3892
A Two-Stage Super-Resolution (TSSR) CEST Model Using Deep-Learning Reconstruction1Center for Biomedical Imaging Research, Department of Biomedical Engineering, Tsinghua University, Beijing, China
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Machine Learning/Artificial Intelligence, Super-resolution
CEST is an important source of new contrast in MRI. However, it is time-consuming to obtain high-resolution CEST images. We proposed a deep learning based Two-Stage Super-Resolution (TSSR) model for CEST images. Compared with conventional SISR or MFSR models, TSSR model can effectively utilize the correlations among slices and those among saturation offsets for CEST images. We acquired brain CEST images on 14 volunteers using a 3T clinical MR scanner. Initial results suggested that the proposed TSSR model outperformed other methods for all the evaluation indicators. Our work showed the potential in reconstruction of high-resolution CEST images from low-resolution ones.Introduction
Chemical exchange saturation transfer is a new source of MR contrast which has potentials in metabolic assessment of multiple diseases including tumors, stroke and neurological disorders [1]. Compared with conventional structural T1WI and T2WI, CEST dataset features an additional dimension of saturation frequency-offset. Therefore, the acquisition of high-resolution CEST images could be very time-consuming. Conventional super-resolution models, however, could not fully utilize the internal correlations in CEST images.Herein, we proposed a deep learning based two-stage super-resolution (TSSR) model that are more suitable for CEST images. The first and second stage of TSSR utilized the correlations among slices and frequency-offsets of images, respectively. Therefore, high-resolution images with better quality and more robustness are expected, compared with conventional network models with a single stage.
Methods
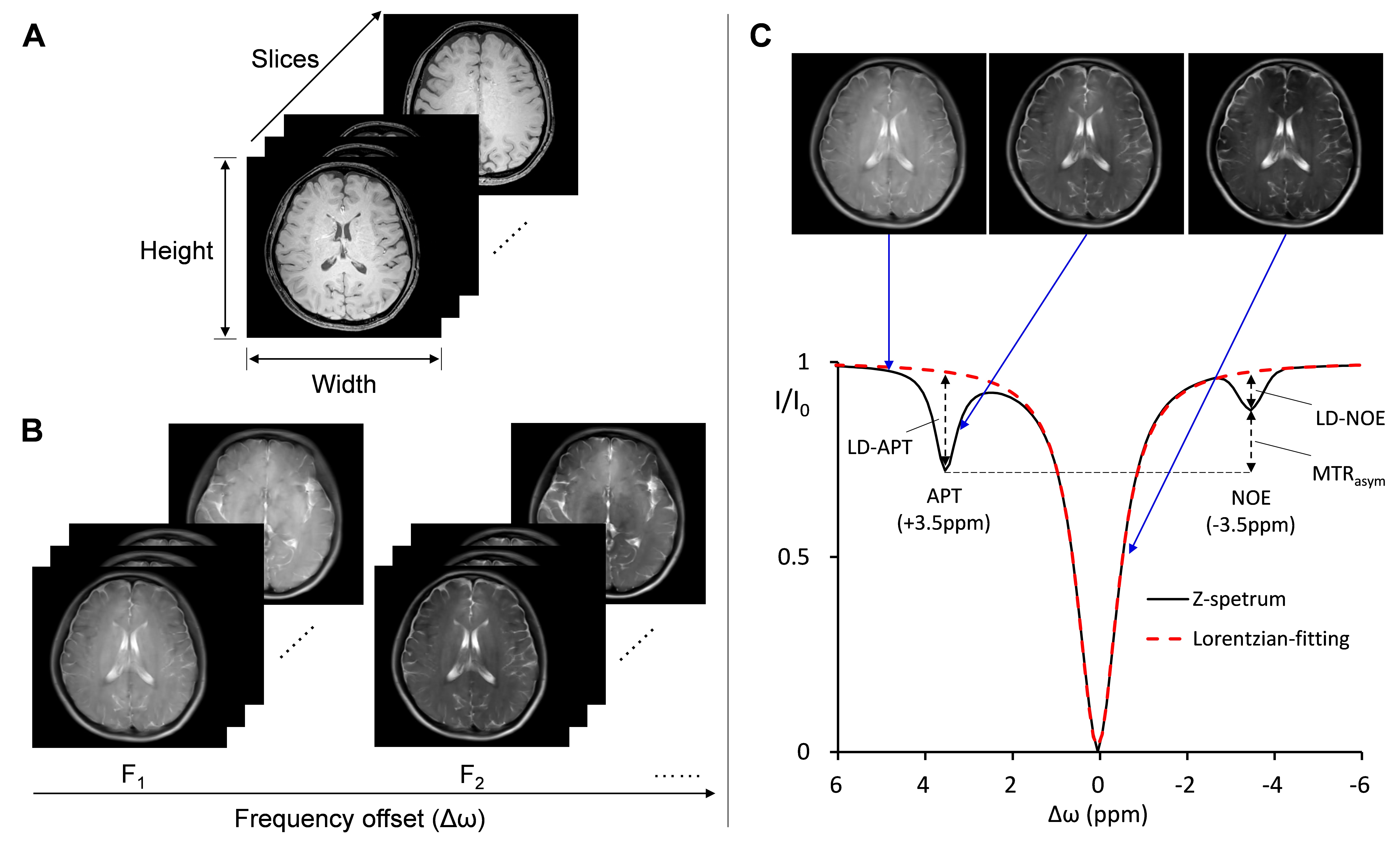
Data structure of CEST images:The data structure of CEST images is different from that of general structure images, such as T1WI and T2WI. As shown in figure 1, the data structure of 3D whole brain T1-weighted images can be described as Y*X*S. Data of CEST images has an additional frequency-offset dimension, and can be described as Y*X*S*F. Both in T1-weighted data and CEST data, images between adjacent slices have certain correlation in structure and details. As a unique characteristic of CEST data, images with different frequency-offset have similar details but different contrast. Z-spectrum and other quantitative analysis, including Lorentzian-difference and asymmetric analysis, can be constructed pixel-by-pixel for images in the same slices [2].
Network architecture:
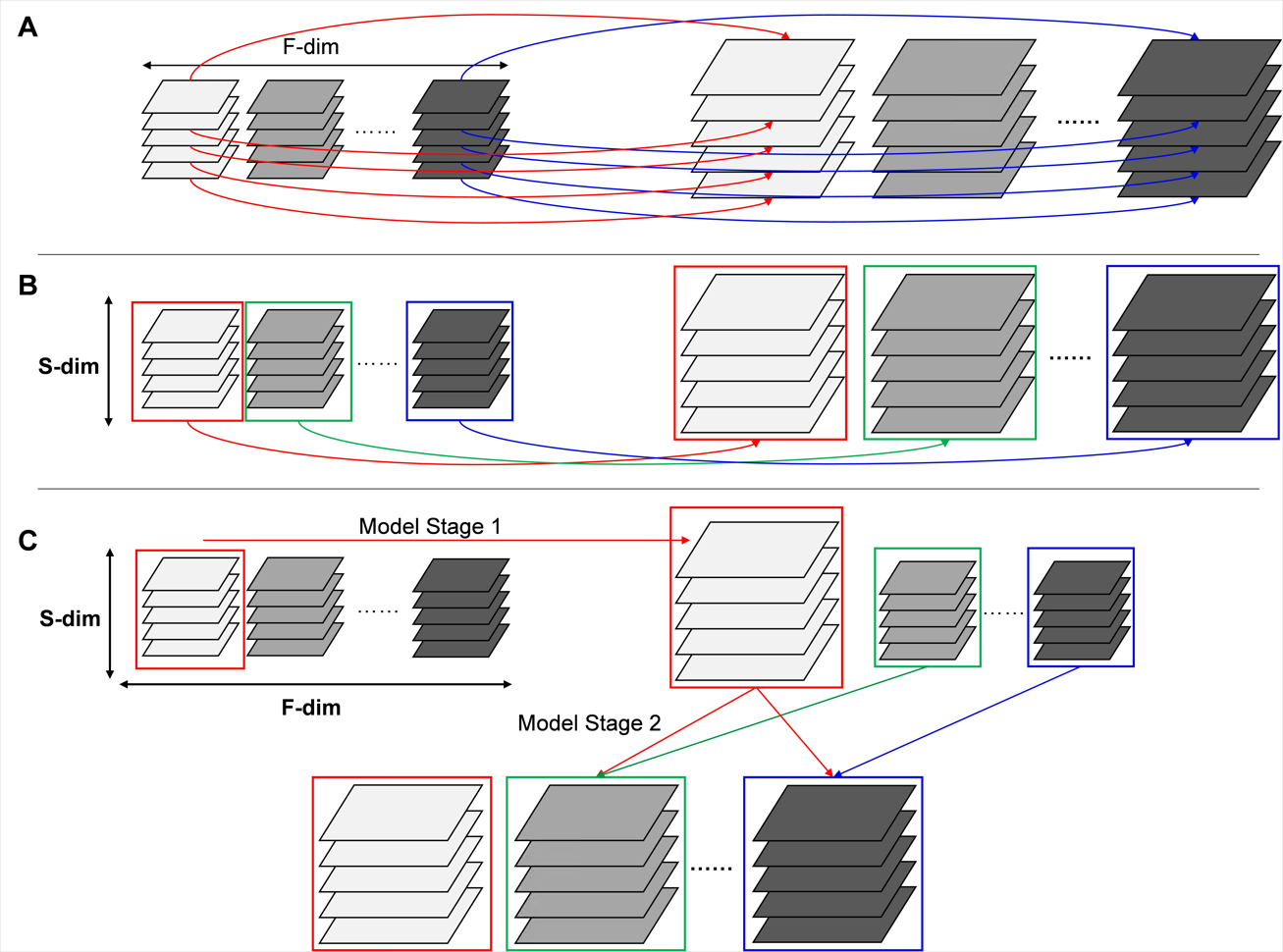
Generally, conventional super-resolution models can be divided into two categories [3]: 1) Single image super-resolution (SISR) models, which accept the input of 2D low-resolution images and generate 2D high-resolution images. 2) Multi frame super resolution (MFSR) models, which accept the input of a sequence of 2D images and output sequence with same length of high-resolution images. Most MFSR models need to calculate the optical flow field. As shown in figure 2, due to the difficulty in extracting the correlation between frequency-offsets, both SISR-only and MFSR-only models are not suitable for super-resolution task of CEST images. The proposed TSSR model effectively solved the problem by the feature fusion process in the second stage, and he first stage of TSSR model is unlimited (e.g., when reference structure images are available, it can be a style-transfer model as Pix2Pix, instead of super-resolution model). In the work, we chose the networks that had been proved in previous study for TSSR model: RSDN network (when no reference image was available) or Pix2Pix network (when T2WI existed as the reference) in stage 1, and Dual CNN network in stage 2 [4-6].
Image acquisition and establishment of dataset:
All images were obtained from a Philips Ingenia CX 3T MR scanner (Philips Healthcare, Best, The Netherlands) with a 32-channel head coil receiver. There are totally 14 cases, which are composed of two subsets. The first subset has 9 cases, and its scanning parameters are as follows: FOV=192*192mm2, resolution=0.75*0.75mm2, acquisition matrix=256*256, TR=4000ms, TE=13ms, slice thickness=4mm, number of slices=12, number of frequency-offsets=33, SENSE=1.6, B1=0.7μT. The second subset has 5 cases, with TR=3500ms, number of slices =20, and other main parameters same as the first subset. We also obtain T2-weighted high-resolution images as reference for Pix2Pix models. Low-resolution (1/4×) images input were down-sampled by only reserve the one fourth of the center of the K-space. We randomly divided the 14 cases into training, verification and test sets at the ration of 10:1:3, and obtained the final test results on the unseen test-set after training for 500 epochs.
Results and Discussion
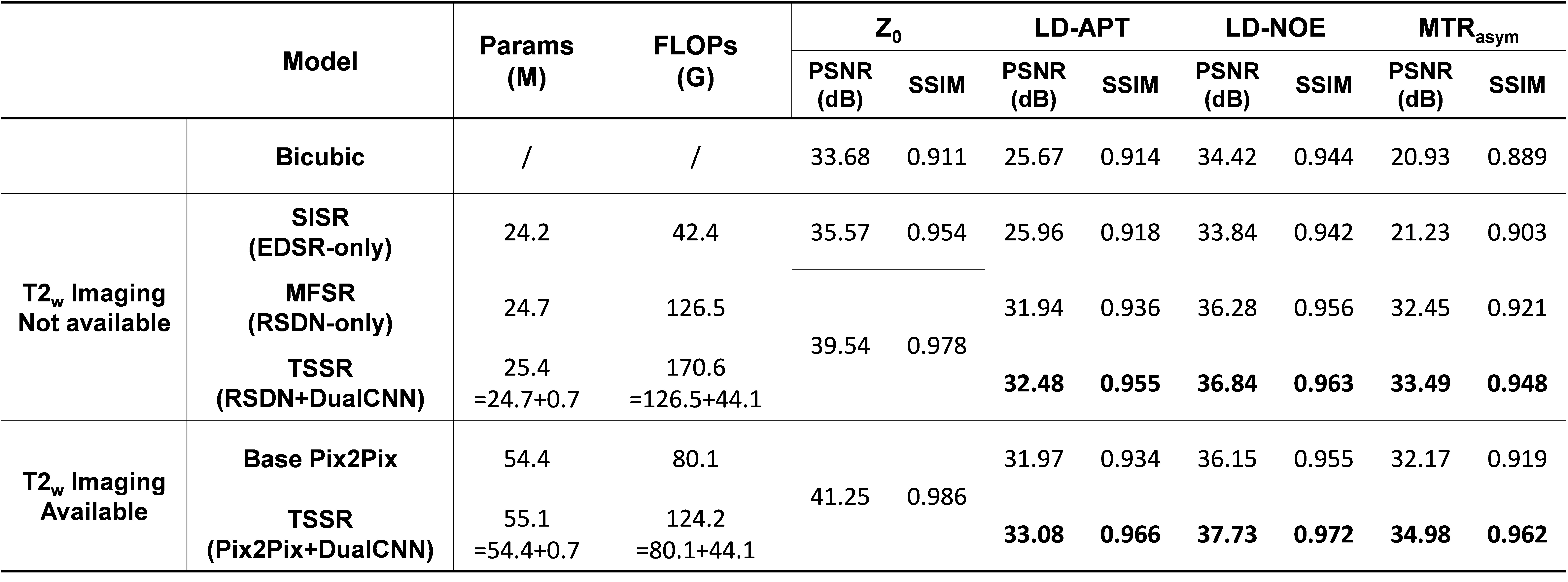
Output results in figure 3 and the evaluation indicators in table 1 showed that the proposed TSSR model outperformed under various cases of quantitative analysis, especially outstanding in LD-APT and MTRasym. It could be indicated that, due the utilization of the correlation on the frequency-offset dimension of images, TSSR model reduced the independence of error of pixels, and resulted in a significant increase in PSNR and SSIM. Another aspect of concern is that the number of parameters and FLOPs of TSSR model is only slightly more than one single model, avoiding complex network and excessive computation.Conclusion
Experimental results proved the effectiveness of the proposed TSSR model for super-resolution task of CEST images. Some detailed improvements of the network structure and more perspective experiments are on-going.Acknowledgements
Funding: This work was supported by the National Natural Science Foundation of China [grant numbers 82071914].References
[1] van Zijl, P.C.M. and N.N. Yadav, Chemical Exchange Saturation Transfer (CEST): What is in a Name and What Isn't? Magnetic Resonance in Medicine, 2011. 65(4): p. 927-948.
[2] Zhou, J.Y., et al., Review and consensus recommendations on clinical APT-weighted imaging approaches at 3T: Application to brain tumors. Magnetic Resonance in Medicine, 2022. 88(2): p. 546-574.
[3] Liu, H.Y., et al., Video super-resolution based on deep learning: a comprehensive survey. Artificial Intelligence Review, 2022. 55(8): p. 5981-6035.
[4] Takashi Isobe, et al., Video super-resolution withrecurrent structure-detail network, in: Proceedings of the European Conferenceon Computer Vision, 2020, pp. 645–660.
[5] Isola, P., et al., Image-to-Image Translation with Conditional Adversarial Networks. 30th Ieee Conference on Computer Vision and Pattern Recognition (Cvpr 2017), 2017: p. 5967-5976.
[6] Pan, J.S., et al., Learning Dual Convolutional Neural Networks for Low-Level Vision. 2018 Ieee/Cvf Conference on Computer Vision and Pattern Recognition (Cvpr), 2018: p. 3070-3079.
Figures