2919
DC-Swin: Deep Cascade of Swin Transformer with Sensitivity Map for Parallel MRI Reconstruction1Graduate School of Science and Technology, University of Tsukuba, Tsukuba, Japan
Synopsis
Keywords: Image Reconstruction, Machine Learning/Artificial Intelligence
Deep learning (DL) reconstruction networks are predominantly architectures that unroll traditional iterative algorithms and tend to perform better than non-unrolled models. Both types of models use convolutional neural networks (CNNs) as building blocks, but CNNs have the disadvantage of focusing on local relationships in the image. To overcome this, hybrid models have been proposed that combine CNNs with Transformers that focus on long-range dependencies. However, these hybrid transformers have been limited to non-unrolled reconstruction networks. Here, we propose an unrolled reconstruction network using a hybrid Transformer, Deep Cascade of Swin Transformer (DC-Swin), and verify that DC-Swin has high performance.Introduction
Deep learning (DL) reconstruction frameworks using unrolled networks [1–4] consist of alternating data-consistency layers and convolutional neural networks (CNNs). They have achieved higher accuracy than conventional iterative reconstruction and image-based DL reconstruction with non-unrolled architectures. While CNNs in unrolled networks are good at capturing local features, they are poor at capturing the relationship between distant parts of the image (long-range dependency) [5]. Recently, the Vision Transformer (ViT) [6] has been reported to capture this long-range dependency [7]. Furthermore, an improved version of ViT, the Swin Transformer [8], implements a local attention mechanism with shifted windows that significantly reduces the computational cost. Subsequently, combining CNN and Swin Transformers, hybrid Transformers have been reported to achieve state-of-the-art image restoration tasks [9]. They have also been applied to a non-unrolled reconstruction network [10]. Adapting the hybrid Transformer to unrolled reconstruction networks would greatly improve performance, but few such studies have been reported.Here we propose a novel unrolled reconstruction network with a hybrid Transformer, Deep Cascade of Swin Transformer (DC-Swin). DC-Swin replaces the CNN in the conventional unrolled reconstruction network, Deep Cascade of convolutional neural network (DC-CNN) [1], with a combination of CNN and Swin Transformer. We apply DC-Swin to the parallel MRI reconstruction and show that it exhibits higher reconstruction performance than the conventional DC-CNN.
Theory
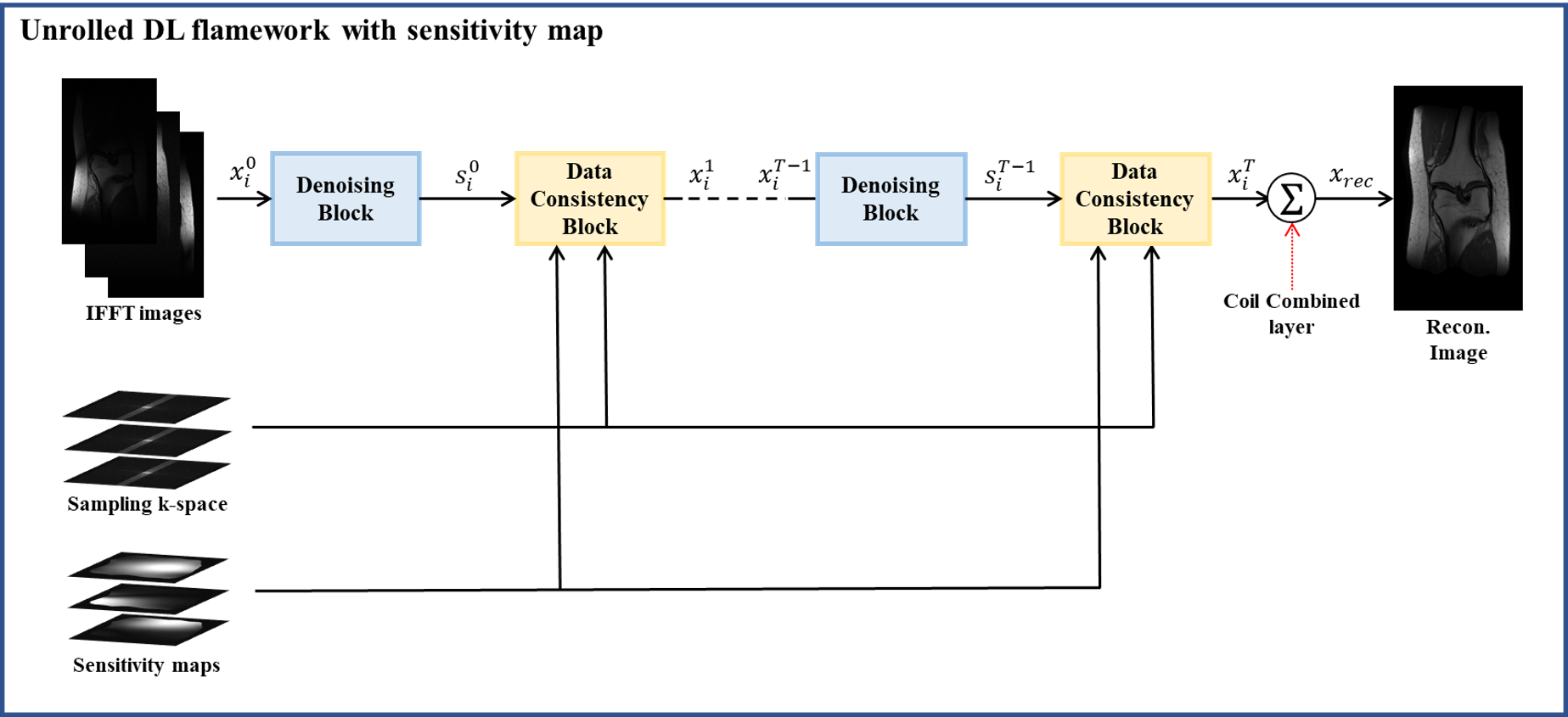
Unrolled DL flamework with sensitivity mapIn an unrolled network such as DC-CNN, the network model is constructed using a closed-form solution of the DL-based regularization model:
$$x_{rec} = \mathop{\rm argmin}\limits_x\sum_i^{N_c}{\underbrace{||y - f_{dnn}(A^H_iy|\theta)||_2^2}_{DL-based~L2~Regularization} +\underbrace{\lambda||A_ix - y||_2^2}_{Data~consistency} } (1)$$
Here, $$$x$$$ is the reconstructed image, $$$y$$$ is the under-sampling k-space data, $$$N_c$$$ is the total number of receiving coils. $$$A_i$$$ is the forward operator, $$$A_i=M_{\Omega}FC_i$$$, $$$M_{\Omega}$$$ is the sampling mask, $$$F$$$ is Fourier transform operator, $$$C_i$$$ is the coil sensitivity map for the coil $$$i$$$, and $$$f_{dnn}$$$ is the deep-neural-network (DNN) denoiser parameterized by $$$\theta$$$. Furthermore, from the closed-form solution of eq. 1, we obtain the following equations.
$$s^{t}_i = \underbrace{f_{dnn}(x^t_i|\theta)}_{DNN~Denoiser} (2)$$
$$x^{t+1}_i = \underbrace{A^H_iA_is_i^t+\frac{\lambda}{1+\lambda}A^H_iy}_{Data~consistency~block~(DCB)} (3)$$
$$x_{rec} = \underbrace{\sum_i^{N_c}x^T_i}_{Coil~combine} (4)$$
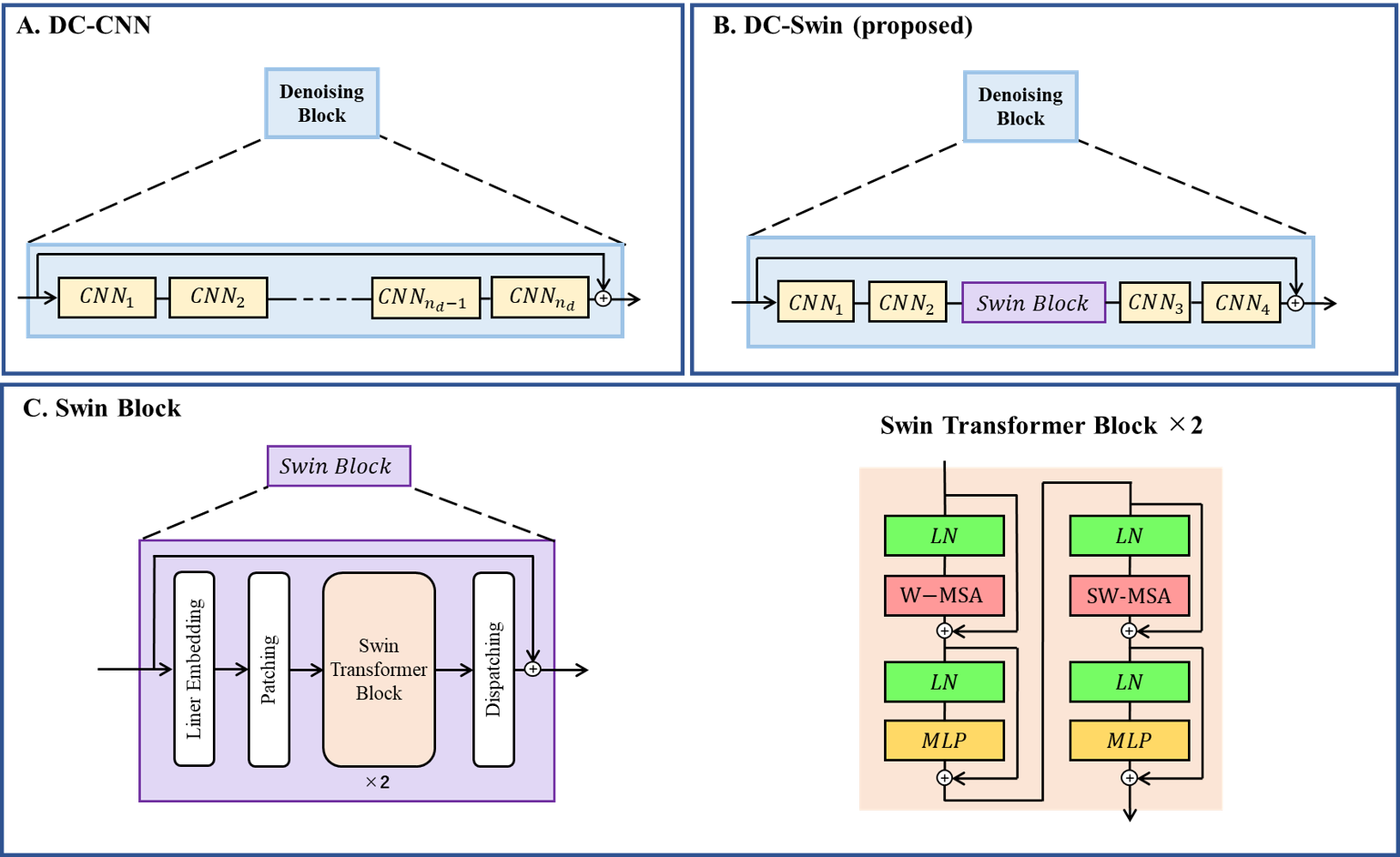
Here, and $$$x_i^t $$$ and $$$s_i^t$$$ are the output images of the data-consistency block (DCB) and the DNN denoiser, respectively, at iteration $$$t$$$ and the coil $$$i$$$. Here $$$x_i^0=A_iy$$$. Based on eqs. 2-4, we constructed an unrolled DL flamework with the alternating denoiser and DCB sandwiched together and finally with a coil-combined layer (Fig. 1). In DC-CNN, the CNN is used for the DNN denoiser (Fig. 2-A).
DC-Swin
Our proposed DC-Swin employs a hybrid architecture that combines a CNN and Swin Transformer in the DNN denoiser (Fig. 2-B). The Swin Transformer layer (Swin block) is embedded between the first two layers and the last two layers of the CNN (Fig. 2-C).
Method
NetworkIn this study, we compared the reconstruction performance between DC-CNN and DC-Swin. For DC-CNN, the CNN kernel size $$$k = 3$$$, the number of filters $$$n_f = 48$$$, the number of layers $$$n_d = 6$$$, and the number of iterations $$$T = 5$$$. For DC-Swin, $$$k = 3$$$, $$$n_f = 48$$$, $$$T = 5$$$, and the size of the attention windows were 20, 20, 10, 10, and 5 for $$$t = 1,2,3,4 $$$ and $$$5$$$, respectively.
Dataset
FastMRI [9] proton-density-weighted (PDw) 15-ch multicoil knee, and T2-weighted (T2w) 16-ch multicoil brain datasets were used. For each dataset, 1000, 200, and 200 images were used for training, validation, and testing. The k-space data was retrospectively undersampled from the fully-sampled data and used as the network input. For both the brain and knee datasets, the acceleration factor (AF) was four and the auto-calibration signal (ACS) line was 30. The sensitivity map was created with ESPIRiT [10].
Training and testing
For network training, mean square error (MSE) was used as the loss function, and Adam was used as the optimizer. The number of epochs was 50, and the initial learning rate was $$$1.0\times10^{-4}$$$ for DC-CNN and $$$3.0\times10^{-4}$$$ for DC-Swin. The weights at the epoch with the smallest MSE in the validation were used in the test. Structural similarity (SSIM) and peak signal-to-noise ratio (PSNR) were used for metrics. The Wilcoxon signed-rank test was used for statistical tests.
Results
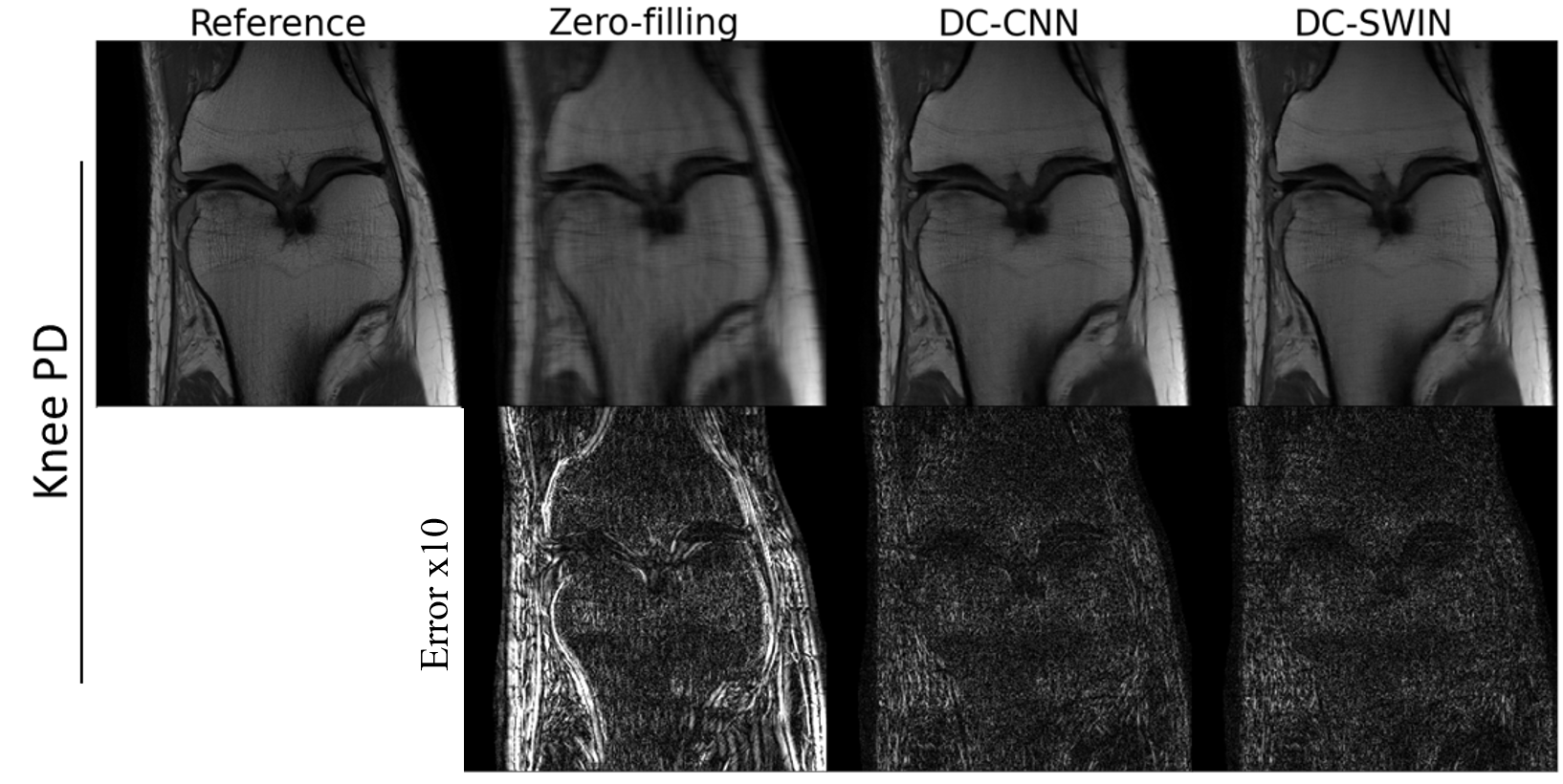
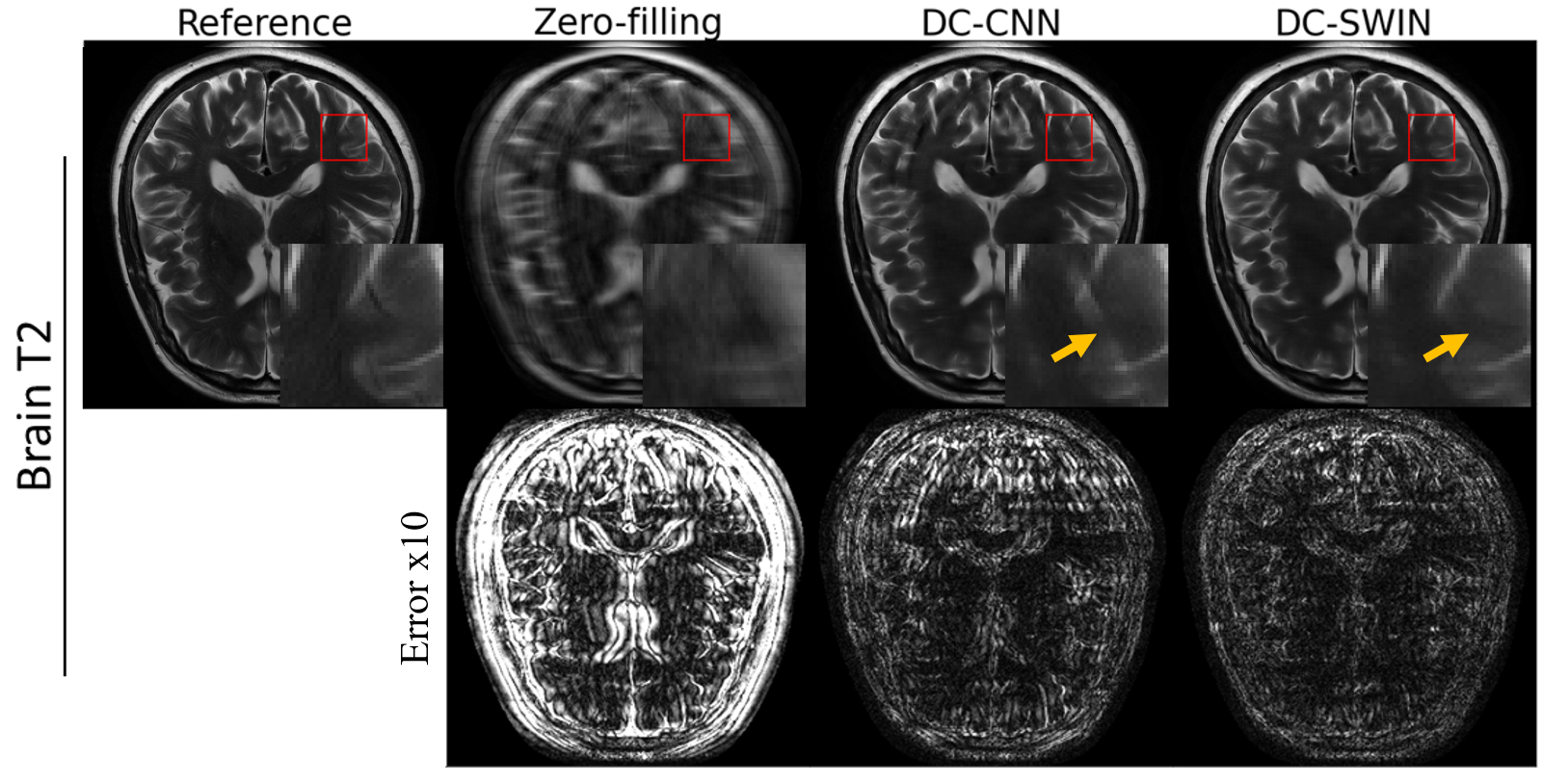
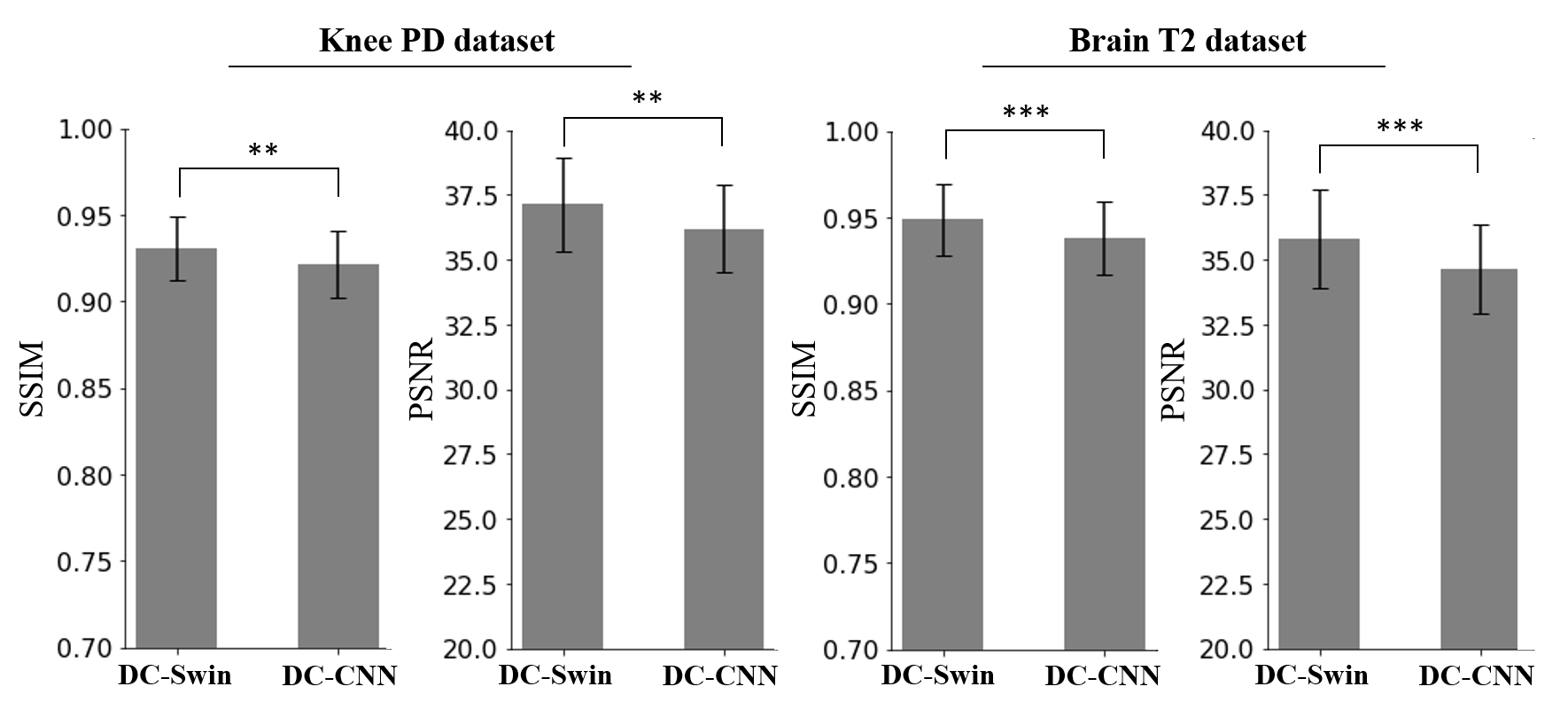
The reconstructed images for brain and knee data are shown in Fig. 3 and Fig. 4. The DC-Swin images showed less error than the DC-CNN images. For example, the artifacts indicated by the arrow in the DC-CNN image were effectively removed in the DC-Swin image. The quantitative metrics are shown in Fig. 5. The PSNR and SSIM values of DC-Swin were significantly higher than those of DC-CNN.Discussion
The results show that the proposed DC-Swin has a higher performance than DC-CNN. DC-Swin has a denoiser that combines a CNN local feature extraction layer and a Swin Block with a wide receptive field. This denoiser would be effective in removing artifacts that cannot be captured by the CNN-only denoiser. Similar performance improvement is expected when the Swin Block is applied to other unrolled networks.Conclusion
In this study, we proposed DC-Swin, which improves the unrolled reconstruction model, DC-CNN, and adds a Swin Transformer to the denoising block. We validated that DC-Swin outperformed DC-CNN. Future work includes optimization of hyperparameters and network weight reduction.Acknowledgements
No acknowledgement found.References
1. Schlemper J, Caballero J, Hajnal JV, Price AN, Rueckert D: A deep cascade of convolutional neural networks for dynamic MR image reconstruction. IEEE Trans Med Imaging 2017; 37:491–503.
2. Aggarwal HK, Mani MP, Jacob M: MoDL: Model-based deep learning architecture for inverse problems. IEEE Trans Med Imaging 2018; 38:394–405.
3. Hammernik K, Klatzer T, Kobler E, et al.: Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med 2018; 79:3055–3071.
4. Souza R, Lebel RM, Frayne R: A hybrid, dual domain, cascade of convolutional neural networks for magnetic resonance image reconstruction. In Int Conf Med Imaging Deep Learn. PMLR; 2019:437–446.
5. Chen J, Lu Y, Yu Q, et al.: TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. 2021.
6. Kolesnikov A, Dosovitskiy A, Weissenborn D, et al.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2021.
7. Raghu M, Unterthiner T, Kornblith S, Zhang C, Dosovitskiy A: Do vision transformers see like convolutional neural networks? Adv Neural Inf Process Syst 2021; 34:12116–12128.
8. Liu Z, Lin Y, Cao Y, et al.: Swin transformer: Hierarchical vision transformer using shifted windows. In Proc IEEECVF Int Conf Comput Vis; 2021:10012–10022.
9. Zbontar J, Knoll F, Sriram A, et al.: fastMRI: An open dataset and benchmarks for accelerated MRI. ArXiv Prepr ArXiv181108839 2018.
10. Uecker M, Lai P, Murphy MJ, et al.: ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magn Reson Med 2014; 71:990–1001.
Figures