0829
SubZero: Subspace Zero-Shot MRI Reconstruction1The Robotics Institute, Carnegie Mellon University, Pittsburgh, PA, United States, 2Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology, Cambridge, MA, United States, 3Athinoula A. Martinos Center for Biomedical Imaging, Massachusetts General Hospital, Charlestown, MA, United States, 4Department of Radiology, Harvard Medical School, Boston, MA, United States
Synopsis
Keywords: Image Reconstruction, Machine Learning/Artificial Intelligence, Deep Learning
Recently introduced zero-shot self-supervised learning (ZS-SSL) has shown potential in accelerated MRI in a scan-specific scenario, which enabled high quality reconstructions without access to a large training dataset. ZS-SSL has been further combined with the subspace model to accelerate 2D T2-shuffling acquisitions. In this work, we propose a parallel network framework and introduce attention mechanism to improve subspace based zero-shot self-supervised learning and enable higher acceleration factors. We name our method SubZero and demonstrate that it can achieve improved performance compared with current methods in T1 and T2 mapping acquisitions .Introduction
Deep learning methods have proven to be powerful in MRI reconstruction. However, they often require large training data which is not always available, and differences in anatomy/pathology between the training and test data may lead to poor generalization. Yaman et al.1 proposed a zero-shot self-supervised learning method(ZS-SSL) for scan-specific MRI reconstruction which has been further extended by incorporating T2-shuffling forward model(ZSSSSub). The ZSSSSub method outperforms standard T2-shuffling and ZS-SSL by modifying the forward model and keeping the original network structure of ZS-SSL. We demonstrate that a tailored network structure may achieve better results beyond those obtained with ZSSSSub. In this abstract, we propose SubZero which introduces a parallel network framework inspired by the previous work2 and leverages the attention mechanism. Vivo reconstruction experiments suggest that SubZero outperforms current works at high acceleration rates of R=8-10.Methods
Zero-shot self-supervised learning (ZS-SSL)ZS-SSL split the undersampled kspace data $$$\Omega$$$ into three subsets: $$$\Theta$$$ for the data consistency units, $$$\Lambda$$$ for k-space training loss in self-supervision and $$$\Gamma$$$ for automated early stopping. The reconstruction process can be formulated into two sub-problems3:
$$\textbf{z}^{(i-1)}=\arg\min_{\textbf{z}}\mu\|\textbf{x}^{(i-1)}-\textbf{z}\|^2_2+R(\textbf{z})$$$$\textbf{x}^{(i)}=\arg\min_{\textbf{x}}\|\textbf{y}_\Omega-\textbf{E}_\Omega \textbf{x}\|^2_2+\mu\|\textbf{x}-\textbf{z}^{(i-1)}\|^2_2$$
Subspace model based ZSSS (ZSSSSub)
Subspace method first assembles the signal evolution into a dictionary and then approximates the low rank subspace $$$\Phi$$$ using singular vector decomposition (SVD). The T1 or T2 weighted images $$$x$$$ to be reconstructed can be projected onto $$$\Phi$$$ and yield coefficients $$$\alpha$$$, where $$$x\in C^{M\times N\times T}$$$, $$$\Phi \in C^{T\times B}$$$, $$$\alpha \in C^{M\times N\times B}$$$, and $$$M$$$, $$$N$$$ are the number of voxels in readout and phase encoding directions, $$$T$$$ is echo number and $$$B$$$ is basis number. The subspace forward model can be written as $$$y=RFS\Phi\alpha$$$, where $$$y\in C^{M\times N\times C\times T}$$$ is the acquired kspace data, $$$R$$$ is the undersampling mask, $$$S$$$ is the coil sensitivity map and $$$F$$$ is the Fourier operator. ZSSSSub incorporates low rank subspace model into ZSSS and can be formulated as4:
$$\textbf{z}^{(i-1)}=\arg\min_{\textbf{z}}\mu\|\alpha^{(i-1)}-\textbf{z}\|^2_2+R(\textbf{z})$$$$\alpha^{(i)}=\arg\min_{\alpha}\|\textbf{y}_\Omega-\textbf{E}_\Omega \Phi \alpha\|^2_2+\mu\|\alpha-\textbf{z}^{(i-1)}\|^2_2$$
Proposed method (SubZero)
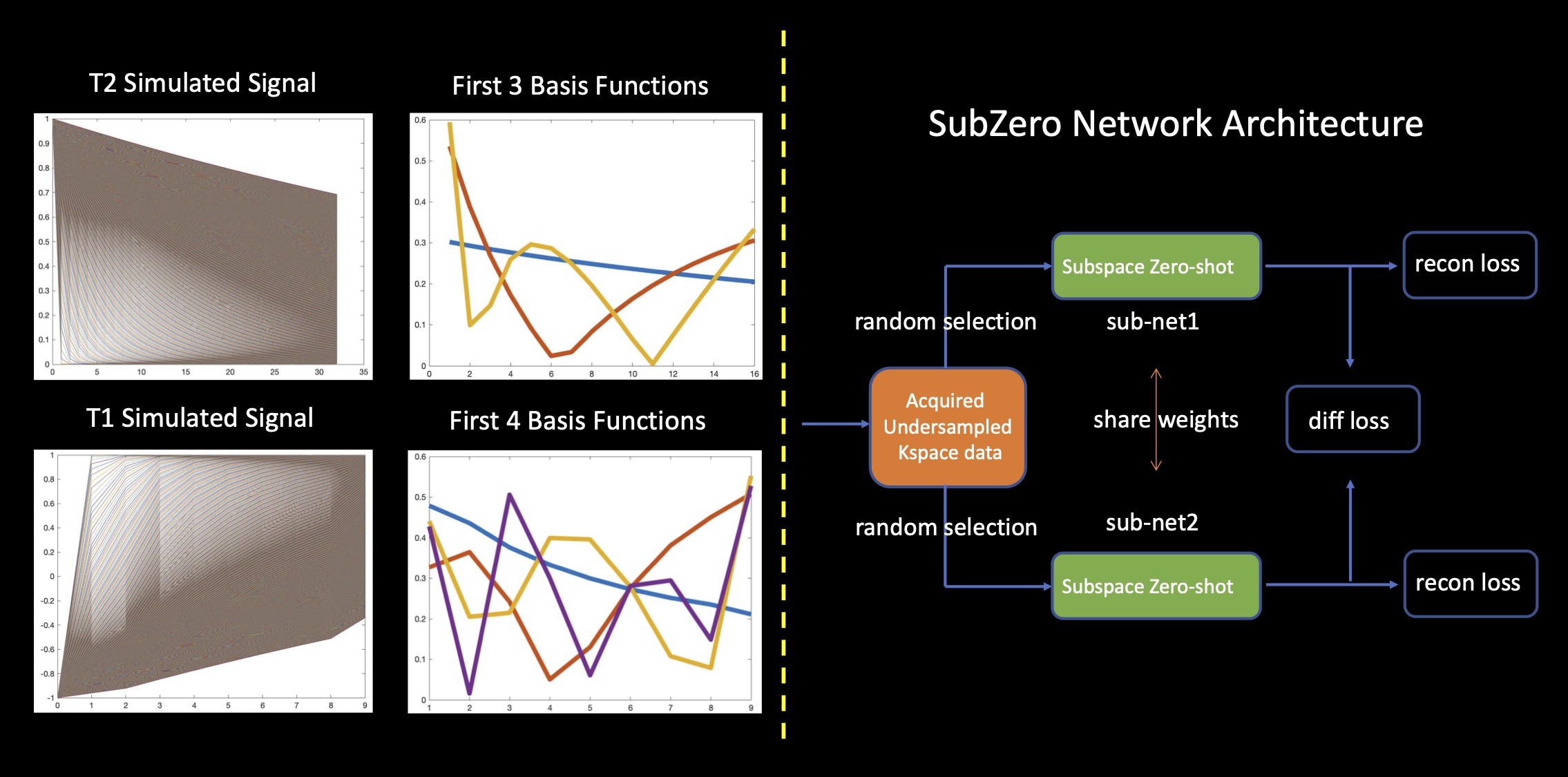
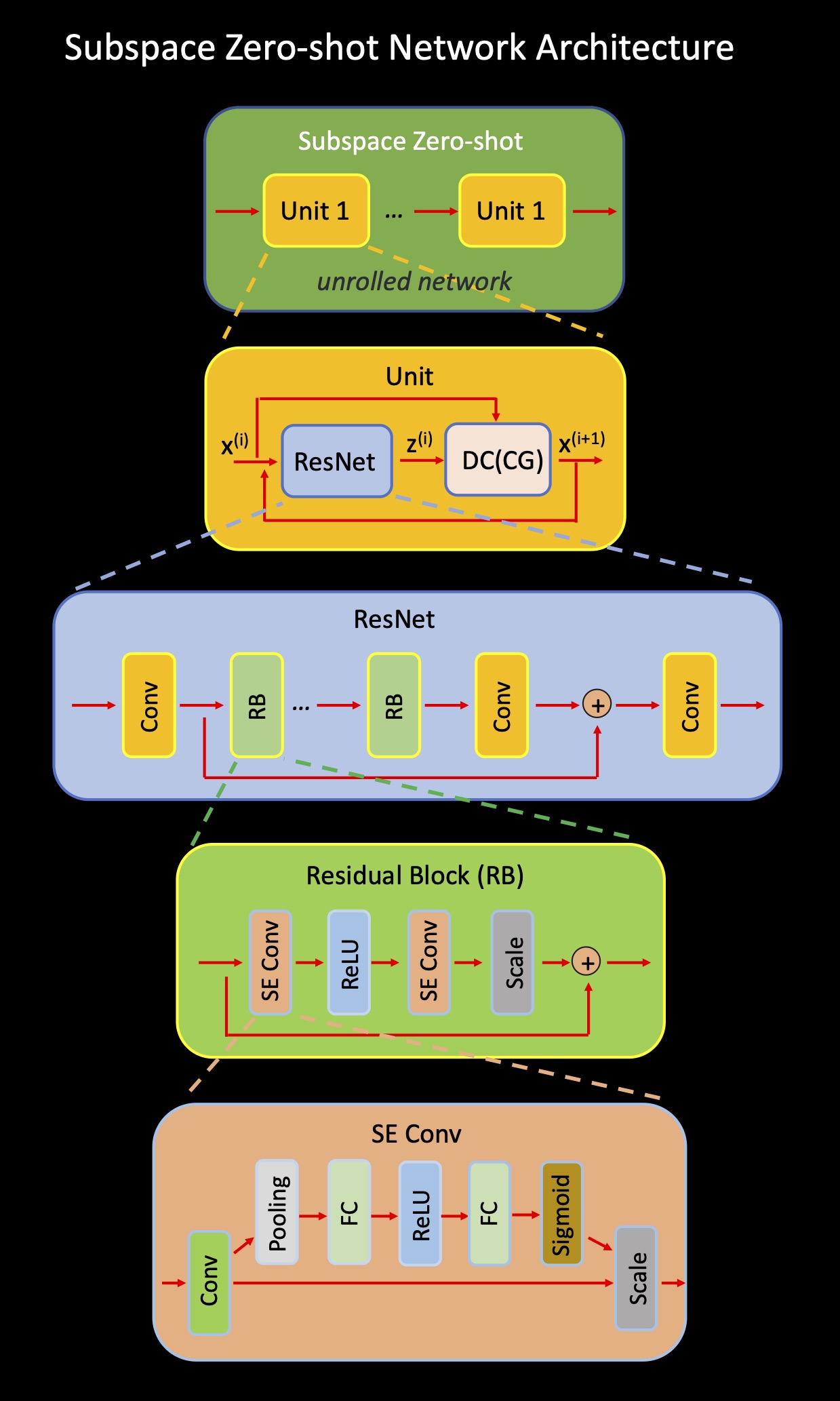
Our SubZero has two parallel sub-networks as shown in Figure 1. The two sub-networks have the same structure and share weights. Each sub-network can be seen as a ZSSSSub module as shown in Figure 2 and we replace the traditional convolution with Squeeze-and-Excitation (SE) convolution proposed in the previous work5 which introduces attention mechanism to help better learn the proper features. SE convolution performs a squeeze operation to get a single value for each channel of the input feature map and then learns per-channel weights using an excitation operation. The final output of the SE convolution is obtained by rescaling the feature map with these per-channel weights. The automated early stopping mask $$$\Gamma$$$ is the same for two sub-networks and $$$\Theta$$$, $$$\Lambda$$$ are randomly selected from $$$\Omega \backslash \Gamma$$$ for each sub-network. The total loss consists of reconstruction loss and difference loss as follows:
$$L=L^{recon}_1+L^{recon}_2+L^{diff}$$
$$$L^{recon}_i$$$($$$i \in {1, 2}$$$ from individual sub-networks) is the same as ZSSSSub and $$$L^{diff}$$$ forces the reconstruction results from two sub-networks to be consistent in $$$\Omega \backslash (\Theta \cup \Lambda)$$$. Note $$$\Omega \backslash (\Theta \cup \Lambda)$$$ as $$$\Delta$$$, $$$X^{(1)}$$$ and $$$X^{(2)}$$$ as the reconstruction results from two sub-networks, we have:
$$L^{diff}=MSE(X^{(1)}_\Delta, X^{(2)}_\Delta)$$
We also use a novel approach to mask generation when dividing $$$\Theta$$$ and $$$\Lambda$$$ during the training process. Given a pre-defined ratio $$$r$$$, we randomly generate the division mask among all the echoes since we use T1 or T2 series data to provide complementary information while keeping the whole mask ratio as $$$r$$$. This online data augmentation introduces more diversity during training. We also shift the under-sampling mask $$$\Omega$$$ among echoes to achieve better performance.
Experiments and Results
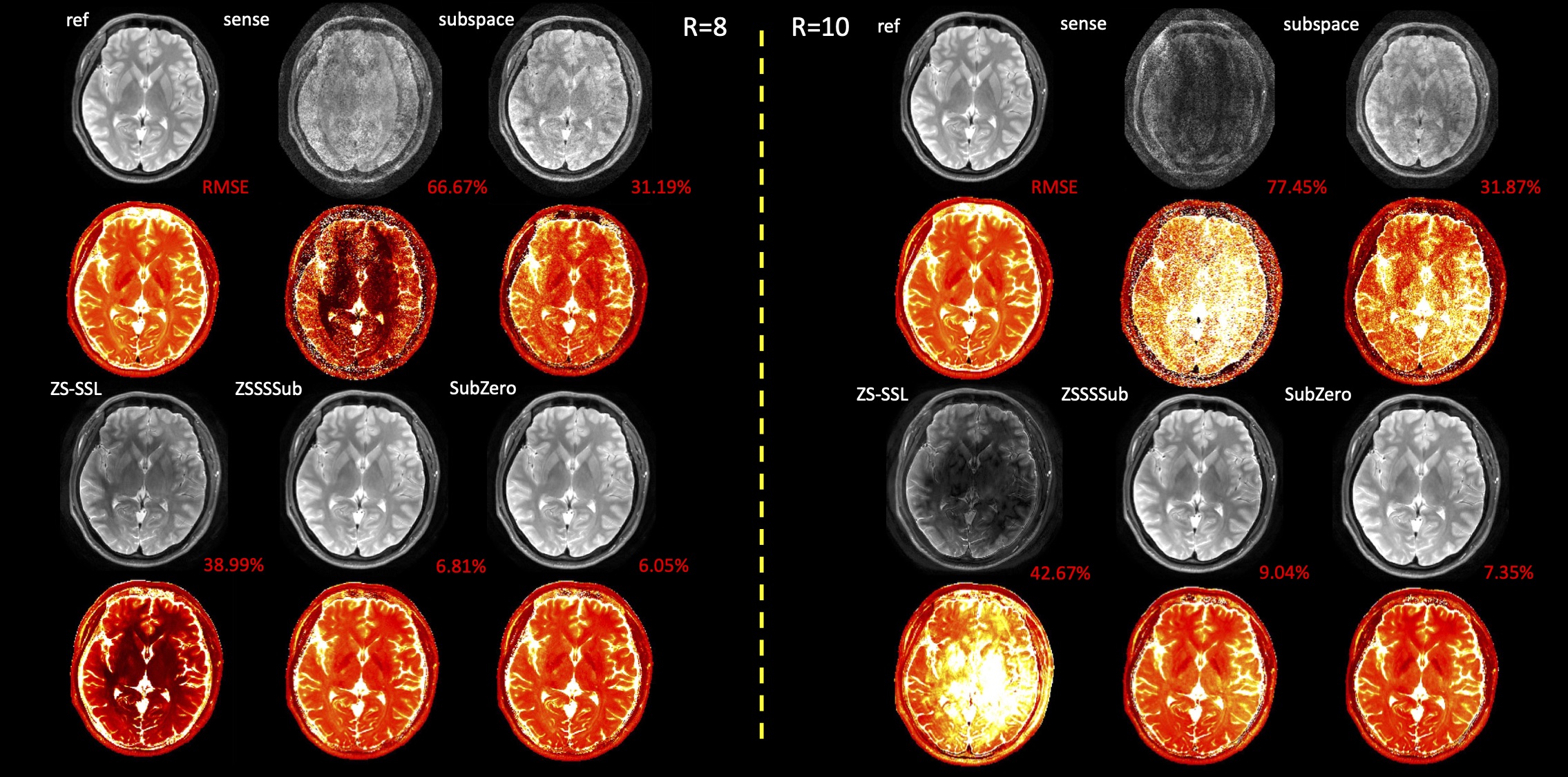
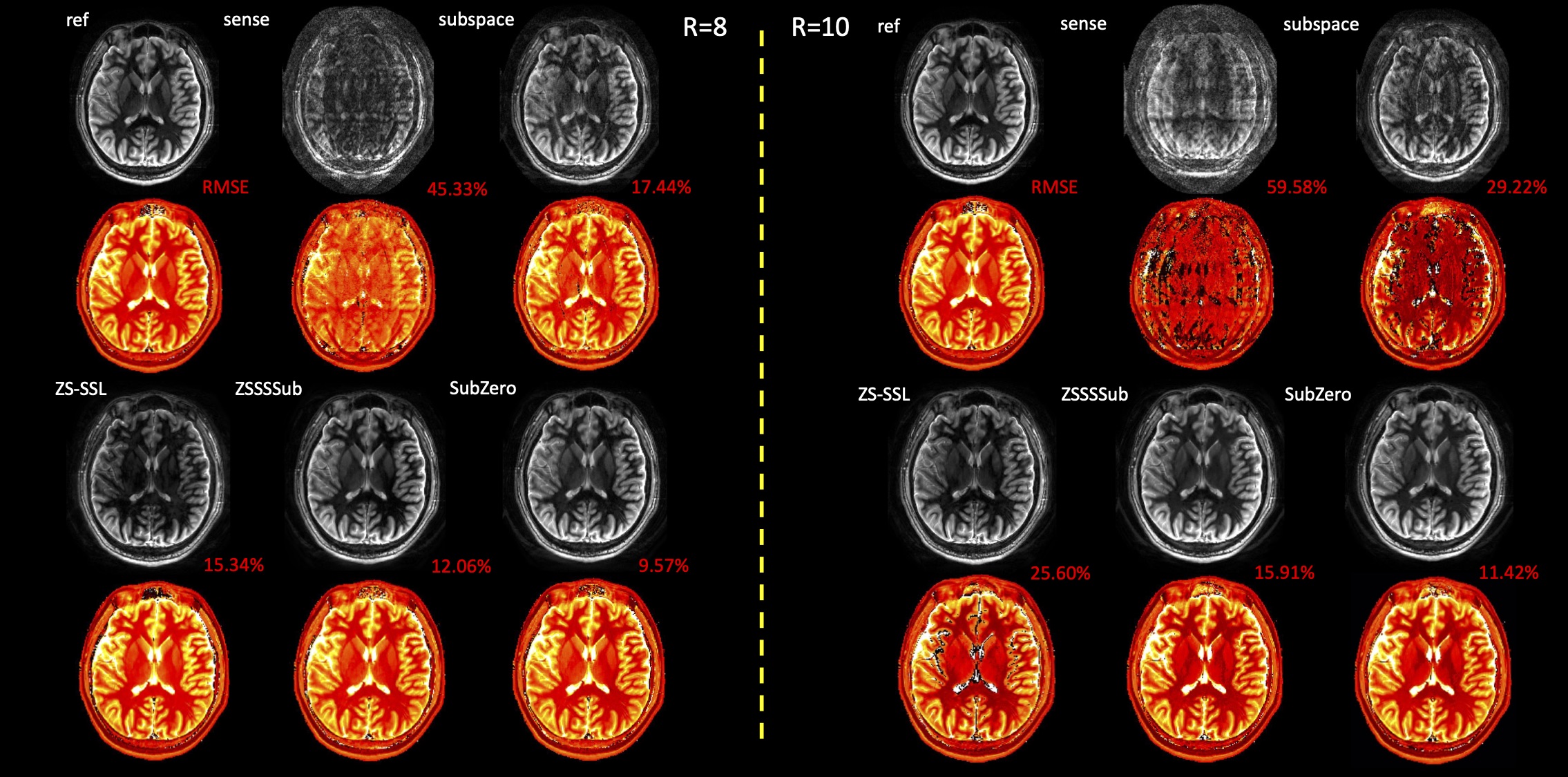
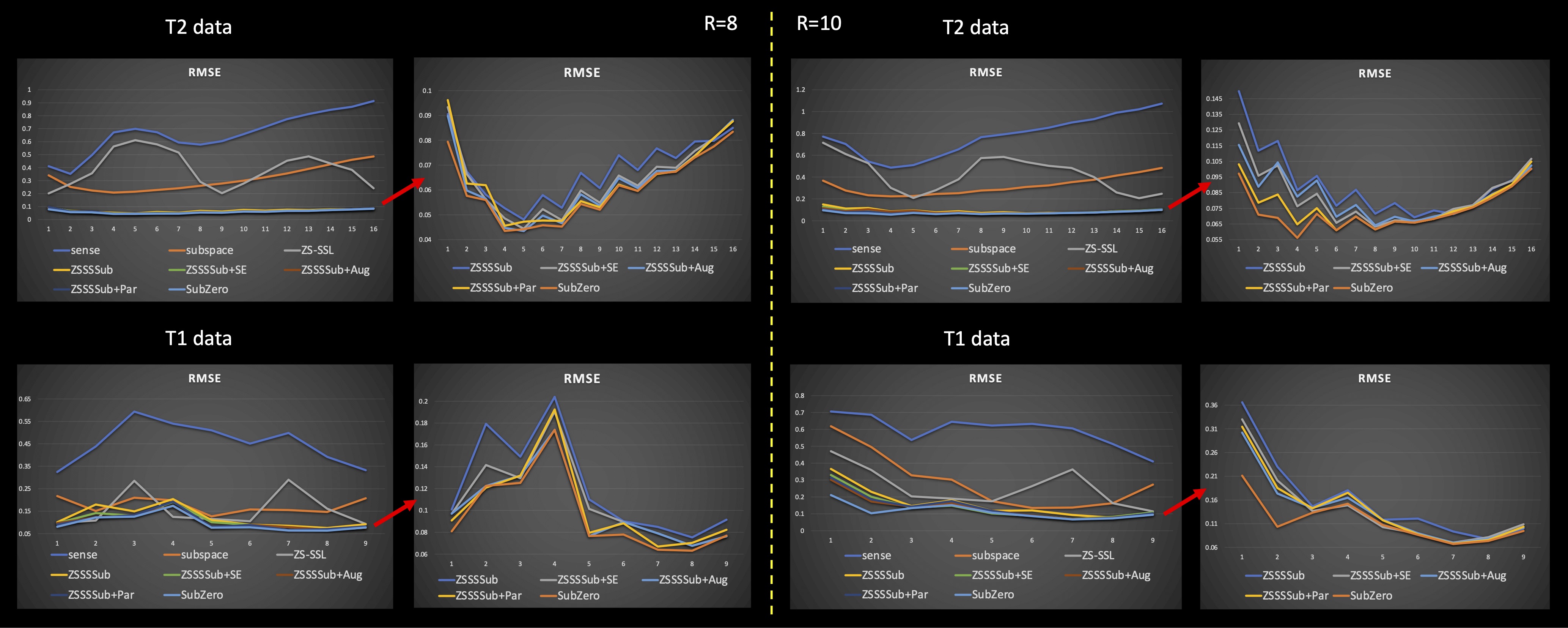
We conduct experiments using T2 and T1-weighted images. T2-weighted multi-echo spin echo data includes 16 echoes with 12 channels and TE=11.5-368 ms($$$\Delta$$$TE=11.5 ms). The full FOV is $$$256 \times 208$$$ and we take $$$B=3$$$ for SVD of simulated signal dictionary. T1-weighted inversion recovery turbo spin echo data includes 9 inversion times(TIs) with 32 channels and TI=100-2000 ms. The full FOV is $$$256 \times 192$$$ and we take $$$B=4$$$ for SVD of simulated signal dictionary. We use acceleration rates of R 8 and 10 along the phase encoding direction for both T2 and T1-weighted image data. For SubZero model, we set unrolled block number 5, resnet block number 10, and iteration of conjugate gradient(CG) 5. From Figures 3 and 4 we can see that SubZero outperforms other models at varying acceleration rates. We also perform ablation experiments to show each of our proposed modules can help improve the performance in Figure 5. Incorporating SE convolution, using online data augmentation method and using a parallel framework with each sub-network are all effective to improve the performance of ZSSSSub and each can achieve up to 2-fold RMSE gain.Code/data: https://anonymous.4open.science/r/SubZero-2891.
Discussion and Conclusion
In this abstract, we propose SubZero method which incorporates subspace model into a zero-shot self-supervised learning framework by using a parallel network and attention mechanism along with a new online data augmentation method. We conduct experiments on multi-echo T2 and multi-inversion T1-weighted images and perform ablation studies of each proposed module. Experimental results demonstrate reductions of up to 4-fold RMSE over ZS-SSL, 3-fold over ZSSSSub using SubZero, especially at higher acceleration rates.Acknowledgements
This work was supported by research grants NIH R01EB028797, R01EB032378, U01EB025162, P41EB030006, U01EB026996, R03EB031175 and the NVidia Corporation for computing support.References
1. Yaman, Burhaneddin, Seyed Amir Hossein Hosseini, and Mehmet Akcakaya. "Zero-Shot Self-Supervised Learning for MRI Reconstruction." International Conference on Learning Representations. 2021.
2. Hu, Chen, et al. "Self-supervised learning for mri reconstruction with a parallel network training framework." International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021.
3. Yaman, Burhaneddin, et al. "Self‐supervised learning of physics‐guided reconstruction neural networks without fully sampled reference data." Magnetic resonance in medicine 84.6 (2020): 3172-3191.
4. Zhang, Molin, et al. “Zero-Shot Self-Supervised Learning for 2D T2-shuffling MRI Reconstruction.” Proceedings of the International Society of magnetic Resonance in Medicine (ISMRM), 2022.
5. Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
Figures