4356
Accelerate MR imaging by anatomy-driven deep learning image reconstruction1Laboratory of Biomedical Imaging and Signal Processing, The University of Hong Kong, Hong Kong, China, 2Department of Electrical and Electronic Engineering, The University of Hong Kong, Hong Kong, China
Synopsis
Supervised deep learning (DL) methods for MRI reconstruction is promising due to their improved reconstruction quality compared with traditional approaches. However, all current DL methods do not utilise anatomical features, a potentially useful prior, for regularising the network. This preliminary work presents a 3D CNN-based training framework that attempts to incorporate learning of anatomy prior to enhance model’s generalisation and its stability to perturbation. Preliminary results on single-channel HCP, unseen pathological HCP and IXI volumetric data (effective R=16) suggest its potential capability for achieving high acceleration while being robust against unseen anomalous data and data acquired from different MRI systems.
Introduction
Recently, supervised deep learning (DL) approaches for MR image reconstruction have received much attention as they outperform conventional methods1-6, allowing greater acceleration with potential clinical applicability. However, all current data-driven DL procedures solving the ill-posed inverse problem do not explicitly utilise the omnipresent mutual anatomical features across human brains for regularising the solutions. The use of such neglected anatomy constraints might drastically increase the image formation efficiency and image quality, enhance robustness to perturbation and generalisation of the supervised DL approaches7. Yet, no relevant frameworks exist in present time to incorporate such constraints in assisting DL reconstruction to further accelerate MR imaging.In this preliminary study, we aim to tackle this problem by pursuing an end-to-end truly 3D CNN-based training framework that embeds learning of anatomy prior to regularise and drive MRI reconstruction for highly undersampled single-channel 3D data.
Methods
The problem of finding reconstructed image $$$\mathbf{\hat{f}}$$$ can be formulated as $$\mathbf{\hat{f}}=\underset{\mathbf{f}}{\arg\min}\|\mathbf{Af}-\mathbf{y}\|^2+R(\mathbf{f})$$where $$$\mathbf{y}$$$ denotes the k-space data, $$$\mathbf{A}$$$ represents the system matrix. The regularisation term $$$R(\mathbf{f})$$$ in model-based DL methods is a CNN with learnt image prior to ensure the convergence of the iterative process while reducing noise and artefacts. By altering the training scheme of the CNN regulariser, we can potentially learn and leverage the genetically pre-defined and highly homogenised brain anatomical information (prior) to guide the reconstruction further, achieving greater acceleration with stability.We propose a training framework (Figure 1) and 3D CNN-based network (Figure 2) to enforce the learning of extracting a complementary and robust set of volumetric anatomical features from the original undersampled complex volume $$$\mathbf{x}_{ref}$$$ and $$$k$$$ deformed versions $$$\mathbf{x}_k$$$:
For training, random deformation fields generating perturbed copies $$$\mathbf{x}_k$$$ were sampled from a Gaussian distribution with zero mean, small variance $$$\sigma^2$$$ such that $$$\mathbf{x}_{ref}\approx\,\mathbf{x}_k$$$ in the feature space. The framework can be thought as an adversarial training scheme8. This steers the learning of optimal weights for weight-shared feature extractors and fusion block to allow selective aggregation and maximisation of mutual information in anatomy between the original and perturbed latent representations given the hard training task of reconstructing $$$\mathbf{x}_{ref}$$$. This essentially regularises the network via learning robust anatomy prior information, stabilising and/or improving the reconstruction task.
For inference, given the perturbed versions $$$\mathbf{x}_k$$$ were similar to the original $$$\mathbf{x}_{ref}$$$, we can replicate $$$\mathbf{x}_{ref}$$$ $$$k$$$ times to exploit self-similarities with the fusion block for improved reconstruction. We set $$$k=1$$$ to reduce computational burden.
We adopted 3D UNet++9 as feature extractors to capture coarse-to-fine features of the undersampled inputs. The pyramid processing allows multiscale extraction of self-similarities and efficient transfer of feature maps through dense connections. Residual groups10 replaced standard convolution blocks to facilitate learning of inter-channel relationship, and to ensure passage of valuable low-frequency information through short and long skip connections. The fusion block uses 3D convolutions to merge extracted information from $$$x_{ref}$$$ and $$$x_k$$$, while the spatial attention11 spatially emphasises the crucial anatomical features in fused feature maps.
Data and Pre-processing
1113 fully-sampled T1-weighted 3D magnitude brain volumes were obtained from HCP S1200 dataset12. The data were corrected with N4 correction algorithm13. To reduce computational costs, data were downsampled and cropped to have a small matrix size of 64×64×48 (isotropic 2.8mm3). To simulate phase-modulation, random quadratic phase maps were applied to the magnitude-only data. The dataset was randomly split into train/validation/test sets at a ratio of 7:1:2. Data were retrospectively undersampled by variable-density 2D Poisson-disk pseudo-random mask with effective R=16.
Training Details
A mixed MS-SSIM[14]-L1 loss: $$$\mathcal{L}=\alpha\cdot\,l_{\text{MS-SSIM}}+(1-\alpha)\cdot\,l_{\text{l1}}$$$ was employed to preserve luminance and contrast in high-frequency and local regions15, where $$$\alpha=0.98$$$. The model was trained using ADAM optimiser and one-cycle scheduler with maximum learning rate 1×10-4 for 200 epochs on a RTX A6000. The batch size was set to 4. We further optimised the speed and memory usage by employing mixed-precision training16. The training time was 2 days.
Testing
For quantitative performance evaluation, we computed peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM)17 metrics over the whole 3D volume. To assess the generalisability, 1.5T and 3T data from out-of-domain IXI dataset18 were used. IXI data were downsampled and cropped to have similar FOV and resolution (isotropic 2.81mm3) as the training data.
Results
Figure 3 and 4 depicts results on normal and pathological HCP data with effective R=16. The model can reasonably remove undersampling artefacts and reconstruct unseen anomalies despite the high acceleration rate. However, isotropic 1-2 voxel-wide blurring can be consistently observed among all results. Figure 5 shows reconstructed results with untrained IXI data acquired from different systems. Results suggest potential generalisability of the framework and model.Discussion and Conclusion
This work presents a novel 3D DL framework to learn anatomy prior for MRI reconstruction at high acceleration. The preliminary results are promising, indicating its ability for highly accelerated single-channel volumetric image reconstruction with potential capability even in presence of anomalies unseen in the training set and for data acquired from other MRI scanners. However, the isotropic blurring problem remains to be resolved likely through improving general architecture including using unrolled method and adopting multiscale feature fusion. Furthermore, deploying and validating the proposed methodology to accelerate reconstruction under multi-coil settings is one of our future goals to ensure clinical relevance.Acknowledgements
This work was supported in part by Hong Kong Research Grant Council (R7003-19F, HKU17112120 and HKU17127121 to E.X.W., and HKU17103819, HKU17104020 and HKU17127021 to A.T.L.L.), Lam Woo Foundation, and Guangdong Key Technologies for Treatment of Brain Disorders (2018B030332001) to E.X.W.References
1. Hammernik K, Klatzer T, Kobler E, Recht MP, Sodickson DK, Pock T, et al. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med. 2018;79(6):3055-71.
2. Schlemper J, Caballero J, Hajnal JV, Price AN, Rueckert D. A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans Med Imaging. 2018;37(2):491-503.
3. Yang G, Yu S, Dong H, Slabaugh G, Dragotti PL, Ye X, et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Trans Med Imaging. 2018;37(6):1310-21.
4. Aggarwal HK, Mani MP, Jacob M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans Med Imaging. 2019;38(2):394-405.
5. Knoll F, Murrell T, Sriram A, Yakubova N, Zbontar J, Rabbat M, et al. Advancing machine learning for MR image reconstruction with an open competition: Overview of the 2019 fastMRI challenge. Magn Reson Med. 2020.
6. Muckley MJ, Riemenschneider B, Radmanesh A, Kim S, Jeong G, Ko J, et al. Results of the 2020 fastMRI Challenge for Machine Learning MR Image Reconstruction. IEEE Transactions on Medical Imaging. 2021;40(9):2306-17.
7. Antun V, Renna F, Poon C, Adcock B, Hansen AC. On instabilities of deep learning in image reconstruction and the potential costs of AI. Proc Natl Acad Sci U S A. 2020.
8. Genzel M, Macdonald J, März M. Solving Inverse Problems With Deep Neural Networks--Robustness Included? arXiv preprint arXiv:201104268. 2020.
9. Zhou Z, Mahfuzur Rahman Siddiquee M, Tajbakhsh N, Liang J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation2018 July 01, 2018:[arXiv:1807.10165 p.]. Available from: https://ui.adsabs.harvard.edu/abs/2018arXiv180710165Z.
10. Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y, editors. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. Computer Vision – ECCV 2018; 2018 2018//; Cham: Springer International Publishing.
11. Woo S, Park J, Lee J-Y, Kweon IS, editors. CBAM: Convolutional Block Attention Module. Computer Vision – ECCV 2018; 2018 2018//; Cham: Springer International Publishing.
12. Van Essen DC, Smith SM, Barch DM, Behrens TEJ, Yacoub E, Ugurbil K. The WU-Minn Human Connectome Project: An overview. NeuroImage. 2013;80:62-79.
13. Tustison NJ, Avants BB, Cook PA, Zheng Y, Egan A, Yushkevich PA, et al. N4ITK: Improved N3 Bias Correction. IEEE Transactions on Medical Imaging. 2010;29(6):1310-20.
14. Wang Z, Simoncelli EP, Bovik AC, editors. Multiscale structural similarity for image quality assessment. The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003; 2003 9-12 Nov. 2003.
15. Zhao H, Gallo O, Frosio I, Kautz J. Loss Functions for Image Restoration With Neural Networks. IEEE Transactions on Computational Imaging. 2017;3(1):47-57.
16. Micikevicius P, Narang S, Alben J, Diamos GF, Elsen E, García D, et al. Mixed Precision Training. International Conference on Learning Representations (ICLR); Vancouver2018.
17. Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process. 2004;13(4):600-12.
18. Group BIA. IXI Dataset: Imperial College London; [Available from: http://brain-development.org/ixi-dataset/.
Figures
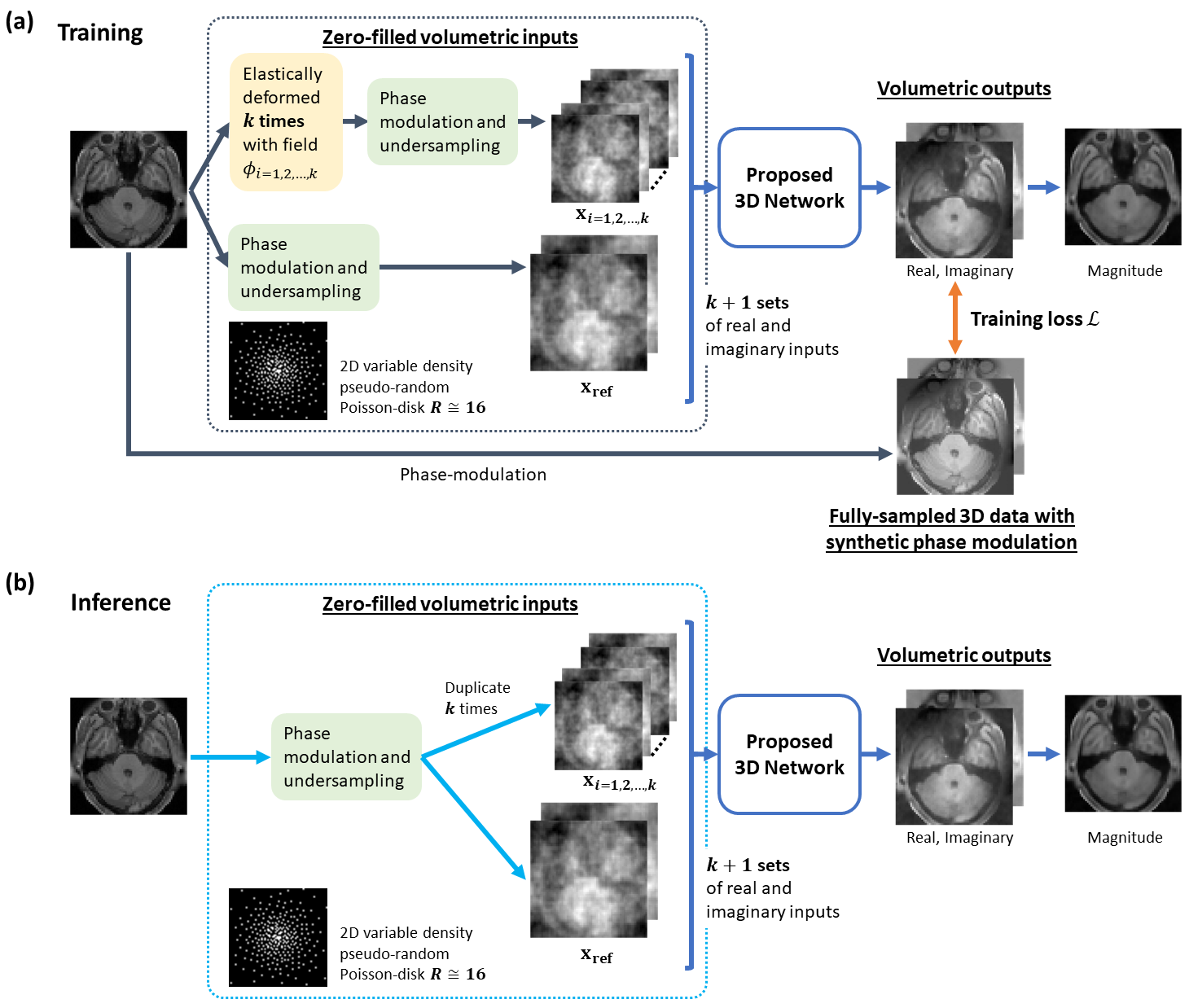
Figure 1. Illustration of the proposed anatomy-driven 3D DL framework. The steps of data processing for inputs of CNN-based network differ depending on the mode of network. During training (a), the original input is firstly elastically deformed by k random deformation fields, resulting in k perturbed inputs and 1 undeformed, original input. The phase and retrospective undersampling are then introduced. Components are treated as separate input channels. For inference (b), the complex input is replicated k times to produce k+1 inputs to the network together with the original input.
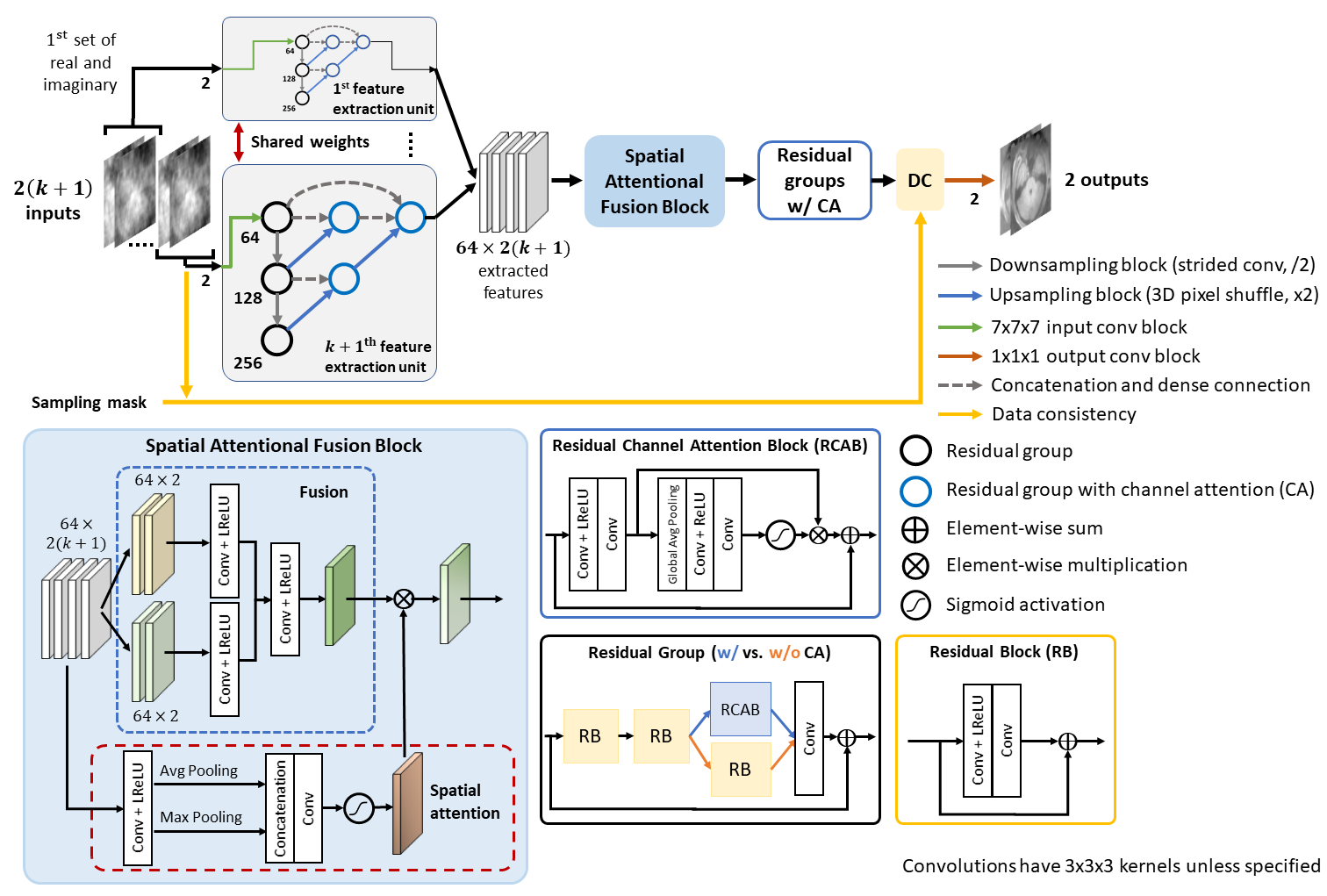
Figure 2. Architecture of the proposed 3D model. The complex MR volumes’ real and imaginary components are split into separate channels, giving a total of 2(k+1) input channels. In our model (k=1), the two weight-sharing UNet++-based feature extractors would extract self-similarity from x_ref and x_k. After the feature extractors, a spatial attentional fusion block fuses the feature maps and passes the spatially-modulated fused features to residual groups with channel attention for reconstruction. A learnable data consistency module is placed before the final convolution.
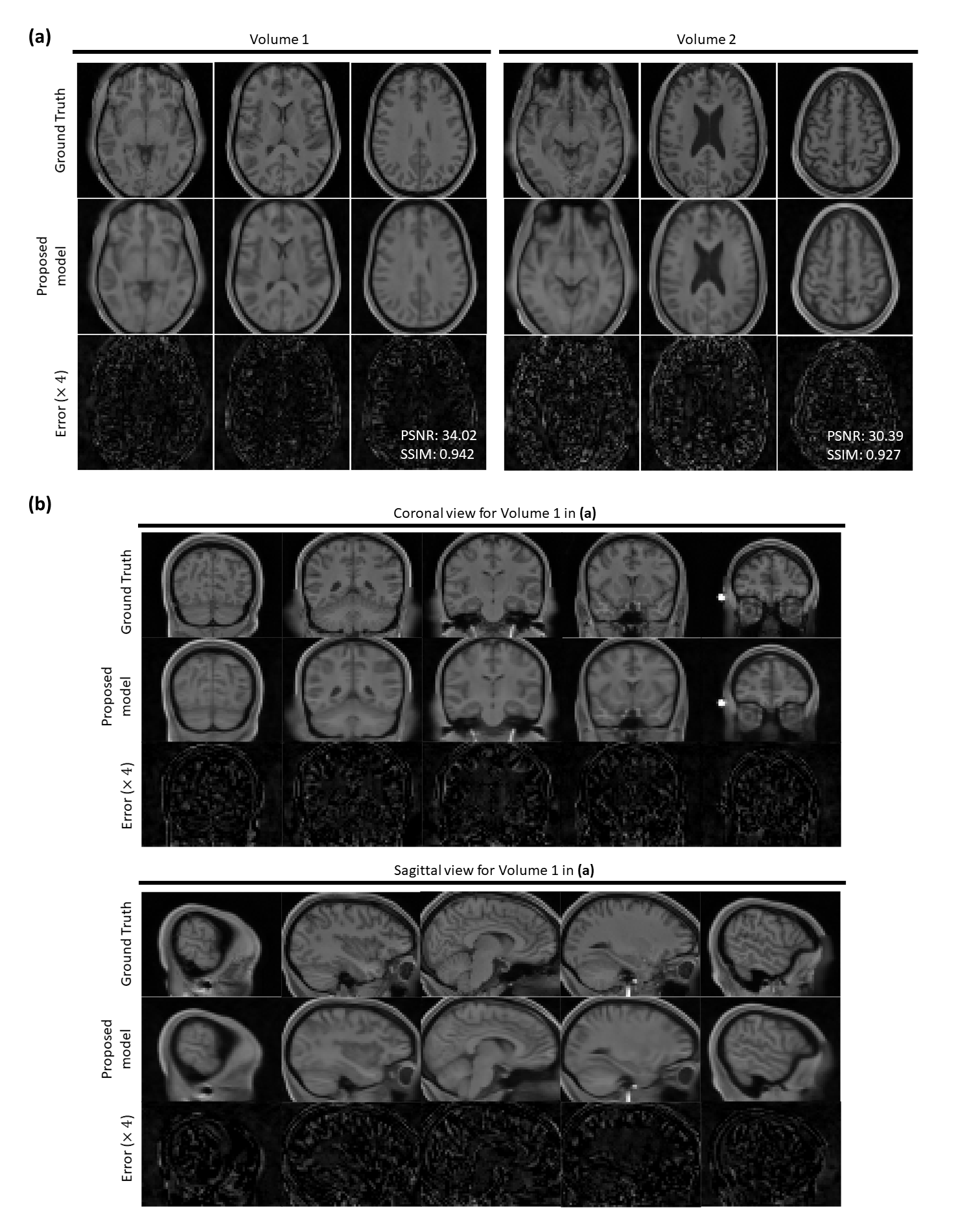
Figure 3. Reconstructions on two HCP single-channel volume test data (R=16). (a) Three axial slices are shown from two 3D volumes. PSNR and SSIM values for the whole volumes are given in the bottom right of error maps. (b) Sagittal and coronal views of the reconstruction for Volume 1 in (a). Top rows show the extracted fully-sampled slices from corresponding 3D volume. Middle and bottom rows show the reconstructed magnitude images by the proposed method and error maps respectively. Proposed method can successfully remove undersampling artefacts and reproduces coherent 3D structures.
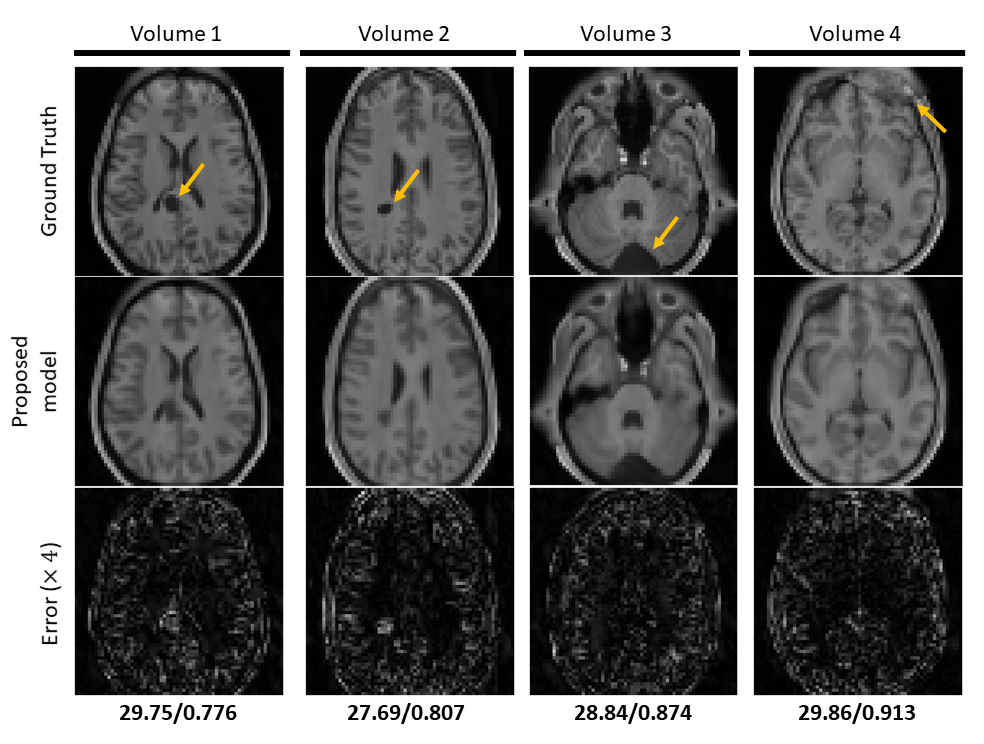
Figure 4. Reconstruction results on hold-out pathological HCP single-channel volume data (R=16). Top row shows the extracted fully-sampled axial slices from the corresponding 3D volume. Middle and bottom row show the reconstructed magnitude images by the proposed method and error maps respectively. PSNR and SSIM values are given below the error maps. Pathologies are indicated by orange arrows. The proposed method shows promising results on reconstructing the anomalies correctly despite the high acceleration factor by efficiently utilising the anatomical features.
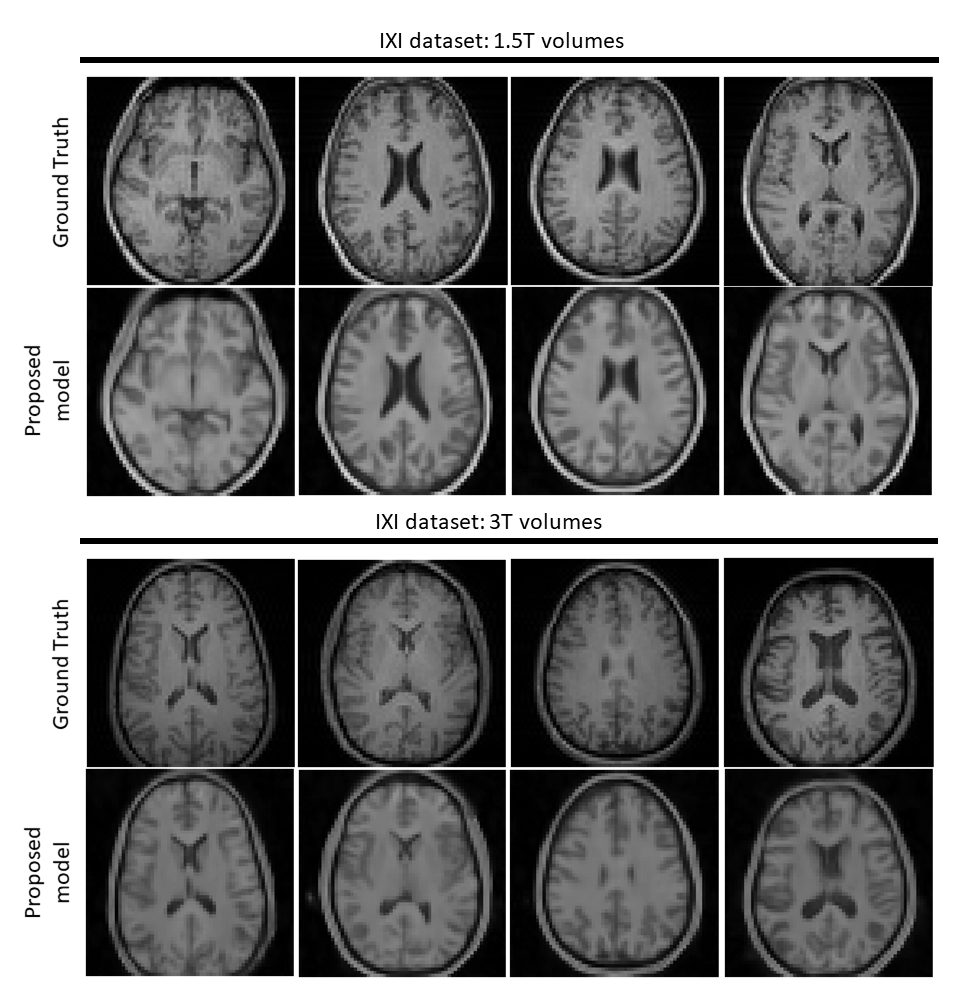
Figure 5. Results on out-of-domain single-channel IXI volume data (R=16). Top and bottom half present reconstructions of data acquired using a Philips 1.5T system and a 3T system respectively. Top rows show the fully-sampled axial slices from 4 distinct volumes. Bottom rows show the reconstructed images by the proposed method. Although contrast changes (to match HCP data) and hallucinations are notable, residual artefacts are not visible in the reconstructions. Major anatomical landmarks are also placed appropriately, indicating some robustness to feature distribution shifts.