4429
Water-Fat Separation from Dual-Echo Dixon Imaging Using Deep Learning
Yan Wu1, Marc Alley 1, Keshav Datta1, Zhitao Li 1, Christopher Sandino 1, Zhifei Wen2, Michael Lustig3, John Pauly1, and Shreyas Vasanawala1
1Stanford University, Stanford, CA, United States, 2Hoag Hospital, Newport Beach, CA, United States, 3University of California, Berkeley, Berkeley, CA, United States
1Stanford University, Stanford, CA, United States, 2Hoag Hospital, Newport Beach, CA, United States, 3University of California, Berkeley, Berkeley, CA, United States
Synopsis
We design a data-driven method to generate water/fat images from dual-echo complex Dixon images, aimed at near-instant water-fat separation with high robustness. A hierarchical convolutional neural network is employed, where ground truth images are obtained using a binary quadratic optimization approach. With IRB approval and informed consent, 9281 image sets are collected from 30 pediatric patients to train and test networks, with the application of six-fold cross validation. In addition to high fidelity and significantly reduced processing time, the predicted images are superior to the ground truth in mitigation of water/fat swaps and correction of artifacts introduced by metallic implants.
INTRODUCTION
Two-point Dixon MR imaging is an effective water-fat separation approach. However, it is prone to global and local water/fat swaps, and robust separation algorithms suffer long postprocessing time. In this study, we design and evaluate a data-driven method to generate water/fat images from dual-echo complex Dixon images, aimed at near-instant water-fat separation with high robustness.METHODS
With IRB approval and informed patient consent, 9281 contrast-enhanced dual-echo Dixon image sets were acquired on GE scanners, including 7589 images of the knee from 25 subjects and 1692 images of other anatomic regions from five subjects. A 3D SPGR sequence was applied with variable density Poisson disc sampling pattern. Based upon prescribed image resolution and system gradient strength, there are two clusters of TR (4.48 – 4.78ms or 6.54 – 7.39ms), a TE of 2.23ms for in-phase images and two clusters of TE (1.21 - 1.31ms or 3.35ms) for out-of-phase images. The in-phase and out-of-phase images are reconstructed with the ARC algorithm. A hierarchical convolutional neural network is designed to derive water/fat images from phase and magnitude of in-phase and out-of-phase images. It is a hierarchical network with densely connected local shortcuts and global shortcuts [1]. The method is shown in Figure 1.The ground truth images for network training are obtained using a robust but lengthy binary quadratic optimization approach -- an iterative projected power method [2], which is more accurate than more routinely used algorithms (e.g., region growing). In addition to phasor calculation and phasor selection (which directly serve for water-fat separation), coil compression and downsampling/upsampling are conducted to speed up data processing. To investigate the impact of background noise, models are trained twice, once with original images and once with images segmented to remove non-tissue background. A total of 9281 image sets collected from 30 subjects are used to train and test networks, with the application of six-fold cross validation. In particular, models trained with only knee images are also assessed on out-of-distribution data (from other anatomic regions, with metallic implants, or acquired at different magnetic field strength). A loss is employed, and network parameters are updated using the Adam algorithm with of 0.001, of 0.89, of 0.89, and of . Computational time is compared. Accuracy is evaluated by calculating correlation coefficient, error, and structural similarity indices (SSIM).
RESULTS
On average, the data processing time required for a 2D image is 0.13 seconds using deep learning, as compared to 1.5 seconds using the projected power approach. In terms of quantitative evaluation of accuracy of the methods, correlation coefficient, error and SSIM of every subject are shown in Figure 2. Of note, the models established with segmented images have very similar performance to those trained with unsegmented images. Generated images have high fidelity relative to the ground truth images. A representative example is illustrated.The proposed method corrects severe errors in the ‘ground truth’ images. In an ankle examination shown in Figure 3, progressively severe water/fat swaps occur in the ground truth slices that get farther from isocenter. In the predicted images, the water/fat swaps are largely corrected. In a foot examination, severe water/fat swaps occur in the ‘ground truth’ images, and the predicted images just have a few smaller swaps.
Another example of robustness to out-of-distribution data, in this case a metallic object, is shown in Figure 4. Severe artifacts appear in the ‘ground truth’ water/fat images. Interestingly, the predicted images lack these artifacts. An even more difficult case with metallic implants is demonstrated, where images of the ankle were acquired on a 1.5T scanner. The substantial magnetic field inhomogeneity is not only reflected in the phase of the input images, but also present in the magnitude of the input images as significant signal loss, leading to apparent metal artifacts in the ‘ground truth’ images. Meanwhile, severe water/fat swaps occur in this off-isocenter ankle slice. In the predicted images, these two categories of artifacts are simultaneously mitigated, even when the model is trained with only knee images acquired on 3T scanners. Of note, in both cases, the training set lacks any examples with metallic implants.
DISCUSSION
Using the proposed method, predicted images are superior to ground truth in several aspects, including mitigation of global or local water/fat swaps, and correction of artifacts introduced by metallic implants. Robust separation is also demonstrated in out-of-distribution data.The proposed method is more practically useful than previous deep learning-based water-fat separation approaches, which require a large number of multi-echo images as the input. Dual-echo water-fat separation is highly desirable in clinical practice due to its high data acquisition efficiency. Particularly in abdominal imaging, where dual-echo Dixon imaging is often an essential part of the clinical imaging protocol, the proposed method may support water-fat separation without acquisition of an additional echo.
The average processing time for a volumetric dataset with 400 slices is reduced from 10 minutes to under one minute. The marked reduction in compute time is critical for contrast-enhanced imaging, since technologists must rapidly evaluate the images for adequacy.
CONCLUSION
A deep learning method is proposed for near-instant water-fat separation from dual-echo Dixon images, and robustness to three forms of out-of-distribution data has been demonstrated.Acknowledgements
The research was supported by NIH R01EB009690, NIH R01 EB026136, NIH R01DK117354, and GE HealthcareReferences
1. Y. Wu, Y. Ma, D. P. Capaldi, J. Liu, W. Zhao, J. Du, et al., "Incorporating prior knowledge via volumetric deep residual network to optimize the reconstruction of sparsely sampled MRI," Magnetic resonance imaging, 2019. 2. Zhang, Tao, et al. "Resolving phase ambiguity in dual‐echo dixon imaging using a projected power method." Magnetic resonance in medicine 77.5 (2017): 2066-2076.Figures
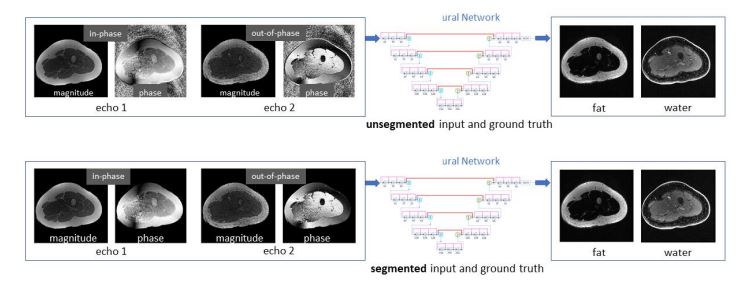
Deep learning-based water-fat separation from
dual-echo Dixon imaging. A deep neural network is employed to provide the
end-to-end mapping from dual-echo Dixon images to the corresponding water/fat
images. Original images are used as the input and ground truth (as illustrated
in the upper row). Alternatively, a
manually segmented mask is applied on every input and ground truth image to
investigate whether the background noise in the input phase images impedes
model training (as illustrated in the lower row).
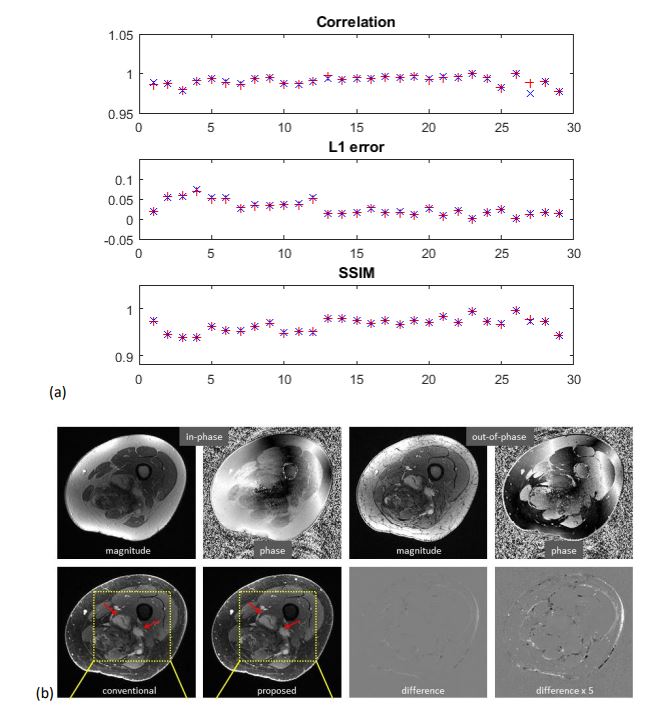
High
accuracy has been achieved using the proposed method. (a) Quantitative
evaluation. When unsegmented images are used, correlation coefficient is
between 0.9772 and 1.0000 with mean/std of 0.9913 ± 0.0055, error is
between 0.0102 and 0.0203 with mean/std of 0.0270 ± 0.0181, and SSIM is between
0.9522 and 0.9900 with mean/std of 0.9655 ± 0.0154. The models trained with segmented
images have very similar performance. (b) a) In this example, highly accurate
water images of the knee are predicted, where the enhancing tumors are well
delineated.
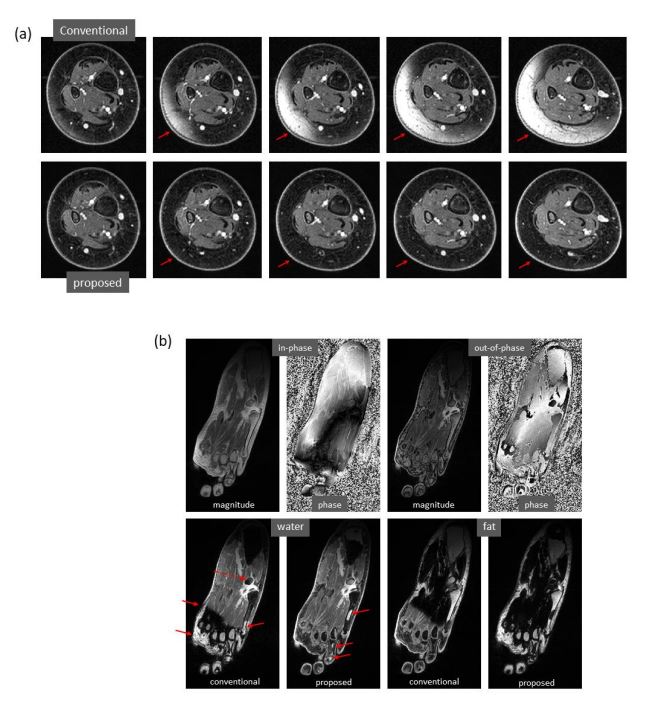
Marked correction of severe water/fat swaps. (a) In the ‘ground truth’
images of the low calf obtained using conventional approach, progressively
severe water/fat swaps occur in the slices farther from isocenter. In the
predicted images, the water/fat swaps are completely corrected. (b) In the
‘ground truth’ images of the foot, severe water/fat swaps appear, where dashed
arrow shows an accessory ossicle with marrow edema that also has a local swap
in its marrow. The water/fat swaps are substantially compensated in the
predicted images, which only have smaller regions of swaps.
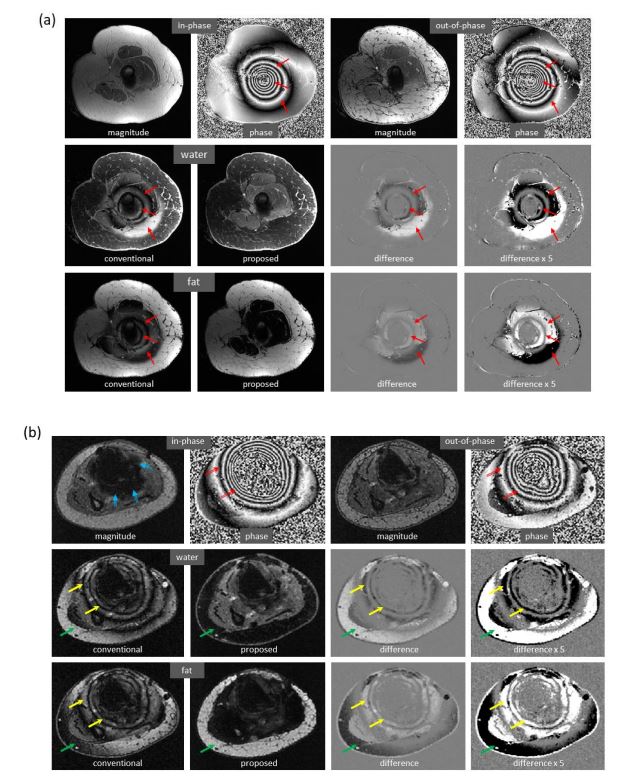
Marked
reduction of metal-induced artifacts, where the training set lacks any examples
with metallic implants. (a) In this case, metal-induced artifacts, which occur
in the ‘ground truth’ images, are largely corrected in the predicted images.
(b) Severe metal-induced artifacts exist in the ‘ground truth’ images, which
come from signal loss and phase corruption in the input images of the ankle acquired
on a 1.5T scanner. In addition, water/fat swaps occur in this off-center slice.
In the predicted images, both types of errors are simultaneously mitigated.
DOI: https://doi.org/10.58530/2022/4429