0077
A Novel Cross-Subject Transformer Denoising Method1College of Health Science and Environmental Engineering, ShenZhen Technology University, Shenzhen, China, 2Laboratory of Biomedical Imaging and Signal Processing, The University of Hong Kong, Hong Kong, China, 3Department of Electrical and Electronic Engineering, The University of Hong Kong, Hong Kong, China
Synopsis
Keywords: Data Processing, Modelling, Deep learning, Denoise
In this work, we propose a new denoising method named Cross-Subject Transformer Denoising (CSTD), which transfers the texture of a reference image retrieved from a large database to the noisy image with soft attention mechanisms. The experiments on the fastMRI dataset with various noise levels show that our method is likely superior to many competing denoising algorithms including current the state-of-the-art NAFNet. Moreover, our method exhibits excellent generalizability when directly applied to in-vivo low-field data without retraining. Due to the flexibility, the method is expected to have a wide range of applications.Introduction
Denoising algorithms can be divided into two categories: internal denoising and external denoising1. The latter utilizes external clean images as auxiliary information and is also known as reference-based denoising.While internal denoising presents satisfactory solutions to many applications, external denoising can be advantageous when noise is high and clean references are at hand. In fact, external denoising is particularly suitable for MRI. Clean reference images can be collected from the same subjects2. Alternatively, we note that it is possible to utilize existing MRI databases since anatomical structures are similar across subjects to certain degrees.
However, most existing external denoising methods such as TID3 suffer from the following limitations. (1) Patches are matched in image space, being not as efficient and robust as in high-level feature space. (2) Domain knowledge cannot be well learned in advance, benefiting little from big data.
Here, we propose a new attention-based external denoising method named Cross-Subject Transformer Denoising (CSTD). For a given noisy image, this method first retrieves clean reference images from a large database, then extracts, correlates, and fuses their deep texture features with soft attention, and lastly decodes the fused features to a denoised image. This method effectively utilizes big data, leading to excellent performance in MRI denoising tasks.
Methods
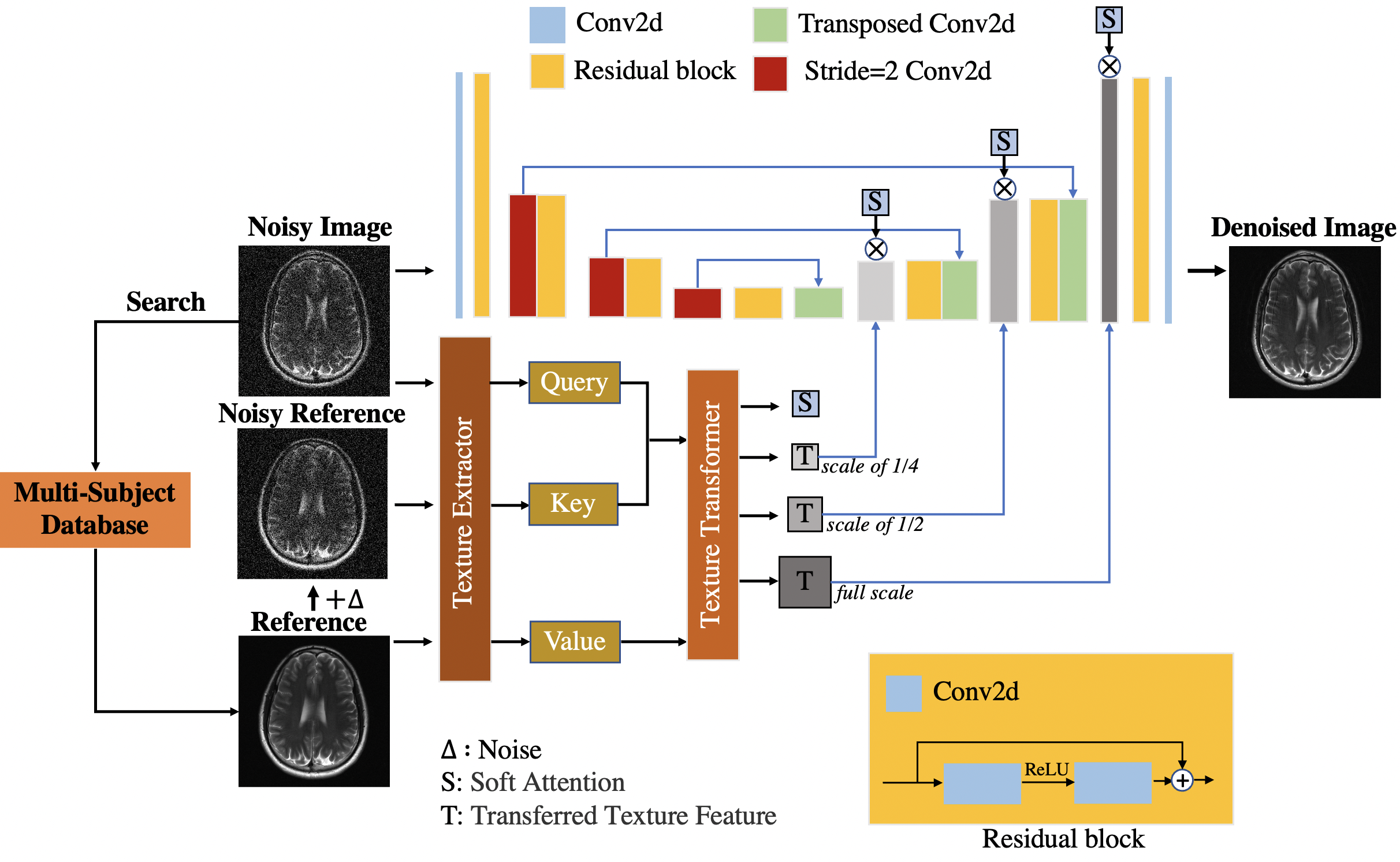
The proposed Cross-Subject Transformer Denoising (CSTD) method is schematically illustrated in Figure 1. It mainly includes a reference image retrieval module and a denoising network module.1. Reference image retrieval module
To accelerate the search, every reference image is vectorized to the length of 2048 using ResNet50, resulting in a prebuilt reference database. For an input noisy image $$$X$$$, we also vectorize it and search the database for the best reference image in terms of least L2 distance using FAISS4 library. This step is highly efficient due to vectorization, costing less than a second even if the number of images is more than a million.
2. Denoising network module
The proposed CSTD network has three key parts: texture extractor, texture transformer, and encoder-decoder. The former two were inspired by TTSR5,6 which was designed for super-resolution tasks.
The texture extractor converts raw images to deep texture features in three scales (1, 1/2 and 1/4). Currently we use VGG19. To facilitate feature correlation later, Gaussian noise Δ was added to $$$Ref$$$, such that the resulting $$$Ref^Δ$$$ has comparable noise level to the input noisy image $$$X$$$.
$$Ref^Δ=Ref+Δ$$
Then $$$X$$$, $$$Ref$$$ and $$$Ref^Δ$$$ are fed to the texture extractor to obtain multiscale query (Q), key (K) and value (V) features, respectively.
$$Q=TE(X), K=TE(Ref^Δ), V=TE(Ref)$$
The texture transformer estimates the feature correlation between Q and K by inner product and locates the most correlated features in V. Note that for each location in Q the correlation is estimated globally on all locations in K. Thus, the transferred multiscale texture features $$$T^n$$$(n for three scales of 1, 1/2 and 1/4) are formed by the most correlated features in V, and the soft attention map S is formed by the highest correlation value in K.
The encoder-decoder is based on a UNet7 with 3 down/upsampling stages. We fuse the multiscale transferred features $$$T^n$$$ with the UNet decoder in a novel way: at each upsampling stage, the UNet derived features $$$F^n$$$ are concatenated with $$$T^n$$$, convoluted once, and multiplied by the soft attention map S. These fused features finally go through a squeeze-and-excite (SE)8 attention layer before next upsampling stage. In summary, the fusion operation on each stage is
$$F^{n}_{fused} = SE(Conv(Concat(F^n,T^n))*S)+F^n$$
The final denoised image is obtained through a convolution layer after the last upsampling stage.
3. Network training and evaluation
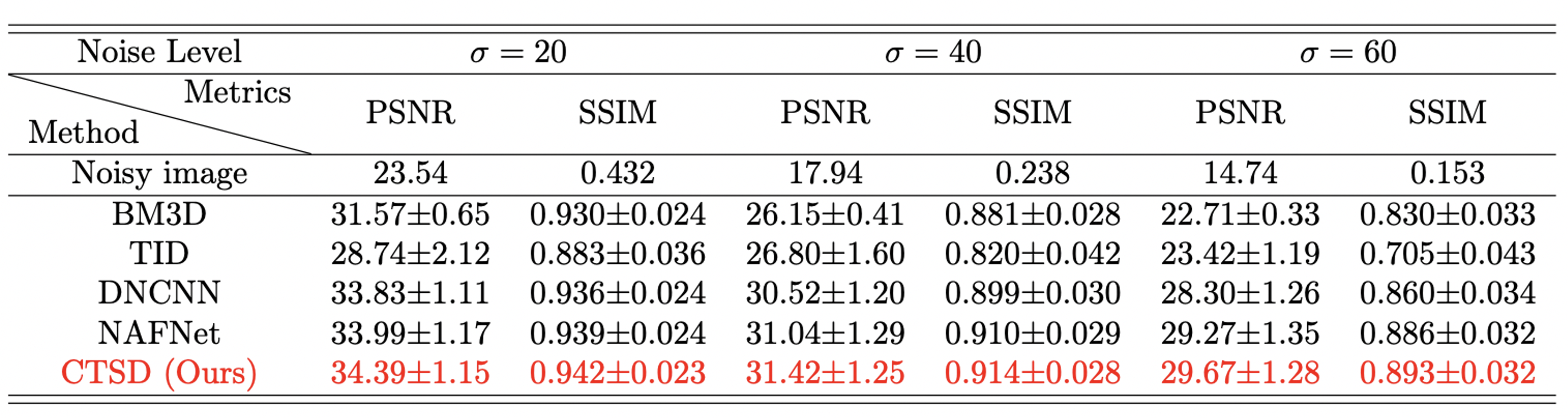
The proposed CSTD network was trained and evaluated on fastMRI9 brain dataset (see Figure 2 caption for details). For comparison, DNCNN10 and NAFNet11 were trained similarly without reference images. Traditional denoising methods BM3D12 and TID were also evaluated.
4. Robustness test
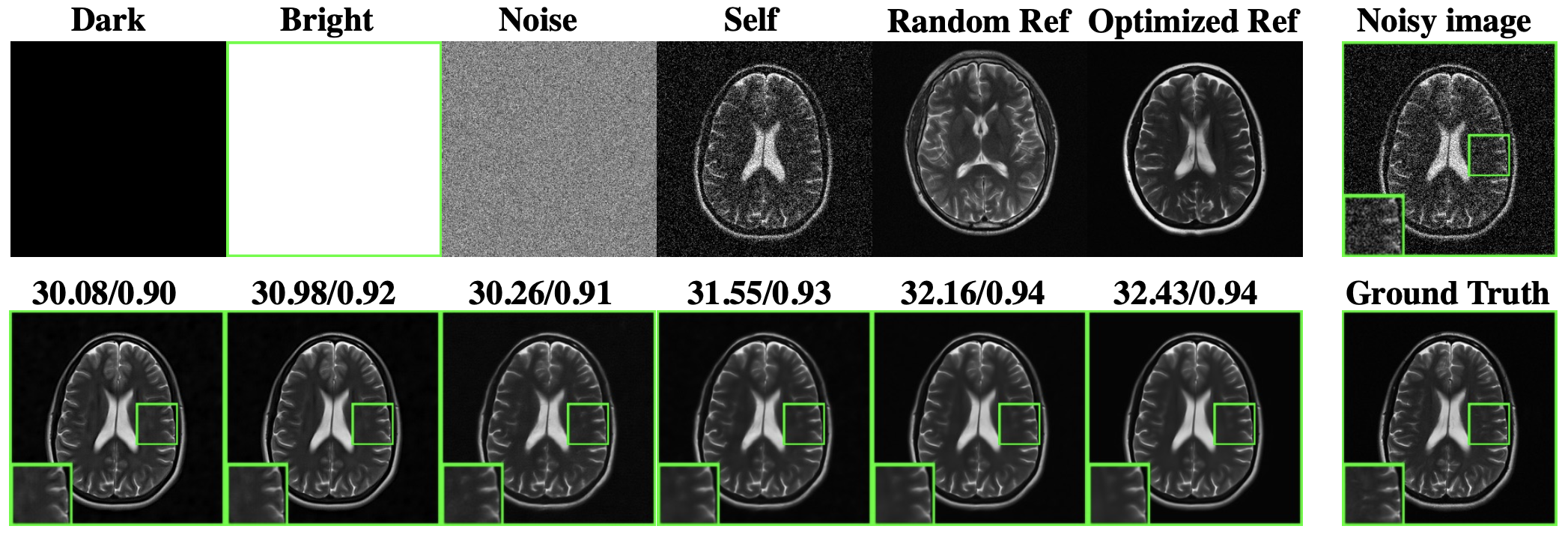
(1) We investigated the robustness of CSTD by using less similar reference images.
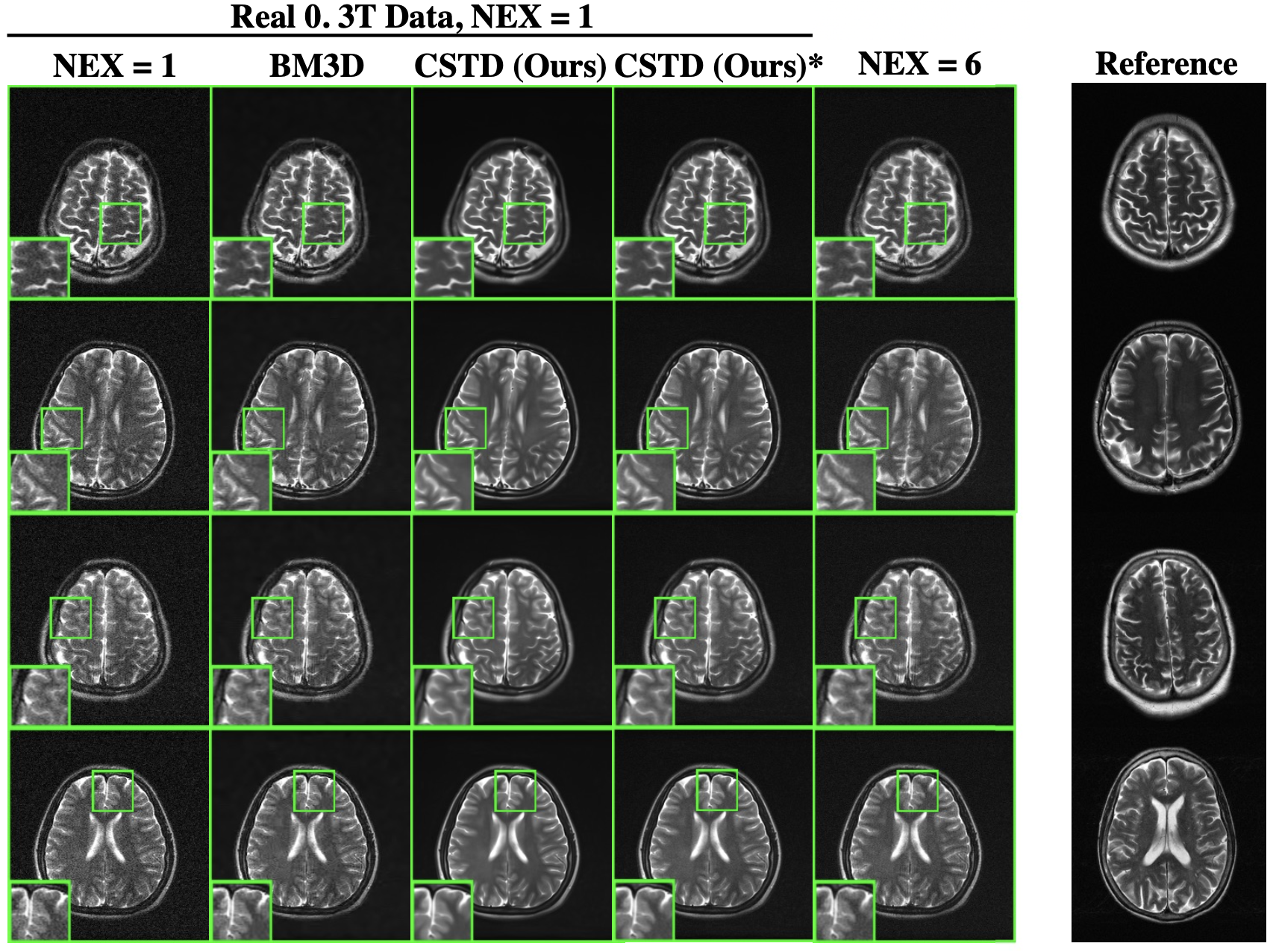
(2) To further demonstrate generalization ability, we applied the CSTD model to denoise real 0.3T brain data without retraining (See Figure 5 caption for details).
Results
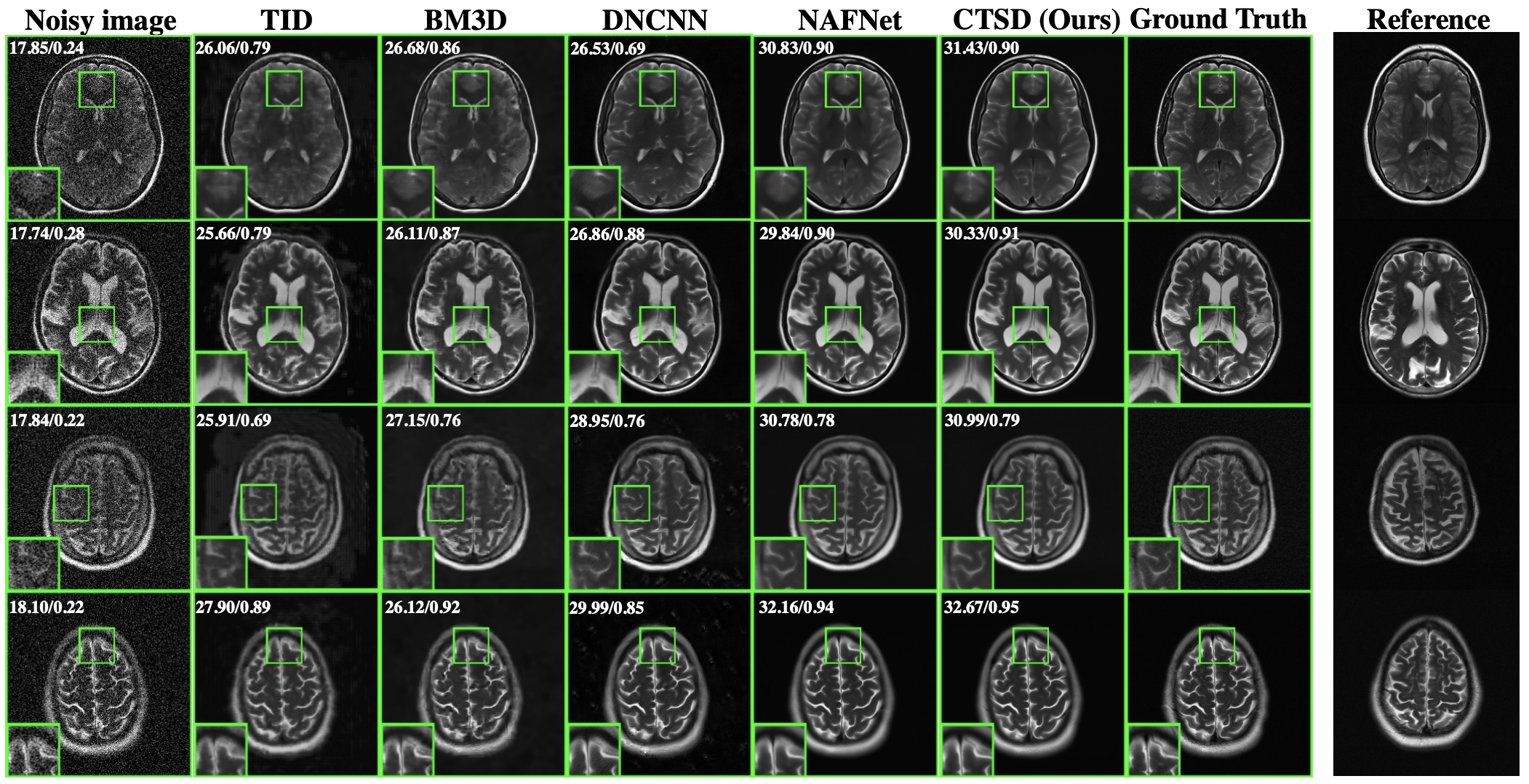
Our method achieved the highest PSNR and SSIM values among all evaluated methods (Figure 2). These numbers agree with the visual inspection of image quality (Figure 3). Our method can be influenced if suboptimal references are used, yet even in extreme cases, it performed reasonably well (Figure 4). In particular, it performed robustly on the real low-field data, and the NEX=1 images after CSTD denoising were visually comparable or better than NEX=6 images (Figure 5).Discussion and Conclusion
Preliminary results indicate our method is very robust, even in comparison to the current state-of-the-art NAFNet. Note that we used a simple implementation of the encoder-decoder and transformer, leaving large room to borrow more advanced structures such as those in NAFNet and Restormer13. The results may also improve if multiple reference images are used. This method is widely applicable. It does not rely on additional acquisition from the same subject, nor require image co-registration. Moreover, in the era of big data, it could continuously benefit from the growth of MRI database.Acknowledgements
This study is supported in part by Natural Science Foundation of Top Talent of Shenzhen Technology University (Grants No. 20200208 to Lyu, Mengye) and the National Natural Science Foundation of China (Grant No. 62101348 to Lyu, Mengye)References
[1]. Buades, A., Coll, B. & Morel, J.-M. A review of image denoising algorithms, with a new one. Multiscale modeling & simulation 4, 490-530 (2005).
[2]. Hu, J., Liu, Y., Yi Z., Y Zhao, Y., Chen, F., & Wu, E. X. (2021). Adaptive Multi-contrast MR Image Denoising based on a Residual U-Net using Noise Level Map. In ISMRM (International Society of Magnetic Resonance Imaging) Virtual Conference & Exhibition, 2021. International Society of Magnetic Resonance Imaging (ISMRM)..
[3]. Luo, E., Chan, S. H., & Nguyen, T. Q. (2014, May). Image denoising by targeted external databases. In 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2450-2454). IEEE.
[4]. Johnson, J., Douze, M., & Jégou, H. (2019). Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3), 535-547.
[5]. Lyu, M., Deng, G., Zheng, Y., Liu, Y., & Wu, E. X. (2021). MR image super-resolution using attention mechanism: transfer textures from external database. In ISMRM (International Society of Magnetic Resonance Imaging) Virtual Conference & Exhibition, 2021. Internationala Society of Magnetic Resonance Imaging (ISMRM)..
[6]. Yang, F., Yang, H., Fu, J., Lu, H., & Guo, B. (2020). Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5791-5800).
[7]. Zhang, K., Li, Y., Zuo, W., Zhang, L., Van Gool, L., & Timofte, R. (2021). Plug-and-play image restoration with deep denoiser prior. IEEE Transactions on Pattern Analysis and Machine Intelligence.
[8]. Vosco, N., Shenkler, A., & Grobman, M. (2021). Tiled Squeeze-and-excite: Channel attention with local spatial context. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 345-353).
[9]. Zbontar, J., Knoll, F., Sriram, A., Murrell, T., Huang, Z., Muckley, M. J., ... & Lui, Y. W. (2018). fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv preprint arXiv:1811.08839.
[10]. Zhang, K., Zuo, W., Chen, Y., Meng, D., & Zhang, L. (2017). Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE transactions on image processing, 26(7), 3142-3155.
[11]. Chen, L., Chu, X., Zhang, X., & Sun, J. (2022). Simple baselines for image restoration. arXiv preprint arXiv:2204.04676.
[12]. Danielyan, A., Katkovnik, V., & Egiazarian, K. (2011). BM3D frames and variational image deblurring. IEEE Transactions on image processing, 21(4), 1715-1728.
[13]. Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S., & Yang, M. H. (2022). Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5728-5739).
Figures