4339
Transformer based Self-supervised learning for content-based image retrieval1GE Healthcare, Bangalore, India, 2GE Global Research, Niskayuna, NY, United States
Synopsis
Diversity in training data encompassing variety of patient conditions is a recipe for the success of medical models based on DL. Ensuring diverse patient conditions is often impeded by the necessity to manually identify and include such cases, which is time-consuming and expensive. Here we propose a method of retrieving images similar to a handful of example images based on features learnt using self-supervised learning. We demonstrate the features learnt using SSL on transformer based networks are excellent feature learners which not only eliminates the need for annotation but enable accurate KNN based image retrieval matching the desired patient conditions.
Introduction
Medical imaging solutions employing AI are impacted by the diversity in training data and is critical to ensure robust performance in clinical practice. But manually identifying or labelling even a fraction of images from a large data pool can be laborious, expensive and/or prohibitive. A possible solution could be to collect a few exemplars of the necessary variety for a given AI task and employ a content-based image retrieval (CBIR) system to retrieve similar images from data pool. Authors in [1] have demonstrated that self-distillation-based self-supervised learning (SSL) with Vision Transformers (ViTs) are capable of learning richer features as compared to using supervised learning on labelled data. In this work, we demonstrate such a ViT framework to automatically identify MRI images of different patient poses, patient conditions (e.g., scoliosis spine) and artifacts (metal) from a database of knee and spine MRI collections.Methods
Subjects: Knee and Spine MRI data for study came from multiple clinical sites and approved by respective IRBs. A total of 513 Knee MRI exams and 1200 spine MRI exams were included.MRI Data: Only three-plane localizer images for knee and spine (cervical, thoracic, and lumbar) anatomies were considered in the present study. MRI data had wide variety in terms of 1.5T and 3T GE MRI scanners, coil configurations, image contrast (gradient -echo, single-shot fast spin echo), resolution and matrix sizes across subjects. For Spine MR, only sagittal and coronal data was considered, while for knee, all planes were considered. Overall, knee images form a data pool of 24250 slices, while spine images form a pool of 9300 slices.
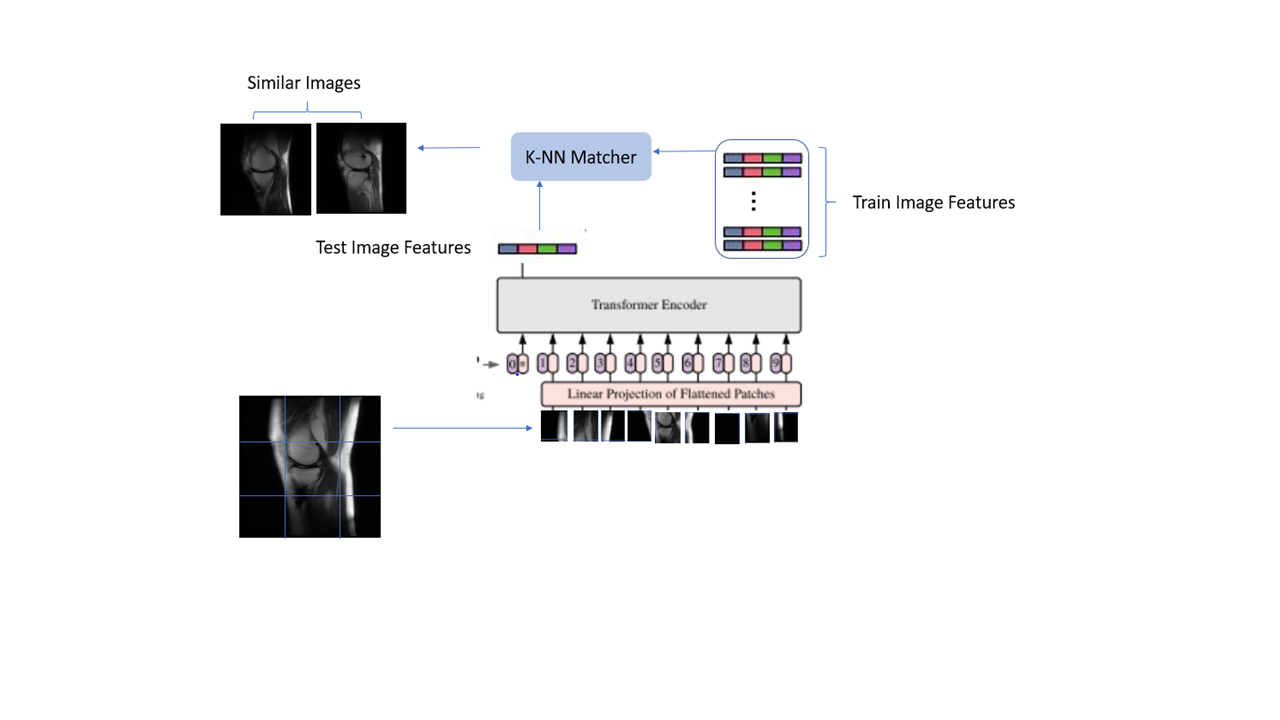
Vision Transformer based CBIR: The framework for ViT based CBIR is shown in Figure 1.
ViT Setup: Vision Transformers [2] consider image patches of fixed sizes and derive embeddings for these patches while encoding context information from other relevant patches and positional embedding. For our experiments, we use patch sizes of 16x16. We used 12 transformer blocks and six attention heads with 64 features per attention head resulting in a total feature size per image of 384.
ViT Training : We adapted the SSL-ViT paradigm in [1] and followed the implementation in [3]. In the absence of labels, the ViT model objective is to derive embeddings similar to each other for different augmented versions of the same image. Several augmentations (cropping, intensity variations, horizontal flips and noise) were used to produce multiple versions of the same image. The cropping was limited to 70% of the total image size to avoid losing of semantic content from the images. The model was trained for 100 epochs. We trained two independent models on an entire pool of un-labelled knee and spine data mentioned above.
CBIR : Given an exemplar image, the trained model is used to derive representation for that exemplar. The nearest images in the train data pool to the exemplar image are identified as the ones which have closest representations to the exemplar image in the latent space (Fig. 1). A K-NN based matching is done using cosine similarity as the metric [1] and images are ranked (1st, 2nd etc.). We leveraged CBIR to retrieve a) anatomically relevant knee images (data pool = 24250 slices) and b) sagittal and coronal spine images containing metal, peculiar contrast, and scoliosis (data pool = 9300 slices).
Results
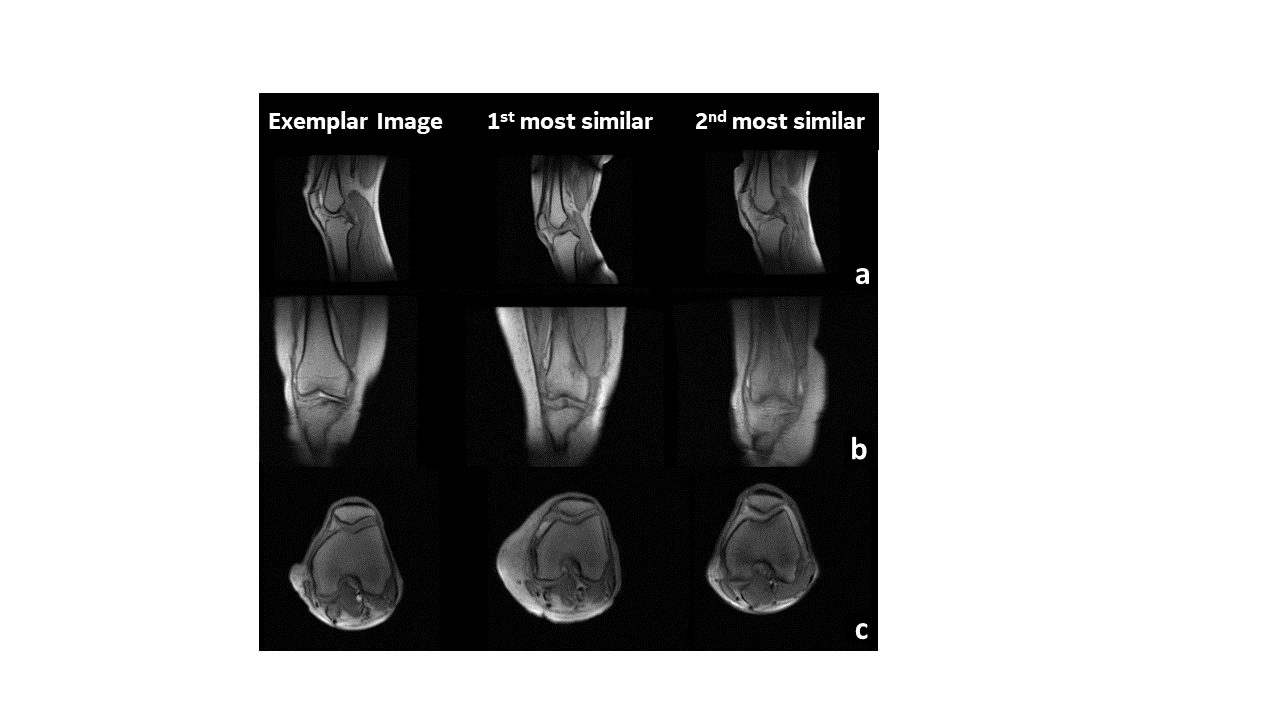
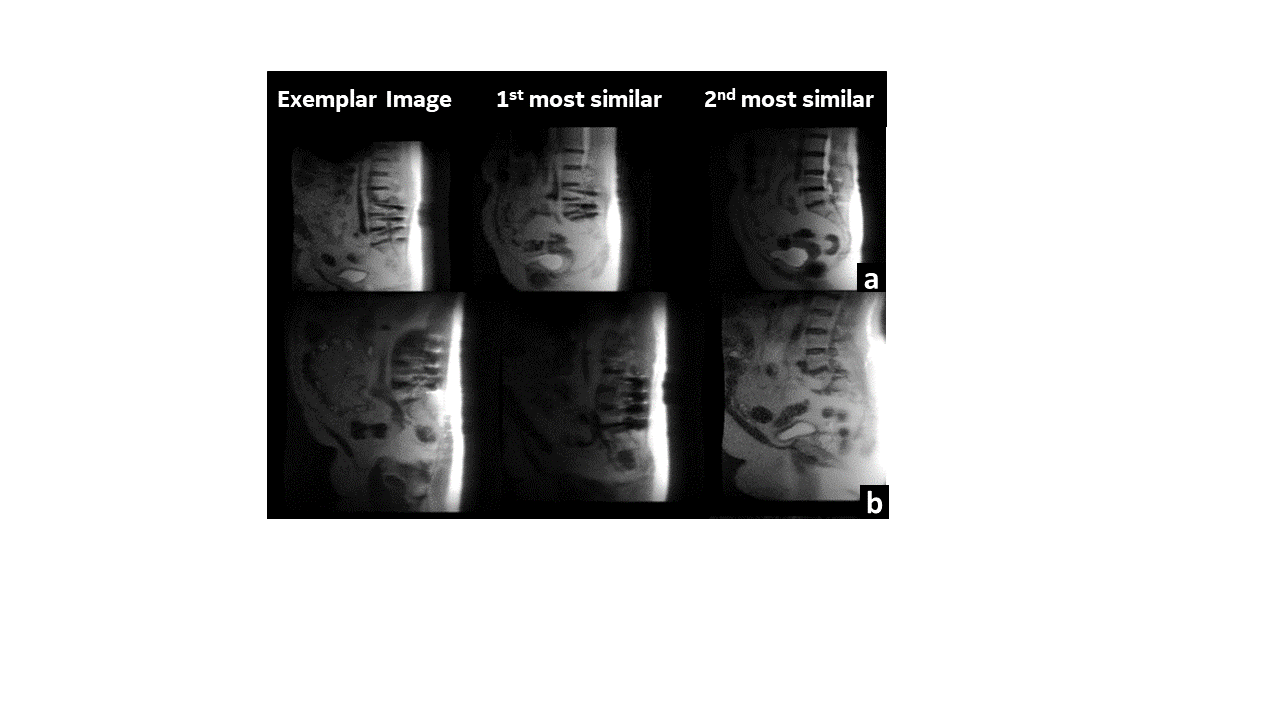
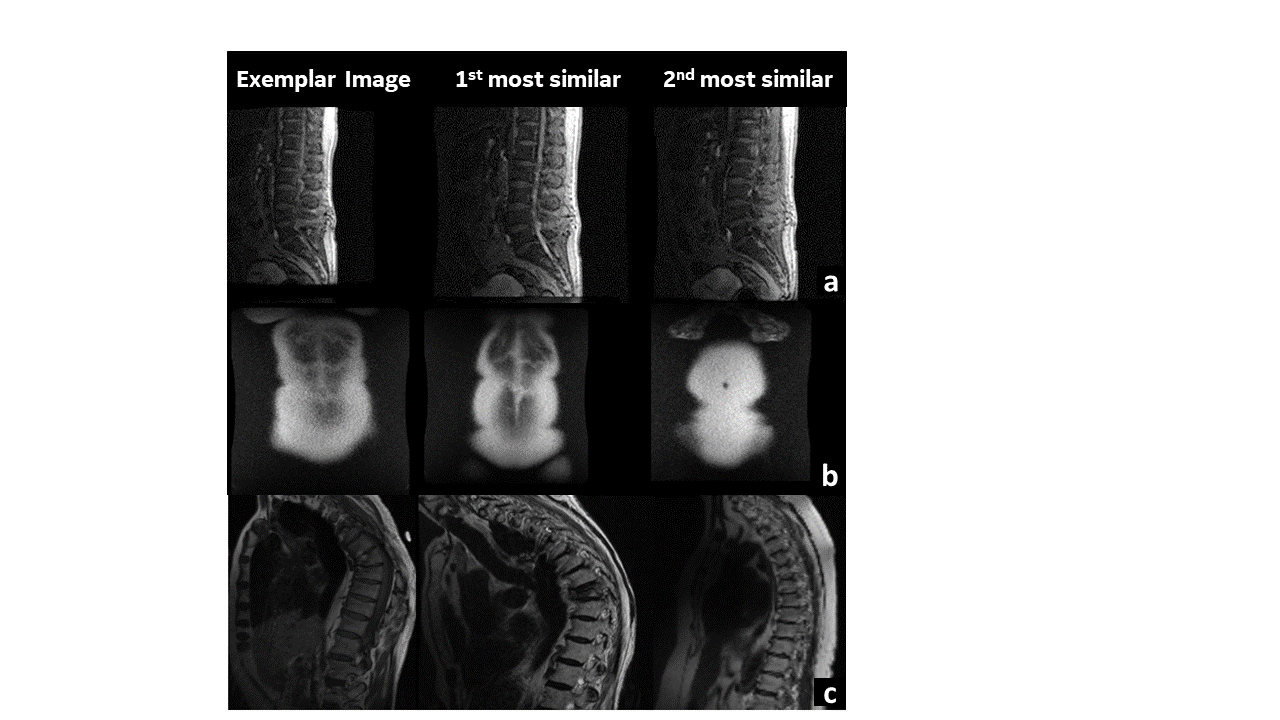
The richness of the feature representations from ViT are apparent in their ability to retrieve images matching the anatomy, contrast and artifacts present in the exemplar image with similar images from the existing data pool(Fig. 2, 3 and 4). For the knee MR images, we notice the ability of the image to not only retrieve similar images from matching orientation views, but also being able to match nuances such as the tapering tibia bone in Fig 2(b). Peculiarly in spine , we notice that the first matching images retrieved corresponding to the spine image containing metal artifact (Fig. 3a,b) not only contain metal but also seem to be of the same type of metal implant. In addition, patient conditions such as scoliosis (Fig.4c) and distal non-spine slice cases (4b) are accurately matched. However, we do notice the false positives which are not correlated with the cosine similarity metric used in KNN matching (e.g. 1st most similar and 3rd most is accurate, but 2nd most similar is a false positive). This suggests that there is scope for improvement to determine a better feature matching methodology and thereby ensure robustness in CBIR for MR images. Even accounting for false positives, the scheme has reduced the manual effort for sorting the data by ~ 50%.Conclusion and Discussion
Accurate content-based image retrieval for medical images lends itself to several useful applications in AI based data curation: especially in identifying rarely occurring patient conditions from a large pool of data using only a small set of exemplar images. Here we use state-of-the-art SSL technique on ViTs trained on knee and spine MRI data completely obliviating need for supervision, yet deriving feature-sets which capture different detailed aspects of the image. ViT based CBIR provide a nuanced image matching capability, leading to significant savings in tiresome manual effort for the same.Acknowledgements
No acknowledgement found.References
[1] Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P. and Joulin, A., 2021. Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294.
[2] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S. and Uszkoreit, J., 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
[3] https://github.com/facebookresearch/dino
Figures