2937
Self-Supervised MR Image Reconstruction with Stage-by-Stage Data Refinement1Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, 2Peng Cheng Laboratory, Shenzhen, China, 3Guangdong Provincial Key Laboratory of Artificial Intelligence in Medical Image Analysis and Application, Guangdong Provincial People’s Hospital, Guangdong Academy of Medical Sciences, Guangzhou, China
Synopsis
Keywords: Image Reconstruction, Machine Learning/Artificial Intelligence
Deep learning-based, especially fully supervised learning-based, methods have shown unprecedented performance in MR image reconstruction. Fully sampled data are utilized as references to supervise the learning process. However, it is challenging to acquire fully sampled data in many real-world application scenarios. Unsupervised approaches are required. Here, we propose an iterative data refinement method for enhanced self-supervised MR image reconstruction. Different from Yaman's self-supervised learning method (SSDU), training data in our method are refined iteratively during model optimization to progressively eliminate the data bias between the undersampled reference data and fully sampled data. Better reconstruction results are obtained.Introduction
Long scanning time has persisted to be a notorious issue that limits the application of magnetic resonance imaging (MRI). K-space undersampling followed by high-quality MR image reconstruction is one prevalent group of methods for MRI acceleration 1. Although deep learning-based MR image reconstruction methods have achieved inspiring results 2,3,4,5, these methods are mostly supervised learning methods requiring fully sampled data to supervise the learning process. However, due to patients’ physiological and physical constraints, it is challenging to acquire fully sampled data in many real-world application scenarios. Moreover, the long acquisition process of fully sampled data may lead to increased image noise or artifacts, which in turn affects the reconstruction model learning. Consequently, there are studies trying to develop unsupervised learning methods, especially self-supervised learning methods, for MR image reconstruction without utilizing any fully sampled reference data 6,7. Despite the achieved promising results, we find that there exists a training data bias issue for existing self-supervised learning methods.Specifically, for fully supervised learning-based MR image reconstruction methods, the training dataset can be written as:$$\text { Supervised training dataset: }\left\{y_{\Omega}^i, y^i\right\}_{i=1}^N$$
where $$$y_{\Omega}^i$$$ is the acquired k-space measurement with the undersampling mask $$$\Omega$$$ and $$$y^i$$$ is the fully sampled k-space reference data. Existing self-supervised methods typically divide the undersampled data into two disjoint sets 6,7. One set is treated as the input to the network and the other (or the entire undersampled data) is used as the reference to supervise the network training 6. The training dataset of self-supervised learning methods can be expressed as:
$$\text{ Self-supervised training dataset: }\left\{\tilde{y}_{\Lambda}^i,\tilde{y}^i\right\}_{i=1}^N, \text{where }\tilde{y}^i=y_{\Omega}^i$$
where $$$\Lambda$$$ is the random mask used to select the input subset.
It is clear from the descriptions of the two training datasets descriptions that there exists a data bias, which can affect the performance of self-supervised MR image reconstruction methods. By minimizing this data bias, we propose an enhanced self-supervised learning framework for MR image reconstruction.
Method
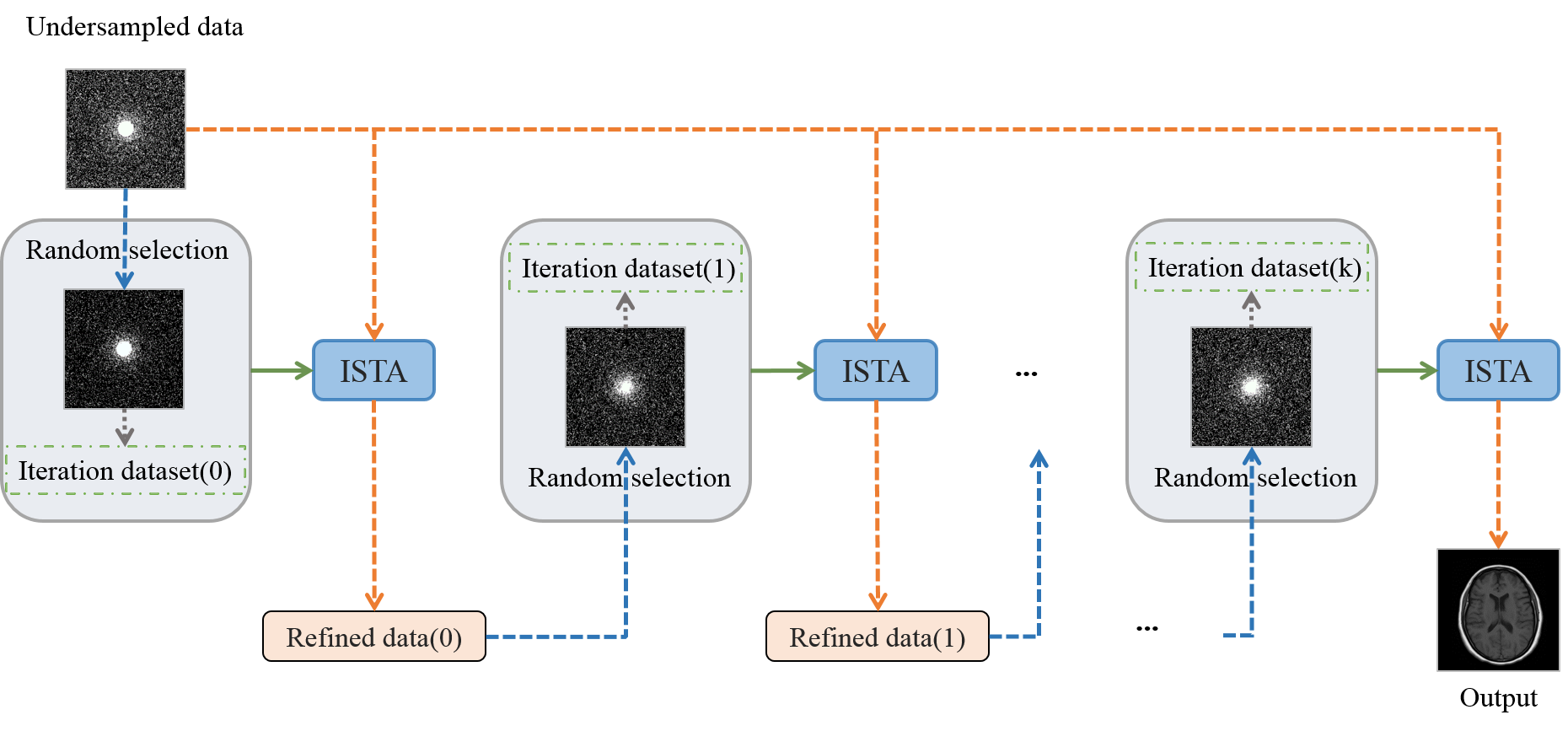
The overall pipeline of our proposed self-supervised MR image reconstruction framework is shown in Fig. 1. In our framework, the network is trained in a stage-by-stage manner. Each stage contains multiple training epochs followed by refinement of the training data. We employ ISTA as the fundamental network structure 8. The specific training details are described in the following.In the first training stage, we use the self-supervised training dataset $$$\left\{\tilde{y}_{\Lambda}^i,\tilde{y}^i\right\}$$$ to train a reconstruction model. Here, $$$\tilde{y}^i$$$ denotes the acquired undersampled data, and $$$\tilde{y}_{\Lambda}^i$$$ denotes the subset selected from $$$\tilde{y}^i$$$ using a random mask $$$\Lambda$$$. The best model in this stage $$$f_{0}$$$ is saved. Then, we utilize $$$f_{0}$$$ to refine the training data. The refined training dataset becomes $$$\left\{{f_{0}\left(\tilde{y}^i\right)}_{\Lambda},f_{0}\left(\tilde{y}^i\right)\right\}$$$. Specifically, the acquired undersampled data $$$\tilde{y}^i$$$ is input into $$$f_{0}$$$, and the output $$$f_{0}\left(\tilde{y}^i\right)$$$ is treated as the refined reference data to supervised the network training in the following stage. We keep the scanned data points unchanged during this data refinement process to ensure data consistency. Meanwhile, the input data $$${f_{0}\left(\tilde{y}^i\right)}_{\Lambda}$$$ for next stage is also modified, which is selected from $$$f_{0}\left(\tilde{y}^i\right)$$$ instead of $$$\tilde{y}^i$$$ using the same random mask $$$\Lambda$$$. $$$f_{0}\left(\tilde{y}^i\right)$$$ should be closer to the fully sampled data $$${y}^i$$$ than $$$\tilde{y}^i$$$. The data bias between self-supervised learning and fully supervised learning can be effectively decreased.
Then, similar operations are repeated for the following training stages. For example, in the second training stage, $$$\left\{{f_{0}\left(\tilde{y}^i\right)}_{\Lambda},f_{0}\left(\tilde{y}^i\right)\right\}$$$ is used to train the network, and a new best model $$$f_{1}$$$ is saved to generate the refined training data $$$\left\{{f_{1}\left(\tilde{y}^i\right)}_{\Lambda},f_{1}\left(\tilde{y}^i\right)\right\}$$$. A better self-supervised training dataset can be obtained by iteratively refining the training data. Supposing the data are refined for k stages, the final training dataset is $$$\left\{{f_{k-1}\left(\tilde{y}^i\right)}_{\Lambda},f_{k-1}\left(\tilde{y}^i\right)\right\}$$$. A largely improved self-supervised MR image reconstruction model $$$f_{k}$$$, which is progressively finetuned using the refined self-supervised training datasets, can be obtained.
Results and Discussion
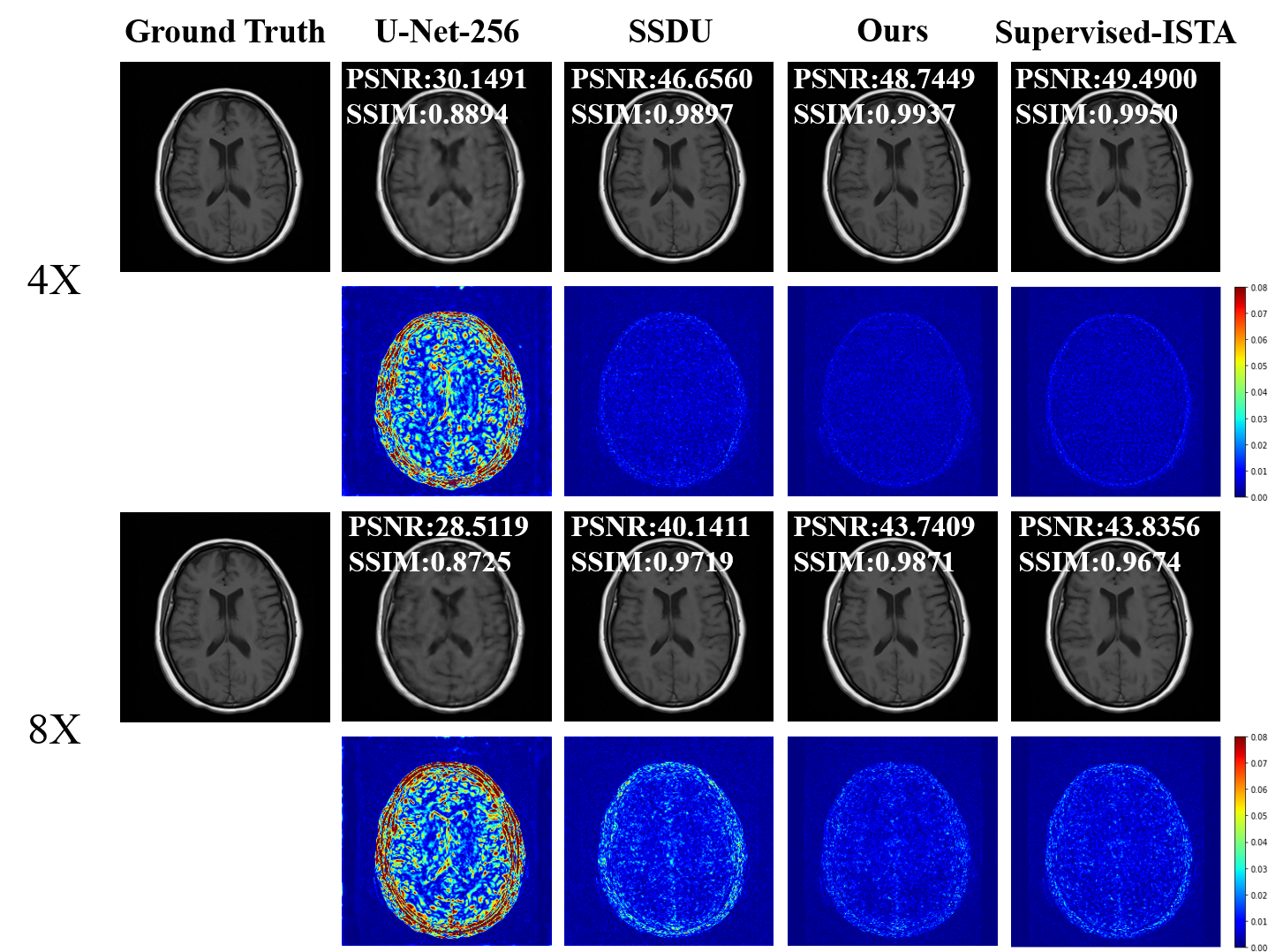
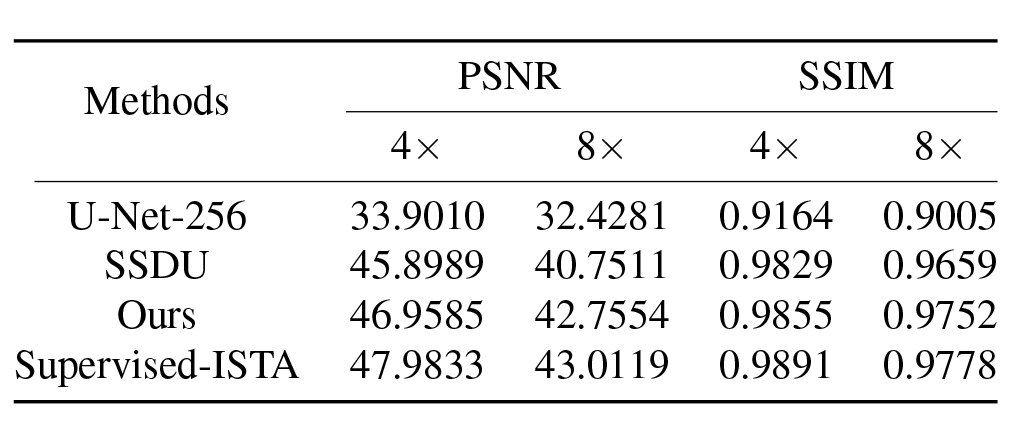
The effectiveness of the proposed method is evaluated using brain MR data from the NYK fastMRI database 9. A supervised U-Net model (U-Net-256), a self-supervised learning version of ISTA (SSDU), and a supervised learning version of ISTA (Supervised-ISTA) are implemented as comparison methods. Two acceleration rates (4× and 8×) are experimented with. PSNR and SSIM are calculated.Fig. 3 lists the results of different methods. At both acceleration rates, our proposed method generates better statistics (higher PSNR and SSIM values) than supervised U-Net-256 and self-supervised ISTA counterpart (SSDU). Furthermore, our proposed self-supervised MR image reconstruction framework achieves comparable performance to that of the supervised counterpart (Supervised-ISTA), confirming the efficacy of our proposed training data refinement method. Example reconstruction images as well as the corresponding error maps are plotted in Fig. 2. Similar conclusions can be made that our method reconstructs better MR images with lower errors than supervised U-Net-256 and SSDU. Our proposed training data refinement method can be a significant add-on to existing self-supervised MR image reconstruction models to enhance the reconstruction performance.
Conclusion
In this study, we propose a training data refinement framework for self-supervised MR image reconstruction. Our framework achieves improved MR image reconstruction with progressively refined training data without requiring fully sampled reference data during model optimization which can be very useful in clinical applications for fast MRI and MR image quality enhancement.Acknowledgements
This research was partly supported by Scientific and Technical Innovation 2030-"New Generation Artificial Intelligence" Project (2020AAA0104100, 2020AAA0104105), the National Natural Science Foundation of China (61871371,62222118,U22A2040), Guangdong Provincial Key Laboratory of Artificial Intelligence in Medical Image Analysis and Application(No. 2022B1212010011), the Basic Research Program of Shenzhen (JCYJ20180507182400762), Shenzhen Science and Technology Program (Grant No. RCYX20210706092104034), AND Youth Innovation Promotion Association Program of Chinese Academy of Sciences (2019351).References
[1] Hammernik K, Klatzer T, Kobler E, et al. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med. 2018; 79(6): 3055- 3071.
[2] Akc ̧akaya, Mehmet and Moeller, Steen and Weing ̈artner, Sebastian and U ̆gurbil, Kˆamil, “Scan-specific robust artificial-neural-networks for k-space interpolation (RAKI) reconstruction: Database-free deep learning for fast imaging,” Magnetic resonance in medicine, vol. 81, no. 1, pp. 439–453, 2019.
[3] Eo, Taejoon and Jun, Yohan and Kim, Taeseong and Jang, Jinseong and Lee, Ho-Joon and Hwang, Dosik, “KIKI-net: cross-domain convolutional neural networks for reconstructing undersampled magnetic resonance images,” Magnetic resonance in medicine, vol. 80, no.5, pp. 2188–2201, 2018.
[4] Sun, Jian and Li, Huibin and Xu, Zongben and others, “Deep ADMM-Net for compressive sensing MRI,” Advances in neural information processing systems, vol. 29, 2016.
[5] Aggarwal, Hemant K and Mani, Merry P and Jacob, Mathews, “MoDL: Model-based deep learning architecture for inverse problems,” IEEE transactions on medical imaging, vol. 38, no. 2, pp. 394–405, 2018.
[6] Yaman, Burhaneddin and Hosseini, Seyed Amir Hossein and Moeller, Steen and Ellermann, Jutta and U ̆gurbil, Kˆamil and Akc ̧akaya, Mehmet, “Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data,” Magnetic resonance in medicine, vol. 84, no. 6, pp. 3172–3191, 2020.
[7] Hu, Chen and Li, Cheng and Wang, Haifeng and Liu, Qiegen and Zheng, Hairong and Wang, Shanshan , “Self-Supervised Learning for MRI Reconstruction with a Parallel Network Training Framework,” 2021.
[8] Zhang, Jian and Ghanem, Bernard, “ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 1828–1837.
[9] Zbontar, Jure and Knoll, Florian and Sriram, Anuroop and Murrell, Tullie and Huang, Zhengnan and Muckley, Matthew J and Defazio, Aaron and Stern, Ruben and Johnson, Patricia and Bruno, Mary and others, “fastMRI: An open dataset and benchmarks for accelerated MRI,” arXiv preprint arXiv:1811.08839, 2018.
Figures