0831
Self-Supervised Deep Learning Reconstruction for Highly Accelerated Diffusion Imaging1Electrical and Electronics Engineering, Bogazici University, Istanbul, Turkey, 2Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, Charlestown, MA, United States, 3Department of Radiology, Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Image Reconstruction, Image Reconstruction
We propose a zero-shot self-supervised learning (ZS-SSL) approach for accelerated diffusion MRI reconstruction. Our method builds on the approach in [3] for subject-specific MRI reconstruction. We perform reconstruction across all diffusion directions with a single model, rather than different models for each direction, reducing computation time. We partition the directions as training and validation directions. We train the model on training directions, while keeping track of validation loss. We test our model on entire directions, evaluating the reconstruction quality of a single network across all directions. Jointly trained ZS-SSL provides better reconstructions than standard parallel imaging, while remaining computationally efficient.Introduction
Deep learning (DL) based MRI reconstruction methods have gained popularity due to their high performance. Although DL methods may outperform traditional approaches in MR image reconstruction, they usually require fully sampled training datasets, which is impractical for the sequences such as diffusion MRI that acquire prospectively undersampled k-space data using echo planar imaging (EPI). To overcome this challenge, [3] introduced a zero-shot self-supervised learning (ZS-SSL) method that can reconstruct the MR images in a scan-specific manner without additional fully sampled training datasets. In this work, building upon their proposal, we introduce a zero-shot self-supervised model, which is trained on a subset of diffusion directions, and can reconstruct diffusion MRI data across all diffusion directions and demonstrate that our approach outperforms a conventional SENSE reconstruction and enable high, R=5-fold in-plane acceleration with high image quality [1].Methods and Experiments
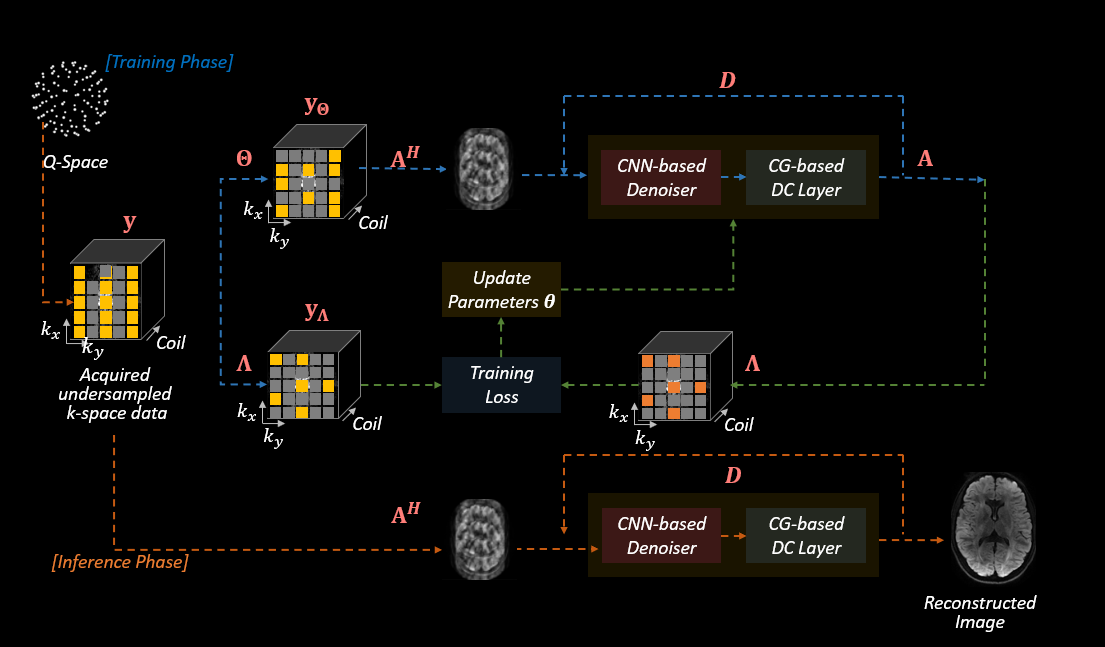
Proposed Approach: The overall scheme of our proposed method is shown in Figure 1. First, the acquired diffusion directions are split into two disjoint sets: training and validation directions. When partitioning the directions, we make sure that training directions cover as much of the q-space as possible, hence also validation directions are distributed across q-space. We use validation directions to determine the optimal training epochs and see whether the model does not overfit and can generalize to unseen directions after training. Then, for training and validation directions, we partition the acquired undersampled k-space data into two non-overlapping k-space portions, called ϴ and Λ, by applying a binary mask that is randomly generated from the original k-space sampling pattern. The k-space data ϴ was used for data consistency during training and the other portion Λ was used for calculating the training loss and updating the trainable parameters. We randomly generated those masks in every epoch for each direction.Data Acquisition: We acquired in vivo data using a 3T Prisma scanner with a multi-shot EPI sequence [4] that allowed for “fully-sampling” the data using 32chan reception at 1 mm in-plane and 4 mm slice thickness at b=1000 s/mm2 R=5-fold acceleration was performed and 5 shots were collected to fully encode the k-space. Performing S-LORAKS [2] on these multi-shot data permitted the reconstruction of a fully-sampled reference, which was used for computing error metrics.
Implementation Details: We used a model-based DL architecture that has a convolutional neural network (CNN)-based denoiser [5]. In the CNN-based denoiser, first the input is fed into a convolutional layer of kernel size 3x3 and with 2 input channels (corresponding the real and imaginary parts of the input image) and 64 output channels. Then the output of this CNN layer is fed into a residual block consisting of CNN layers with 3x3 kernels and 64 channels. This residual block is itself iterated 17 times. Then the output of this block goes through a CNN layer of 64 channels, then gets added with the input of the denoiser. Then the result goes through a CNN layer of 64 input channels and 2 output channels. This process is also iterated 15 times. The following k-space loss, which calculates the $$$l_{1}$$$ and $$$l_{2}$$$ norm of the difference between the acquired and the output k-space, is used for the training and validation loss:
$$\frac{{||u-v||_{2}}}{||v||_{2}} +\frac{{||u-v||_{1}}}{||v||_{1}}$$
where u and v are the acquired k-space and output k-space data masked with Λ, respectively.
Results
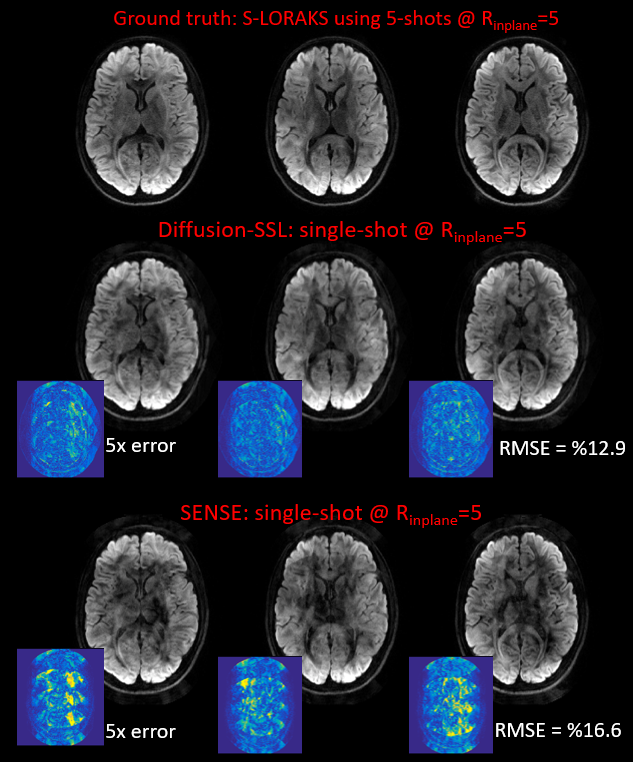
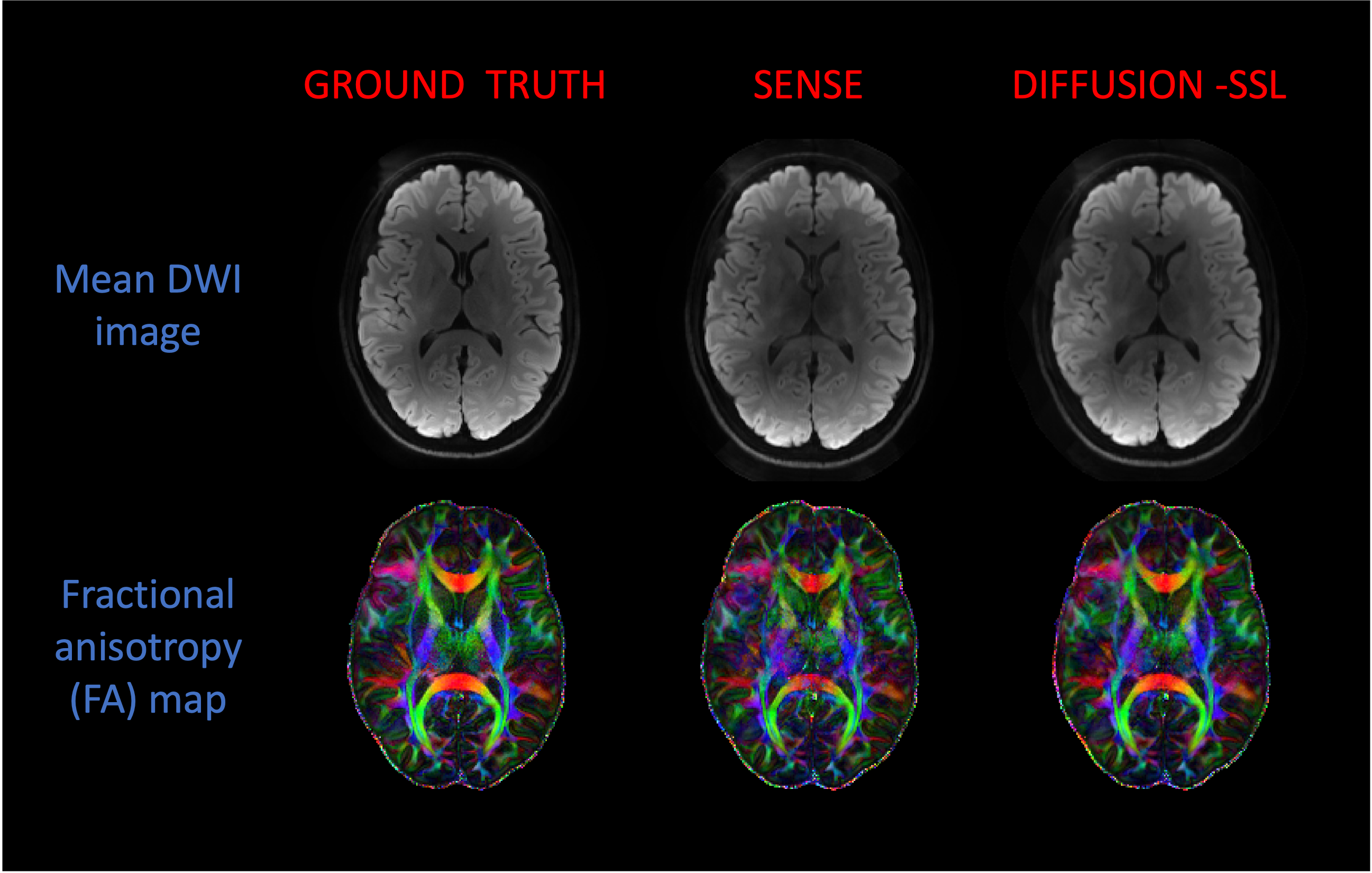
Figure 2 shows the reference and reconstructed diffusion images with three different directions using SENSE and our proposed method using a single EPI shot at R=5. We demonstrated that averaged over all diffusion directions, our method showed 1.28 times better than SENSE (12.9% vs. 16.6%) in terms of root mean square error (RMSE) relative to the 5-shot S-LORAKS reconstruction.Discussion and Conclusion
We have proposed Diffusion-SSL to apply the previously proposed ZS-SSL approach to diffusion MRI data. We trained a single network across different directions so that we can have a single network which can perform reconstruction for different directions. Our method leaves out a portion of directions as validation directions. This ensures that overfitting is prevented, so that the network can generalize well to previously unseen directions. We also compared the performance of our method with SENSE reconstructions, and saw that our method was able to further reduce the RMSE. Our method requires less computation time than the original method, since the original case would have to be trained on each direction separately.Acknowledgements
No acknowledgement found.References
[1] K. P. Pruessmann, M. Weiger, M. B. Scheidegger, and P. Boesiger, “SENSE: Sensitivity encoding for fast MRI,” Magn Reson Med, vol. 42, pp. 952–962, 1999.
[2] J. P. Haldar, "Low-Rank Modeling of Local k-Space Neighborhoods (LORAKS) for Constrained MRI," in IEEE Transactions on Medical Imaging, vol. 33, no. 3, pp. 668-681, March 2014, doi: 10.1109/TMI.2013.2293974.
[3] B. Yaman, S. A. H. Hosseini, M. Akcakaya, “Zero-Shot Self-Supervised Learning for MRI Reconstruction”, International Conference on Learning Representations, 2021
[4] C. Liao, B. Bilgic, Q. Tian, J. P. Stockmann, X. Cao, Q. Fan, S. S. Iyer, F. Wang, C. Ngamsombat, M. K. Manhard, S. Y. Huang, L. L. Wald, K Setsompop, “Distortion-free, high-isotropic-resolution diffusion MRI with gSlider BUDA-EPI and multicoil dynamic B0 shimming”, Magnetic Reson Med, vol. 86, no. 2, pp. 791-803, 2021
[5] H. K. Aggarwal, M. P. Mani and M. Jacob, "MoDL: Model-Based Deep Learning Architecture for Inverse Problems," in IEEE Transactions on Medical Imaging, vol. 38, no. 2, pp. 394-405, Feb. 2019, doi: 10.1109/TMI.2018.2865356.
Figures