4812
Quantifying Domain Shift for Deep Learning Based Synthetic CT Generation with Uncertainty Predictions1Medical Biophysics, University of Toronto, Toronto, ON, Canada, 2Physical Sciences, Sunnybrook Research Insitute, Toronto, ON, Canada, 3Department of Radiation Oncology, Sunnybrook Health Sciences Centre, Toronto, ON, Canada, 4Department of Physics, Ryerson University, Toronto, ON, Canada
Synopsis
Convolutional Neural Networks behave unpredictively when test images differ from the training images, for example when different sequences or acquisition parameters are used. We trained models to generate synthetic CT images, and tested the models on both in-distribution and out-of-distribution input sequences to determine the magnitude of performance loss. Additionally, we evaluated if uncertainty estimates made using dropout-based variational inference could detect spatial regions of failure. Networks tested on out of distribution images failed to generate accurate synthetic CT images. Uncertainty estimates identified spatial regions of failure and increased with the difference between the training and testing sets.
Introduction
Synthetic computed tomography (sCT) images are required for accurate MR-based radiation treatment planning. Convolutional neural networks (CNNs) can produce accurate sCTs with mean absolute error (MAE) and dose difference suitable for clinical implementation1. However a drawback to CNNs is they respond unpredictably when the training and testing distributions are different (domain shift)2 . This can occur by changing pulse sequences, acquisition parameters, or hardware variations between scanners. Previous studies have used data from single institutions with predefined sets of MR sequences. Therefore, two remaining obstacles for clinical implementation of deep learning based sCT methods are 1) quantifying the effect of domain shift between different scanners and protocols and 2) automated quality control. In this work, we trained sCT CNN models using combinations of different MRI sequences acquired from three difference scanners, each with different acquisition protocols. The effect of domain shift on network output was quantified by testing images on networks not exposed to their protocol during training. We also evaluated whether using dropout-based variational inference3 could identify out-of-distribution inputs, as well as the specific spatial regions of model failure.Methods
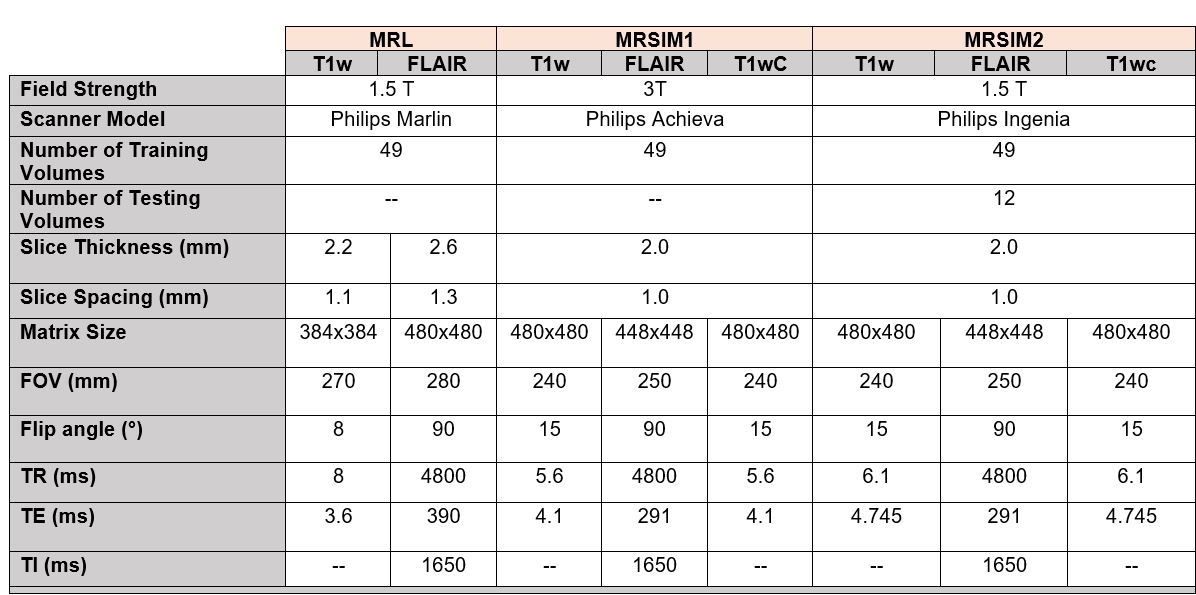
Data: Three MRI datasets were obtained retrospectively from glioblastoma patients undergoing radiation therapy treatment. MRI data was acquired from three scanners at our institution, a 3T Philips Achieva MR-SIM (Philips Healthcare, Best, Netherlands), a 1.5T Philips Ingenia MR-Sim (Philips Healthcare, Best, Netherlands), and a 1.5T Elekta Unity MR-Linac (Elekta AB, Stockholm). Details on the MR datasets can be found in Table 1. Planning CTs (Matrix size 512x512, FOV=450mm, 1mm slice thickness) acquired from a Philips Brilliance Big Bore CT-SIM were used as ground truth.Image Processing: For each patient, each volume was rigidly registered to the T1w volume using FSL FLIRT 4,5. Each volume was resampled to a 0.8mm3 isotropic resolution with a FOV of 240mm. Axial 2D slices were used for training and testing the network. CT images were clipped from [-1100-3000] Hounsfield Units (HU) and linearly rescaled to [0-1]. MR images were scaled to [0-1] based on 95% maximum intensity before being split into 2D slices for input to the network.
Network: For all experiments, the model architecture was a 2D conditional generative adversarial network (cGAN)6 based on the Pix2Pix architecture. The cGAN consisted of a 256x256 8-layer U-Net generator and a 64x64 patch-based classifier discriminator. Each network was trained for 200 epochs using the ADAM optimizer7, with a constant learning rate (10-4) for the first 100 epochs, linearly decreasing to zero for the final 100 epochs. Random flipping, rotation, and cropping were used for data augmentation during training. Dropout-based variational inference 3 was used to estimate the model uncertainty by computing the standard deviation over 25 samples per input image.
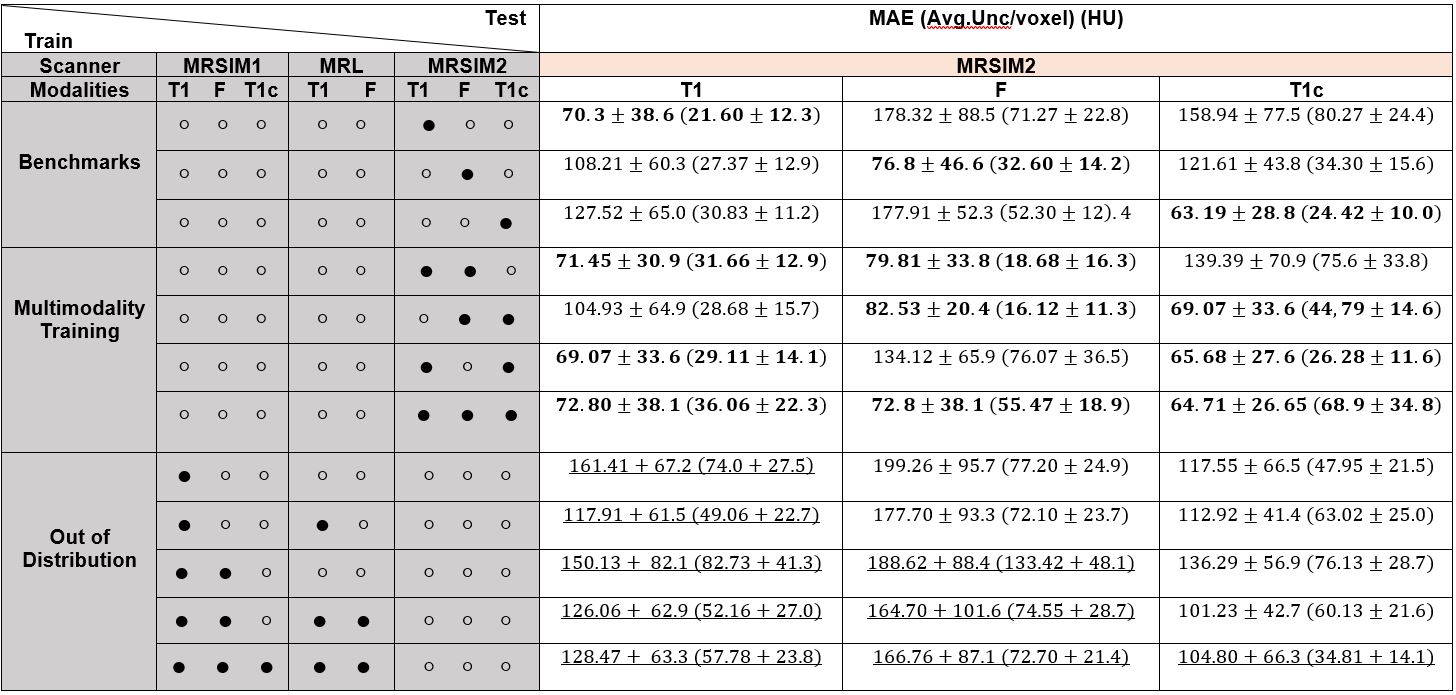
Experiments: Table 2 shows the different models trained with different combinations of MRI sequences, from different scanners. MAE for each model was measured on a fixed test set from the target MRSIM2 dataset (1.5T, n=12 subjects). Three sets of models were trained, using either A) one modality from the MRSIM2 dataset (‘Benchmarking”), B) Multiple sequences from the MRSIM2 dataset (“Multimodality”) and C) different sequences from either MRSIM1, MRL, or both (“Out-of-distribution”).
Results
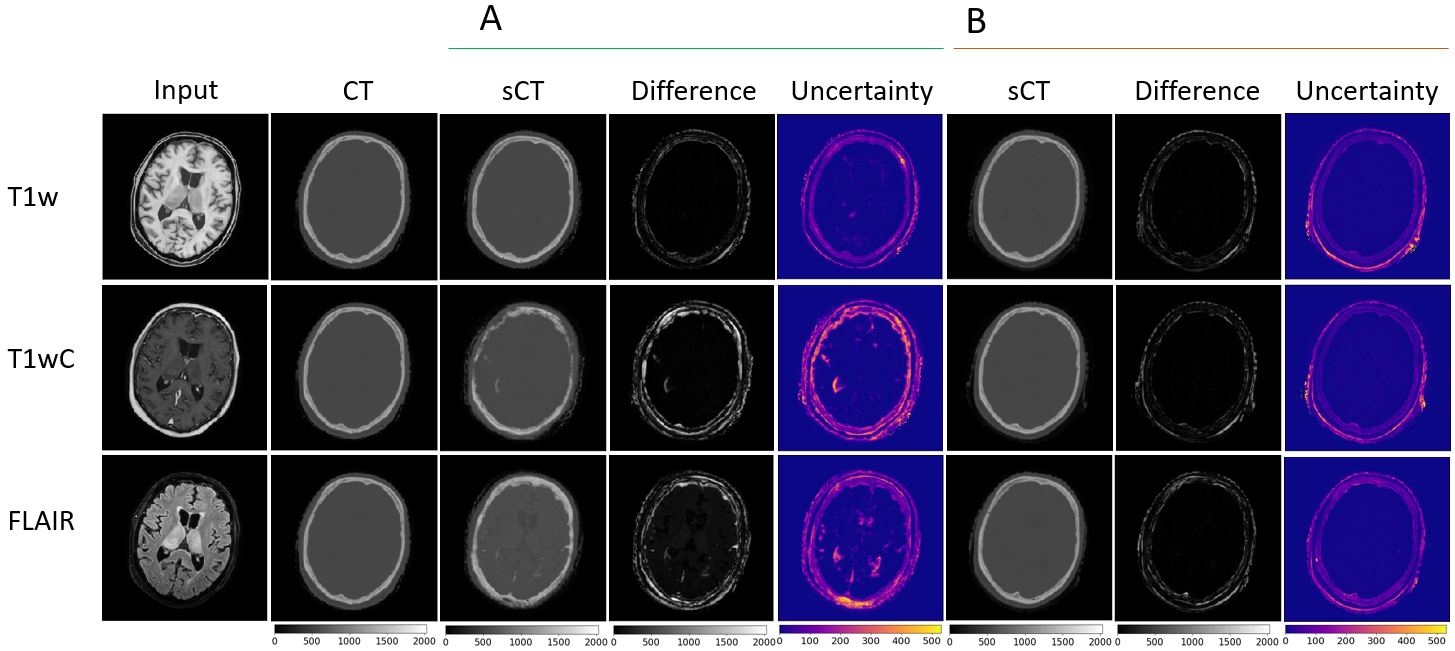
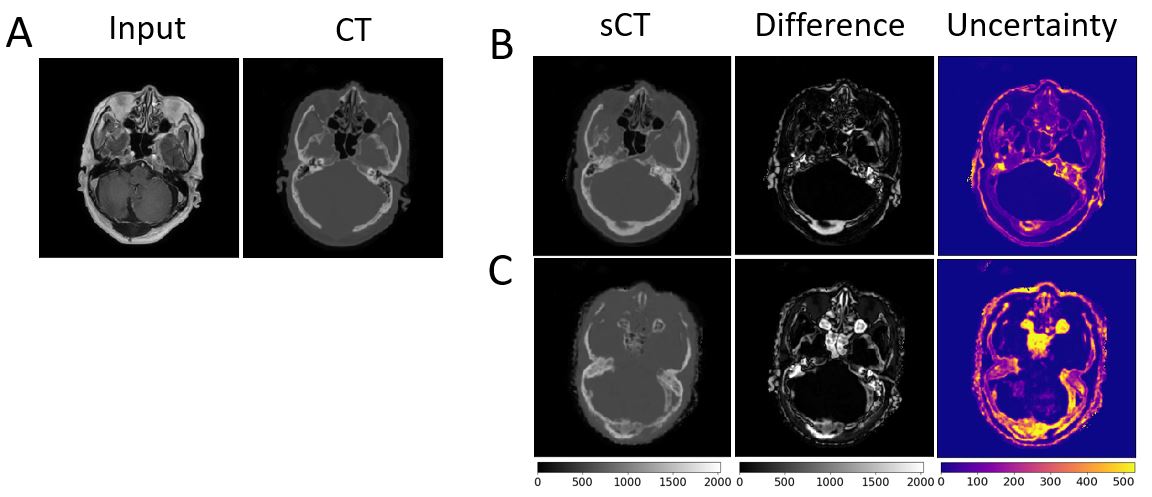
The MAE and average reported uncertainty per voxel of each source and target domain combinations in HU are given in Table 2. The ROI was the brain, with background excluded. Benchmarks are comparable with literature values 1 (reported range 47HU-116HU for various input sequences). Figure 3 gives example outputs comparing in-distribution vs out-of-distribution training on the benchmark datasets. The average difference in HU between out-of-distribution models and benchmark models were T1w: 66.5 HU, FLAIR: 102.6 HU, T1wC: 51.2 HU. Results from the “Multimodality” experiments were compared with benchmark results that were in-distribution (bold results in Table 2 in “Multimodality” and “Benchmark” sections in the same column) with a paired t-test, which showed no significant change in model performance. Figure 4 provides an example of spatial region of failure detection using uncertainty predictions.Discussion
cGAN models that produced accurate sCTs when tested on in-distribution data did not generalize to out-of-distribution inputs. This was true even if the same sequence was included in training but acquired with different acquisition parameters and scanners. This performance decrease is a hindrance to model sharing and clinical implementation. Models trained on multiple input modalities were able to generate accurate sCTs when tested on any of the modalities included during training, compared to their benchmark tests. Uncertainty estimates predicted by the network increased as the difference between testing and training datasets increased and could identify specific regions of spatial failure in the output sCT, demonstrating potential usefulness for automated quality control. Future work includes employing domain generalization techniques such as meta-learning8 to address the performance loss and to determine how many training examples from additional sequences are required to match results from the Multimodality experiments.Conculsion
CNNs models trained to produce Synthetic CTs were not accurate when applied to data acquired with different acquisition parameters than seen in the training set. Uncertainty estimates made using dropout-based variational inference could identify spatial regions of failure in the output and increased as the difference in testing and training datasets increased.Acknowledgements
The authors acknowledge funding from NSERC and Nvidia.References
1. Spadea, M. F., Maspero, M., Zaffino, P. & Seco, J. Deep learning based synthetic-CT generation in radiotherapy and PET: A review. Med. Phys. (2021) doi:10.1002/MP.15150.
2. Quionero-Candela, J., Sugiyama, M., Schwaighofer, A. & Lawrence, N. Dataset shift in machine learning. (2009).
3. Gal, Y. & Uk, Z. A. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning Zoubin Ghahramani. arXiv:1506.02142 [stat.ML] (2016).
4. Jenkinson, M. & Smith, S. A global optimisation method for robust affine registration of brain images. Med. Image Anal. 5, 143–156 (2001).
5. Jenkinson, M., Bannister, P., Brady, M. & Smith, S. Improved Optimization for the Robust and Accurate Linear Registration and Motion Correction of Brain Images. Neuroimage 17, 825–841 (2002). 6. Isola, P., Zhu, J.-Y., Zhou, T., Efros, A. A. & Research, B. A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv:1611.07004[cs.CV] (2018).
7. Kingma, D. P. & Ba, J. L. Adam: A method for stochastic optimization. in 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings (International Conference on Learning Representations, ICLR, 2015).
8. Li, D., Yang, Y., Song, Y.-Z. & Hospedales, T. M. Learning to Generalize: Meta-Learning for Domain Generalization.
Figures