4335
A residual-spatial feature based MR motion artifact detection model with better generalization1GE Healthcare, Beijing, China
Synopsis
Motion artifact in MRI images is the frequency existence in daily scanning and causes clinical distress. In this study, we proposed an automatic framework for MRI motion artifact detection using the residual features from neural network and spatial characteristics combination-based machine learning method, which can be applied to multiple body parts and sequences. High performance is achieved in validation with the accuracy of 97.6%. The comparison is performed with different representative methods and proving the effectiveness of the proposed architecture on limited dataset.
Introduction
MRI can provide various contrasts with flexible parameters, but the complex parameters and long scan times can cause imaging artifacts that degrading image quality. In particular, motion artifact is considered as one of the main problems of MRI acquisition which presents significant challenge for clinical diagnostic and analysis [1].The existence of motion artifact on MR images is usually discerned by experienced specialists and the observation process is laborious. A late Identification of insufficient image quality prone to delay diagnosis and analysis, even require an additional scanning. Thus, automatic motion detection method which identifying motion artifact on images as early as possible is very necessary. Although there are different methods for motion inspection automatically, these methods either require abundant data or only apply to specific anatomy [1,2,3].
In this study, we proposed a novel and automatic model for motion artifact identification using residual and spatial combination features-based machine learning method. A wide applicability of this motion artifact detection architecture has been proved on multiple body parts. In addition, we compared the proposed method with deep learning (DL)-based and traditional machine learning (ML)-based algorithms, validated the strength of the proposed method in model development with limited dataset.
Materials and Methods
The database contains 1,017 images in total, including 489 scanned MR images with motion artifact, 136 scanned MR images without motion artifact in high quality, and 350 additional simulated images generated from high-quality images by adding a varied degree of noise. The simulated image dataset is used as an augmentation to no motion artifact dataset. All original images were acquired on 1.5T MR scanner (GE Healthcare) with multiple sequences and contrasts. Examples of dataset are shown in Figure 1.The proposed architecture is depicted in Figure 2. The motion classifier is trained with the combination of features from a residual neural network and features extracted by traditional image statistics in spatial domain.
The residual neural network accepts input of MR images with and without motion artifact, containing convolutional layers and eight residual blocks with max-pooling layer. Followed by a fully connected layer to obtain the 16-dimensional residual feature vector V1.
Meanwhile, spatial features are extracted from each input images. The mean-subtracted contrast-normalized (MSCN) coefficients are calculated, and 5 Multi-Directional Filtered Coefficients (MDFC) maps are generated by Gaussian low-pass filtering MSCN with 5-directions gradient vectors [4,5]. Shape parameters of MDFC histograms, fitted with a generalized Gaussian distribution (GGD), are used as features. A total 20-dimensional spatial feature vector V2 is obtained with a two-scale decomposition.
Based on the concatenated V1 and V2 features, the Support Vector Machine (SVM) classifier is trained to learn its separating decision hyperplanes in high-dimensional space.
Training the architecture includes two stages. (i) The residual neural network is trained by Adam optimizer with training and testing ratio of 9:1, the model of minimized cross-entropy loss is selected after 150 epochs. (ii) A soft-margin SVM classifier is trained by 5-fold cross-validation with combined features for appropriate hyperparameters.
We compared the proposed algorithm with DL-based ResNet [6] method and traditional ML-based method using MDFC features only in SVM training. 2 DL models of different complexity were trained, ResNet-18 and ResNet-50. The validation performed on an additional dataset including 42 MRI images with balanced categories.
Results
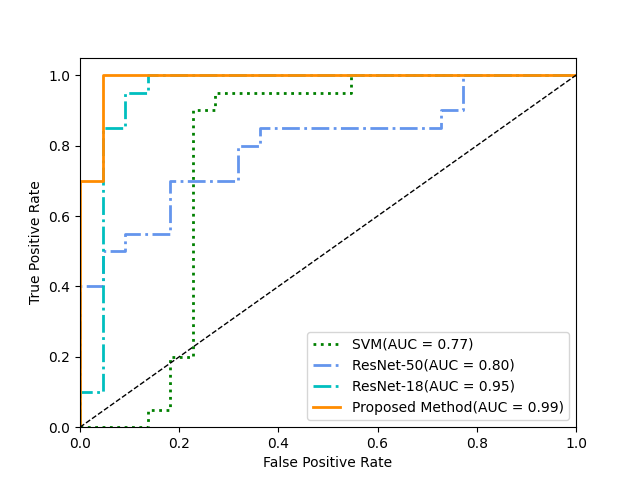
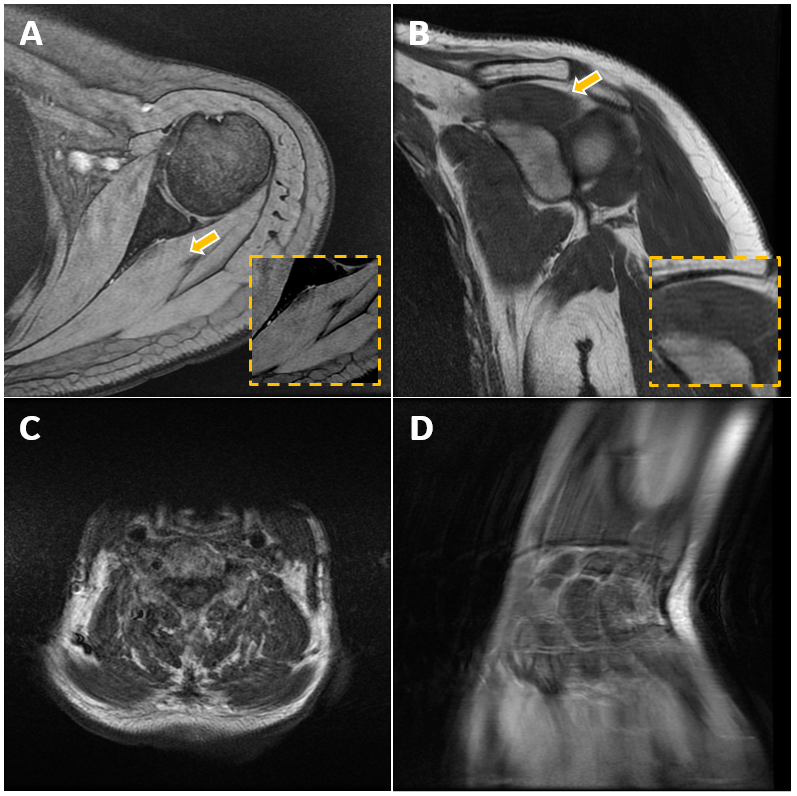
Figure 3 depicts the receiver operating characteristic (ROC) curves of the 4 methods (proposed, 2 DL-based, SVM-based), validated by an additional dataset. The Area Under Curve (AUC) is 0.99,0.95, 0.80 and 0.77, respectively. The proposed residual and spatial combination features-based architecture achieved classification accuracy of 97.6%, meanwhile the DL-based methods and SVM-based method have accuracy of 92.8%, 66.7% and 80.9%, respectively. Figure 4 shows examples from validation dataset that motion artifacts are detected by proposed method.Discussion
In this work, a residual and spatial combination features-based motion artifact detection method is proposed and images with severe motion or slight artifacts can be well recognized even under poor SNR situation. We compared our architecture with DL-based algorithm and traditional machine learning-based method, the proposed architecture performs best. The combined feature utilized multi-dimension features, including both the abstract information in high-dimensional space from residual features and the more concrete information from multi-directional filtering and image statistics, such as shapes, from spatial features.Although multiple previous researches proved DL-based method can achieve outstanding results, it usually requires deep model as well as numerous data. For example, a previous work developed VNetArt, trained with large-scale images and reached single anatomy classification accuracy of 98% [1]. The deep neural network has known limitation when learning from small dataset. The model with high complexity, such as ResNet-50, tends to be overfitted and get low accuracy in test dataset. The architecture proposed in this work overcomes the limitation of small dataset by introducing residual-spatial combined features.
Conclusion
Proposed residual and spatial features combination-based architecture for MRI motion artifacts detection achieved a classification accuracy of 97.6% and not restricted by body parts. The method is promising to assist expert distinguish insufficient quality images with motion artifact as soon as possible and contribute to clinical research. Furthermore, this framework provides possibility for model training with small data sets and can be easily extended to other artifacts degrading MRI image quality.Acknowledgements
No acknowledgement found.
References
[1] Küstner T, Jandt M, Liebgott A, et al. Motion artifact quantification and localization for whole-body MRI[C]//Proceedings of the International Society for Magnetic Resonance in Medicine (ISMRM). 2018.
[2] Mohebbian M R, Walia E, Habibullah M, et al. Classifying MRI motion severity using a stacked ensemble approach[J]. Magnetic Resonance Imaging, 2021, 75: 107-115.
[3] Fantini I, Rittner L, Yasuda C, et al. Automatic detection of motion artifacts on MRI using Deep CNN[C]//2018 International Workshop on Pattern Recognition in Neuroimaging (PRNI). IEEE, 2018: 1-4.
[4] Quality evaluation of no‐reference MR images using multidirectional filters and image statistics[J]. Magnetic Resonance in Medicine, 2018, 80(3).
[5] Mittal A, Moorthy AK, Bovik AC. No-reference image quality assessment in the spatial domain. IEEE Trans Image Process 2012; 21:4695–4708.
[6] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
Figures
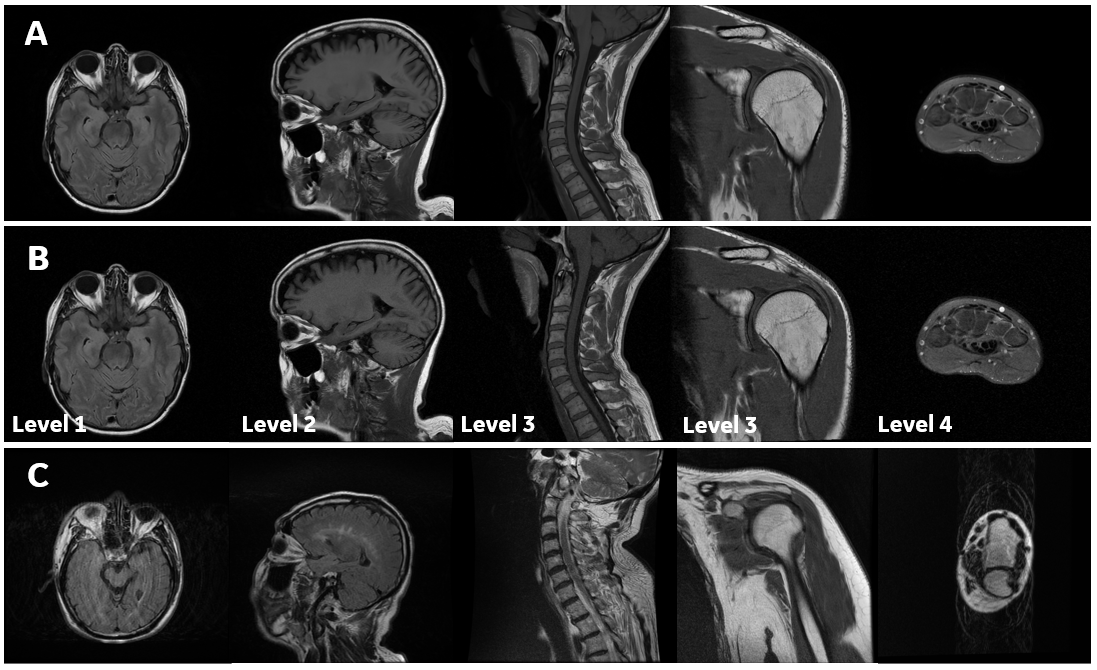
Figure 1. Examples of training sets. (A) Examples from 136 images without motion artifact in high quality acquired on GE MR with multiple sequences (e.g., FSE, SE, GRE, etc.) and different contrasts (T1w, T2w, PDw). (B) Examples from 350 images with varying degrees (Level 1-4: slight-severe) of noise are generated from high-quality images as an augmentation to no motion artifact dataset. (C) Examples from 489 images with motion artifact dataset. Motion artifacts from slight to severe can be found in the training set.
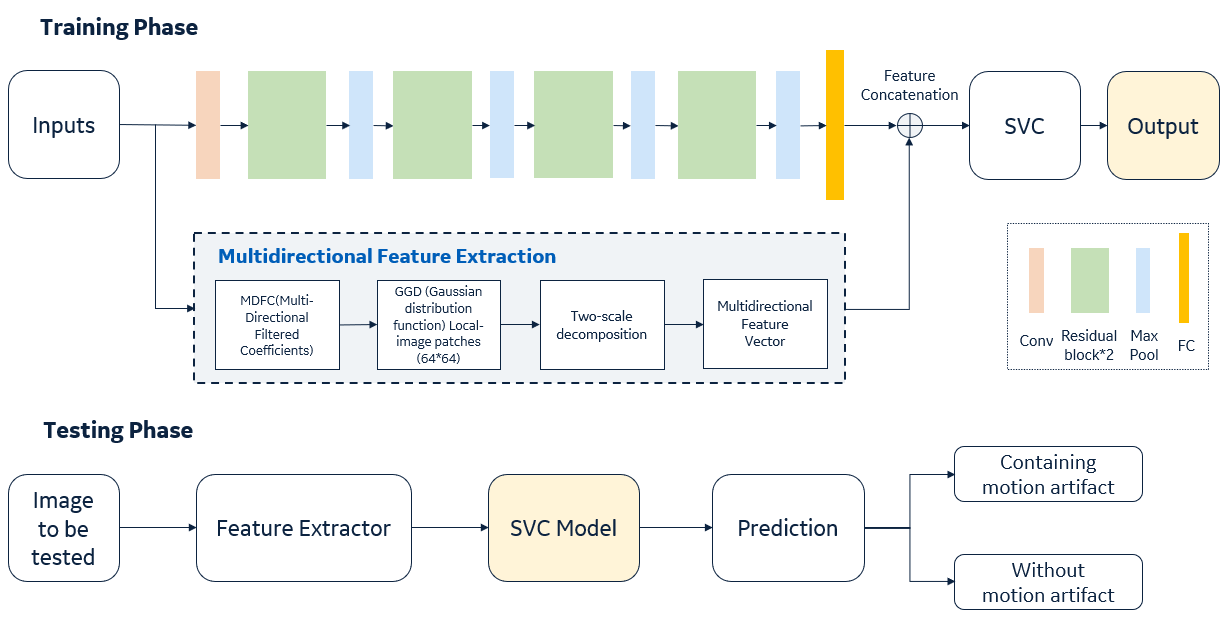
Figure 2. Workflow of the proposed architecture. In training phase, a SVM classifier is trained with the concatenation of features from a residual neural network and features extracted from traditional image statistics in spatial domain. During testing phase, features extracted from image to be tested, the SVC model predicts the probability of whether containing motion or not and the image with motion artifact can be distinguished properly.