0833
SVD Compression for Nonlinear Encoding Imaging with Model-based Deep Learning Reconstruction1Department of Biomedical Engineering, School of Engineering and Applied Science, Yale University, New Haven, CT, United States, 2Department of Radiology and Biomedical Imaging, School of Medicine, Yale University, New Haven, CT, United States, 3Interdepartmental Neuroscience Program, School of Medicine, Yale University, New Haven, CT, United States, 4Department of Neurosurgery, School of Medicine, Yale University, New Haven, CT, United States
Synopsis
Keywords: Image Reconstruction, Signal Representations, Nonlinear Encoding
Model-based deep learning reconstruction with a nonlinear encoding matrix poses unique challenges to GPU memory, due to the densely connected computational graph nodes in the physics model part. In this work, SVD compression is demonstrated as necessary for such networks, and it is applied to the highly nonlinear case of Bloch-Siegert encoding from a low-field MR scanner. The redundancy across all nonlinear encoding dimensions is exploited for compression. With the compressed encoding matrix, the model-based network is feasible to implement. It outperforms the traditional reconstruction at all levels of simulated Gaussian noise and has advantages over commonly used regularization terms.Introduction
Nonlinear encoding, in contrast to the linear encoding associated with Fourier transformation, requires an alternative approach to image reconstruction, either to account for the field imperfection1,2 or to decode the signal projected by nonlinear gradient coils3–6 or RF arrays7. The general signal model is as follows:$$b_{i,c} (t)= \int \rho(r) S_c (r) exp(-j\phi_i (r,t))dr+n_{i,c} (t)=\int \rho(r) E_{i,c} (r,t)dr+n_{i,c} (t)$$
where the signal $$$b_{i,c}(t)$$$, mixed with noise $$$n_{i,c}(t)$$$, is from the underlying object $$$\rho(r)$$$ encoded by the $$$i$$$th time-varying position-dependent phase $$$\phi_i(r,t)$$$ and the $$$c$$$th receiving coil $$$S_c(r)$$$. Image reconstruction is formulated as
$$\hat{\rho}=\arg{\min}_{\rho}\|b-E\rho\|_2^2$$
Previous work has shown that model-based deep learning can improve image reconstruction of nonlinearly encoded data8. It reduces the need for rigorous field mapping of nonlinear gradient waveforms. In that work, implementation relied on playing the same nonlinear waveform during each readout, whereby the nonlinear encoding can be treated as a Point Spread Function (PSF) modulation after Fast Fourier Transform (FFT).
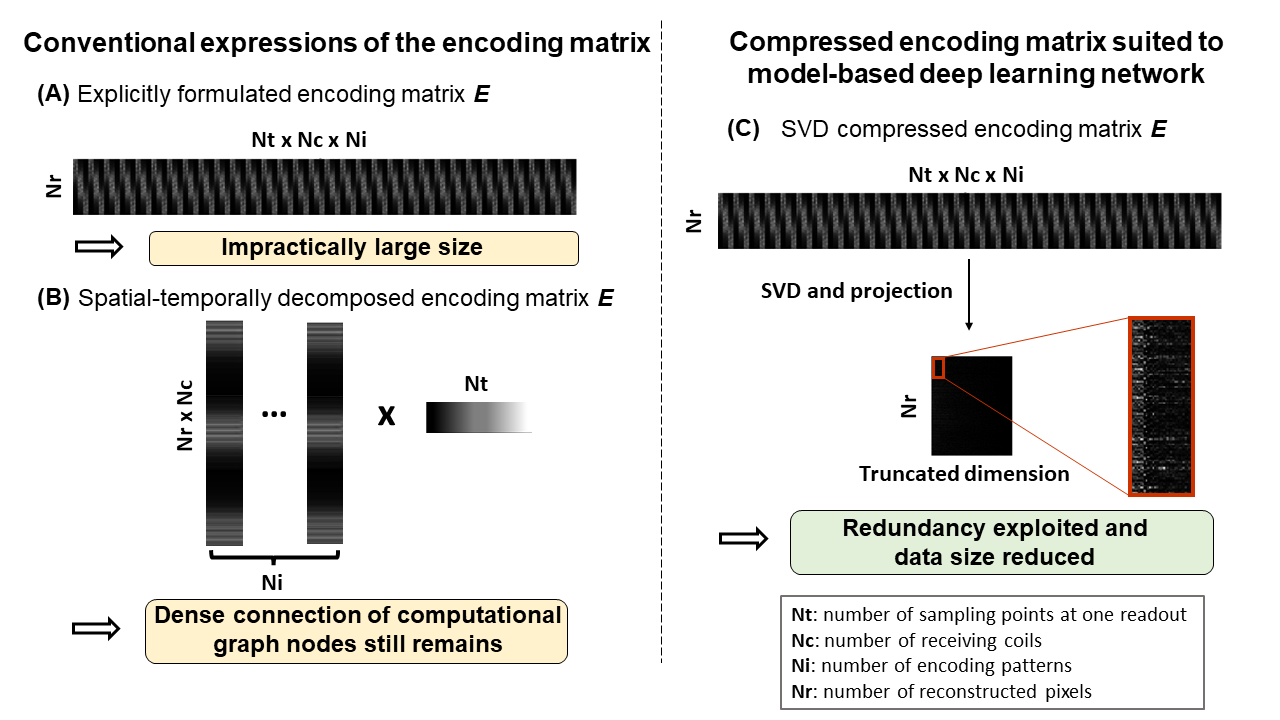
For a general case of nonlinear encoding, like that provided by RF encoding7,9, the encoding matrix is not based on FFT, and there are various nonlinear terms occurring across readouts. A reasonable $$$E$$$ requires O(100GB), which is impractical for saving and loading. The approaches of spatial-temporal decomposition2,9,10 avoid expressing $$$E$$$ explicitly, but do not alleviate the memory issue in backpropagation, as the computational graph still has nodes densely connected in the physics model part of the network, and thus the memory requirement often exceeds GPU capacity.
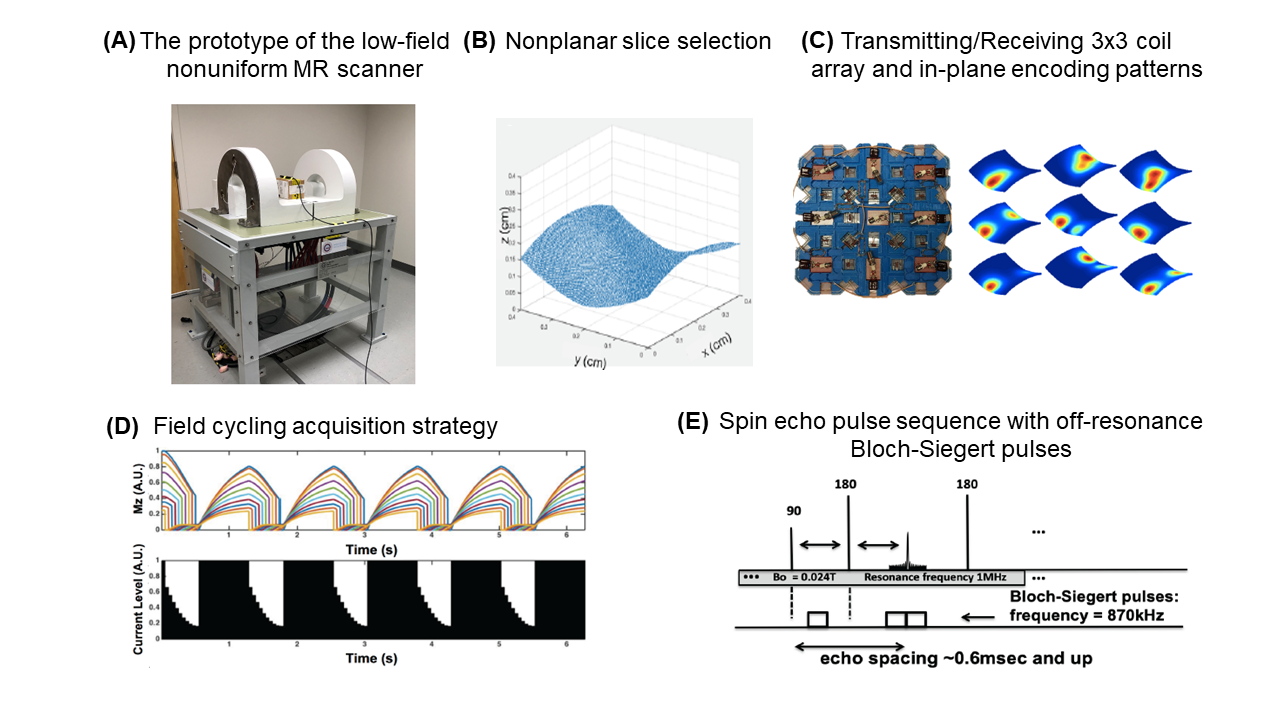
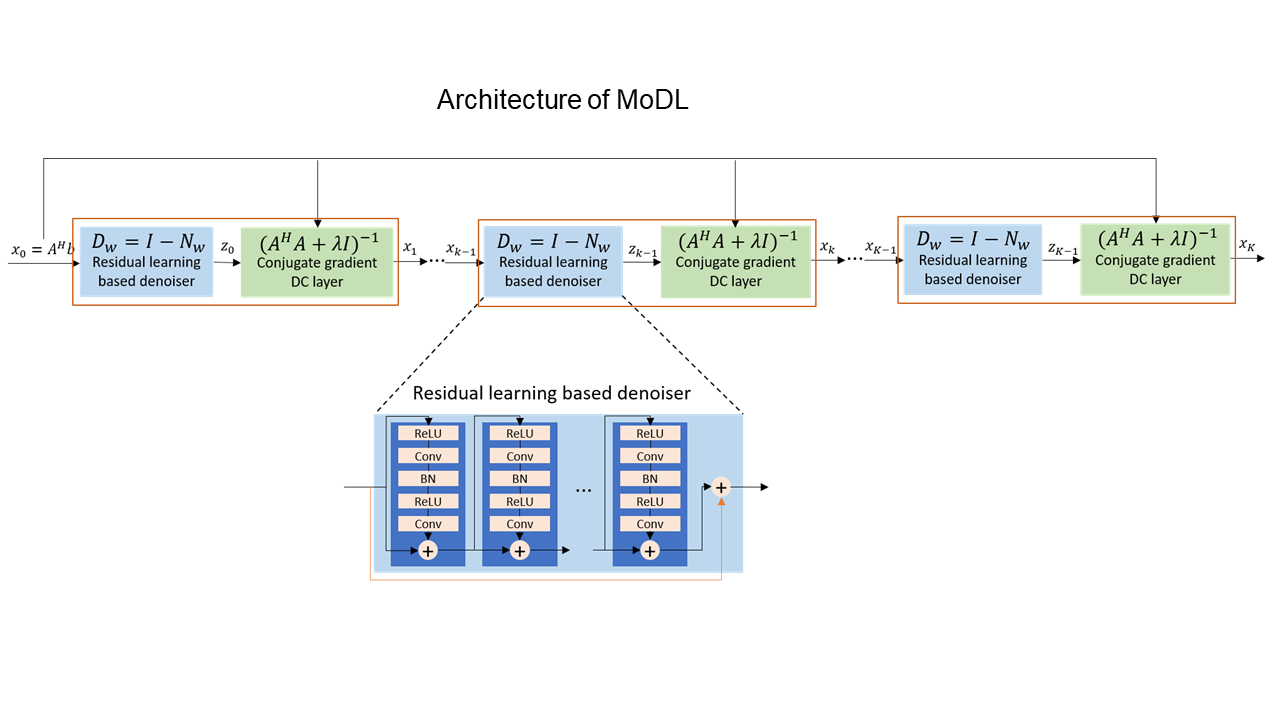
Here we present a compression method to reduce the data size and make model-based networks feasible for the reconstruction of nonlinear encoding imaging. We apply the method to the low-field nonuniform imaging MR device7,9, shown in Fig. 1. It features gradient-free RF spatial encoding, with a nonplanar 1MHz imaging slice selected from the nonuniform electromagnet. Off-resonance RF pulses with 130kHz offset transmitted by a 3x3 coil array induce spatially varying Bloch-Siegert shifts11 for in-plane nonlinear encoding. One can create various encoding patterns by switching on or off individual coil elements. Low-field MR scanners have lower SNR, and because of nonlinear encoding, certain regions may receive limited encoding, leading to noisy and blurry reconstruction. Both these issues can be improved with a model-based reconstruction. This study demonstrates the feasibility and advantage of a state-of-the-art model-based network MoDL12 (Fig. 2) implemented with the proposed compression method.
Method
Unlike conventional linear encoding which has orthogonal basis vectors while redundancy only occurs at the coil encoding dimension, nonlinear encoding usually has redundancy in the frequency encoding, phase encoding, and coil sensitivity encoding dimensions, which has great potential for matrix size reduction. Similar to the concept reported previously13, Singular Value Decomposition (SVD)14 is used to decompose the encoding matrix $$$E$$$$$E=U\Sigma V^*$$
where $$$U$$$ and $$$V$$$ both form a set of orthonormal vectors. The total energy of $$$E$$$ is defined as the sum of the squares of its singular values.
Projecting $$$E$$$ onto the subspace spanned by the first k singular vectors $$$\{v_1,\cdots,v_k\}$$$ yields a representation in the lower dimensional space $$$C^k, 1<k<rank(E)$$$. This is done by multiplying
$$E_k=EV_k$$
where $$$V_k=\{v_1,\cdots,v_k\}$$$. The energy ratio is the fraction of energy of $$$E$$$ retained after truncation. The acquired signal should also be projected to the new space.
$$b_k=bV_k$$
Therefore, the physics model part of MoDL is formulated in the lower dimensional space
$$\rho_{n+1}=\arg{\min}_{\rho}\sum\limits_{i=1}^{N_i}\sum\limits_{c=1}^{N_c}\|b_{k_{i,c}}-E_{k_{i,c}}\rho\|_2^2+\lambda\|\rho-z_n\|_2^2$$
where $$$z_n$$$ is the ’denoised’ version of $$$\rho_n$$$ at the $$$n$$$th unrolled iteration.
In this study, 500 images from fastMRI dataset15 and a 3T liver image serve as the ground truth, and signals were simulated with 256 readout points per echo, 128 phase encoding steps, and 20cmx20cm FOV received by the 3x3 coil array. A range of Gaussian noise levels was simulated and tested. MoDL was compared to traditional CG reconstructions with and without regularizations.
Results and Discussion
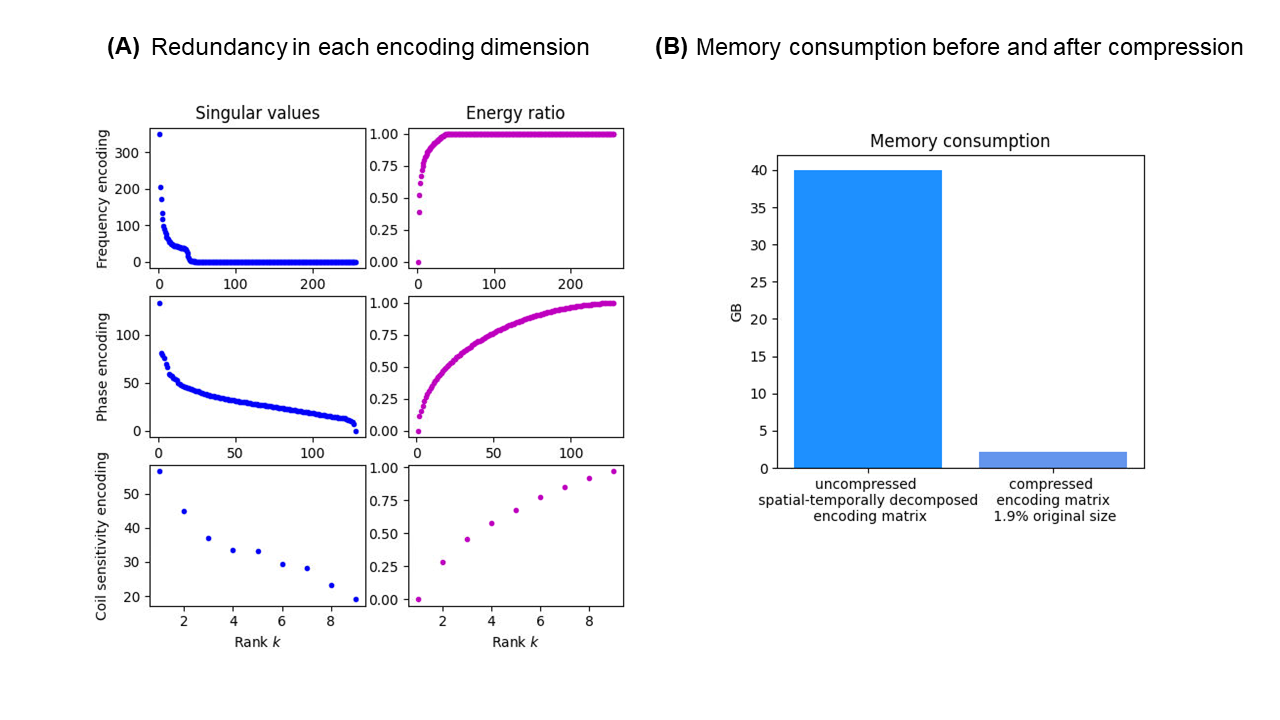
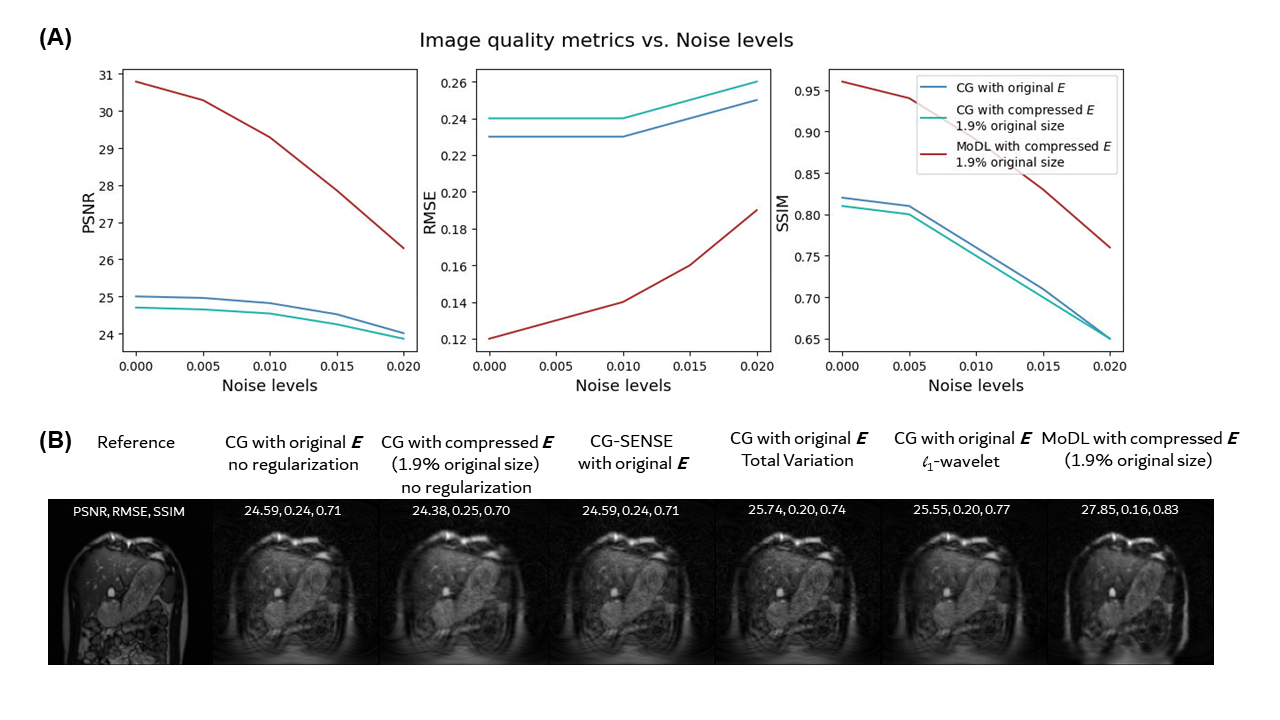
Fig. 4A shows the potential for compression across three encoding dimensions by plotting singular values and the corresponding energy ratios, which demonstrate redundancy in the nonlinear encoding scheme. Combining these dimensions lead to a >90% reduction of the encoding matrix and signals. Fig. 4B shows the benefit of compression through memory consumption change. Attempting MoDL with the uncompressed input exceeds the memory capacity of most GPUs, but is made feasible with the compressed input. Note that the spatial-temporally decomposed matrix brings additional graph node connections, compared to an explicitly formulated matrix.Fig. 5 shows the performance of various reconstruction methods using the full and compressed $$$E$$$ matrix. The compressed $$$E$$$ has 1.9% of the original size but only causes slight degradation in PSNR, RMSE, and SSIM across all noise levels (-0.2dB, +1%, and -0.01, respectively). Applying MoDL, which is only feasible with the compressed $$$E$$$ matrix, improves PSNR, RMSE, and SSIM by +2~6dB, -6%~-11%, and 0.12~0.15, respectively. Compared to traditional regularization terms with optimized weightings, MoDL yields the best PSNR, RMSE, and SSIM, approximately by a margin of 2dB, -4%, and 0.06.
Conclusion
Nonlinear encoding imaging with model-based deep learning reconstruction presents unique challenges for memory requirements. SVD compression was proven feasible and necessary for the implementation of the model-based network. With the compressed data, MoDL was implemented and demonstrated to outperform traditional reconstructions at various noise levels.Acknowledgements
No acknowledgement found.References
1. Wilm BJ, Barmet C, Pavan M, Pruessmann KP. Higher order reconstruction for MRI in the presence of spatiotemporal field perturbations. Magn Reson Med 2011;65:1690–1701 doi: 10.1002/mrm.22767.
2. Lee NG, Ramasawmy R, Lim Y, Campbell-Washburn AE, Nayak KS. MaxGIRF: Image reconstruction incorporating concomitant field and gradient impulse response function effects. Magn Reson Med 2022;88:691–710 doi: 10.1002/mrm.29232.
3. Hennig J, Welz AM, Schultz G, et al. Parallel imaging in non-bijective, curvilinear magnetic field gradients: a concept study. MAGMA 2008;21:5–14 doi: 10.1007/s10334-008-0105-7.
4. Stockmann JP, Ciris PA, Galiana G, Tam L, Constable RT. O-Space Imaging: Highly Efficient Parallel Imaging Using Second-Order Nonlinear Fields as Encoding Gradients with No Phase Encoding. Magn Reson Med 2010;64:447–456 doi: 10.1002/mrm.22425.
5. Cooley CZ, Stockmann JP, Armstrong BD, et al. Two-dimensional imaging in a lightweight portable MRI scanner without gradient coils. Magn Reson Med 2015;73:872–883 doi: 10.1002/mrm.25147.
6. Wang H, Tam LK, Constable RT, Galiana G. Fast rotary nonlinear spatial acquisition (FRONSAC) imaging. Magn Reson Med 2016;75:1154–1165 doi:10.1002/mrm.25703.
7. Constable RT, Rogers III C, Wu B, Selvaganesan K, Galiana G. Design of a novel class of open MRI devices with nonuniform Bo, field cycling, and RF spatial encoding. In: Proc. Intl. Soc. Mag. Reson. Med. 27 (2019).
8. Zhang Z, Galiana G. Deep Learning Reconstruction for FRONSAC. In: Proc. Intl. Soc. Mag. Reson. Med. 30 (2022).
9. Selvaganesan K, Ha Y, Galiana G, Constable RT. Nonlinear encoding scheme design for gradient-free projection imaging in an inhomogeneous Bo at low-field. In: Proc. Intl. Soc. Mag. Reson. Med. 30 (2022).
10. Rodriguez Y, Elsaid NMH, Keil B, Galiana G. 3D FRONSAC with PSF reconstruction. arXiv; 2021. doi: 10.48550/arXiv.2111.05143.
11. Bloch F, Siegert A. Magnetic Resonance for Nonrotating Fields. Phys. Rev. 1940;57:522–527 doi: 10.1103/PhysRev.57.522.
12. Aggarwal HK, Mani MP, Jacob M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans Med Imaging 2019;38:394–405 doi: 10.1109/TMI.2018.2865356.
13. McGivney DF, Pierre E, Ma D, et al. SVD Compression for Magnetic Resonance Fingerprinting in the Time Domain. IEEE Trans Med Imaging 2014;33:2311–2322 doi: 10.1109/TMI.2014.2337321.
14. Golub GH, Van Loan CF. Matrix Computations. Baltimore, MD: Johns Hopkins Univ. Press; 1996.
15. fastMRI: A Publicly Available Raw k-Space and DICOM Dataset of Knee Images for Accelerated MR Image Reconstruction Using Machine Learning | Radiology: Artificial Intelligence. https://pubs.rsna.org/doi/10.1148/ryai.2020190007. Accessed October 20, 2022.
Figures