Vision Transformers in Medical Imaging
1Bilkent University, Turkey
Synopsis
Deep learning models have been swiftly established as state-of-the-art in recent years for difficult medical image formation and analysis tasks such as reconstruction, synthesis, super-resolution and segmentation. A critical design consideration for model architectures is the capacity to account for representation errors that comprise both locally- and globally-distributed elements. While convolutional models with static local filters have been widely adopted due to their computational benefits, they lack in sensitivity for contextual or anomalous features. Instead, the recently emerging vision transformers are equipped with global attention operators as a universal mixing primitive for minimizing representation errors in diverse medical imaging tasks.
 Slide #1
Slide #1 Slide #2
Slide #2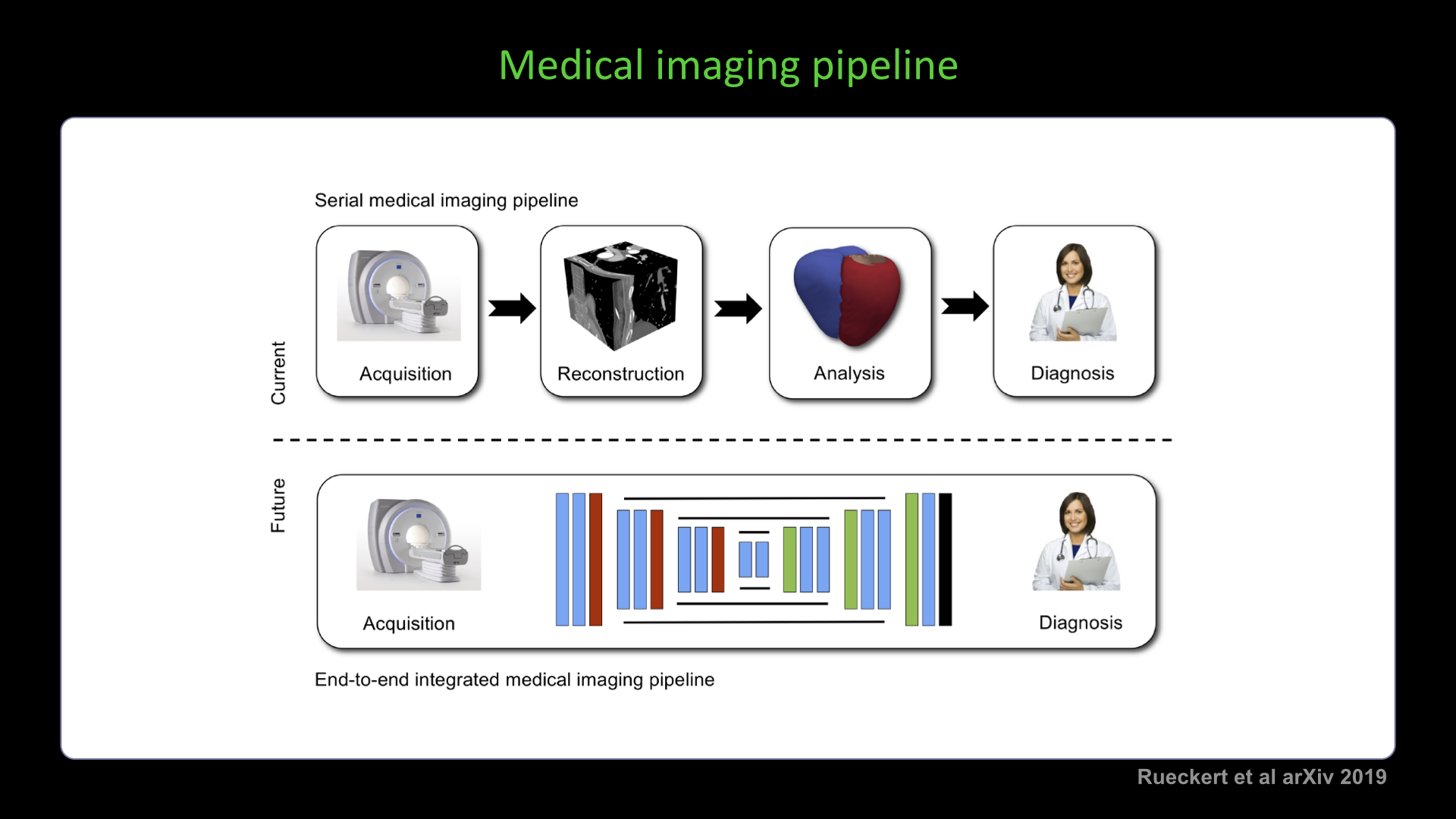 Slide #3
Slide #3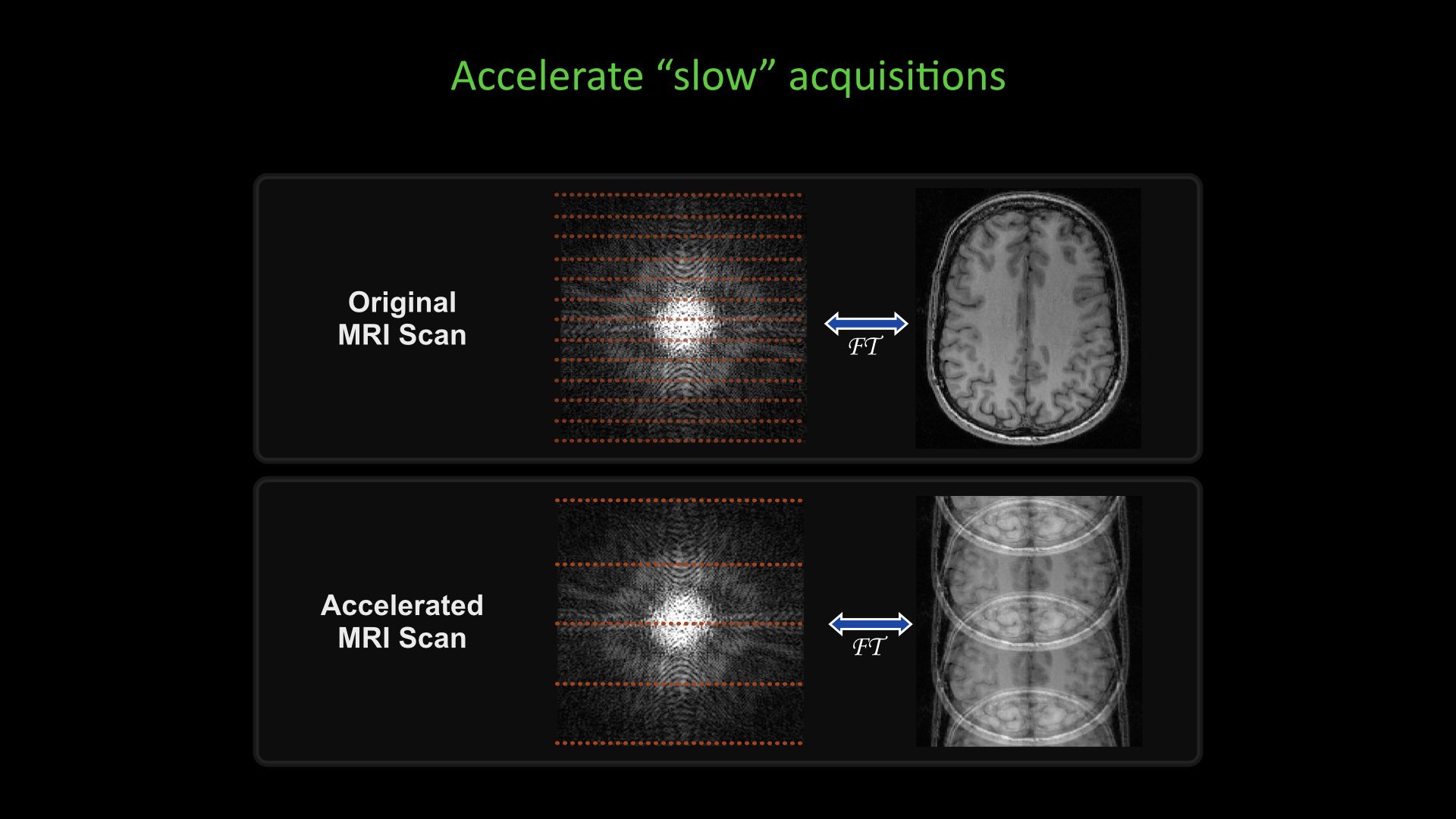 Slide #4
Slide #4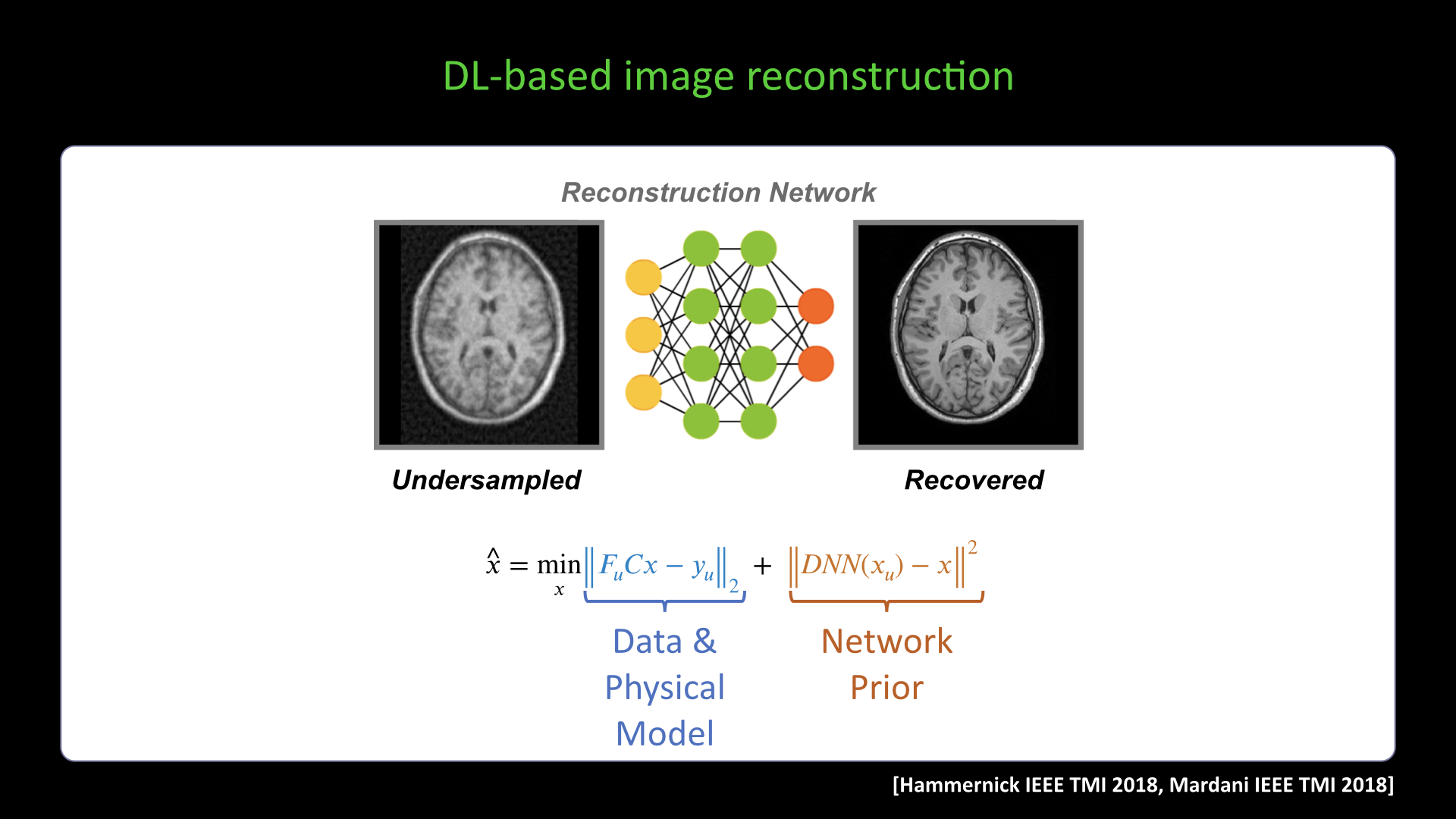 Slide #5
Slide #5 Slide #6
Slide #6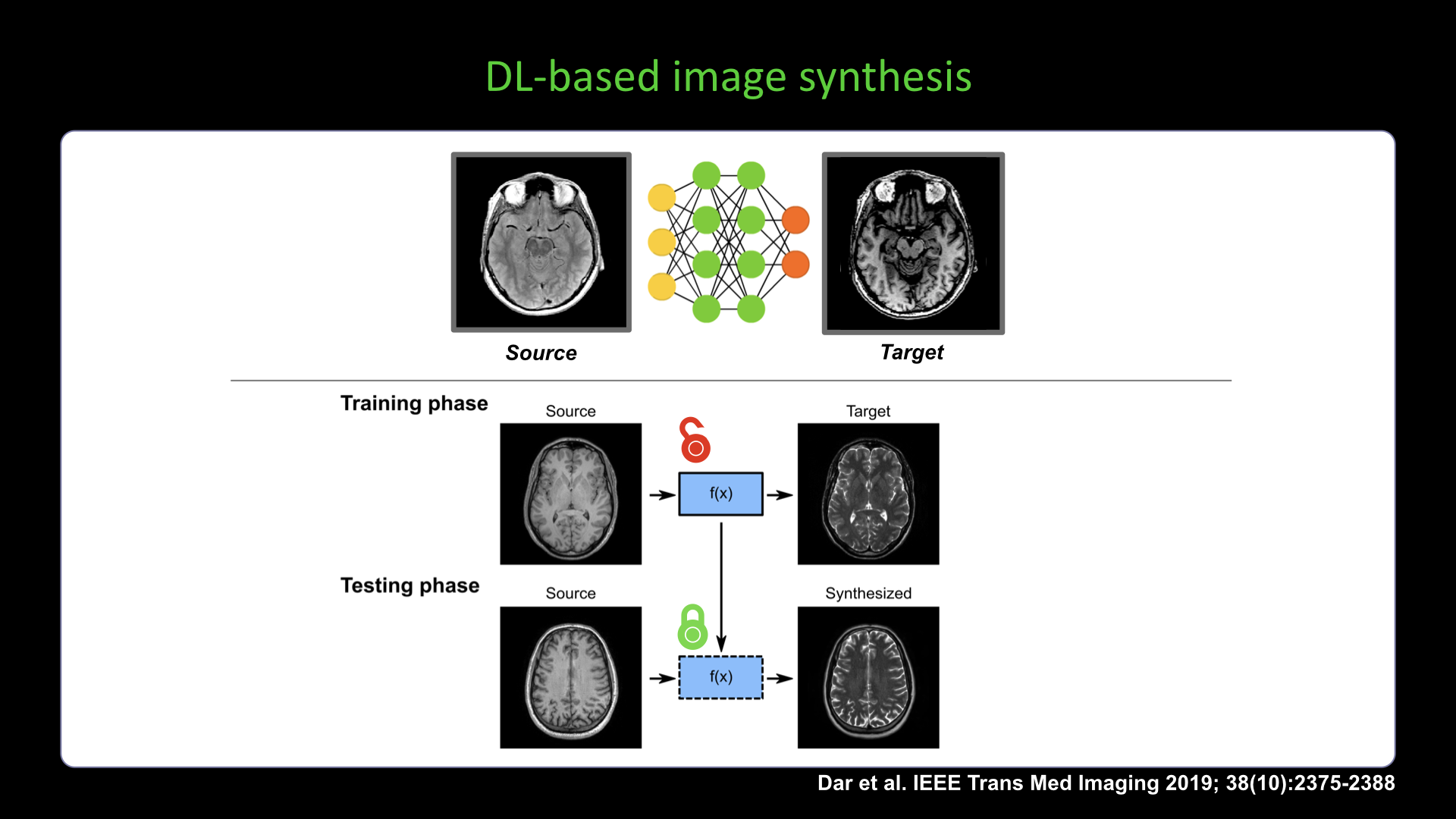 Slide #7
Slide #7 Slide #8
Slide #8 Slide #9
Slide #9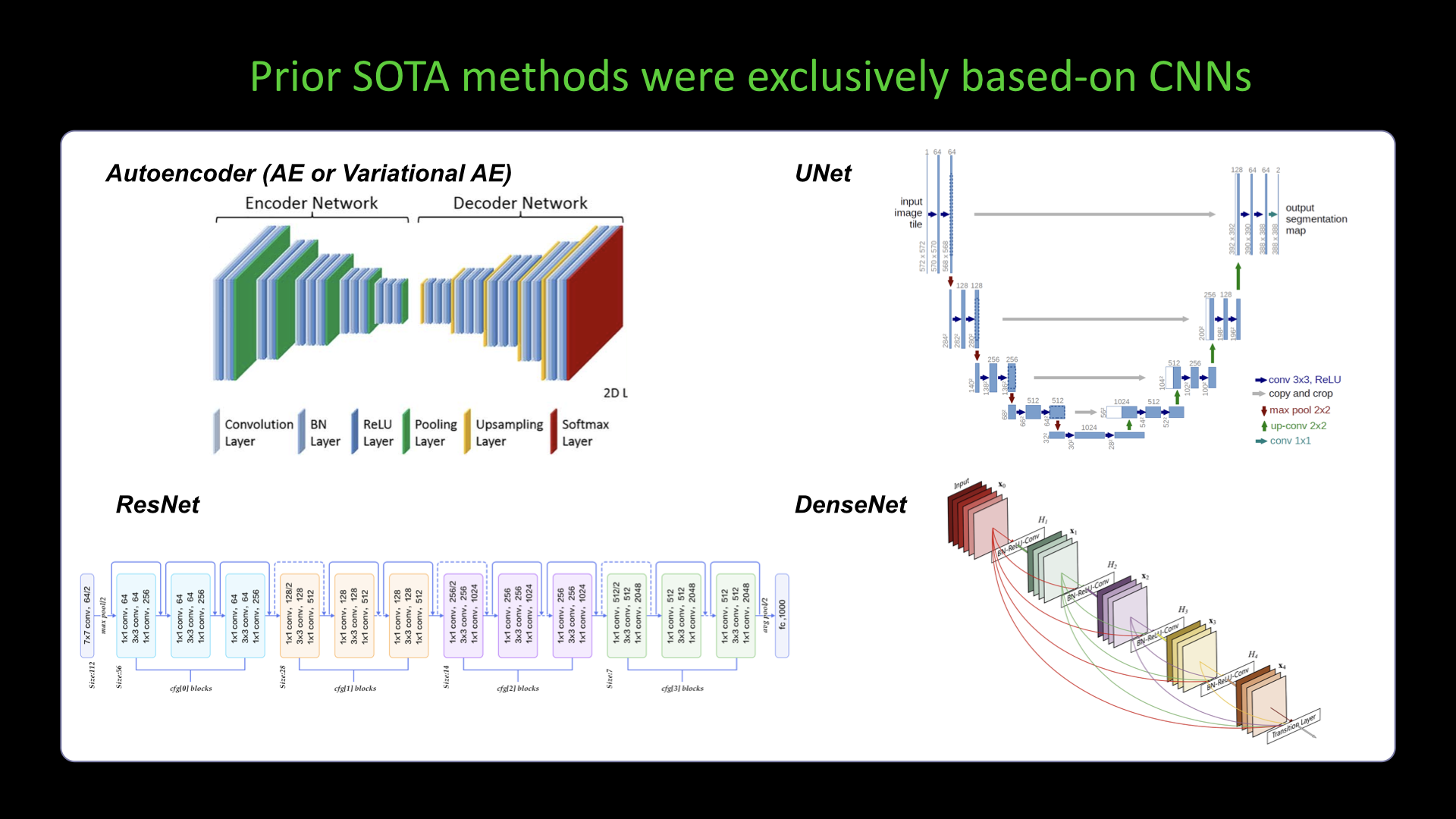 Slide #10
Slide #10 Slide #11
Slide #11 Slide #12
Slide #12 Slide #13
Slide #13 Slide #14
Slide #14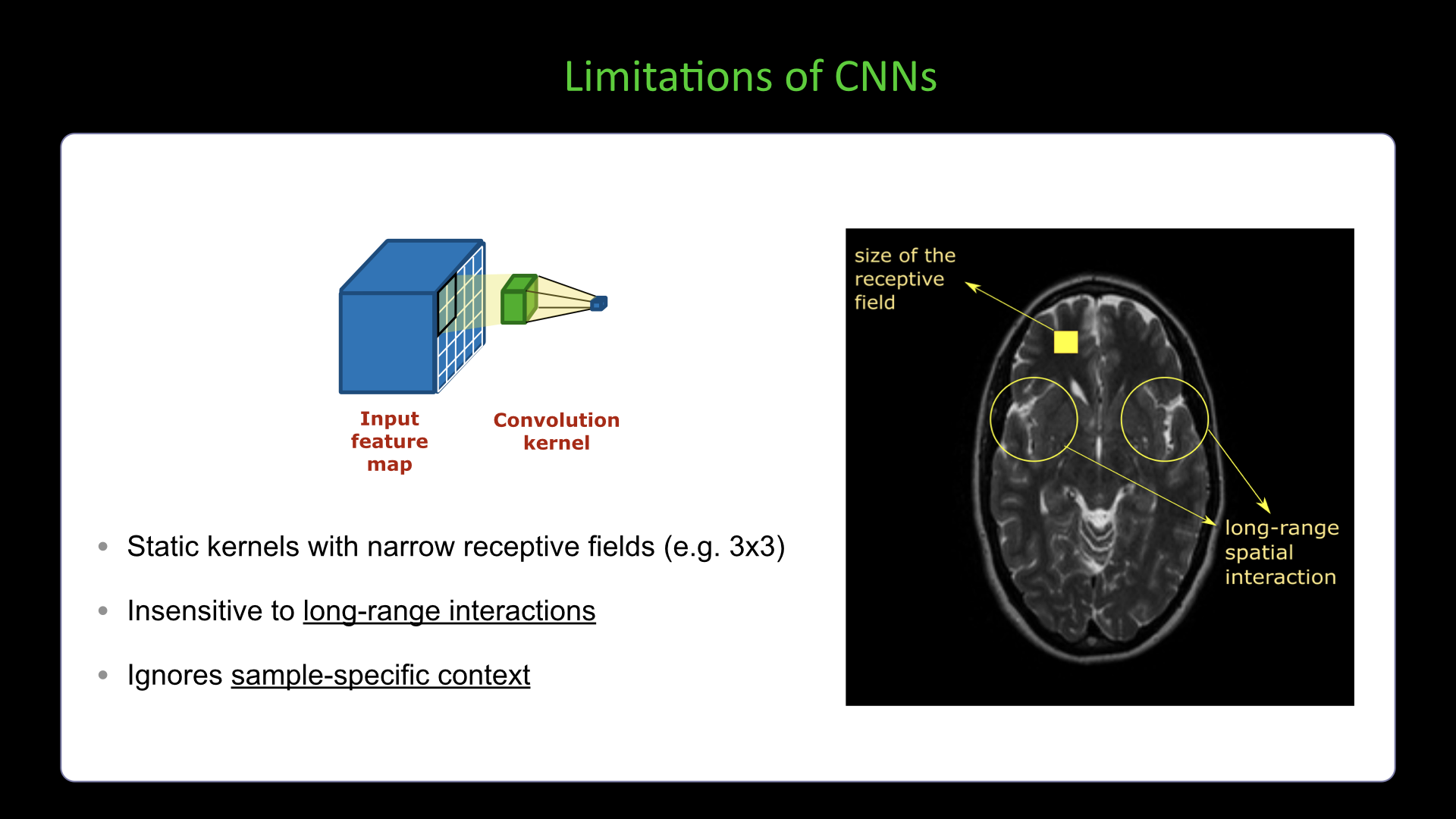 Slide #15
Slide #15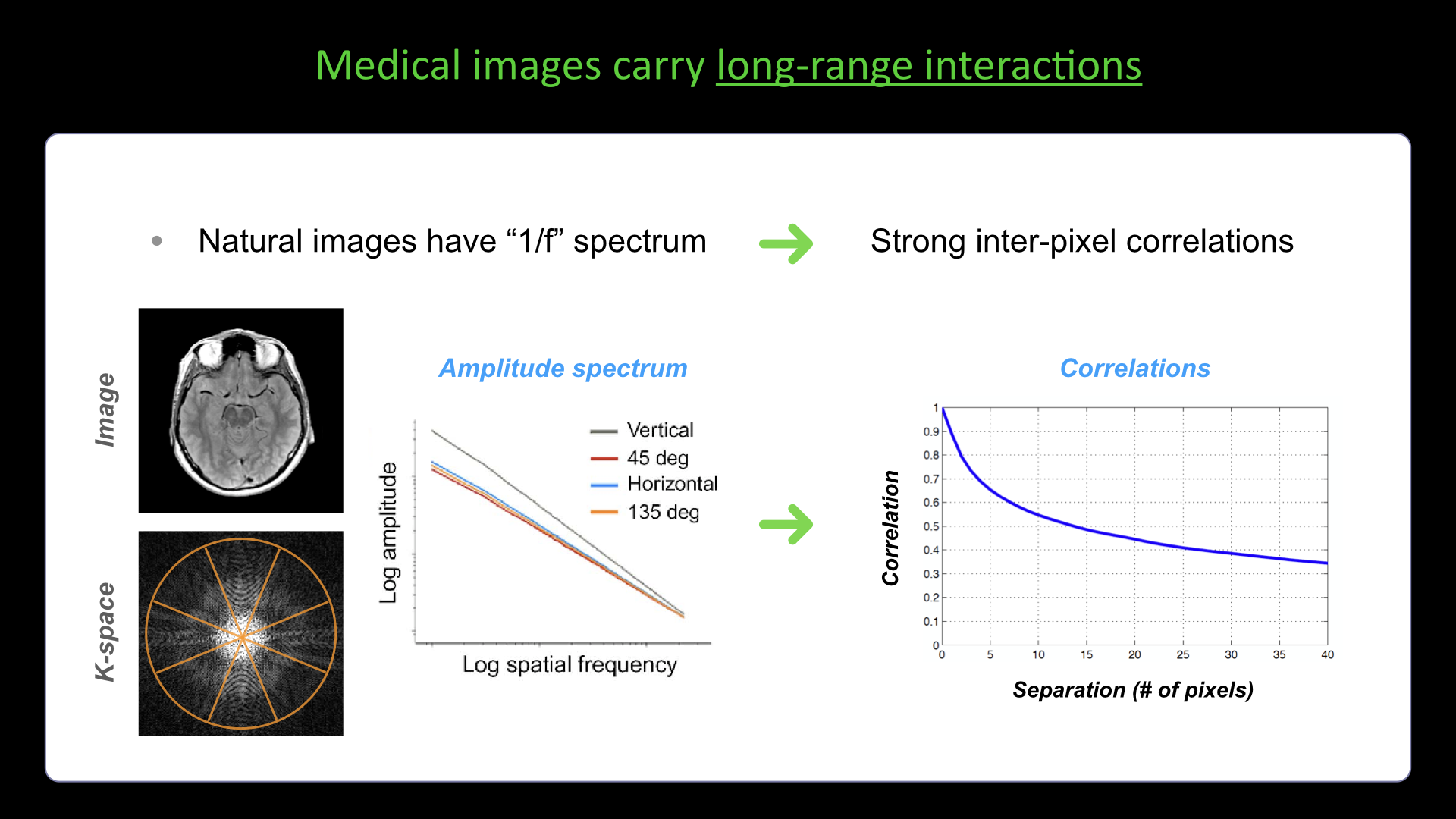 Slide #16
Slide #16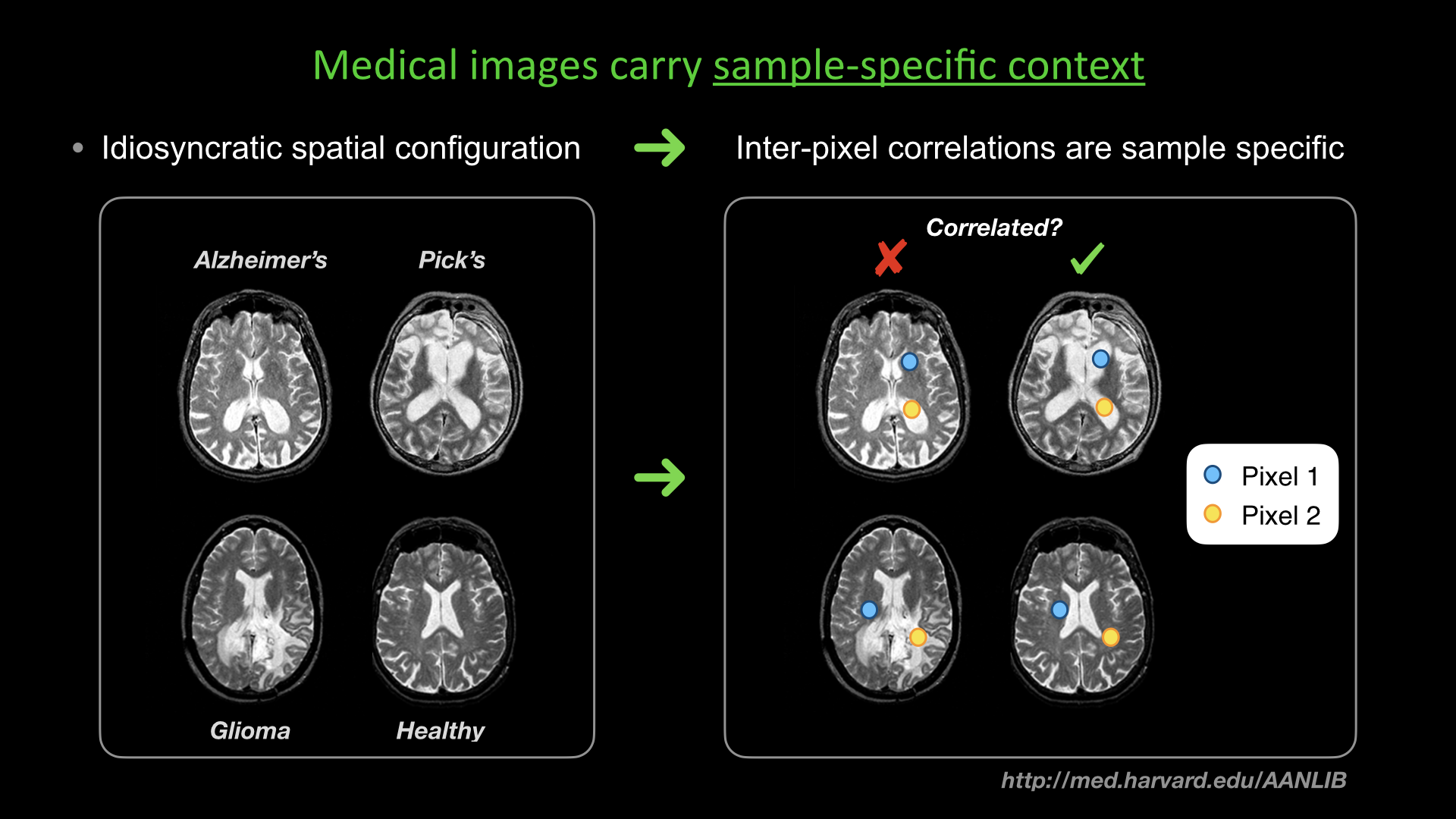 Slide #17
Slide #17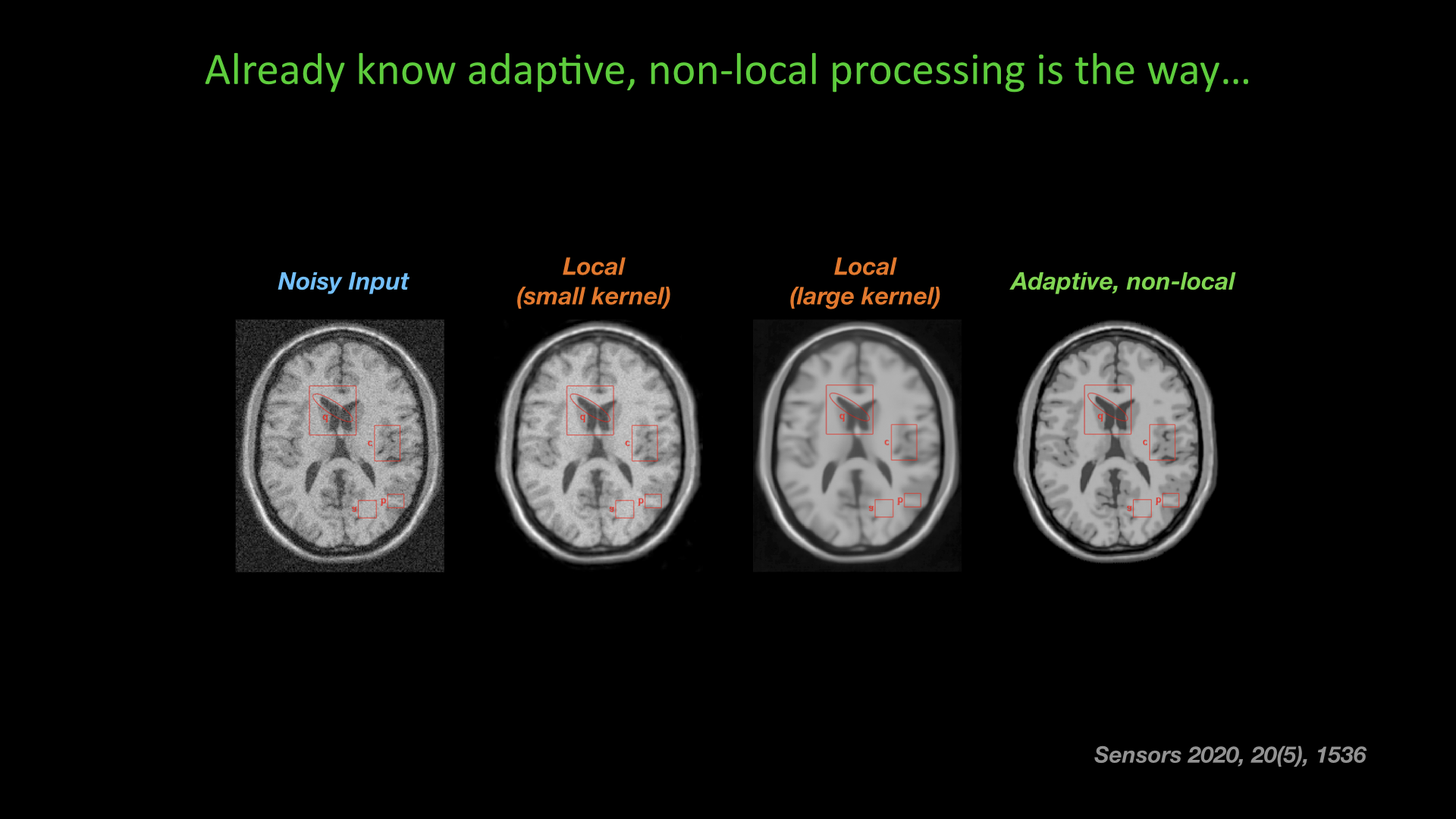 Slide #18
Slide #18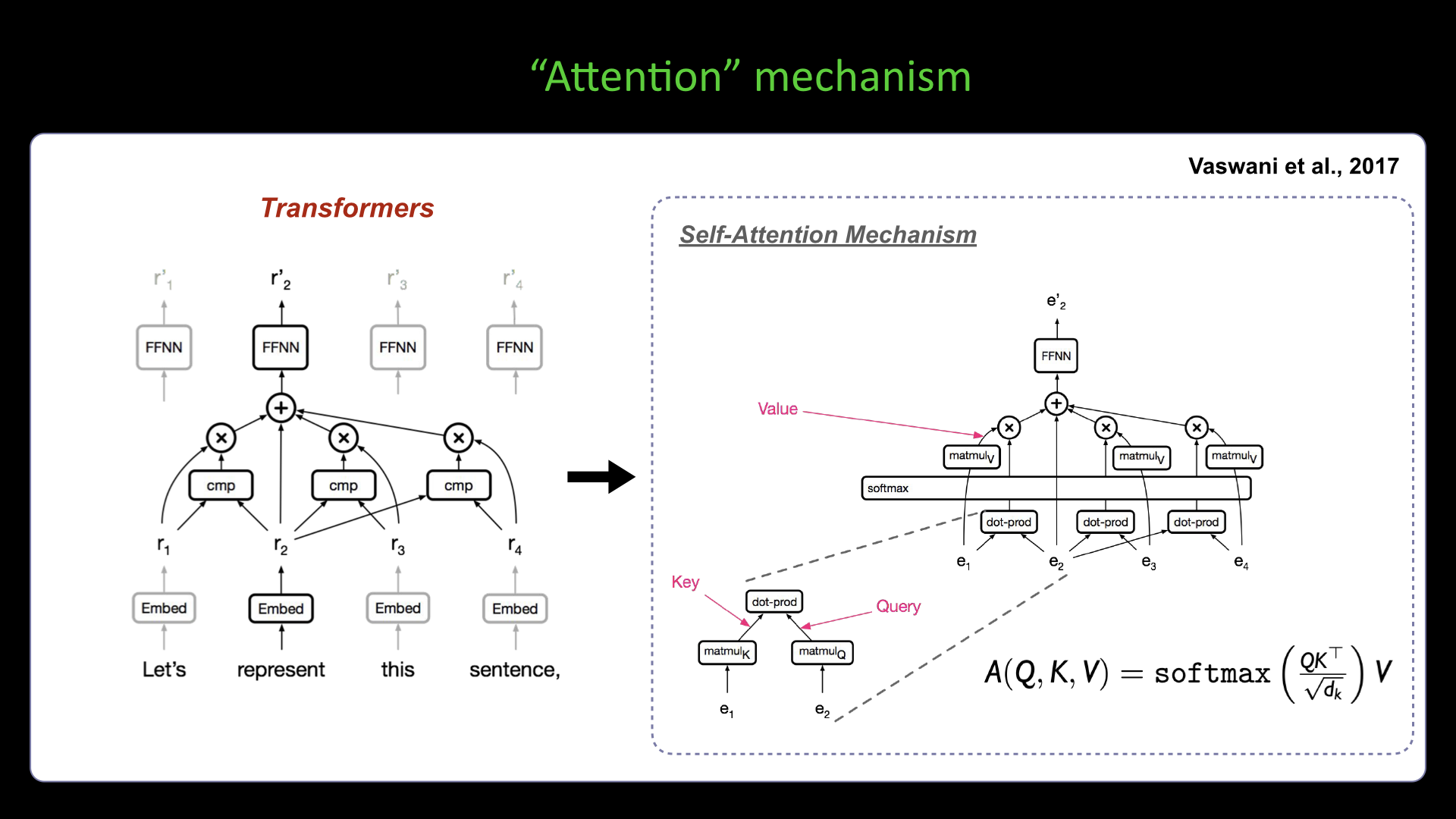 Slide #19
Slide #19 Slide #20
Slide #20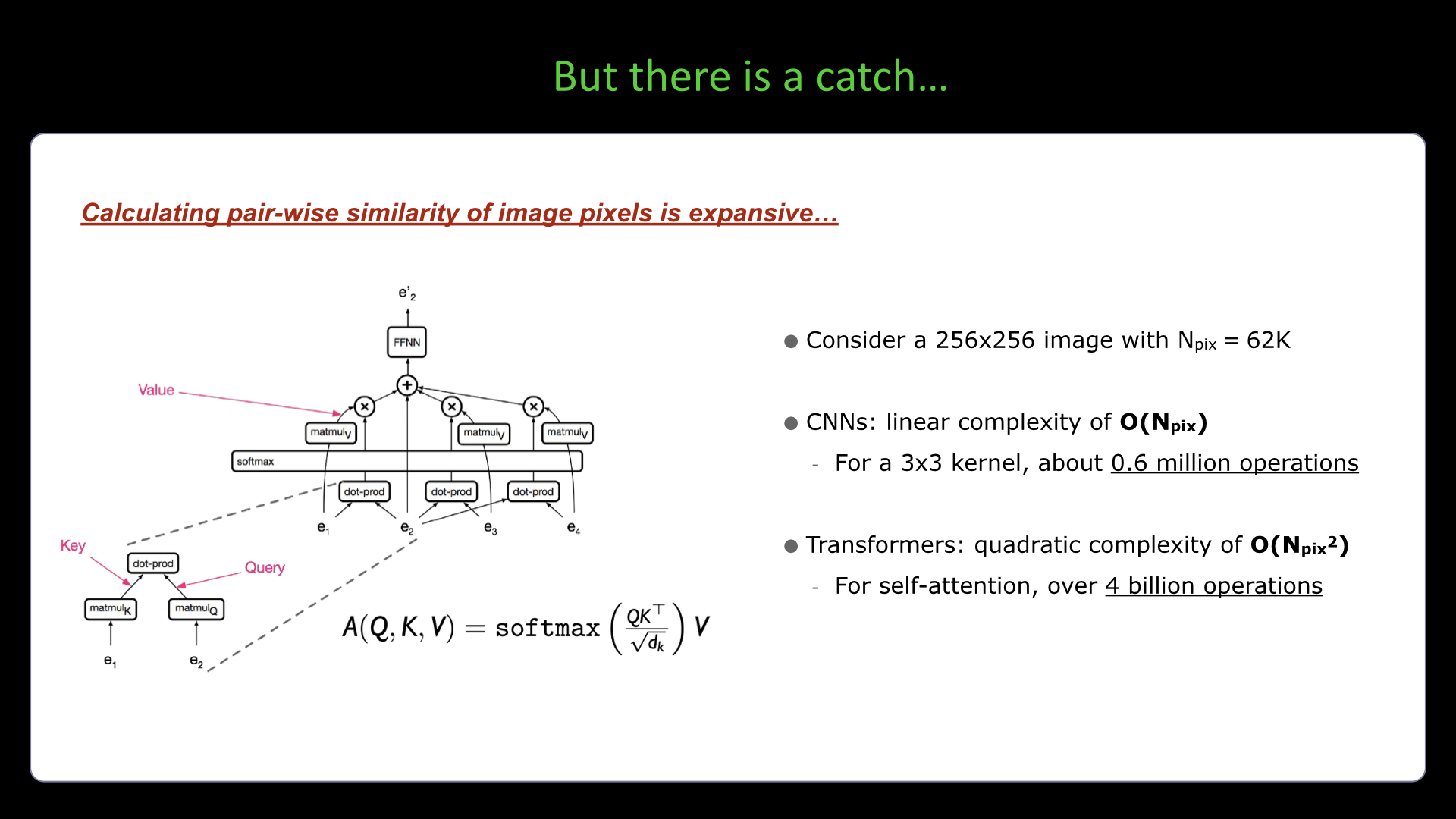 Slide #21
Slide #21 Slide #22
Slide #22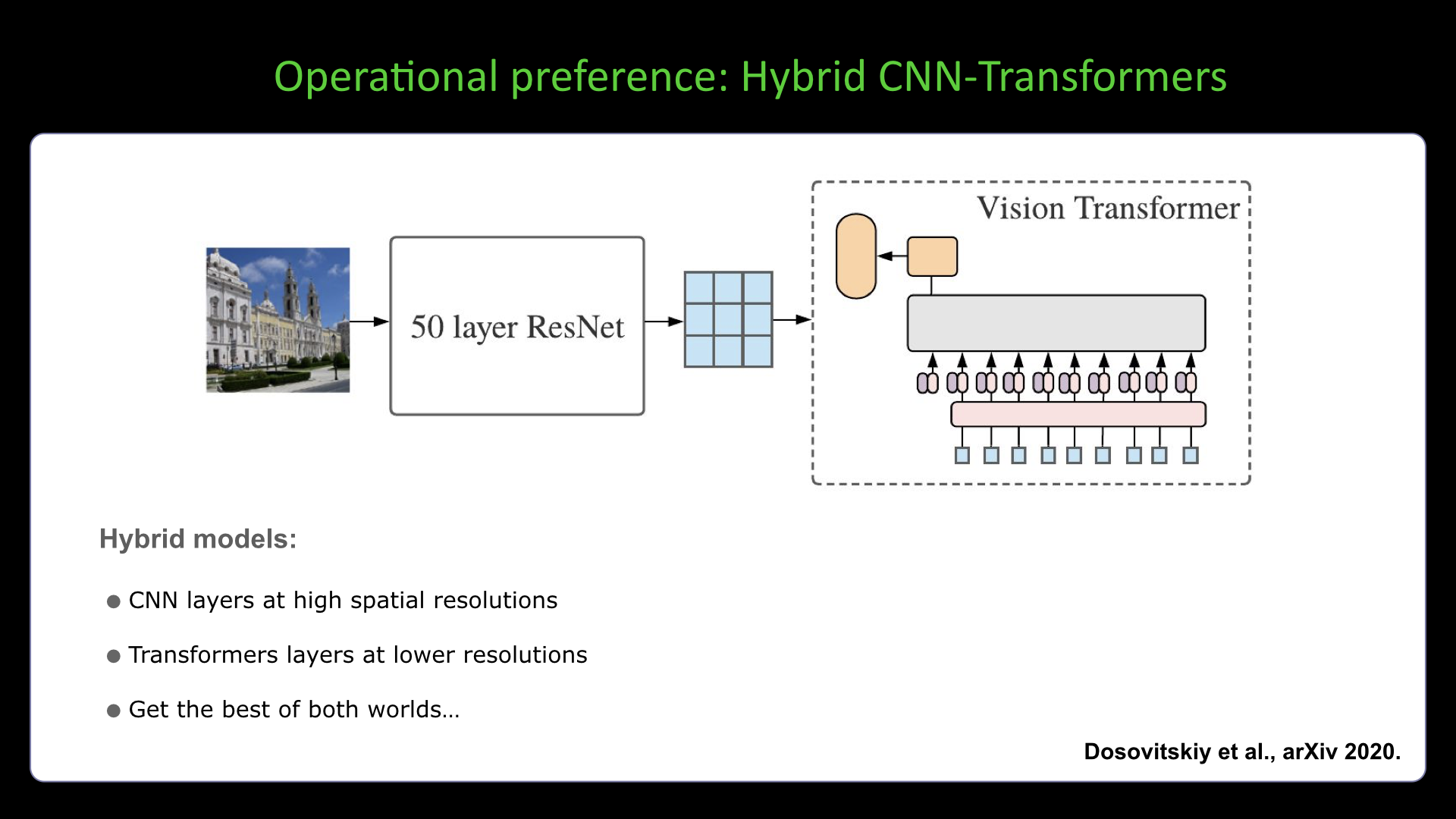 Slide #23
Slide #23 Slide #24
Slide #24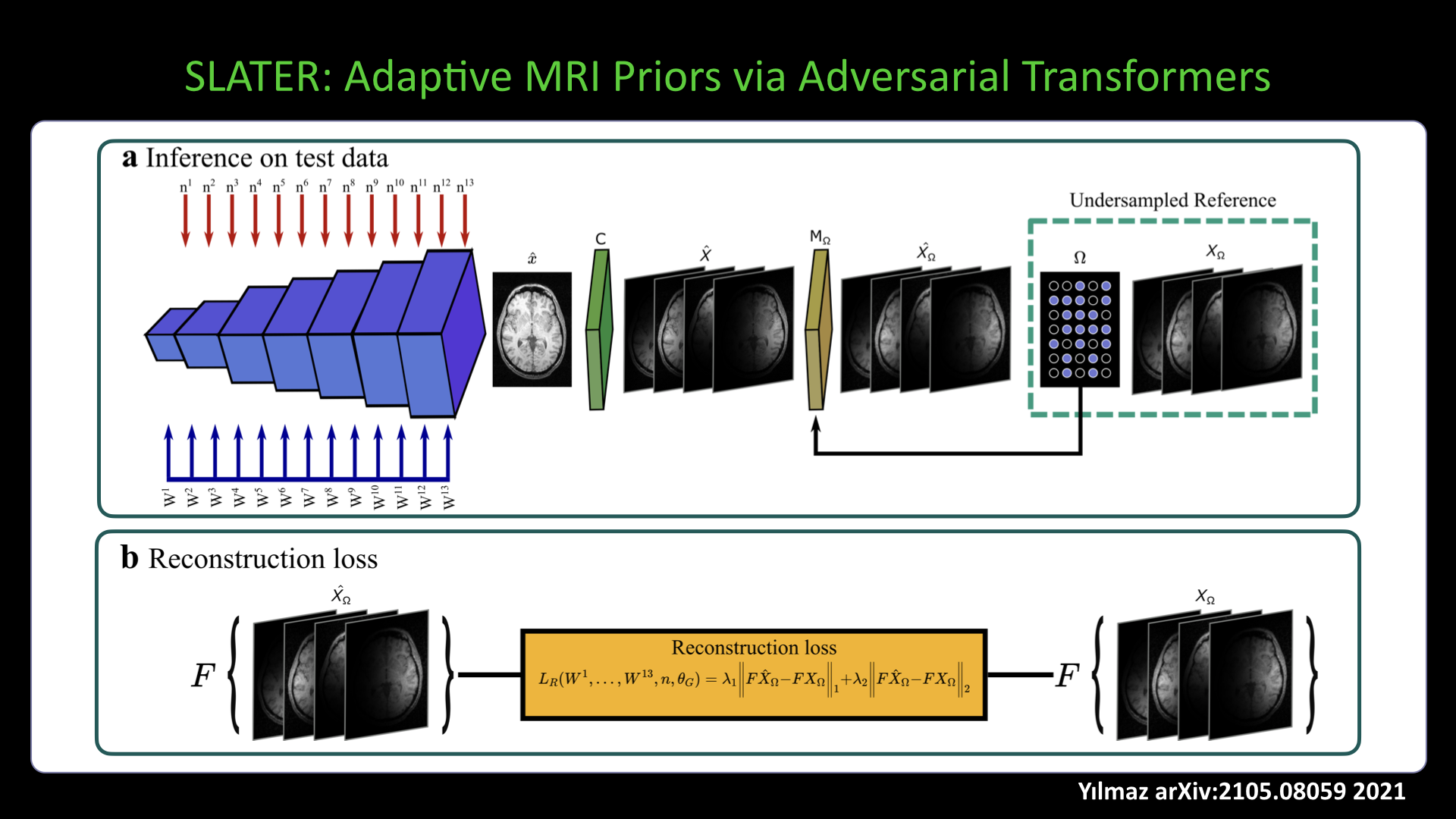 Slide #25
Slide #25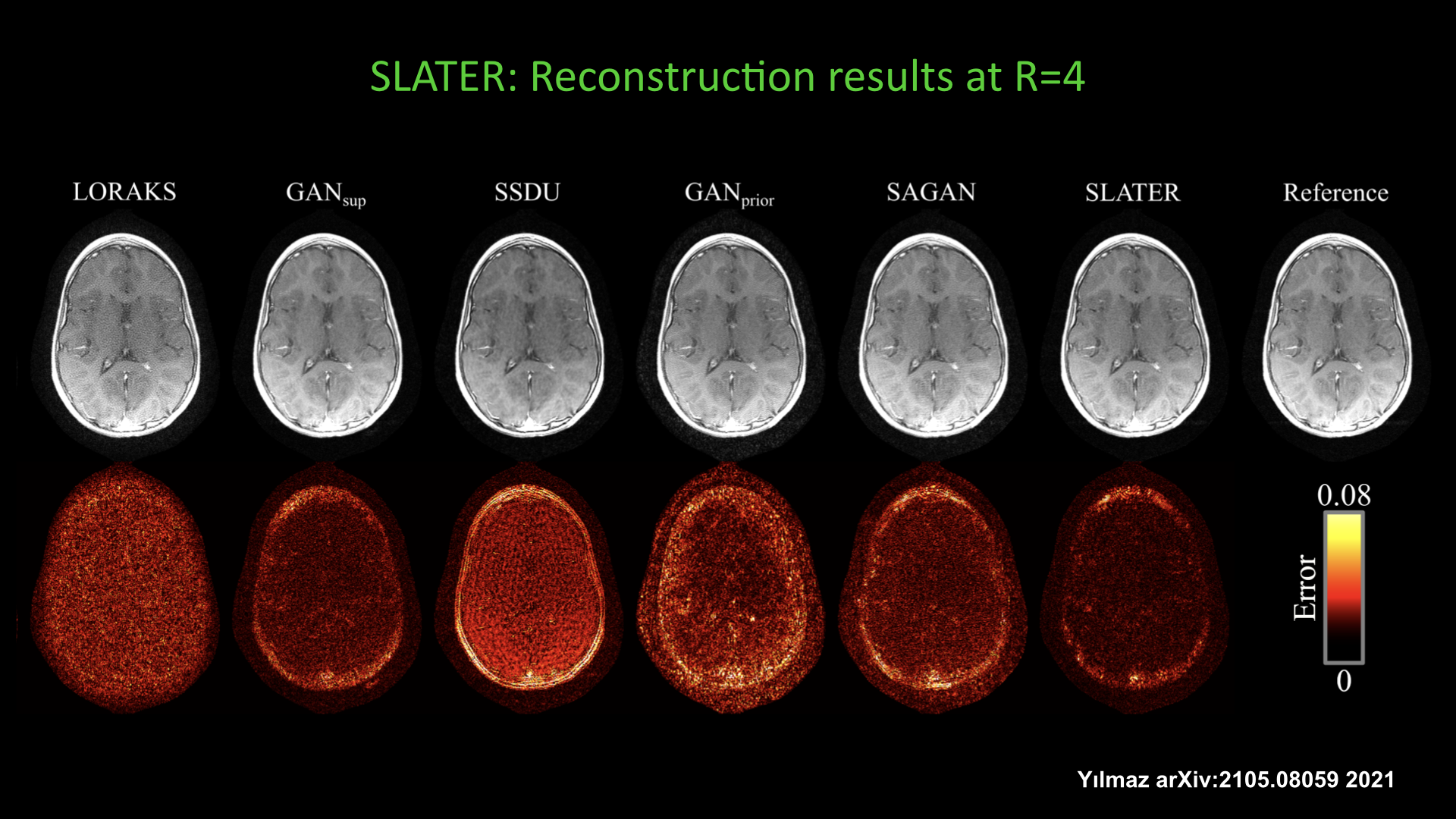 Slide #26
Slide #26 Slide #27
Slide #27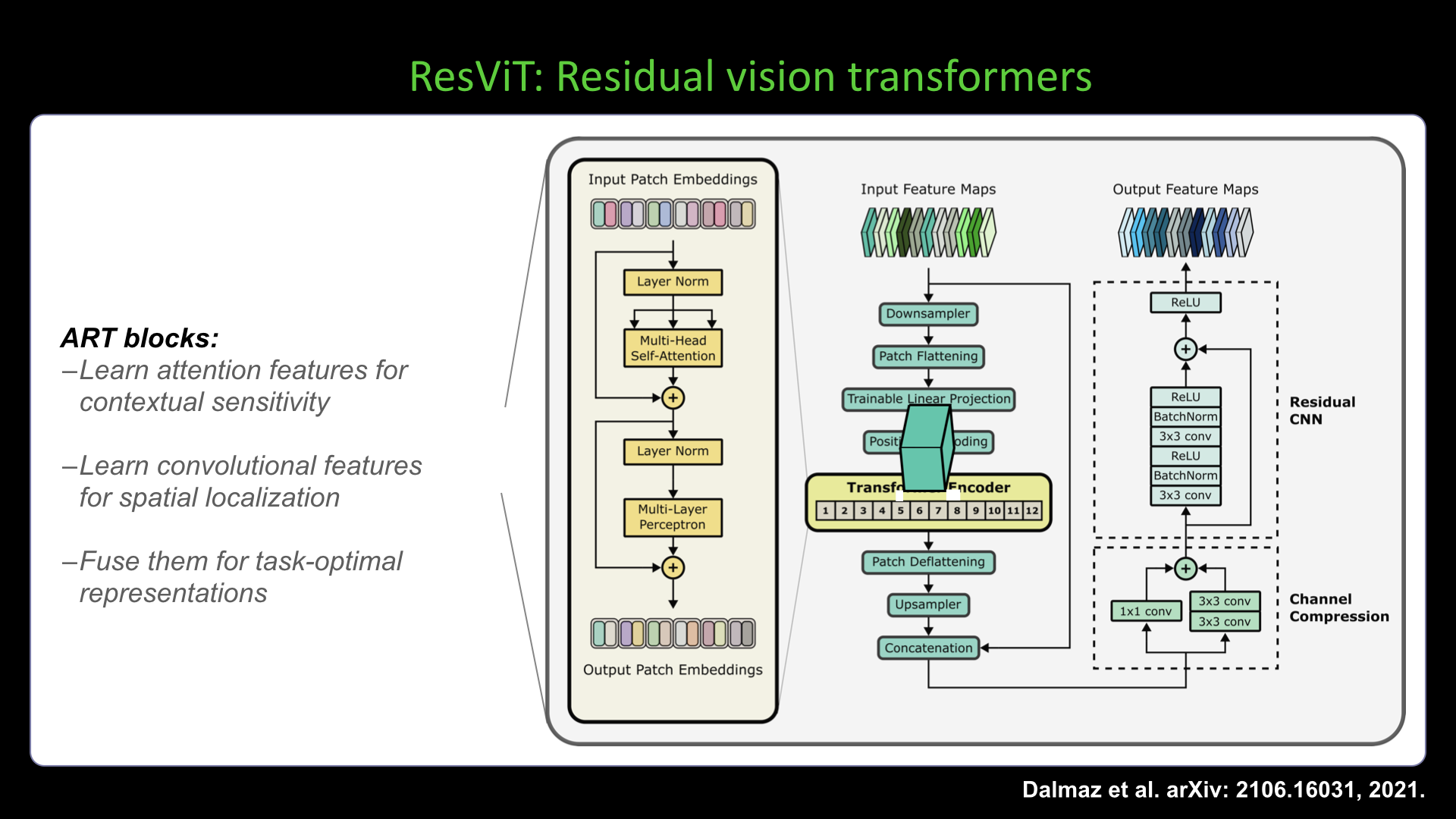 Slide #28
Slide #28 Slide #29
Slide #29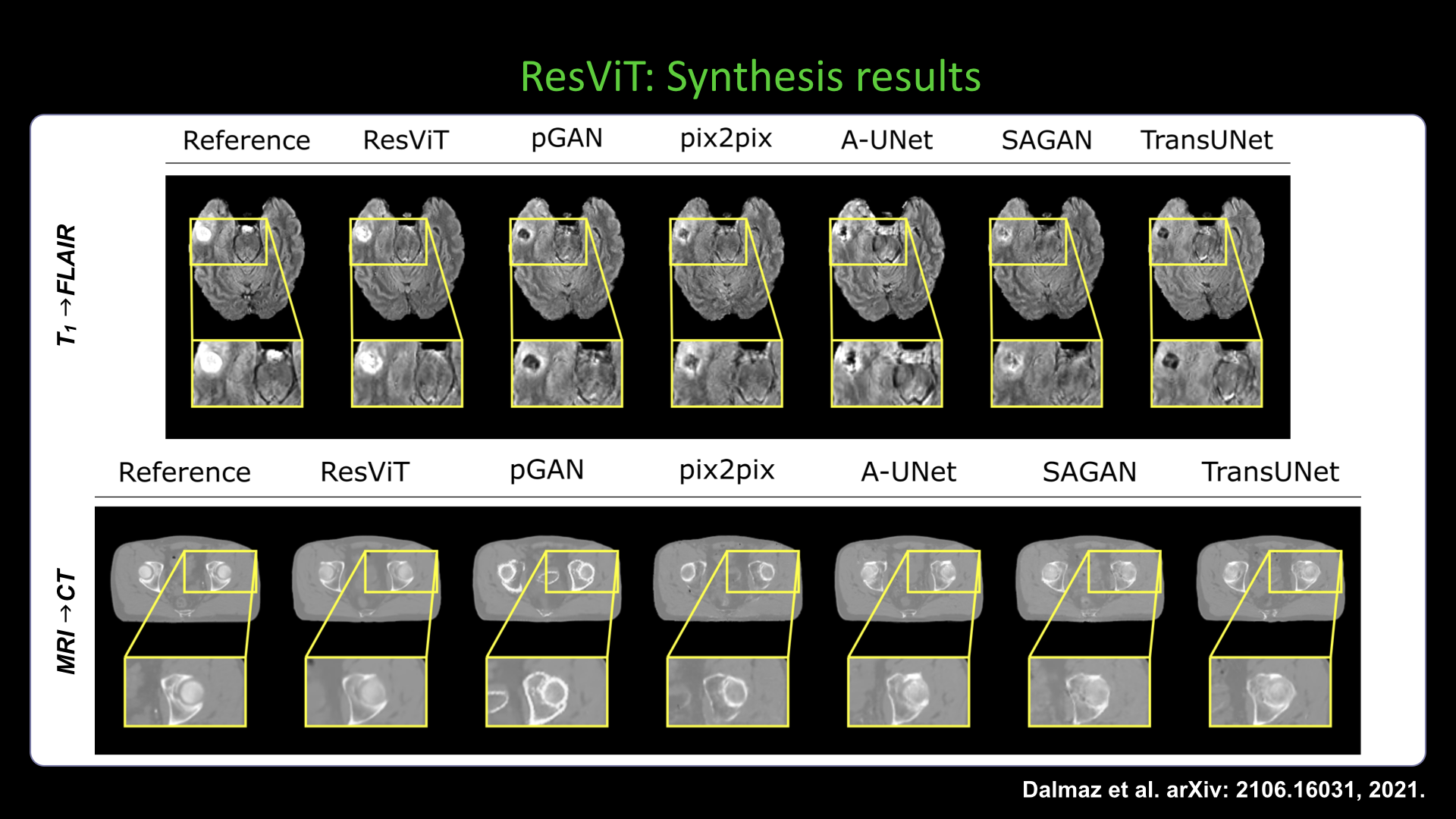 Slide #30
Slide #30