4826
The Potential of AI-Based Clinical Text Mining to Improve Patient Safety: the Case of Implant Terms and Patient Journals
Marina Santini1, Oskar Jerdhaf2, Anette Karlsson2, Emma Eneling3, Magnus Stridsman3, Arne Jönsson4, and Peter Lundberg2,5
1Digital Health, Research Institutes of Sweden (RISE), Stockholm, Sweden, 2Radiation Physics, Linköping University, Linköping, Sweden, 3Unit for Technology Assessment, Testing and Innovation and Department of Health, Medicine and Caring Sciences, Linköping University, Linköping, Sweden, 4Department of Computer and Information Science, Linköping University, Linköping, Sweden, 5Center for medical Imaging and Visualization (CMIV), Linköping, Sweden
1Digital Health, Research Institutes of Sweden (RISE), Stockholm, Sweden, 2Radiation Physics, Linköping University, Linköping, Sweden, 3Unit for Technology Assessment, Testing and Innovation and Department of Health, Medicine and Caring Sciences, Linköping University, Linköping, Sweden, 4Department of Computer and Information Science, Linköping University, Linköping, Sweden, 5Center for medical Imaging and Visualization (CMIV), Linköping, Sweden
Synopsis
It is important for radiologists to know in advance if a patient has an implant, since MR-scanning is incompatible with some implants. At present, the unbiased process to ascertain whether a patient could be at risk is manual and not entirely reliable. We argue that this process can be enhanced and accelerated using AI-based clinical text-mining. We therefore investigated the automatic discovery of medical implant terms in electronic-medical-records (EMRs) written in Swedish using an AI-based text mining algorithm called BERT. BERT is a state-of-the-art language model trained using a deep learning algorithm based on transformers. Results are promising.
Introduction
Implant terms are domain-specific words indicating artificial artefacts that replace or complement parts of the human body. Common implants are devices such as `pacemaker', `shunt', `Codman', `prosthesis' or `stent'. The need of an automatic identification of implant term contexts spurs from safety reasons because patients who have an implant may or may be not submitted to MRI scans. MRI is very safe, and most people are able to benefit from it. However, in some cases an MRI scan may not be recommended. Before having an MRI scan, for example the following conditions must be verified: (a) metal implant in the body and (b) being pregnant or breastfeeding, and sometimes also (c) tattoos. It is important to know if a patient has an implant, because MRI-scanning is incompatible with some implants (e.g., the ‘pulmonary artery catheter’) or maybe partially compatible with some of them (e.g., the ‘mitraclip’). When a patient has or is suspected to have an implant, the procedure of recognition and acknowledgement is manual, laborious and involves quite many human experts with specialized knowledge (MRSO, MRSE, MRSD). The workflow of the current procedure is described in [1]. Even if implants have been removed, metallic or electronic parts (like small electrodes or metallic clips) may have been overlooked and left in situ, without causing harm to patient’s health before the MRI. Normally, referring physicians may be aware of the limitation of specific implants, and prior to an MRI-examination, they should go through the patient’s medical history by reading EMRs. EMRs are digital documents, but the information they contain is not structured or organized in a way that makes it trivial to find implant terms and contexts quickly and efficiently. This downside can be addressed by automatically trying to identify implant terms. In our experiments, we use BERT ('Bidirectional Encoder Representations from Transformers') [2], which is the state-of-the art in 'Natural Language Processing' (NLP) Text Mining. The aim is to find as many validated instances of implant-related words as possible in free-text EMRsMaterials and Methods
BERT is a powerful but complex model. The BERT architecture is based on Transformers, which are a type of neural networks. Neural networks are the foundation of modern Artificial Intelligence (AI). Simply put, BERT approaches tasks in 2-steps: (1) by training a language model on a large unlabelled text corpus (unsupervised or semi-supervised); (2) by fine-tuning this large model to specific NLP tasks to utilize the knowledge this model has gained (supervised). In our case, the pre-trained BERT model is the bert-base-swedish-cased released by The National Library of Sweden [3]. For the fine-tuning, the Adam algorithm was used with default values. When the model was fined-tuned, we applied the KDTree algorithm to identify implant terms, 4636 candidate terms were discovered.Results
To assess whether a term discovered using this BERT model is indicative of the presence of implants, special domain knowledge is required. The manual assessments of BERT candidate terms were carried out by two experienced MR-physicists from the Department of Radiology at Linköping University Hospital, who assessed the terms independently. The raters agreed on 3475 terms, of which 1088 were assessed to be indicative implant terms (approx. 23.5%), 2163 terms were assessed to be non-indicative of implants, and for 224 terms both raters agreed on being “unsure”. The raters disagreed on 1161 terms (see Fig. 1 for the breakdown).Discussion
The percentage of terms on which the raters disagree (approx. 25%) reveals that the automatic identification of implant terms is challenging also for humans. The percentage of terms indicative of implants (y-y terms in Fig. 1) validated by domain experts (23.5%) shows that regardless the difficulty of the task, BERT’s results mark a turning point, since they provide valuable information about the presence of implants. This information can be visualized and organized for further investigations. For instance, Fig. 2 shows that the term “ventil” (en: valve) is indicative of the presence of implants as much as the terms “shunt” and all its variants (see circles), while some terms are not indicative of implants (squares); finally some other terms like those in grey squares are controversial and the domain experts disagree on whether they indicate the presence of implants or not. This information can be used when creating an automatic classification system that predicts patients at risk of MRI by automatically searching their medical records.Conclusion
In conclusion, we presented results of an AI-based text mining model for the automatic discovery of implant terms in EMRs. Although the task is challenging, manual evaluation by domain experts shows that the approach is re-warding, since a solid number of indicative terms were automatically discovered. Future work is focussed on the reduction of irrelevant terms, while enhancing model accuracy.Acknowledgements
This research was funded by Vinnova, the Swedish Innovation Agency, and by the County Council of Östergötland. Project title: Patient-Safe Magnetic Resonance Imaging Examination by AI-based Medical Screening. Grants number: 2020-00228 and 2021-01699References
[1] J. Kihlberg and P. Lundberg, “Improved workflow with implants gave more satisfied staff,” in SMRT 28th Annual Meeting 10-13 May 2019, 2019.[2] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapterof the Association for Computational Linguistics: Human LanguageTechnologies, Volume 1 (Long and Short Papers), 2019, pp. 4171–4186.[3] M. Malmsten, L. Börjeson, and C. Haffenden, “Playing with words at the national library of sweden–making a swedish bert,” arXiv preprintarXiv:2007.01658, 2020.Figures
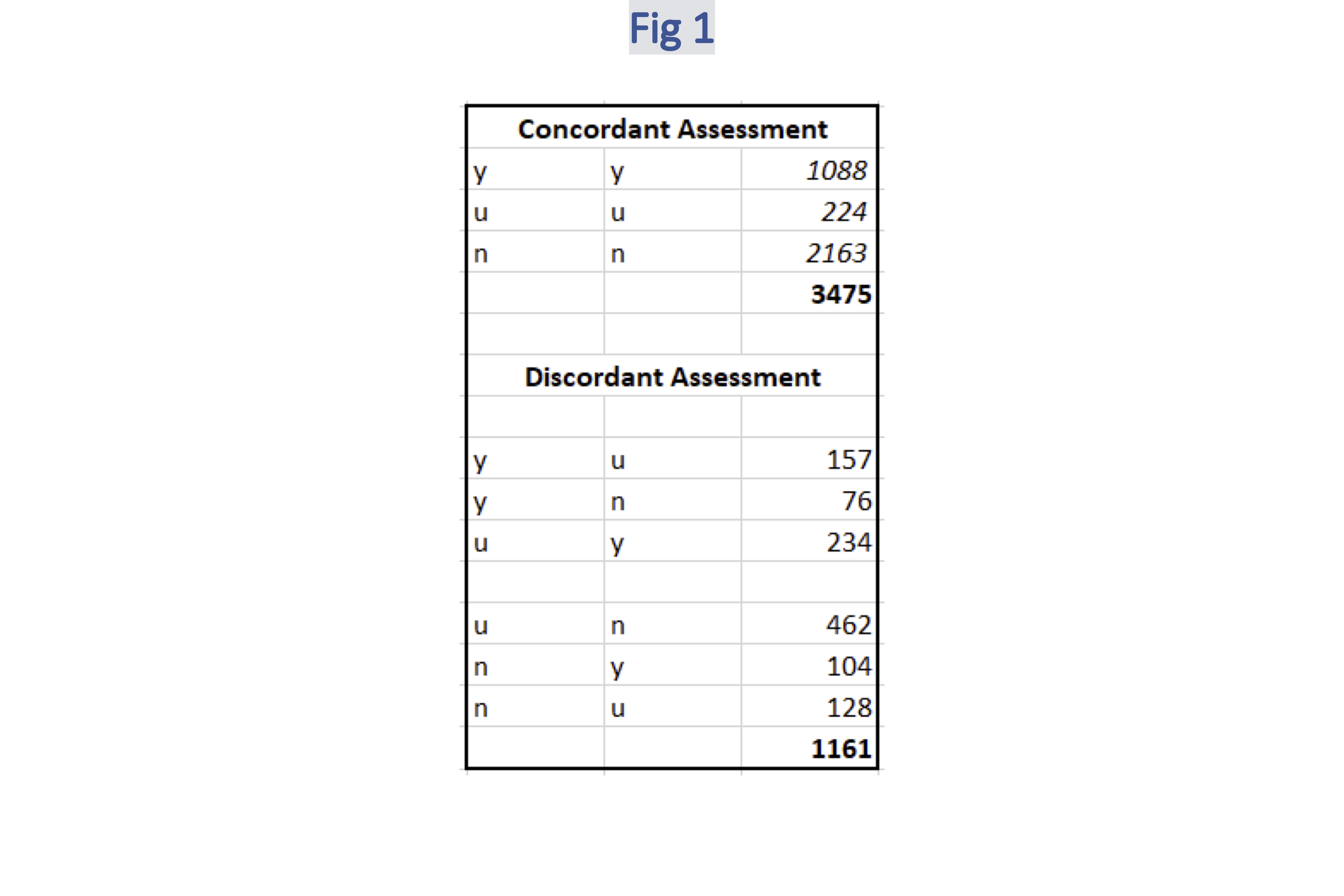
Figure 1. Breakdown: concordant/discordant independent assessments by the two expert raters.
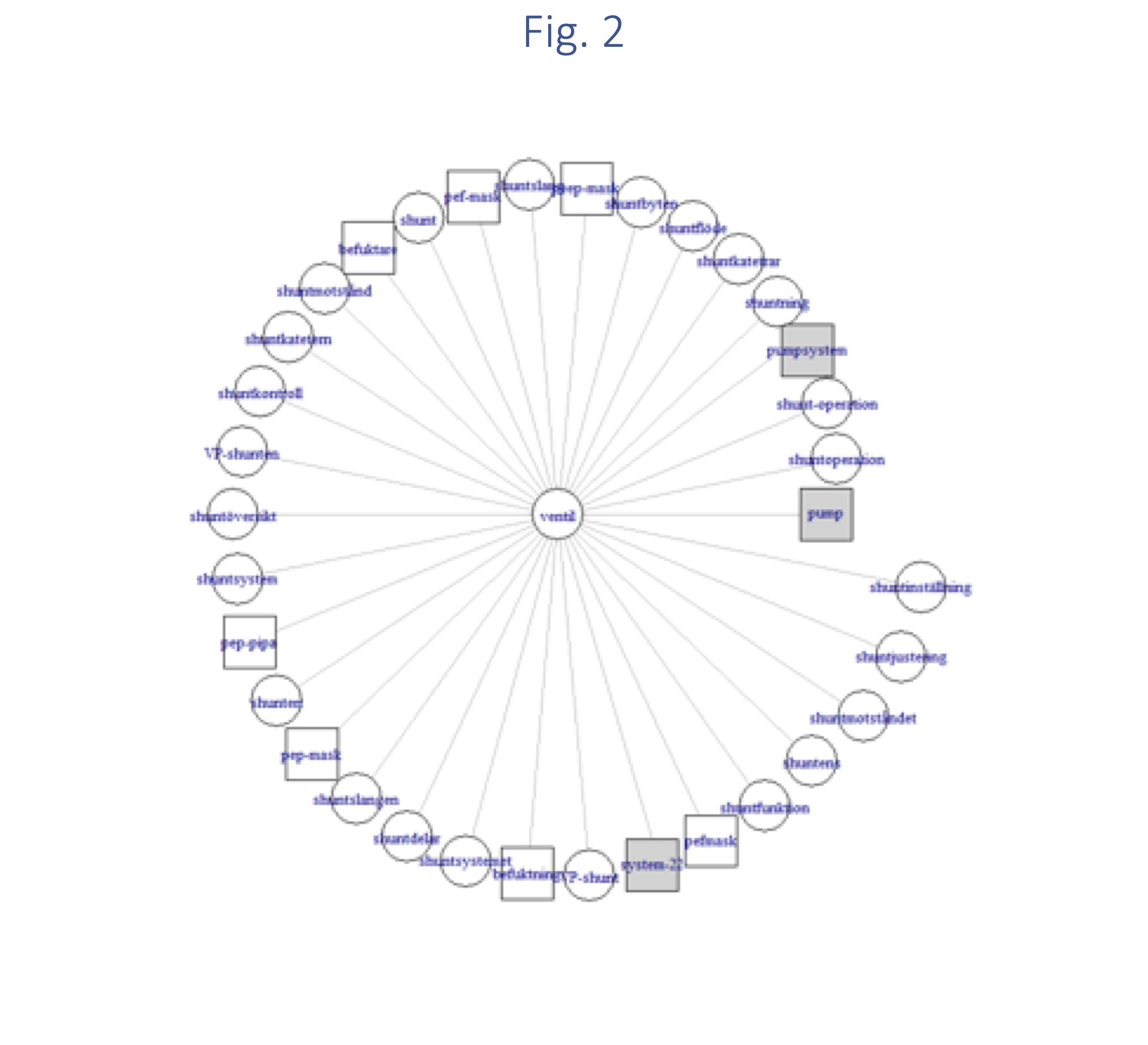
Figure 2 Circles are implant terms; squares are words that are not implant terms; and grey squares are controversial terms. The length of the lines represents the relatedness of the terms to “ventil”, according to BERT.
DOI: https://doi.org/10.58530/2022/4826