3765
Breast Segmentation of MRI Based on U-Net and Multi-Headed Self-Attention Mechanism1School of Aerospace Science and Technology,Xidian university, xi'an, China, 2GE Healthcare, Beijing, China, 3Guangzhou institute of technology,Xidian University, Guangzhou, China
Synopsis
Keywords: Segmentation, Breast
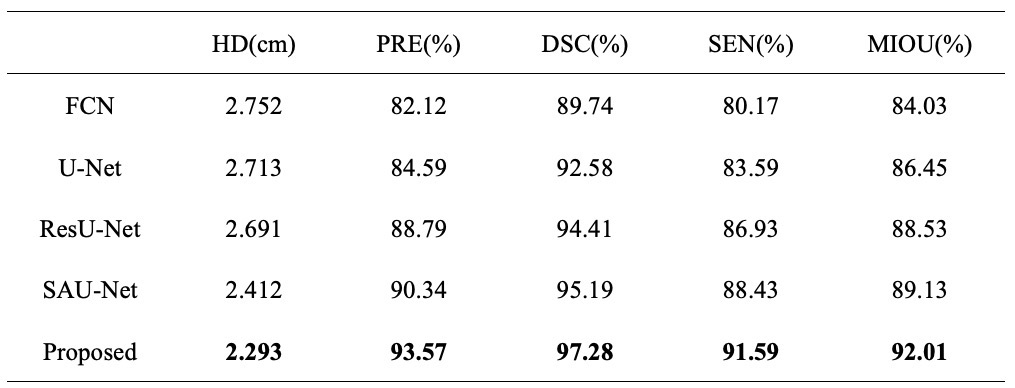
In breast MRI, overall breast segmentation is a key step in performing breast cancer risk assessment.To achieve automatic and accurate breast segmentation in breast MR images, we propose a breast segmentation model based on U-Net and multi-head self-attention mechanism, which adds global information through multi-head self-attention module and changes the cascade structure in U-Net network to pixel-by-pixel summation.On the breast MRI dataset, the proposed model can achieve accurate, effective and fast breast segmentation with an average DSC and an average MIOU of 97.28 % and 92.01 %, respectively, which are 4.7 % and 5.56 % higher compared to U-Net, respectively.Background or Purpose
Breast MRI is a valuable tool for early detection of breast cancer patients which has been becoming increasingly popular as a screening modality for patients at high risk for genetic mutations or dense breasts. Breast cancer detection is mainly divided into four steps: image preprocessing, image segmentation, image feature extraction selection, and grade classification. Among these four steps, image segmentation is the key to the subsequent other steps and determines the quality of the final results.Methods
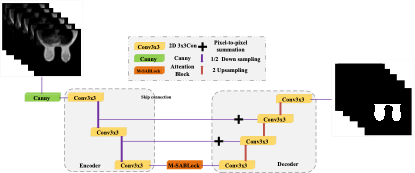
To achieve accurate segmentation of the whole breast region as well as to remedy the existing shortcomings of the whole breast segmentation, we propose a whole breast ultrasound image segmentation (MSAU-Net) based on U-Net and multi-head self-attention mechanism. Due to the small amount of edible breast MRI public datasets, the existing data were first augmented by rotation, scaling, and image enhancement to augment the number of samples. To achieve smooth and accurate edges of the segmented breasts, we normalize all the data by setting the pixel value of the breast region to 1 and the pixel value of other regions to 0. We extract the breast edge feature information by the Canny edge detection operator, and input the edge feature information into the model using convolution operation for training and learning. The MSAU-Net consists of three parts: the Canny edge detection operator, the U-Net base network structure and the multi-head self-attention module, as shown in Fig. 1.MSAU-Net network contains an Encoder, Decoder and intermediate multi-headed self-attentive module M-SABlock. The image is first passed through the Canny edge operator for edge detection, then through the encoding convolution module, which extracts the image underlying features, and then is sequentially fed into two down-sampling blocks for reducing the space size and obtaining advanced features. After each down-sampling block, the number of channels is doubled. Then, the end of the down-sampling is fed to the self-attention module to summarize the global information and produce the encoder output. The encoding module consists of a convolution, which is used to extract local information. Correspondingly, the decoder uses three up-sampling blocks to recover its corresponding feature images. The features are copied from the encoder to the decoder by implementing a down-sampling to up-sampling hopping structure through the multi-head self-attention module. Since the low-level features already contain more global information, it can be directly hopped to the decoder side, and the high-level features have less global information, and the global information can be extracted more efficiently using M-SABlock. Therefore, M-SABlock is added to the latter layer of the network encoder. At the decoder side, the feature map cascade operation of the original U-Net structure is changed to pixel-by-pixel summation, as shown in Fig. 1. The decoding module is convolutional, which first recovers the original information by decomposing the convolution, and then inputs the convolutional output to decode the features, and the up-sampled features are summed with the output of M-SABlock and passed to the next stage.
Results
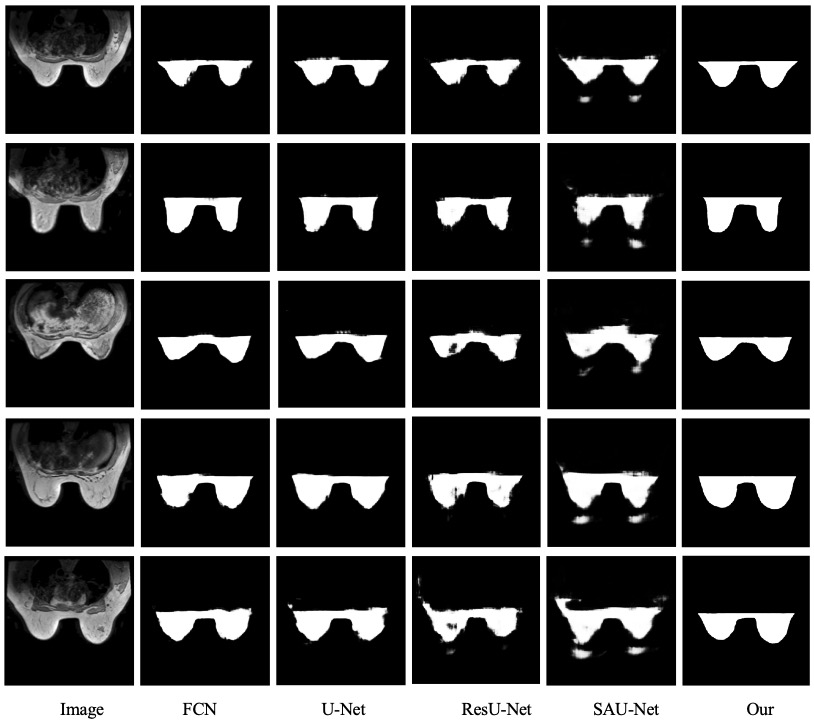
The proposed algorithm is kept with the same experimental setup as FCN [1], U-Net [2], ResU-Net [3], and SAU-Net [4] networks on the breast dataset for comparison experiments. The segmentation results of each algorithm are shown in Table 1 and Fig. 2. As shown in Table 1 and Fig. 2, the segmentation results of the proposed MSAU-Net network are significantly better than those of the FCN, U-Net, ResU-Net, and SAU-Net models. Comparing with ResU-Net, the algorithm of the proposed question improves 3.48 % and 2.87 % on the average MIOU and DSC, respectively, and compared with SAU-Net, which has better segmentation results, the algorithm of this paper also improves 3.23 % and 3.16 % on the PRE and SEN are also improved by 3.23 % and 3.16 %, respectively.Conclusions
This study proposes MSAU-Net based on U-Net and a multi-head self-attention mechanism. Firstly, the existing data are pre-processed, and the data are augmented by rotation, scaling and image enhancement to augment the number of samples, which in turn can improve the learning efficiency of the model. To achieve smooth and accurate edges of segmented breasts, breast edge feature information is extracted by Canny edge detection operator and input to the model for convolution training learning. Then the multi-head self-attention mechanism module is introduced to add global information, and the cascade structure in the original U-Net is replaced by pixel-by-pixel summation to fully extract the contextual information of the breast region; finally, the accurate segmentation of the breast region is achieved. In the future, we will work on 3D convolutional networks to realize 3D segmentation of breast.Acknowledgements
This work was financially supported by the Fundamental Research Funds for the Central Universities, under Grant [JB211312, XJS221307].
Our data from: The Second Affiliated Hospital of Xi'an Jiaotong University
References
[1] E. Shelhamer, J. Long, and T. Darrell, "Fully Convolutional Networks for Semantic Segmentation," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 4, pp. 640-651, 2017.
[2] O. Ronneberger, P. Fischer, and T. Brox, "U-Net: Convolutional Networks for Biomedical Image Segmentation," in Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Cham, N. Navab, J. Hornegger, W. M. Wells, and A. F. Frangi, Eds., 2015// 2015: Springer International Publishing, pp. 234-241.
[3] X. Xiao, S. Lian, Z. Luo, and S. Li, "Weighted Res-UNet for High-Quality Retina Vessel Segmentation," in 2018 9th International Conference on Information Technology in Medicine and Education (ITME), 19-21 Oct. 2018 2018, pp. 327-331.
[4] J. Sun, F. Darbehani, M. Zaidi, and B. Wang, "SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation," in Medical Image Computing and Computer Assisted Intervention – MICCAI 2020, Cham, A. L. Martel et al., Eds., 2020// 2020: Springer International Publishing, pp. 797-806.
Figures