4691
Motion Aware Deep Learning Accelerated MRI Reconstruction
Kamlesh Pawar1,2, Gary F Egan1,2,3, and Zhaolin Chen1,4
1Monash Biomedical Imaging, Monash University, Melbourne, Australia, 2School of Psychological Sciences, Monash University, Melbourne, Australia, 3ARC Centre of Excellence for Integrative Brain Function, Monash University, Melbourne, Australia, 4Department of Data Science and AI, Faculty of Information Technology, Monash University, Melbourne, Australia
1Monash Biomedical Imaging, Monash University, Melbourne, Australia, 2School of Psychological Sciences, Monash University, Melbourne, Australia, 3ARC Centre of Excellence for Integrative Brain Function, Monash University, Melbourne, Australia, 4Department of Data Science and AI, Faculty of Information Technology, Monash University, Melbourne, Australia
Synopsis
Deep learning (DL) models for accelerated image reconstruction involves retrospective undersampling of the fully sampled k-space data for training and validation. This strategy is not a true reflection of real-world data and in many instances, the input k-space data is corrupted with artifacts and errors, such as motion artifacts. In this work, we propose to improve existing methods of DL training and validation by incorporating a motion layer during the training process. The incorporation of a motion layer makes the DL model aware of the underlying motion and results in improved image reconstruction in the presence of motion.
Introduction
Deep Learning (DL) algorithms have been demonstrated to be effective in image reconstruction1–3 from undersampled data and motion correction4–6 from motion degraded MR images. Motion artifacts in MRI are one of the frequently occurring artifacts7 due to patient movements during scanning. The image reconstruction task involves removing undersampling artifacts such as noise, aliasing, and incoherent aliasing artifacts; while motion correction involves removing artifacts including blurring, ghosting, and ringing. Even though motion is present in approximately 20% of clinical cases7, it is not explicitly modeled in DL accelerated image reconstruction models. In this work, we propose a novel method of incorporating motion information during DL training for the task of accelerated MRI. We model motion as a tightly integrated auxiliary layer in the DL model during training that makes the DL model ‘motion aware’. During inference, the motion layer is removed and image reconstruction is performed from the raw k-space data.Methods and Materials
Deep learning model:Our model is built upon the end-to-end variational network1 consisting of a cascade of convolutional neural network (CNN) driven reconstruction steps described as
$$ k^{t+1}=k^{t} - \eta^{t}M(k^{t}-\hat{k})+R^{t}(k^{t}) \quad [1]$$
where, $$$k^{t}$$$ is current k-space, $$$k^{t+1}$$$ is updated k-space, $$$\hat{k}$$$ is acquired k-space, $$$\eta^{t}$$$ is a learnable data consistency parameter, $$$M$$$ is sampling mask with ones at the sampling locations and $$$R^{t}$$$ is the reconstruction CNN (Figure.1e). Eq.1 is equivalent to one step of gradient descent. The reconstruction CNN proceeds as follows: (i) uses intermediate k-space, (ii) performs the inverse Fourier transform, (iii) combines the multi-channel images to a complex-valued image using the sensitivity maps estimated from the sensitivity maps estimation (SME) network (Figure 1f), (iv) the combined complex-valued image is processed through a Unet, (v) the processed image is converted back to multi-channel k-space and (vi) data consistency (DC) is enforced (Figure 1c). To make the variational network ‘motion aware’ we propose to incorporate a motion layer (MS) Figure 1d) and motion informed data consistency parameter estimator (MIDCP) (Figure 1b)
Motion simulation layer:
The motion simulation layer generates random motion parameters in three degrees of freedom, two translations parameters with a maximum of +/- 10 pixels, and one rotation parameter with a maximum of +/- 100. The number of motion events for each image varied from 0 to 16 i.e a set of three motion parameters were generated randomly up to a maximum of 16 times and the k-space was distorted using these motion parameters. The motion layer was incorporated in the motion aware variational network (VarnetMi) as shown in Figure 1.
Motion informed data consistency parameter estimator (MIDCP):
As shown in Figure 1(a-b), the introduced MIDCP layer takes the intermediate k-space and learns a data consistency parameter using a CNN, thus Eq.1 is modified for VarnetMi as follows:
$$k^{t+1}=k^{t} - H^{t}(k^{t})\;M(k^{t}-\hat{k})+R^{t}(k^{t}) \quad [2]$$
where, $$$H^{t}$$$ is a CNN (Figure 1b) that takes k-space and predicts a single parameter for data consistency.
Training:
We used the fastmri dataset8 for training and validation of Varnet (not motion aware) and VarnetMi (motion aware). After the last iteration, the k-space was converted to root sum of squares (rss) image (Figure 1a) which was used to calculate the loss for supervised training and the loss function was difference structural similarity9.
Results
Experiments were performed using both with simulated motion and without motion images (T1, T2, T1-contrast, Flair) to compare the performance of Varnet and VarnetMi. When the motion was present in the input images with the undersampling factor of four, we observe a marked difference in the performance of the Varnet and VarnetMi in terms of quantitative scores with VarnetMi being superior. The reconstructed images using Varnet consisted of artifacts as shown in Figure 2, while VarnetMi being motion aware was able to recover images without any residual artifacts in the images. On the other hand, when there was no motion present (Figure 3) in the input images the performance difference between the Varnet and VarnetMi was negligible, with VarnetMi being slightly inferior. However, there was no visible artifact in both the reconstructions in this case (Figure 3). We also performed a quantitative group assessment on 1300 slices (different subjects) consisting of multiple contrasts as shown in Figure 4 which demonstrated that there was a consistent improvement for VarmetMi in terms of SSIM, PSNR, and NMSE when motion was present (Figure 4, top-row) while there was a negligible degradation in the quantitative scores when motion was not present (Figure 4, bottom-row).Discussion
A novel DL based motion aware accelerated imaging method was presented which can reconstruct images in the presence of frequently occurring patient movement. The experiments suggest that the proposed method makes the DL reconstruction more robust for practical clinical purposes. A limitation of making the DL model motion aware includes minor degradation in the image quality for the proposed method when motion is not present. Future work will involve minimizing this limitation.Conclusion
A robust motion aware variational network based deep learning reconstruction method for accelerated imaging was developed. The proposed method works both on motion degraded and non-motion degraded undersampled k-space, thus making it highly practical for clinical applications.Acknowledgements
No acknowledgement found.References
- Sriram A, Zbontar J, Murrell T, et al. End-to-End Variational Networks for Accelerated MRI Reconstruction. 2020 doi: 10.1007/978-3-030-59713-9.
- Pawar K, Egan GF, Chen Z. Domain knowledge augmentation of parallel MR image reconstruction using deep learning. Computerized Medical Imaging and Graphics 2021;92:101968 doi: 10.1016/j.compmedimag.2021.101968.
- Pawar K, Chen Z, Shah NJ, Egan GF. A Deep Learning Framework for Transforming Image Reconstruction into Pixel Classification. IEEE Access 2019;7 doi: 10.1109/ACCESS.2019.2959037.
- Küstner T, Armanious K, Yang J, Yang B, Schick F, Gatidis S. Retrospective correction of motion-affected MR images using deep learning frameworks. Magnetic Resonance in Medicine 2019;82:1527–1540 doi: 10.1002/mrm.27783.
- Pawar K, Chen Z, Shah NJ, Egan GF. Suppressing motion artefacts in MRI using an Inception-ResNet network with motion simulation augmentation. NMR in Biomedicine 2019 doi: 10.1002/nbm.4225.
- Pawar K, Chen Z, Seah J, Law M, Close T, Egan G. Clinical utility of deep learning motion correction for T1 weighted MPRAGE MR images. European Journal of Radiology 2020;133 doi: 10.1016/j.ejrad.2020.109384.
- Andre JB, Bresnahan BW, Mossa-Basha M, et al. Toward quantifying the prevalence, severity, and cost associated with patient motion during clinical MR examinations. Journal of the American College of Radiology 2015;12:689–695 doi: 10.1016/j.jacr.2015.03.007.
- Zbontar J, Knoll F, Sriram A, et al. fastMRI: An Open Dataset and Benchmarks for Accelerated MRI. 2018.
- Pawar K, Chen Z, Shah J, Egan G. Enforcing Structural Similarity in Deep Learning MR Image Reconstruction. Enforcing Structural Similarity in Deep Learning MR Image ReconstrucInternational Society for Magnetic Resonance in Medicine 2019:4711 doi: 10.2/JQUERY.MIN.JS.
Figures
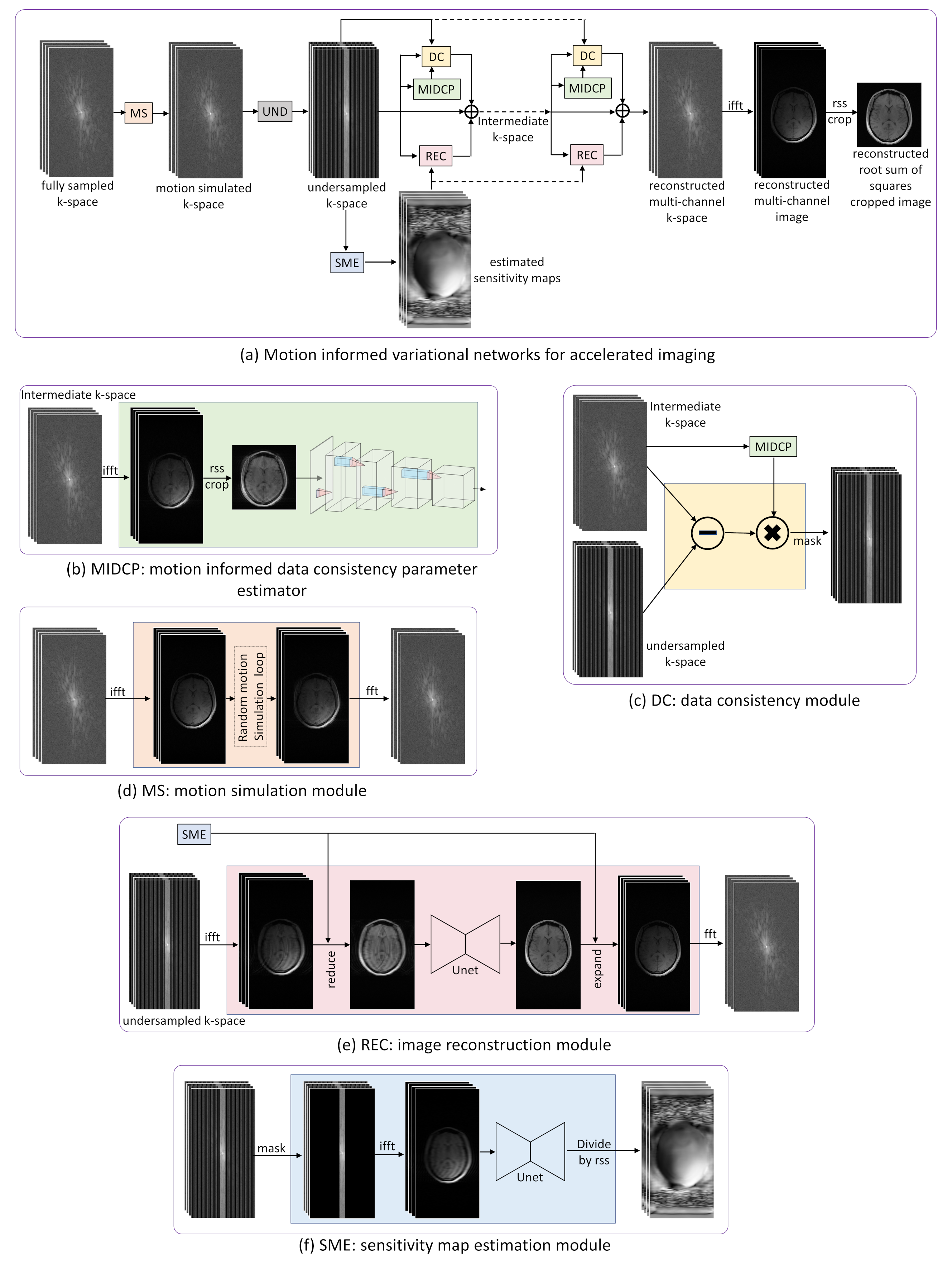
Figure
1: (a) Block
diagram of the proposed VarnetMi; (b) MIDC module to estimate the appropriate
data consistency parameter of DC layer; (c) data consistency layer enforcing
the reconstruction to be consistent with the acquired data; (d) motion
simulation module to simulate motion artifact for multi-channel k-space; (e)
reconstruction module that combines multi-channel k-space data to single
complex-valued image and process it through a Unet; and (f) SME module that takes
the center of k-space to estimate the sensitivity maps needed for reconstruction
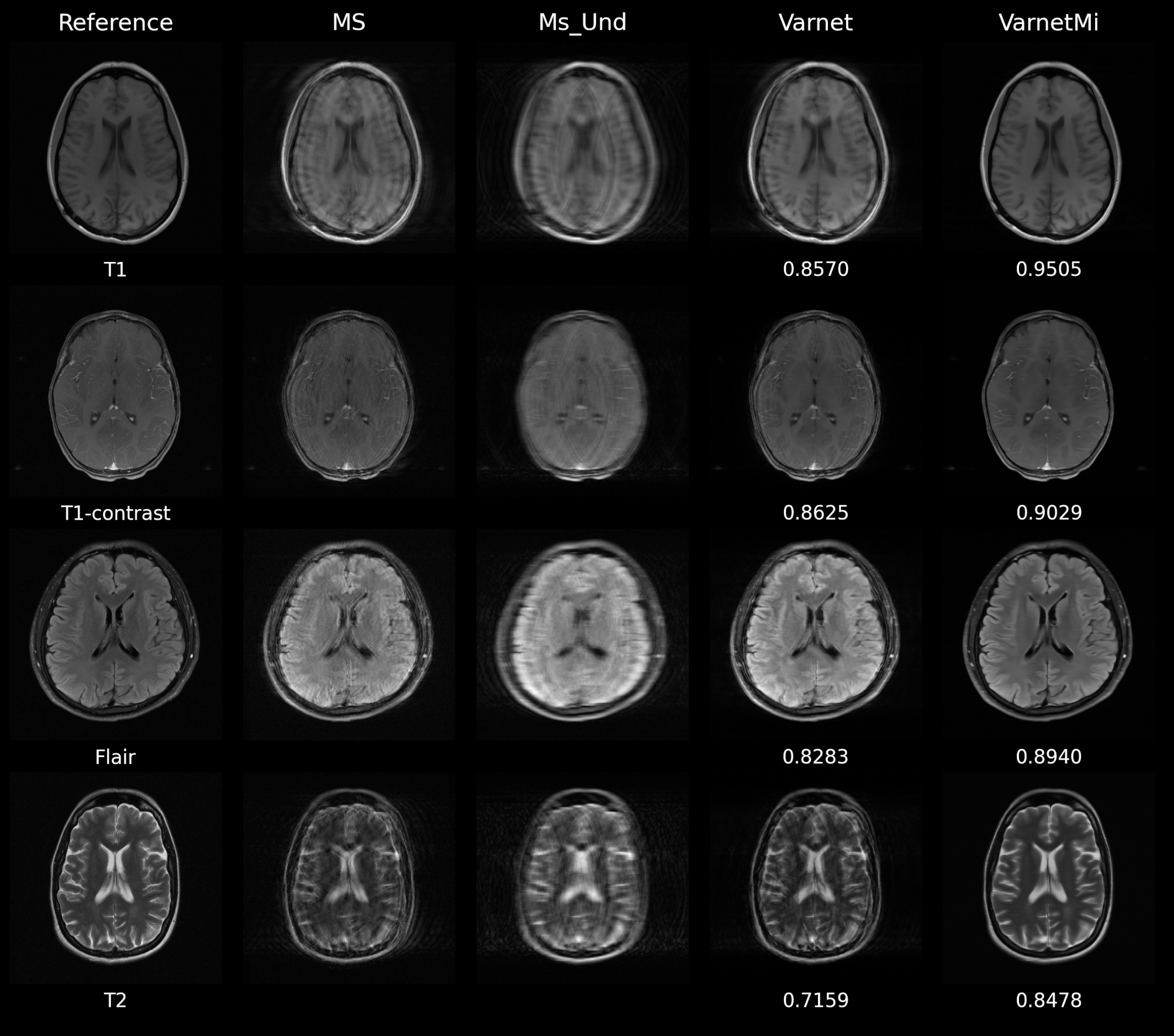
Figure
2: Representative
images comparing Varnet and motion aware VarnetMi in the presence of motion; Reference:
Ground truth images; MS: images corrupted with motion artifacts; Ms_Und:
motion corrupted image undersampled with an acceleration factor of four; Varnet:
reconstruction using the variational network with six iterations; VarnetMi:
reconstructions using the motion aware variational network with six iterations.
The numbers below each image in the right hand two columns show the structural
similarity scores in comparison to the images in the reference column.
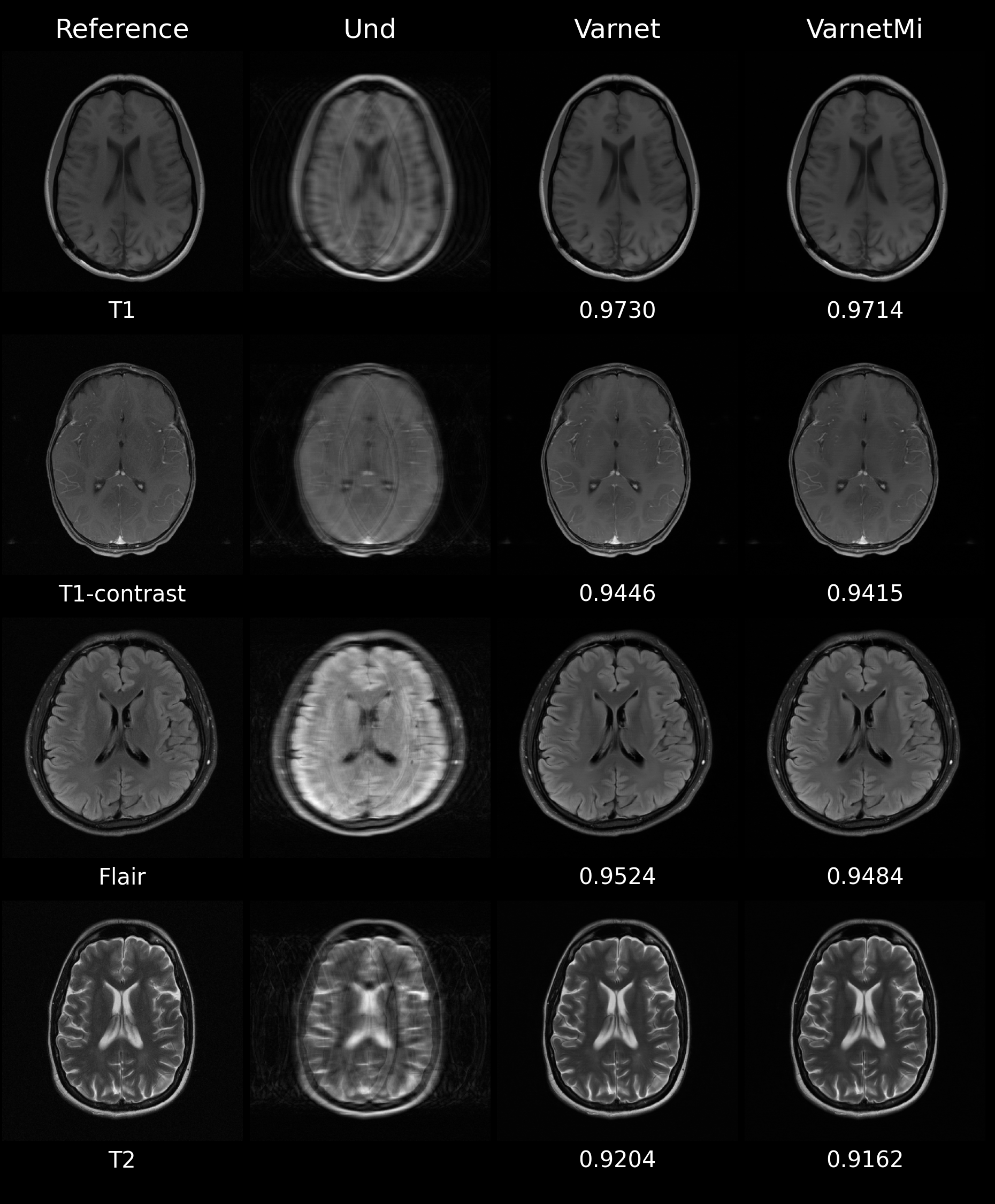
Figure
3: Representative
images comparing Varnet and motion aware VarnetMi in the absence of motion; Reference:
Ground truth images; Und: image undersampled with an acceleration factor
of four; Varnet: reconstruction using the variational network with six
iterations; VarnetMi: reconstructions using the motion aware variational
network with six iterations. The numbers below each image in the right hand two
columns show the structural similarity scores in comparison to the images in
the reference column.
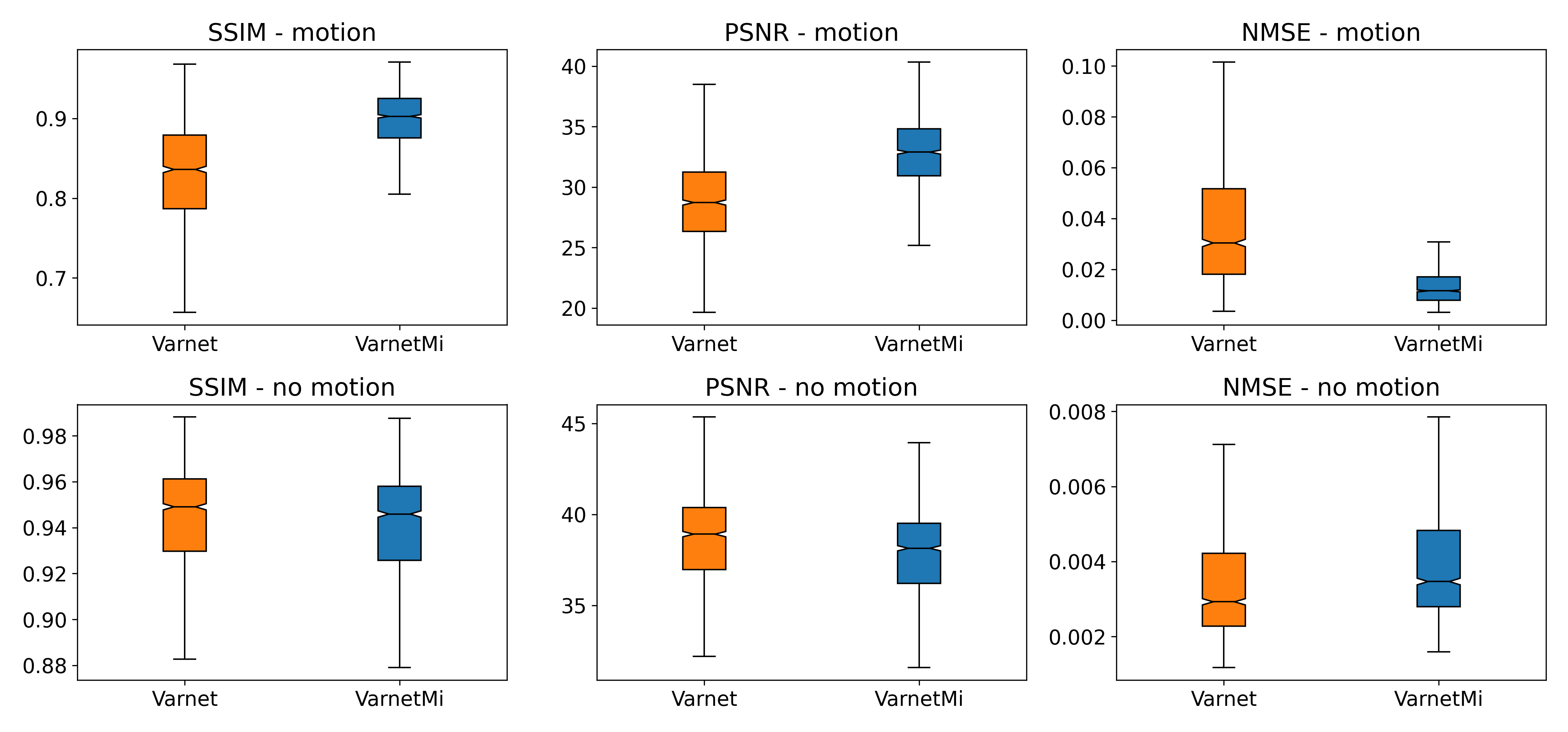
Figure
4: Group results
on the 1300 slices (different subjects) consisting of T1, T2, T1-contrast, and
Flair images. Top row: Quantitative scores for the reconstruction in the
presence of motion; Bottom row: Quantitative scores for the
reconstruction in the absence of motion. There was a marked improvement in the SSIM,
PSNR, and NMSE using the proposed VarnetMi method compared to the Varnet method.
In the absence of motion, there was a slight degradation in the performance of
VarnetMi compared to Varnet.
DOI: https://doi.org/10.58530/2022/4691