2706
Brain Decoding and Reconstruction of concepts of visual stimuli from fMRI through deep diffusion models
Matteo Ferrante1, Tommaso Boccato2, and Nicola Toschi3,4
1Biomedicine and prevention, University of Rome Tor Vergata, Roma, Italy, 2Biomedicine and prevention, University of Rome Tor Vergata, Rome, Italy, 3BioMedicine and prevention, University of Rome Tor Vergata, Rome, Italy, 4Department of Radiology,, Athinoula A. Martinos Center for Biomedical Imaging and Harvard Medical school, Boston, MA, USA, Boston, MA, United States
1Biomedicine and prevention, University of Rome Tor Vergata, Roma, Italy, 2Biomedicine and prevention, University of Rome Tor Vergata, Rome, Italy, 3BioMedicine and prevention, University of Rome Tor Vergata, Rome, Italy, 4Department of Radiology,, Athinoula A. Martinos Center for Biomedical Imaging and Harvard Medical school, Boston, MA, USA, Boston, MA, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Neuroscience, brain decoding, fMRI
In vision, the brain is a feature extractor which works from images. We hypothesize that fMRI can mimic the latent space of a classifier, and employ deep diffusion models with BOLD data from the occipital cortex to generate images which are plausible and semantically close to the visual stimuli administered during fMRI. To this end, we mapped BOLD signals onto the latent space of a pretrained classifier and used its gradients to condition a generative model to reconstruct images. The semantic fidelity of our BOLD response to visual stimulus reconstruction model is superior to the state of the art.Introduction
In computational neuroscience, "Brain decoding" refers to the attempt to reconstruct the stimulus (e.g. images/sounds) that generated brain activity using neurophysiological data (e.g. fMRI) only. Our hypothesis is that the visual cortex acts as a deep nonlinear projector into a space of abstract features that describes and summarizes an image’s concept and content. In this paper, we aimed to synthesize images which contain the same semantic content as the stimuli presented during the fMRI experiment. We focused on deep diffusion models (Ho et al., 2020), which are deep generative models that learn how to reverse the diffusion process. In other words, they are trained to reconstruct denoised version of images perturbed by noise. The amount of noise depend on the “time” of the diffusion process, so images with higher t are more perturbed. After training, the model is applied iteratively T times, starting from noise to generate a plausible image.Methods
We used the Generic Object Decoding Dataset (Horikawa & Kamitani, 2017), where 4 subjects saw 1200 ImageNet images from 150 object categories during a training session. In a test session, 50 images from 50 object categories (different from the training categories) were each presented 35 times. Each stimulus presentation lasted for 9 s, and BOLD (TR=3s, voxel size=3 mm3) data were acquired for a total of 12 hours per subject using a 3T Siemens MAGNETOM Trio A Tim scanner with an interleaved T2*-weighted gradient-EPI sequence to acquire the whole brain. The data was preprocessed through motion correction and registration to the anatomical T1 image using SPM5 software and normalization as percentage variation of the average signal for each voxel in a run. Finally, a mask over the visual cortex (VC) provided by authors of the dataset using localizer and retinotopical experiments was used to select about 4000 voxels for each subject. To account for the hemodynamic response, the signal relative to a stimulus presentation was averaged in time for the 3 subsequent TR (9s) and delayed by three seconds from the onset of the stimulus itself. When creating a test set, the signal obtained for the 35 repetitions of the visual stimuli was also averaged.For each image shown (i.e. stimulus) we extracted a feature vector from the last convolutional layer of a Resnet50 architecture, and we trained a Ridge Regression model to predict the feature vector from the BOLD signals while optimizing the regularization parameter over a random 10% of the training reserved as validation set. The best root mean squared error (RMSE) was found using alpha=1000. We observed that the RMSE in the validation set (0.21) was significantly lower than the average Euclidian distance in feature space in ImageNet (17.6), supporting the hypothesis that fMRI data from the visual cortex can be linearly mapped on the latent space of image features generated by a pretrained convolutional neural network (ResNet50) using optimized ridge regression. From this latent space, estimated image features from brain activity are classified using either a pretrained linear classifier or a k-Nearest Neighbors algorithm over a subset of the ImageNet latent space. We then employed this information to condition, through classifier guidance a deep latent diffusion model (with U-net as underlying architecture) to reconstruct the visual stimuli from fMRI data. Here we employed the implementation of Stable Diffusion (Saharia et al., 2022) and the API and pretrained models provided by HuggingFace (Wolf et al., 2020), which are based on a latent diffusion model coupled with a transformer based architecture for conditioning. In this way the output of the classification can be used as conditioning for the image generation model through the pretrained transformer.. Finally, we used the Wu-Palmer (WUP) distance as a metric to evaluate semantic overlap between predicted categories from brain activity and target ones. WUP is a normalized [0,1] metric which estimates similarity as a function of distance to the common root in the WordNet semantic graph (Higher WUP = higher correlation).
Results
Our pipeline recreates high-resolution images (see Figures) which bear striking visual as well as semantic similarity to the images which were presented to the subjects under fMRI. This was true even in the presence of stimuli from classes different from the ones included in the training set. We found, on average, a WUP coefficient of 0.83 0.05 for the training set and 0.55 0.06 for the test set. Just to have a comparison, the WUP coefficient between “apple” and “pear” is 0.91, “apple” and “food” is 0.462. Visual evaluation reveals a semantic reconstruction quality that matches or outperforms all similar architectures.Conclusions
Our pipeline starts from processed BOLD data related to a stimulus, maps them into a latent space through the Ridge Regression, uses the predicted image features to pick the most probable classification labels according to the linear classifierand the kNN algorithm and use them to condition the generation of the final image. Our model can decode and reconstruct visual stimuli from elicited BOLD response only with visual accuracy which is superior to the state of the art.Acknowledgements
Part of this work is supported by the EXPERIENCE project (European Union’s Horizon 2020 research and innovation program under grant agreement No. 101017727)
Matteo Ferrante is a Ph.D. student enrolled in the National PhD in Artificial Intelligence, XXXVII cycle, course on Health and life sciences, organized by Università Campus Bio-Medico di Roma.
References
Gaziv, G., Beliy, R., Granot, N., Hoogi, A., Strappini, F., Golan, T., & Irani, M. (2022). Self-supervised Natural Image Reconstruction and Large-scale Semantic Classification from Brain Activity. NeuroImage, 254(April 2021), 119121. https://doi.org/10.1016/j.neuroimage.2022.119121 Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 2020-Decem(NeurIPS 2020), 1–25. Horikawa, T., & Kamitani, Y. (2017). Generic decoding of seen and imagined objects using hierarchical visual features. Nature Communications, 8(May), 1–15. https://doi.org/10.1038/ncomms15037 Mozafari, M. (2020). Reconstructing Natural Scenes from fMRI Patterns using BigBiGAN. 9206960, 1–8. https://doi.org/10.1109/IJCNN48605.2020.9206960 Ozcelik, F., Choksi, B., Mozafari, M., Reddy, L., & VanRullen, R. (2022). Reconstruction of Perceived Images from fMRI Patterns and Semantic Brain Exploration using Instance-Conditioned GANs. http://arxiv.org/abs/2202.12692 Ren, Z., Li, J., Xue, X., Li, X., Yang, F., Jiao, Z., & Gao, X. (2021). Reconstructing seen image from brain activity by visually-guided cognitive representation and adversarial learning. NeuroImage, 228. https://doi.org/10.1016/j.neuroimage.2020.117602 Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E., Ghasemipour, S. K. S., Ayan, B. K., Mahdavi, S. S., Lopes, R. G., Salimans, T., Ho, J., Fleet, D. J., & Norouzi, M. (2022). Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. http://arxiv.org/abs/2205.11487 Shen, G., Dwivedi, K., Majima, K., Horikawa, T., & Kamitani, Y. (2019). End-to-end deep image reconstruction from human brain activity. Frontiers in Computational Neuroscience, 13, 1–24. https://doi.org/10.3389/fncom.2019.00021 Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Le Scao, T., Gugger, S., … Rush, A. (2020). Transformers: State-of-the-Art Natural Language Processing. 38–45. https://doi.org/10.18653/v1/2020.emnlp-demos.6Figures
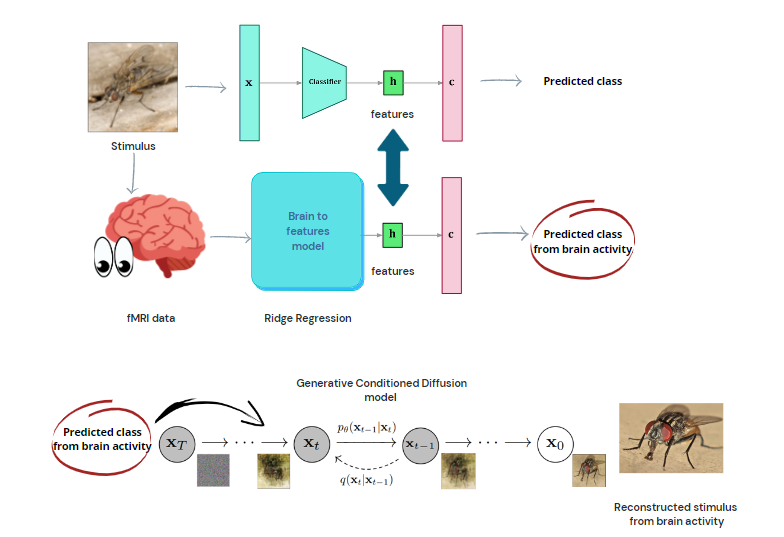
Diagram
of the reconstruction pipeline. Image features are extracted from a pretrained architecture,
and a Ridge Regression model is trained to predict these features from BOLD
activity. Through classifying over the predicted features, a generative model
is conditioned for image generation.

Examples of generated images. First column: real
visual stimuli. Other columns: reconstruction from our model

Examples of reconstructions for a test set
composed only of unseen classes. Feature mapping allows our model to generate
contextually similar images. match the context. First column: real visual
stimuli. Other columns: reconstruction from our model

Comparison
between results on brain decoding. First column is the shown stimuli, other
columns are reconstruction from fMRI.(Gaziv et al.,
2022; Mozafari, 2020; Ozcelik et al., 2022; Ren et al., 2021; Shen et al.,
2019)
DOI: https://doi.org/10.58530/2023/2706