scheduler was used with warmup 20 epochs. The model was trained during 100 epochs.
Dataset
The PD, T1, T2 contrasts images of IXI Dataset (http://brain-development.org/ixi-dataset/) were used for experiments. The input data was under-sampled with factor 4. The preserved low-frequency region was designated for 70% of the acquired data which was located in the center. The remaining 30% of acquired data was uniformly sampled in high-frequency regions in consistent intervals. The k-space data size was 256 with 2 complex channels.
Results
The results were compared with ViT with two kinds of patches, 2-dimensional and 1-dimensional along the phase-encoding line of k-space. Compared between ViT-2D and ViT-1D, the ViT-2D outperformed with an additional 0.3dB in PSNR and an additional 0.005 SSIM. To show the effectiveness of additional MIM task in reconstruction, the proposed MAE structure with 2-dimensional patches was compared. The proposed method outperformed ViT-2D with an additional 0.3dB PSNR and an additional 0.04 SSIM (Table.1). The representative images of reconstruction are shown in Fig.2. The proposed method showed better perceptuality and less aliasing artifacts compared two ViT models.Discussion
By leveraging the effect of capturing the long-range dependency, it was possible to better reconstruct the data of k-space directly. Reconstructing in k-space has been rarely used than spatial domain reconstruction because the small difference in k-space usually causes a large artifact in the spatial domain. In this study, we enhanced the performance of k-space reconstruction using additional MIM using the MAE structure. Also, by combining the loss in both k-space and spatial domain, it was available to reconstruct images with better perceptuality.Conclusion
The MR reconstruction in k-space using ViT with MAE structure showed better performance than the original ViT. It represents that MIM can be used to enhance the reconstruction quality to help learn the distribution. According to the conventional usage of MIM which has been used for the self-supervised pre-training stage, it is expected that this method is able to be developed for self-supervised MR reconstruction.Acknowledgements
No acknowledgement found.References
[1] DOSOVITSKIY, Alexey, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
[2] BAO, Hangbo; DONG, Li; WEI, Furu. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
[3] HE, Kaiming, et al. Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. p. 16000-16009.
Figures
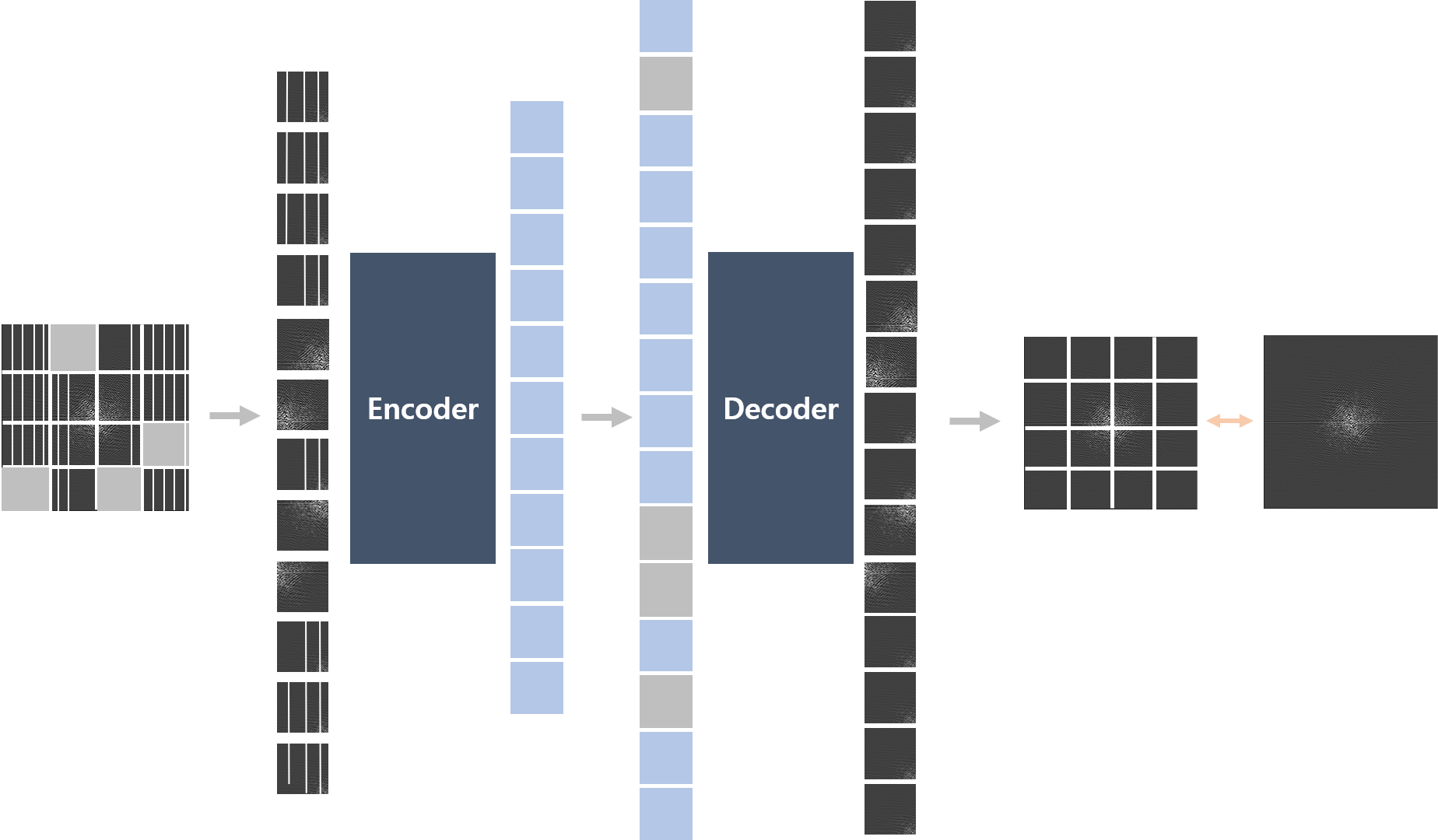
The
overall architecture.
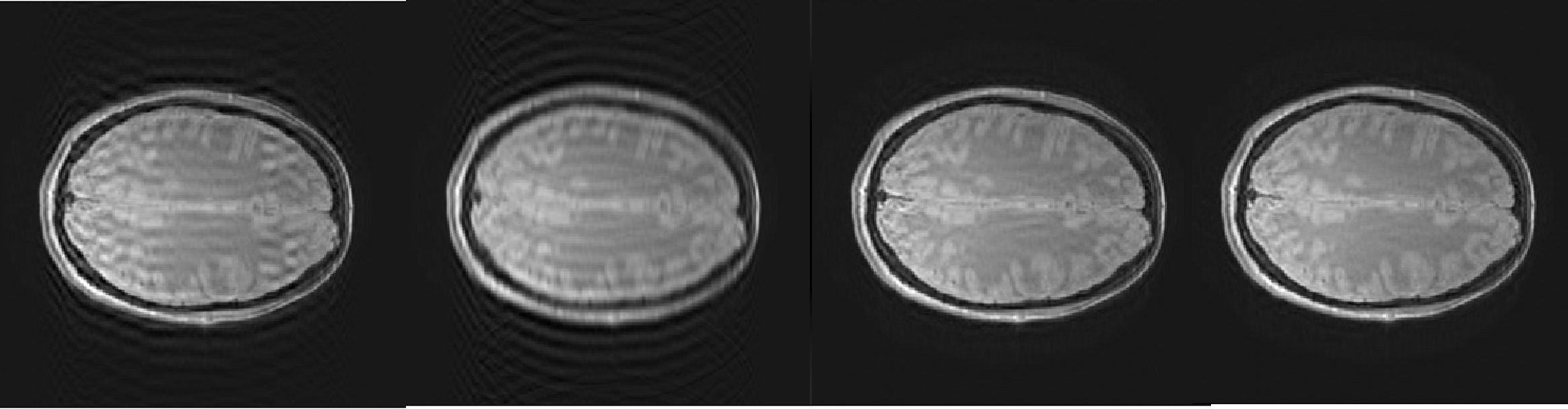
The representative images from down-sampled,
ViT-1D, ViT-2D, and Proposed output, respectively.

The
quantitative results compared with ViT-2D and ViT-1D.
DOI: https://doi.org/10.58530/2023/4039