1674
Multi-modal fusion with joint conditional transformer for grading hepatocellular carcinoma1School of Medical Information Engineering, Guangzhou University of Chinese Medicine, Guangzhou, China, 2First Clinical Medical College, Guangzhou University of Chinese Medicine, Guangxhou, China, 3Department of Radiology, Guangdong Provincial People’s Hospital, Guangzhou, China, 4Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China
Synopsis
Keywords: Cancer, Machine Learning/Artificial Intelligence
Multimodal medical imaging plays an important role in the diagnosis and characterization of lesions. Transformer pays more attention to global relationship modeling in data, which has obtained promising performance in lesion characterization. We propose a multi-modal fusion network with jointly conditional transformer to realize adaptive fusion of multimodality information and mono-modality feature learning constrained by other modal conditions. The experimental results of the clinical hepatocellular carcinoma (HCC) dataset show that the proposed method is superior to the previously reported multimodal fusion methods for HCC grading.Introduction
Hepatocellular carcinoma (HCC) is the third most common cause of cancer death in the world. The preoperative knowledge of pathological grade of HCC is of great significance to the management of patients and prognosis prediction. Contrast-enhanced MR has been demonstrated to be a promising tool for diagnosing and characterizing HCC, especially the combination of multimodal medical images for HCC grading1. Although the information between or within modalities are considered in previous research2-4, the effective combination of these information has not been explored. In addition, the information of other modalities should be consistent with the learning objectives of the mono-modality. These should be used as conditions to constrain other modalities to focus on this position to obtain the connection between modalities. By controlling the input mode of self-attention, transformer can simply realize the learning of the specificity within modality and the correlation between modalities5. Therefore, we propose a multi-modal fusion network with jointly conditional transformer (M-JCT network) for grading HCC.Materials and Methods
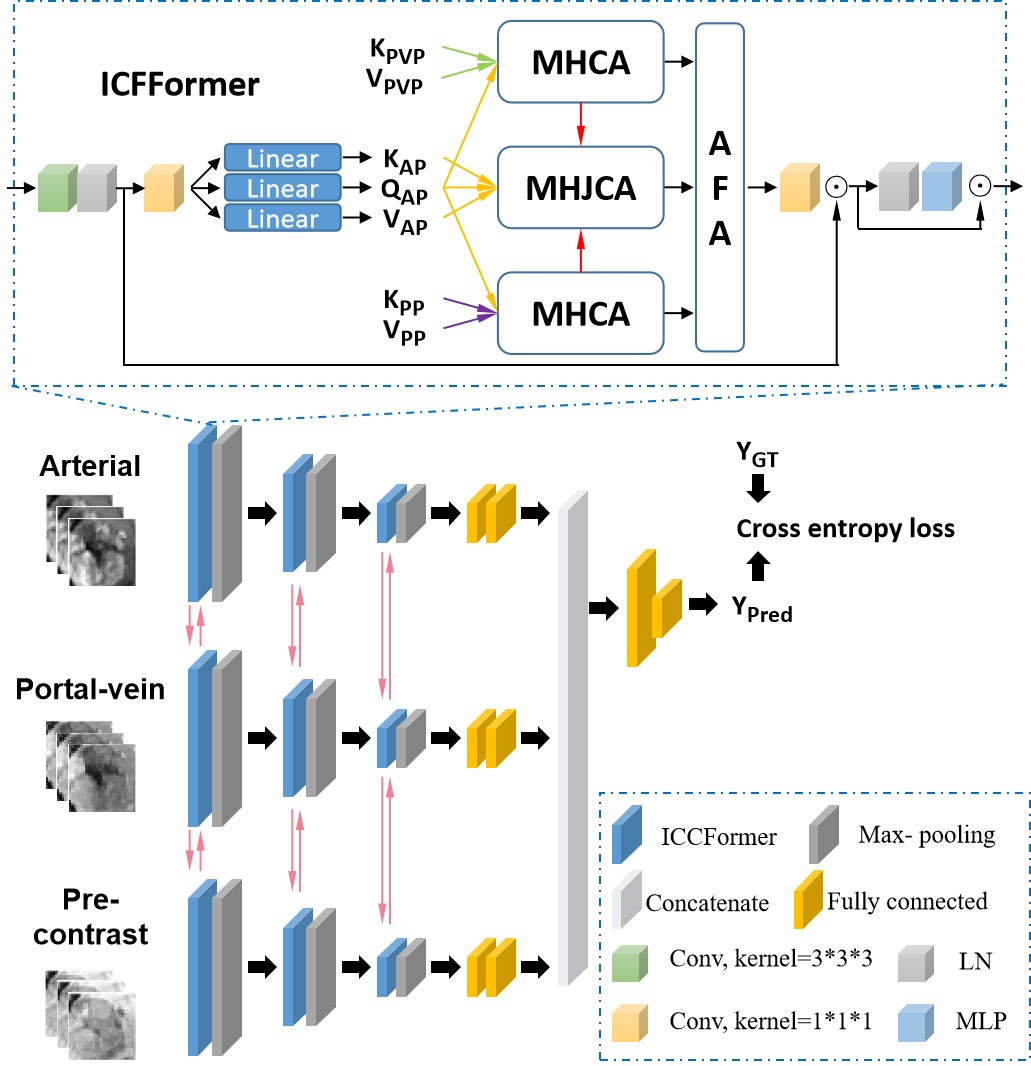
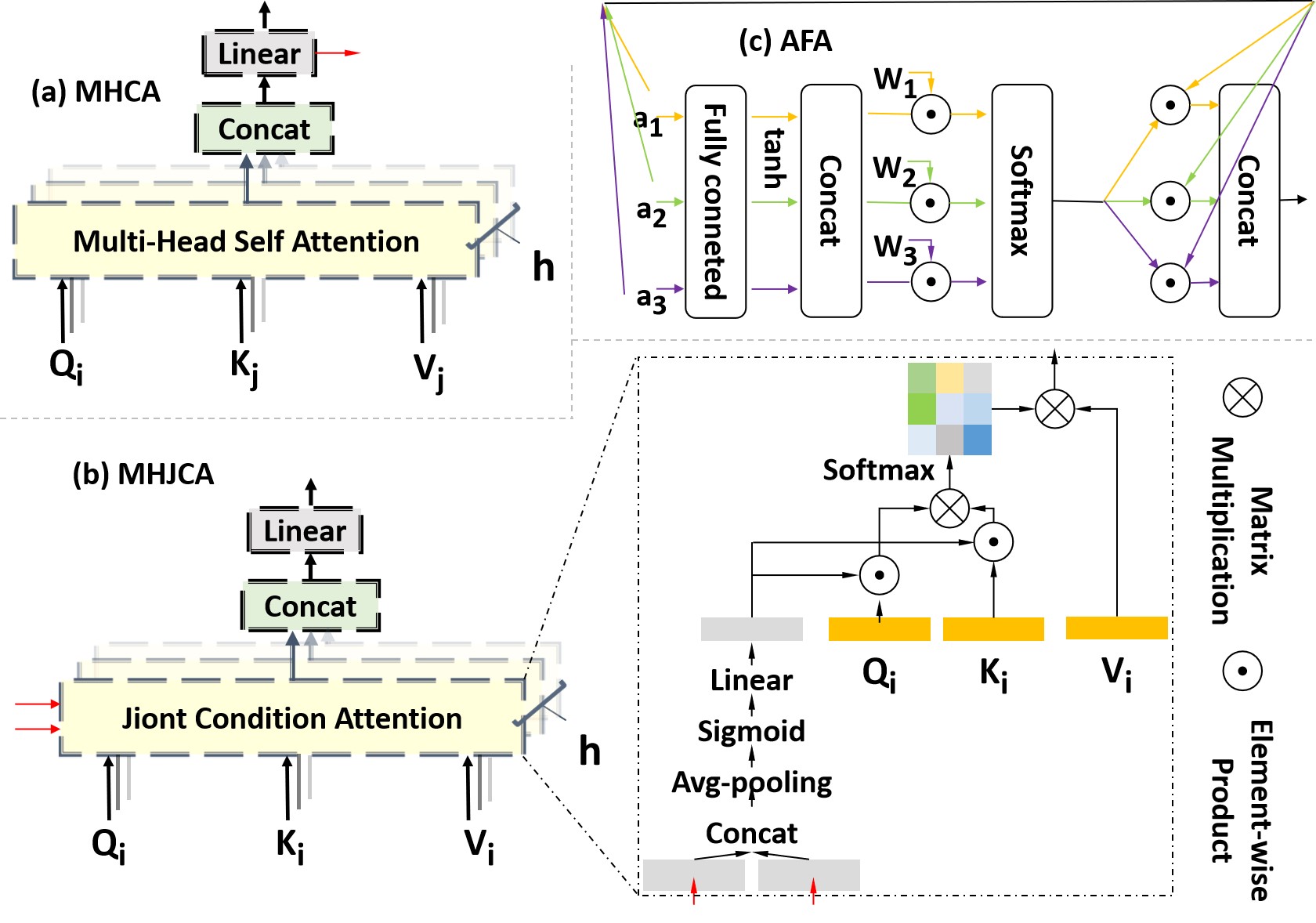
This retrospective study was approved by the local institutional review board and the informed consent of patients was waived. From October 2012 to December 2018, a total of 112 patients with 117 histologically confirmed HCCs were retrospectively included in the study. Gd-DTPA enhanced MR images for each patient were acquired with a 3.0T MR scanner. The pathological diagnosis of HCC was based on surgical specimens, in which there were 54 low-grade and 63 High-grade. Figure 1 shows the proposed M-JCT network, which extracts deep features from different modalities using a parallel architecture. Each architecture learns the cross-modal information through the multi-head cross attention (MHCA) module (Figure 2(a)) and uses them as constraints to guide the multi-head joint conditional attention (MHJCA) module (Figure 2(b)) to learn the information within the mode. Then, the two information is effectively integrated through the AFA module (Figure 2(c)). Finally, the deep features of the three modals are concatenated and cross entropy loss is adopted for optimization. The training and testing were repetitively performed five times in order to reduce the measurement error, and values of accuracy, sensitivity, specificity and area under the curves (AUC) were calculated in average.Results
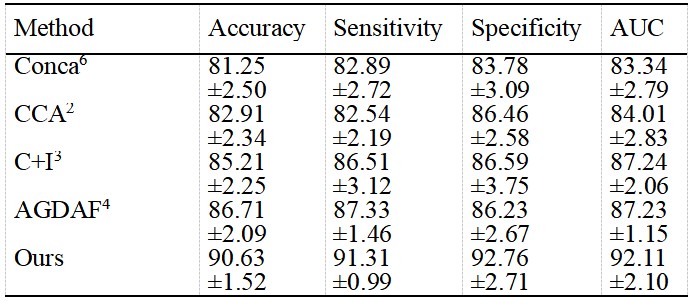
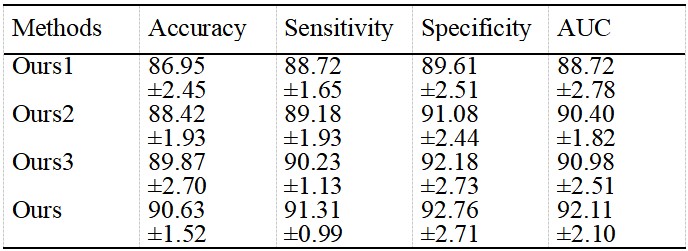
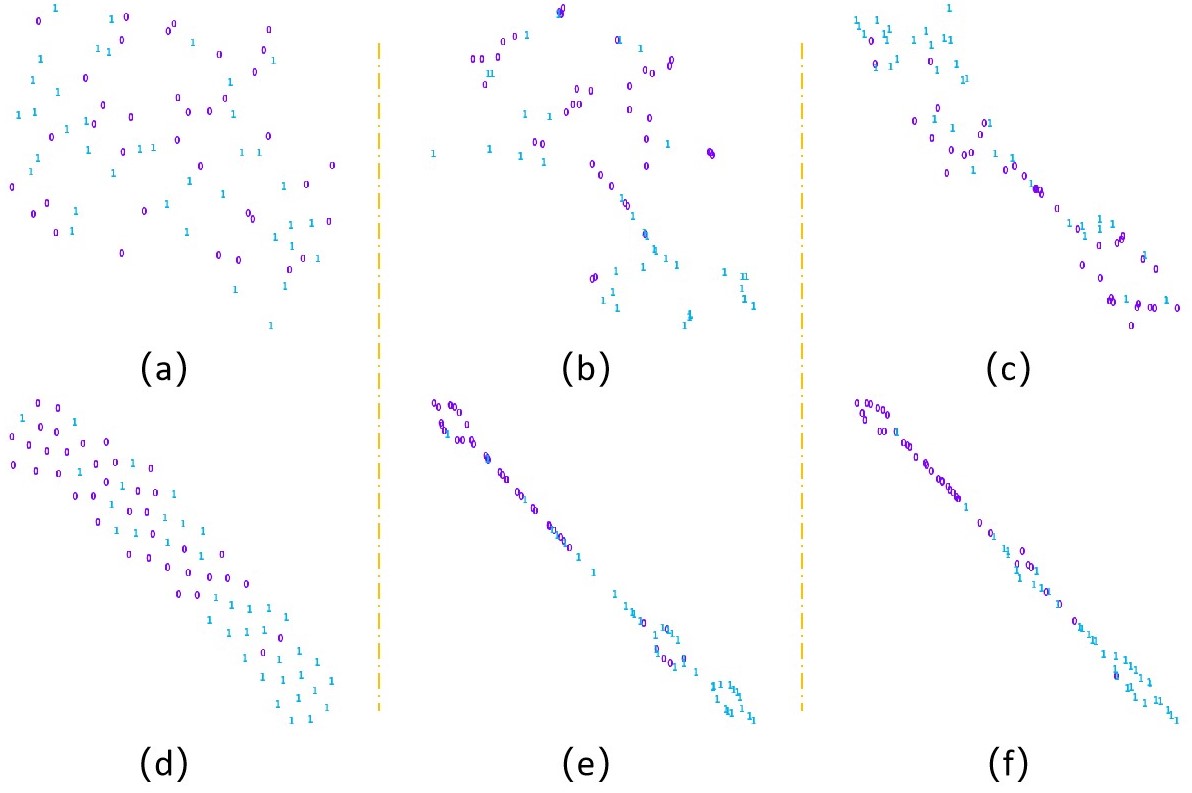
Table 1 showed the performance comparison of different fusion methods in HCC grading of Contrast-enhanced MR. The performance of proposed M-JCT network is significantly better than other fusion methods. In addition, compared with simple concatenation6 or deeply supervised fusion7 of deep features in different phases, analyzing the relationship within3,4 or between modals2-4 can better guide feature fusion. According to the ablation experiment results of Table 2 and the visual spatial feature distribution of figure 3, the proposed method uses the multi-head attention structure with stronger remote modeling ability to transfer inter modal information and intra modal feature learning, and adaptively and effectively fuse these features. In addition, the joint conditional attention module can use other modal information to constrain intra-modal feature learning and promote the learning of intra-modal important features.Discussion
Our research shows that compared with matrix decomposition-based methods2,3, using the attention mechanism4 or our transformer with more powerful long-distance modeling advantages and flexible multimodal input mode can effectively learn the characteristics within and between modals. Evidently, the proposed M-JCT network is superior to the previously reported multimodality fusion methods for lesion characterization. In addition, our research shows that effective fusion of features within and between modes can bring better results, which indicates that they need to be treated differently with greater importance. In addition, inter modal information is used as a condition constraint to guide intra modal feature learning and further strengthen the discriminability of intra modal features.Conclusion
In this work, we proposed a multi-modal fusion network with jointly conditional transformer for grading hepatocellular carcinoma (M-JCT network) to improve the performance of lesion characterization, outperforming previously reported multimodal fusion methods. The method and findings proposed in this study may be beneficial to multimodal fusion for lesion characterization.Acknowledgements
This research is supported by the grant from National Natural Science Foundation of China (NSFC: 81771920).References
1. Bi WL, Hosny A, Schabath M.B, et al. Artificial intelligence in cancer imaging: Clinical challenges and applications. CA Cancer J Clin. 2019; 69(2):127-157.
2.Hussein S, Kandel P, Corral J.E, et al. Deep multi-modal classification of intraductal papillary mucinous neoplasms (IPMN) with canonical correlation analysis. In 2018 IEEE 15th International Symposium on Biomedical Imaging, 2018; 800-804.
3. Dou T, Zhang L, Zheng H, et al. Local and Non-local Deep Feature Fusion for Malignancy Characterization of Hepatocellular Carcinoma. International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2018.
4. Li S, Xie Y, Wang G, et al. Attention guided discriminative feature learning and adaptive fusion for grading hepatocellular carcinoma with Contrast-enhanced MR. Computerized Medical Imaging and Graphics. 2022; 97:102050.
5. Xu P, Zhu X, Clifton D.A. Multimodal Learning with Transformers: A Survey. 2022; arXiv:2206.06488
6.Dou T, Zhang L, Zhou W, 3d deep feature fusion in contrast- enhanced MR for malignancy characterization of hepatocellular carcinoma. IEEE 15th International Symposium on Biomedical Imaging. 2018; 29–33.
7.Zhou W, Wang G, Xie G, et a. Grading of hepatocellular carcinoma based on diffusion weighted images with multiple b-values using convolutional neural networks. Med Phys. 2019; 46(9):3951-3960.
Figures