4431
Prediction of Total Knee Replacement using Vision Transformers
Chaojie Zhang1, Haresh Rengaraj Rajamohan2, Kyunghyun Cho2, Gregory Chang1, and Cem M. Deniz1
1Department of Radiology, New York University Langone Health, New York, NY, United States, 2Center for Data Science, New York University, New York, NY, United States
1Department of Radiology, New York University Langone Health, New York, NY, United States, 2Center for Data Science, New York University, New York, NY, United States
Synopsis
Vision transformers were used to predict total knee replacement within 9 years from magnetic resonance images. Inspired by MRNet, 2D slices of an MR image were encoded by a vision transformer and these encodings were aggregated to provide a single prediction outcome from a 3D MR volume. Our results suggest that the prediction performance of vision transformers was comparable with the models based on convolutional neural networks for the outcome prediction task. Moreover, training models with stochastic gradient descent optimizer provided a better performance compared with the Adam optimizer.
Introduction
Osteoarthritis (OA) is the most common form of arthritis and it is the most common reason leading to total knee joint replacement (TKR). It is important to identify patients who will progress to undergo a TKR so that the potential disease-modifying therapies can be effectively developed/tested. MRNet, an approach based on convolutional neural networks (CNNs), has been proposed for classification tasks on knee MRI and it achieved radiologist level performance on detecting disorders1. Recently, vision transformers (ViTs)2 have been shown to outperform CNNs in the classification of natural images. In the medical domain, ViTs and CNNs were compared on three mainstream medical image datasets and it was found that ViTs with transfer learning can reach comparable performance as CNNs in small medical datasets3. In this study, we adapted MRNet with vision transformers and used this model to predict TKR from knee MR images of different contrast. In addition to the backbone architecture changes, we applied a training strategy with stochastic gradient descent (SGD) to improve the performance of outcome prediction models.Methods
MR images from the Osteoarthritis Initiative (OAI) dataset4 were used in the study: coronal intermediate-weighted turbo spin echo (COR IW TSE), sagittal 3D double-echo steady-state with water excitation (SAG 3D DESS WE), SAG IW TSE with fat suppression (SAG IW TSE FS) images, and first echo time images of SAG T2 mapping sequence (SAG T2 MAP). Parameters of these imaging sequences are provided in Table 1. Each imaging sequence enables us to extract different sometimes overlapping information of different parts of the knee joint.For SAG T2 MAP, COR IW TSE and SAG IW TSE FS images, the center 36 slices were used as model input and zero padding was applied when the number of slices were below 36. For SAG 3D DESS WE, 160 slices were separated into four disjoint sections (40 slices for each) with a step size of 4 due to limitations on GPU memory size. Predictions from these four sections were averaged. Seven-fold cross-validation was used on a case-control cohort of 718 subjects, where cases were identified as individuals who underwent a TKR within 9 years from the baseline and controls who didn't undergo a TKR within 9 years5.
Three approaches were implemented: (1) MRNet (Figure 1 a) used an ImageNet pre-trained AlexNet as the base model, it took a series of MR images as input, each slice of the MRI series was fed through the base model. The series of base model features were then connected to a max-pooling layer and a fully connected layer. (2) S-MRNet (Figure 1 b) used the same model architecture as MRnet but took adjacent three slices, instead of only one, as base model input. (3) Within the MRNet structure, ViT-MRNet (Figure 1 c) replaced AlexNet with ImageNet pre-trained ViT-B/162, and used adjacent three slices as base model input.
Two different optimizers were analyzed in each approach: (1) The first training strategy was proposed by MRNet, using Adam with a base learning rate of 1⋅10−5, weight decay of 0.01, and ReduceLROnPlateau. (2) We implemented a training strategy with SGD, with a base learning rate of 3⋅10−2, momentum of 0.9, linear learning rate warmup of 50 steps, and cosine learning rate decay. All models were trained for 100 epochs. Models were selected based on the area under the receiver operating characteristic curve (AUC) in the validation set.
Results
For each model using CNNs or vision transformers, comparable performance was observed with different MR images as an input (Table 2). The best performing model used COR IW TSE images and ViT-MRNet model trained with SGD (AUC with a 95% confidence interval = 0.91±0.02). In contrast to a vision transformer model for COR IW TSE images, other vision transformer models performed worse than models using CNNs (SAG T2 MAP, SAG IW TSE, and SAG 3D DESS). MRNet and S-MRNet achieved similar prediction performance overall for different image types.Conclusion and Discussion
We demonstrated the use of vision transformers to predict the total knee replacement outcome using MR images of different contrasts. We observed that the training strategy using SGD improved the performance of all models. Even though previous research using 2D medical images reported better performance using vision transformers3, we have only observed improvements in one of the contrasts but not in all. Further investigation of vision transformer implementations and pre-training tailored to medical 3D volumes could bring the promise of vision transformers to the prediction tasks using MR images.Acknowledgements
This work was supported in part by NIH grant R01 AR074453, and was performed under the rubric of the Center for Advanced Imaging Innovation and Research (CAI2R, www.cai2r.net), a NIBIB Biomedical Technology Resource Center (NIH P41 EB017183).References
1. Bien N, Rajpurkar P, Ball RL, et al. Deep-learning-assisted diagnosis for knee magnetic resonance imaging: Development and retrospective validation of MRNet. PLoS medicine. 2018;15(11):e1002699. https://www.ncbi.nlm.nih.gov/pubmed/30481176. doi: 10.1371/journal.pmed.1002699.2. Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale. . 2020. https://arxiv.org/abs/2010.11929.
3. Matsoukas C, Haslum JF, Söderberg M, Smith K. Is it time to replace CNNs with transformers for medical images? . 2021. https://arxiv.org/abs/2108.09038.
4. Peterfy, C.G., M.D., Ph.D, Schneider E, Ph.D, Nevitt M, Ph.D. The osteoarthritis initiative: Report on the design rationale for the magnetic resonance imaging protocol for the knee. Osteoarthritis and cartilage. 2008;16(12):1433-1441. https://www.clinicalkey.es/playcontent/1-s2.0-S1063458408002239. doi: 10.1016/j.joca.2008.06.016.
5. Leung K, Zhang B, Tan J, et al. Prediction of total knee replacement and diagnosis of osteoarthritis by using deep learning on knee radiographs: Data from the osteoarthritis initiative. Radiology. 2020;296(3):584-593. https://www.ncbi.nlm.nih.gov/pubmed/32573386. doi: 10.1148/radiol.2020192091.
Figures

Table 1: Parameters of different MRI sequences.
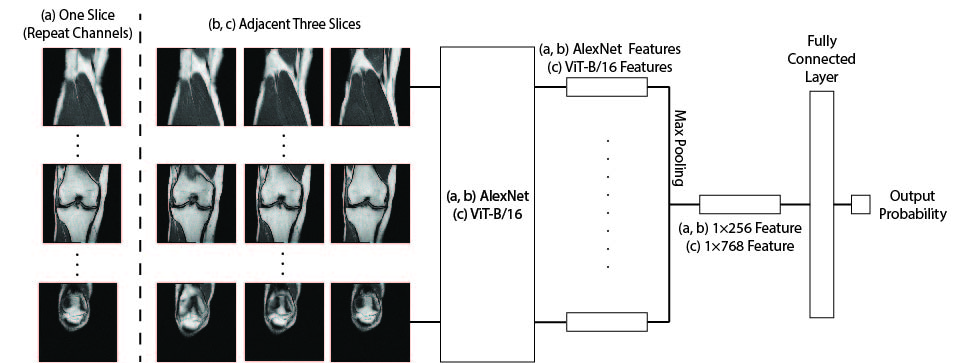
Figure 1: Model architectures. (a) MRNet. (b) S-MRNet. (c) ViT-MRNet.

Table 2: Total knee replacement prediction results using different deep learning approaches.
DOI: https://doi.org/10.58530/2022/4431