1370
SRNR: Training neural networks for Super-Resolution MRI using Noisy high-resolution Reference data1Department of Electronic Engineering, Tsinghua University, Beijing, China, 2Department of Biomedical Engineering, Tsinghua University, Beijing, China, 3Athinoula A. Martinos Center for Biomedical Imaging, Department of Radiology, Massachusetts General Hospital, Charlestown, MA, United States, 4Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Machine Learning/Artificial Intelligence, Data Analysis
Neural network (NN) based approaches for super-resolution MRI typically require high-SNR high-resolution reference data acquired in many subjects, which is time consuming and a barrier to feasible and accessible implementation. We propose to train NNs for Super-Resolution using Noisy Reference data (SRNR), leveraging the mechanism of the classic NN-based denoising method Noise2Noise. We systematically demonstrate that results from NNs trained using noisy and high-SNR references are similar for both simulated and empirical data. SRNR suggests a smaller number of repetitions of high-resolution reference data can be used to simplify the training data preparation for super-resolution MRI.
Introduction
Super-resolution MRI synthesizes high-resolution images from low-resolution images and is a useful tool to shorten the scan time and visualize fine structures. Deep learning techniques, particularly neural networks (NNs), have been shown to outperform conventional super-resolution methods and are widely adopted in biomedical imaging1-4. Nonetheless, the training of NNs requires high-quality and high-resolution reference data acquired in many subjects, as a result reducing the practical feasibility and accessibility of NN-based super-resolution. Higher resolution necessitates not only a larger number of data samples and longer acquisition times to encode a whole-brain volume, but also multiple signal averages to improve the inherently low signal-to-noise ratio (SNR). This work aims to simplify reference data acquisition for NN-based super-resolution.Noise2Noise5 is a classic NN-based denoising method that does not need high-SNR reference data, which works by training denoising NNs to map a noisy image to another instance of the image acquired with a statistically independent noise sample. It is proven that the learned NN parameters remain unchanged if certain statistics of noisy reference values match those of the clean reference values (e.g., the expectation for L2 minimization).
In this work, we leverage the mechanism of Noise2Noise and train NNs for Super-Resolution using Noisy Reference data (SRNR). The proposed SRNR method trains NNs to map low-resolution images to their residuals compared to noisy high-resolution reference images, which are composed of random noise and static high-frequency residuals resulting from the difference in resolution. We hypothesize that the random noise does not affect the training.
We systematically demonstrate the efficacy of SRNR by comparing its results to those from NNs trained using high-SNR references. We first evaluate the effects of noise in reference data on super-resolved images using simulated reference data with different levels of noise. We then show that super-resolution results from NNs trained with single-average and 10-average high-resolution data are highly similar. SRNR has the potential to promote wider adoption of NN-based super-resolution MRI, thereby benefiting a broader range of clinical and neuroscientific applications.
Methods
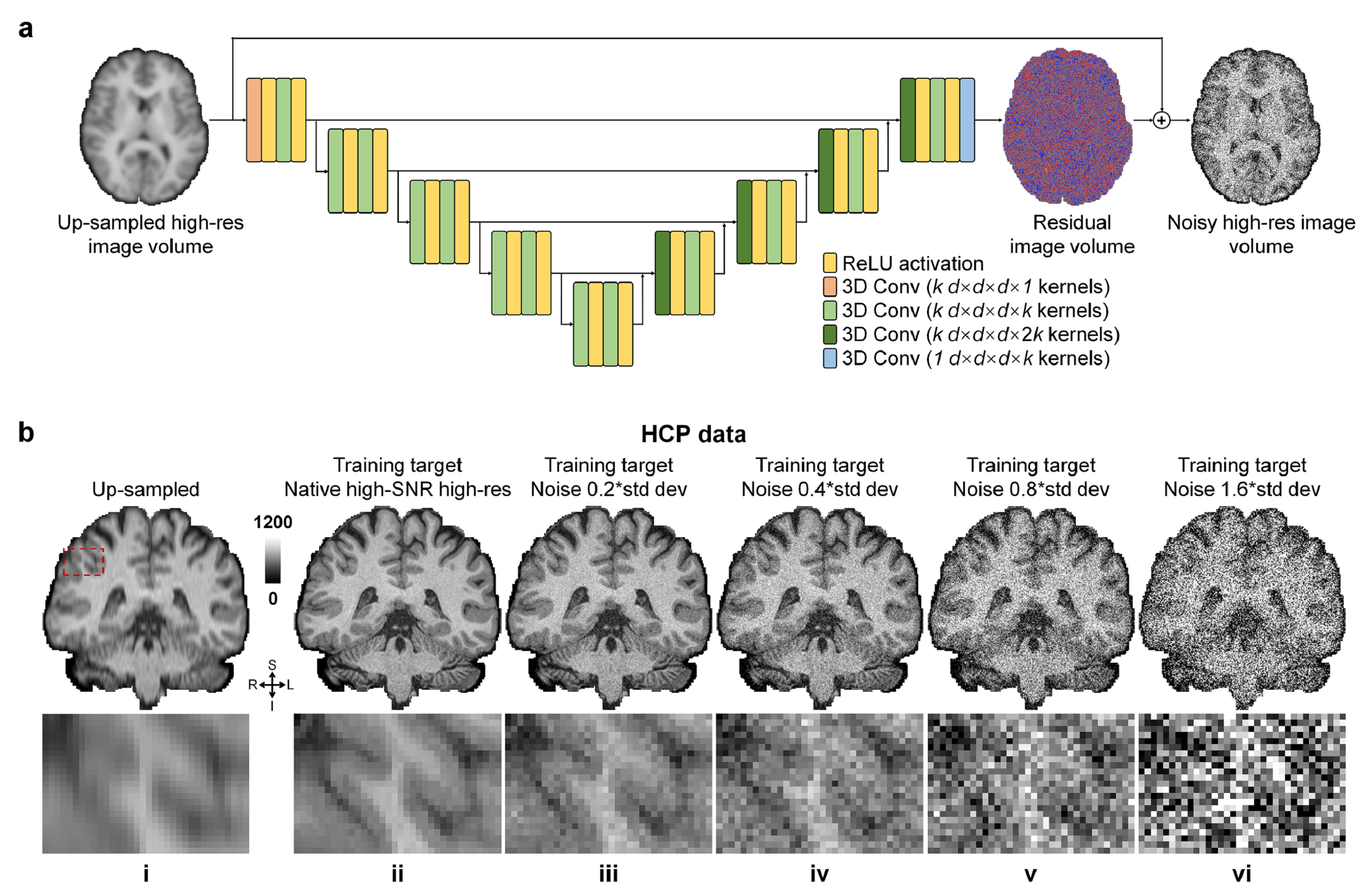
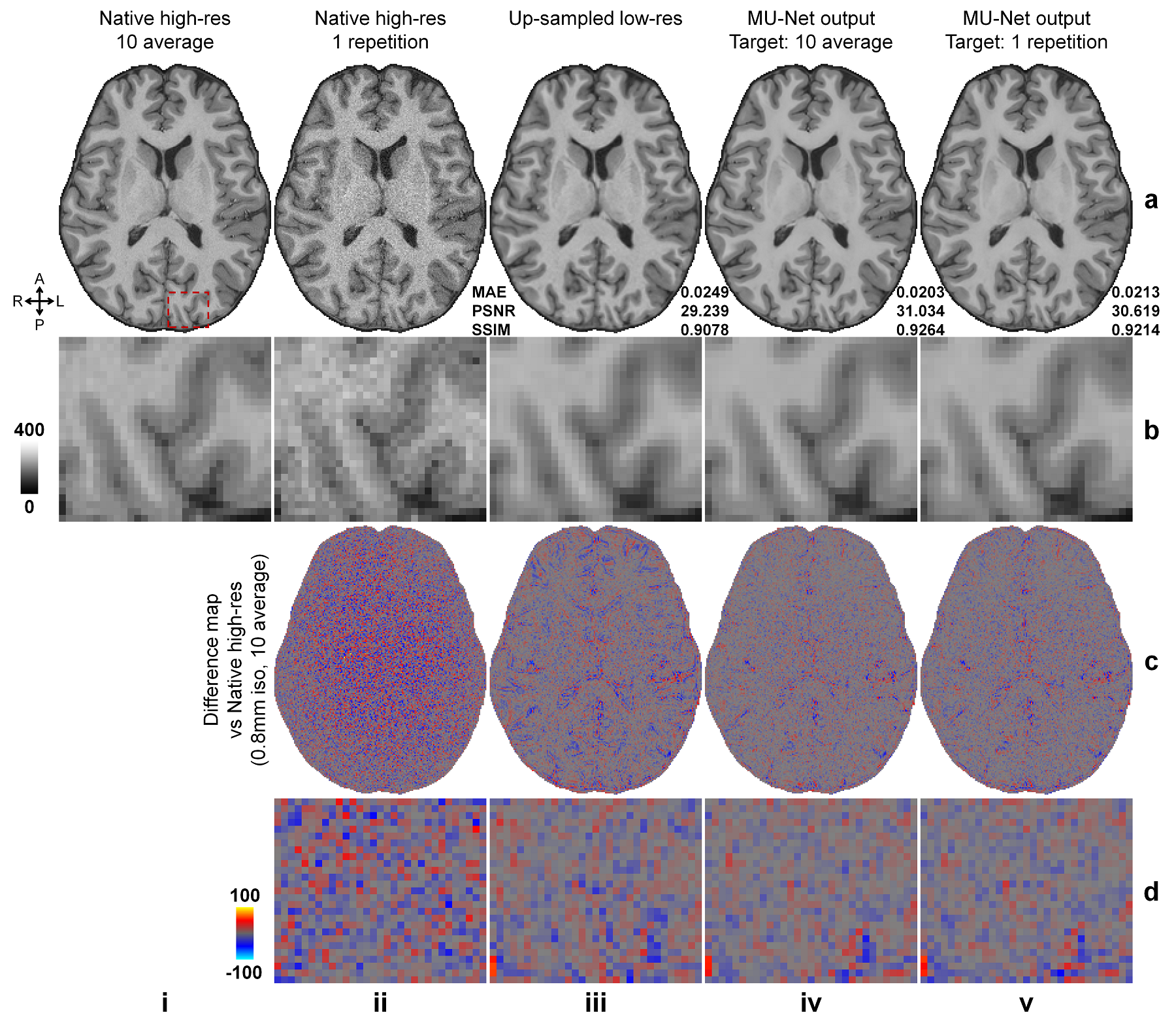
Simulated data. High-SNR T1w images acquired at 0.7×0.7×0.7 mm3 resolution of 30 healthy subjects from the Human Connectome Project (HCP)6, 7 WU-Minn-Ox Consortium were used as the ground-truth high-resolution data. Low-resolution thick-slice images were generated by down-sampling the ground-truth data along the superior-inferior direction to 0.7×0.7×3.5 mm3 resolution. Noisy high-resolution data were simulated by adding Gaussian noise (μ=0, σ=0.2, 0.4, 0.6, …, 1.6×σ of brain voxel intensities) to the native data as the noisy reference high-resolution data (Fig.1b).Empirical data. Highly accelerated (R=3×3) high-resolution (0.8×0.8×0.8 mm3, 10 repetitions) and lower-resolution (1×1×1 mm3, 1 repetition) T1w data were acquired on 9 healthy subjects using a Wave-MPRAGE sequence (five on a MAGNETOM Skyra scanner and four on a MAGNETOM Prisma scanner, Siemens Healthineers). For each subject, the 10 repetitions of high-resolution T1w data were co-registered to the first repetition and averaged using FreeSurfer’s “mri_robust_template” function8-11. The low-resolution T1w data were co-registered to the 10-repetition averaged volume using NiftyReg’s “reg_aladin” function.
Network and training. The modified U-Net (MU-Net, Fig.1a) with all pooling and up-sampling layers removed was adopted and implemented using Tensorflow. The input of MU-Net was the low-resolution image volume up-sampled to the target high-resolution using cubic spline interpolation. The output of MU-Net was the residual volume between the input and target volume. The training and validation were performed on the simulation data of 15 subjects with the high-SNR and noisy high-resolution data as the target as well as the empirical data of 4 subjects with the single-average and 10-average data as the target respectively, with Adam optimizers and L2 loss.
Evaluation. The mean absolute error (MAE), peak SNR (PSNR), and structural similarity index (SSIM) were computed to quantify the similarity between up-sampled, super-resolved images and ground-truth high-resolution images, as well as between super-resolved images from different models.
Results
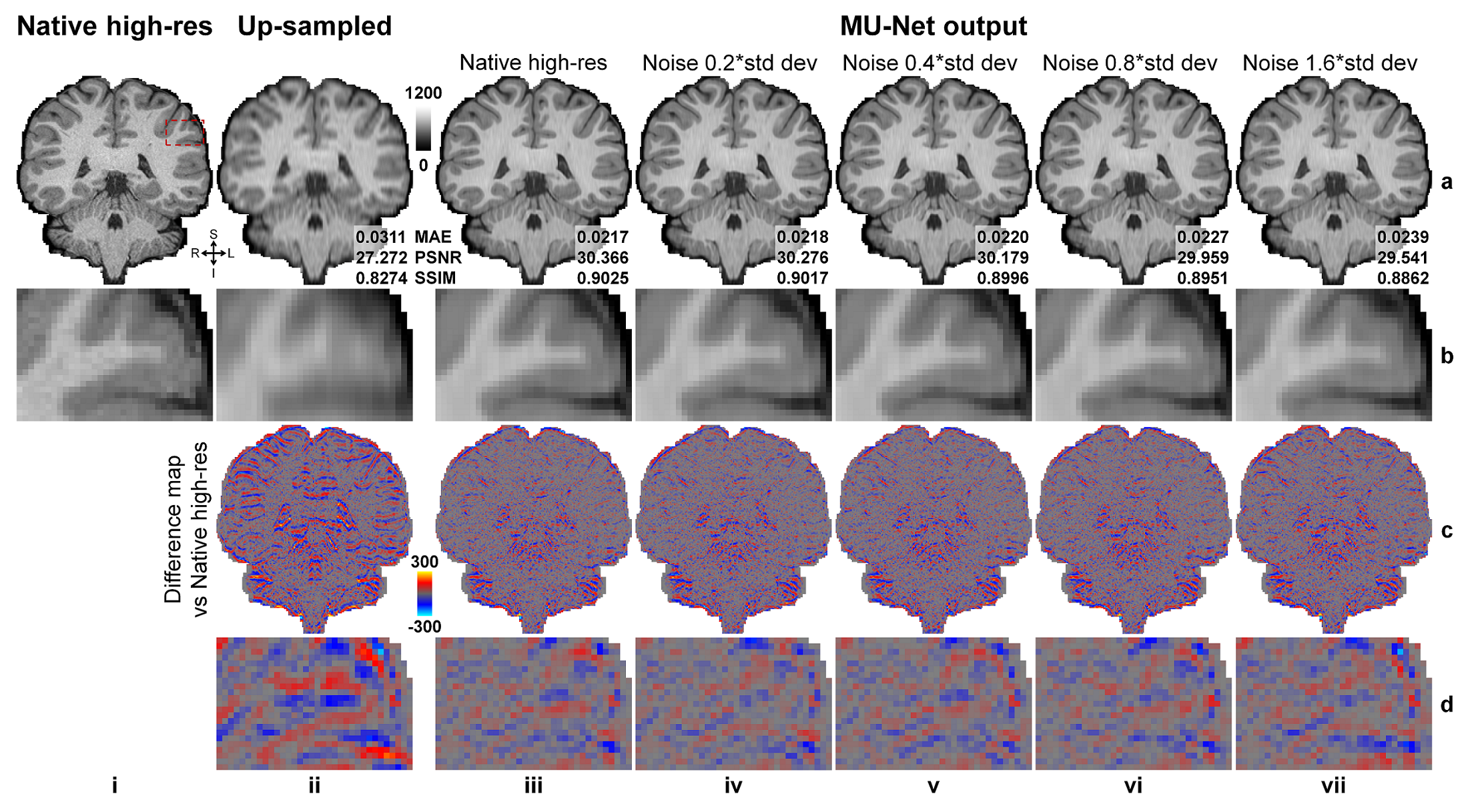
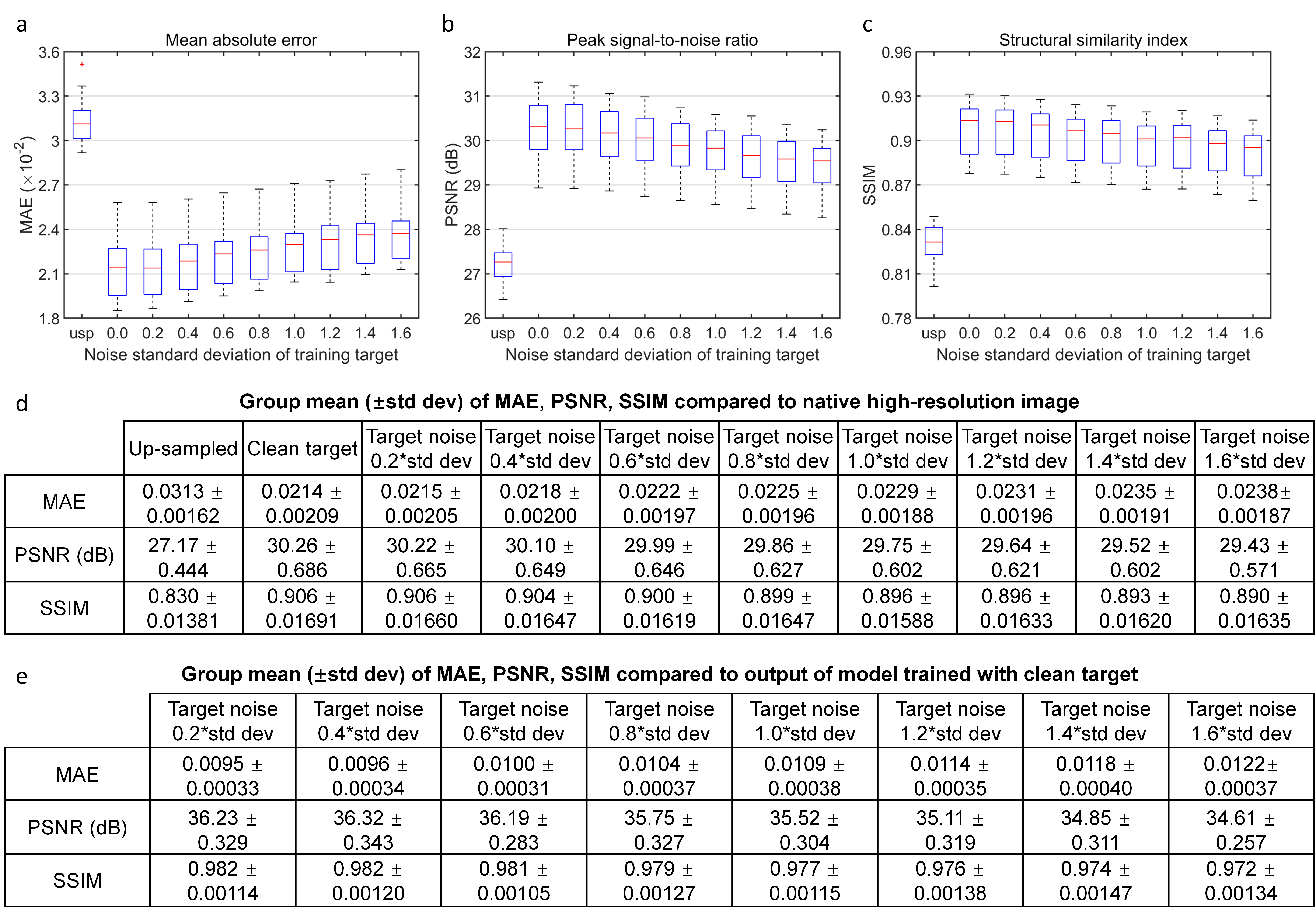
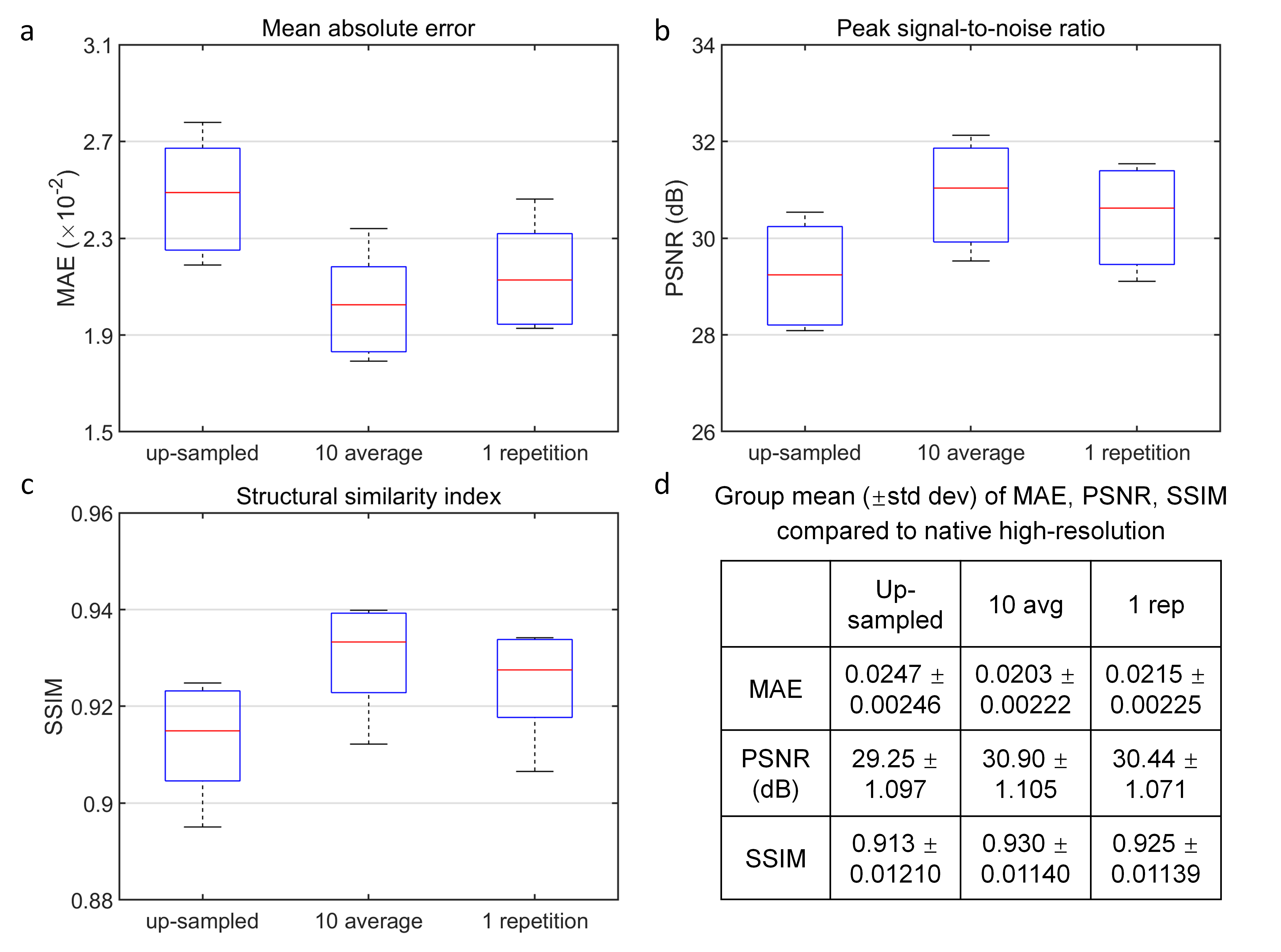
Super-resolved images from NNs trained with noisy high-resolution references were visually (Figs.2 and.4) and quantitatively (Figs.3 and 5) similar to those from NNs trained with high-SNR reference data. For the simulated data, the similarity gradually decreased as the noise level in the reference data increased, as expected (Fig.3). Even for the noisiest case (Fig.2, vii), the similarity compared to the ground-truth data only slightly decreased (Fig.3d, MAE: 0.0214 vs. 0.0238, 11.2%; PSNR: 30.26 dB vs. 29.43 dB, -2.7%; SSIM: 0.906 vs. 0.890, -1.77%) and the inter-result similarity was high (Fig.3e, MAE: 0.0122; PSNR: 34.61 dB; SSIM: 0.972).For the empirical data, the similarity of results using single-average and 10-average reference data compared to the ground-truth data was highly similar (Fig.5d, MAE: 0.0203 vs. 0.0215, 5.9%; PSNR: 30.90 dB vs. 30.44 dB, -1.6%; SSIM: 0.930 vs. 0.925, -0.54%). The inter-result similarity was also high (MAE: 0.0097; PSNR: 36.75 dB; SSIM: 0.988).
Discussion and Conclusion
SRNR shows comparable efficacy of training using noisy versus high-SNR high-resolution reference data for super-resolution MRI. The success of the SRNR approach suggests that a smaller number of repetitions of high-resolution reference data for averaging can be adopted to achieve slightly compromised super-resolution performance and improve feasibility and accessibility. Using a single repetition also avoids additional data re-sampling during image co-registration, thus avoiding potential blurring of the high-resolution reference data.Acknowledgements
The T1-weighted data for simulation was provided by the Human Connectome Project, WU-Minn-Ox Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; U54-MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University. This work was supported by the National Institutes of Health (grant numbers P41-EB015896, P41-EB030006, K99-AG073506), and the Athinoula A. Martinos Center for Biomedical Imaging.
References
1. Pham C-H, Ducournau A, Fablet R, Rousseau F. Brain MRI super-resolution using deep 3D convolutional networks. IEEE; 2017:197-200.
2. Chaudhari AS, Fang Z, Kogan F, et al. Super‐resolution musculoskeletal MRI using deep learning. Magnetic resonance in medicine. 2018;80(5):2139-2154.
3. Chen Y, Shi F, Christodoulou AG, Xie Y, Zhou Z, Li D. Efficient and accurate MRI super-resolution using a generative adversarial network and 3D multi-level densely connected network. Springer; 2018:91-99.
4. Tian Q, Bilgic B, Fan Q, et al. Improving in vivo human cerebral cortical surface reconstruction using data-driven super-resolution. Cerebral Cortex. 2021;31(1):463-482.
5. Lehtinen J, Munkberg J, Hasselgren J, et al. Noise2Noise: Learning image restoration without clean data. arXiv preprint arXiv:180304189. 2018;
6. Glasser MF, Sotiropoulos SN, Wilson JA, et al. The minimal preprocessing pipelines for the Human Connectome Project. Neuroimage. 2013;80:105-124.
7. Glasser MF, Smith SM, Marcus DS, et al. The human connectome project's neuroimaging approach. Nature neuroscience. 2016;19(9):1175-1187.
8. Reuter M, Rosas HD, Fischl B. Highly accurate inverse consistent registration: a robust approach. Neuroimage. 2010;53(4):1181-1196.
9. Fischl B, Sereno MI, Dale AM. Cortical surface-based analysis: II: inflation, flattening, and a surface-based coordinate system. NeuroImage. 1999;9(2):195-207.
10. Dale AM, Fischl B, Sereno MI. Cortical surface-based analysis: I. Segmentation and surface reconstruction. NeuroImage. 1999;9(2):179-194.
11. Fischl B. FreeSurfer. NeuroImage. 2012;62(2):774-781.Figures