4308
Arbitrary Missing Contrast Generation Using Multi-Contrast Generative Network with An Encoder Network1Electrical and Electronic Engineering, Yonsei university, Seoul, Korea, Republic of
Synopsis
Multi-contrast images acquired with magnetic resonance imaging (MRI) provide abundant diagnostic information. However, the applicability of multi-contrast MRI is often limited by slow acquisition speed and high scanning cost. To overcome this issue, we propose a contrast generation method for arbitrary missing contrast images. First, StyleGAN2-based multi-contrast generator is trained to generate paired multi-contrast images. Second, pSp-based encoder network is used to predict style vectors from input images. Consequently, the imputation for arbitrary missing contrast is achieved by the process of (1) embedding one or more kinds of contrast images and (2) forward-propagating the style vector to the multi-contrast generator.
Introduction
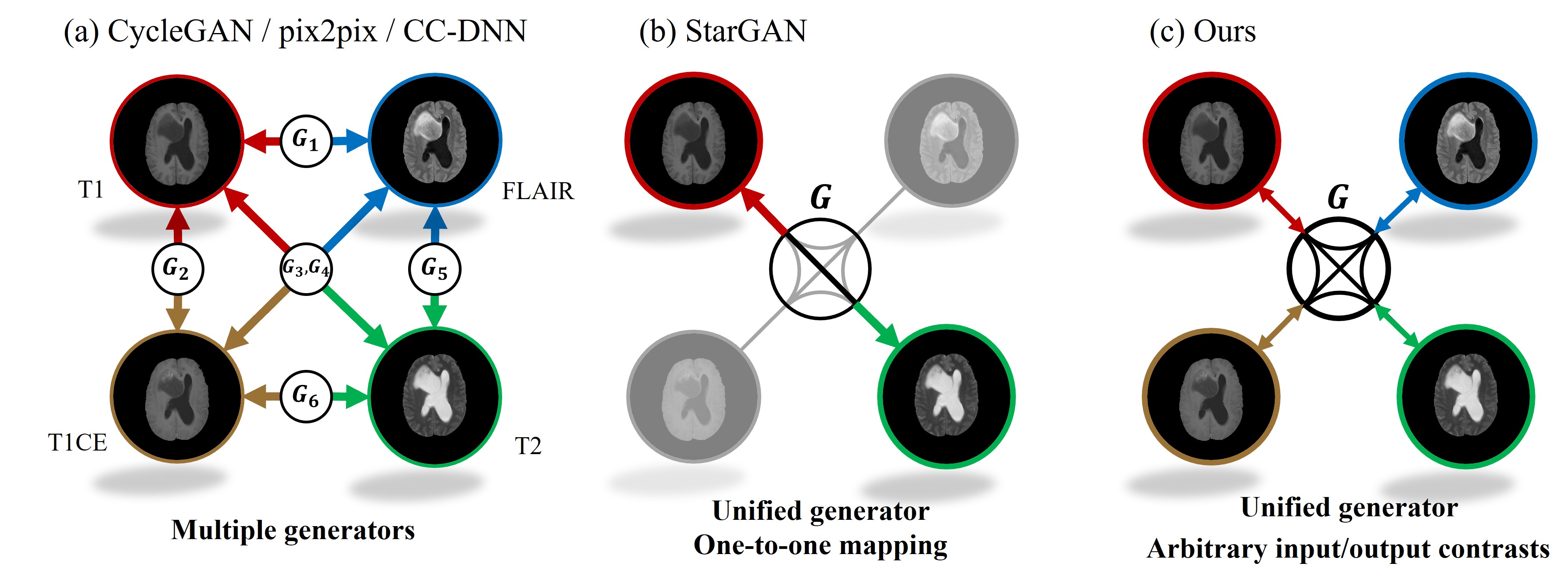
In magnetic resonance imaging (MRI), MR images with different contrasts such as T1, contrast-enhanced T1 (i.e., T1-CE), T2, or FLAIR provide useful diagnostic information which contains different tissue characteristics. However, it is difficult to acquire multi-contrast images in some clinical settings due to the reasons such as long scan time, patient discomfort, and motion-related artifacts. Moreover, MR contrasts preferred by institutions, vendors, or individual doctors are commonly different. So, it is often the case that some contrasts are absent. For this reason, there have been studies to impute missing contrast images and synthesize multi-contrast MR reconstruction. However, most of the previous methods focused on cases for which types of missing contrast are fixed and generate only single contrast from single or multiple contrasts. For this reason, existing methods cannot be applied if the types and the numbers of missing contrasts in the test set are varied. To overcome this issue, we propose a new method that can generate arbitrary missing contrast images in any case. The proposed method comprises with StyleGAN2-based multi-contrast generative adversarial network (GAN)1, 8-11 and a pSp-based encoder network3 for GAN inversion. In the experiments, we evaluated the effectiveness of our proposed method to predict the remaining missing contrast images when arbitrary contrasts are given from four contrasts (i.e., T1, T1ce, T2, and FLAIR). The imputation process and comparison with existing methods can be described as in Fig. 1.Method
Generation ModelA StyleGAN2-based multi-contrast generative model is exploited to learn the joint distribution among multi-contrast MR images. Our generator is built on the top of StyleGAN2, which generates output image of which size is 4x256x256(i.e., # of contrasts x image height x image width). By combining T1, T1-CE, T2, and FLAIR images into multichannel images, our model generates multi-contrast MR images simultaneously. As original StyleGAN2, our generator takes random vectors following a normal distribution as input. Through affine transformation, the random vectors are transformed to style vectors and are fed to the generator. All other settings including optimizers, losses, training settings, and other hyperparameters are kept unchanged except that horizontal flips are used as augmentations.
Encoder
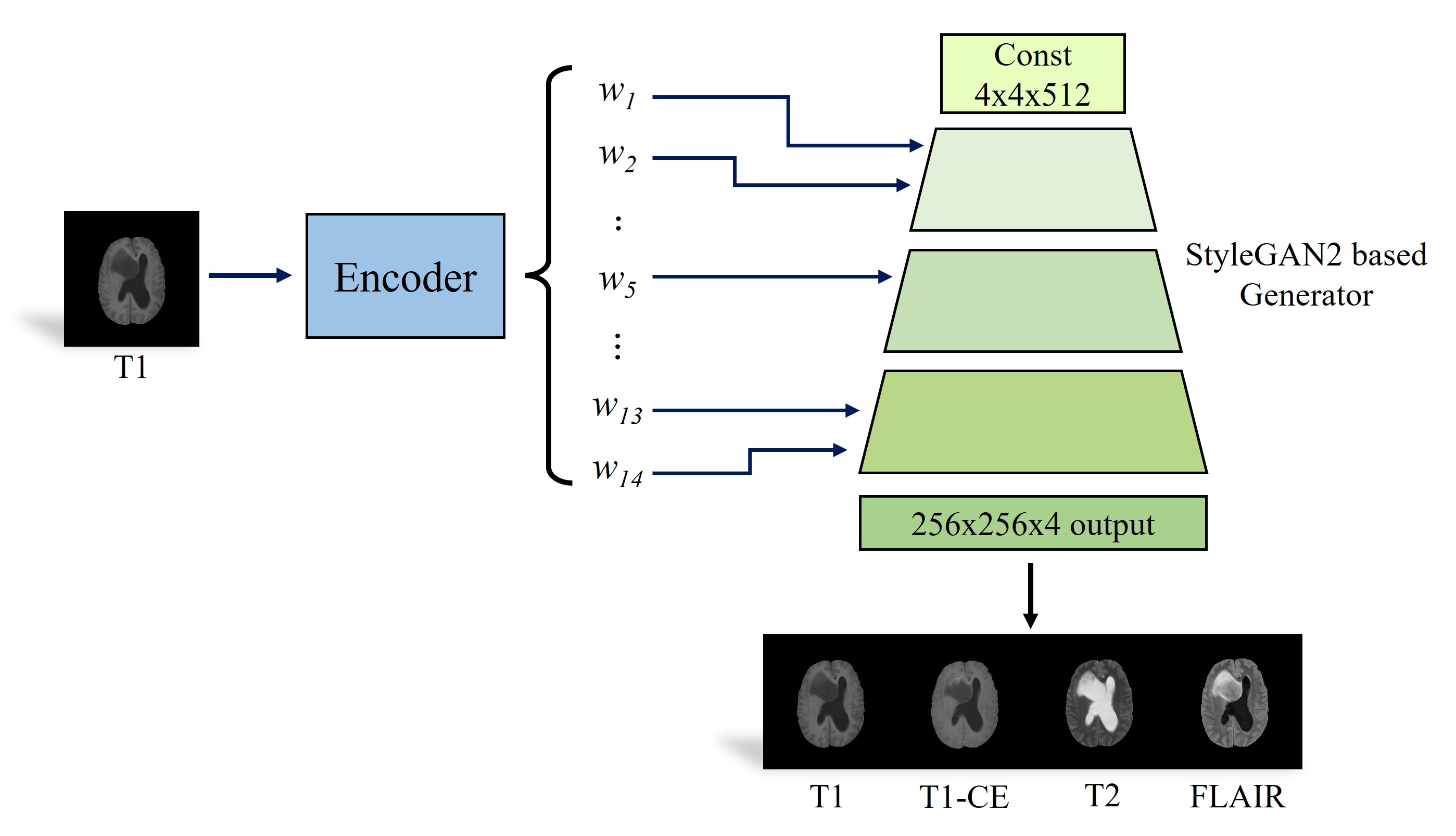
For GAN inversion, we need to infer input images’ embeddings which are fed into the generator. When the encoder is being trained, we freeze the generator. The process is presented in Fig. 2. The encoder is based on pSp networks and trained using a weighted combination of the below objectives. First, we utilize the pixel-wise L2 loss, $$$ \mathit{L}_{l2}(\mathbf{x})=\left \| \textbf{x}-{\textbf{x}}' \right \|_{2}$$$ and MS-SSIM loss, $$$\mathit{L}_{MS-SSIM}(\mathbf{x})=1-MSSSIM(\mathbf{x},{\mathbf{x}}')$$$. To learn perceptual similarities, we utilize the LPIPS loss, $$$\mathit{L}_{LPIPS}(\mathbf{x})=\left \| F(\textbf{x})-F({\textbf{x}}') \right \|_{2}$$$, where F is a AlexNet network trained with ImageNet. Moreover, motivated from self-supervised learning techniques to preserve image identity, we utilize identity loss defined by, $$$\mathit{L}_{ID}(\mathbf{x})=1-\left \langle C(\textbf{x}),C({\textbf{x}}') \right \rangle$$$, where C is a ResNet-506 network trained with MOCOv27. In summary, the total loss function is defined as $$L(\mathbf{x})=\mathit{\lambda}_{1}\mathit{L}_{l2}+\mathit{\lambda}_{2}\mathit{L}_{MS-SSIM}+\mathit{\lambda}_{3}\mathit{L}_{LPIPS}+\mathit{\lambda}_{4}\mathit{L}_{ID}.$$ The lamda values are set as $$$\mathit{\lambda}_{1}=1, \mathit{\lambda}_{2}=0.8, \mathit{\lambda}_{2}=0.1$$$, and $$$\mathit{\lambda}_{4}=1$$$. Whatever inputs are, the loss is calculated on all multi-contrast images. For training, we use the Ranger optimizer, a combination of Rectified Adam4 with the Lookahead technique5, with a constant learning rate of 0.001. Only horizontal flips are used as augmentations.
Inference
At inference time, our goal is to predict missing contrast images when one or more contrast images are given. For example, if the T1 image is given as input, our method imputes other missing contrasts (i.e., T1-CE, T2, and FLAIR). Therefore, we train our encoder again by self-supervised manner. Loss is calculated between input images and output images that belong to the same contrast. This is called optimization fitting model for a specific input.
Experiments
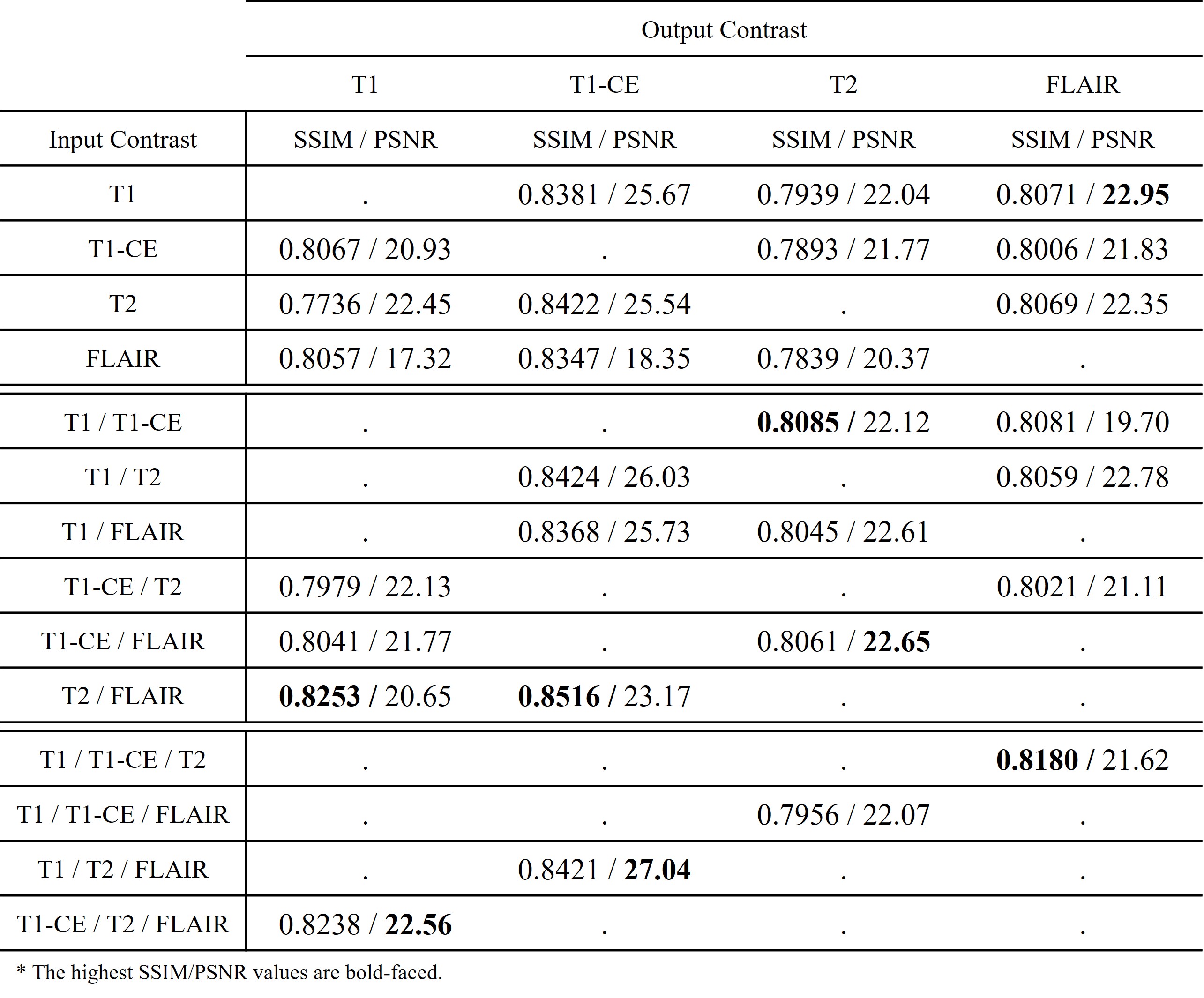
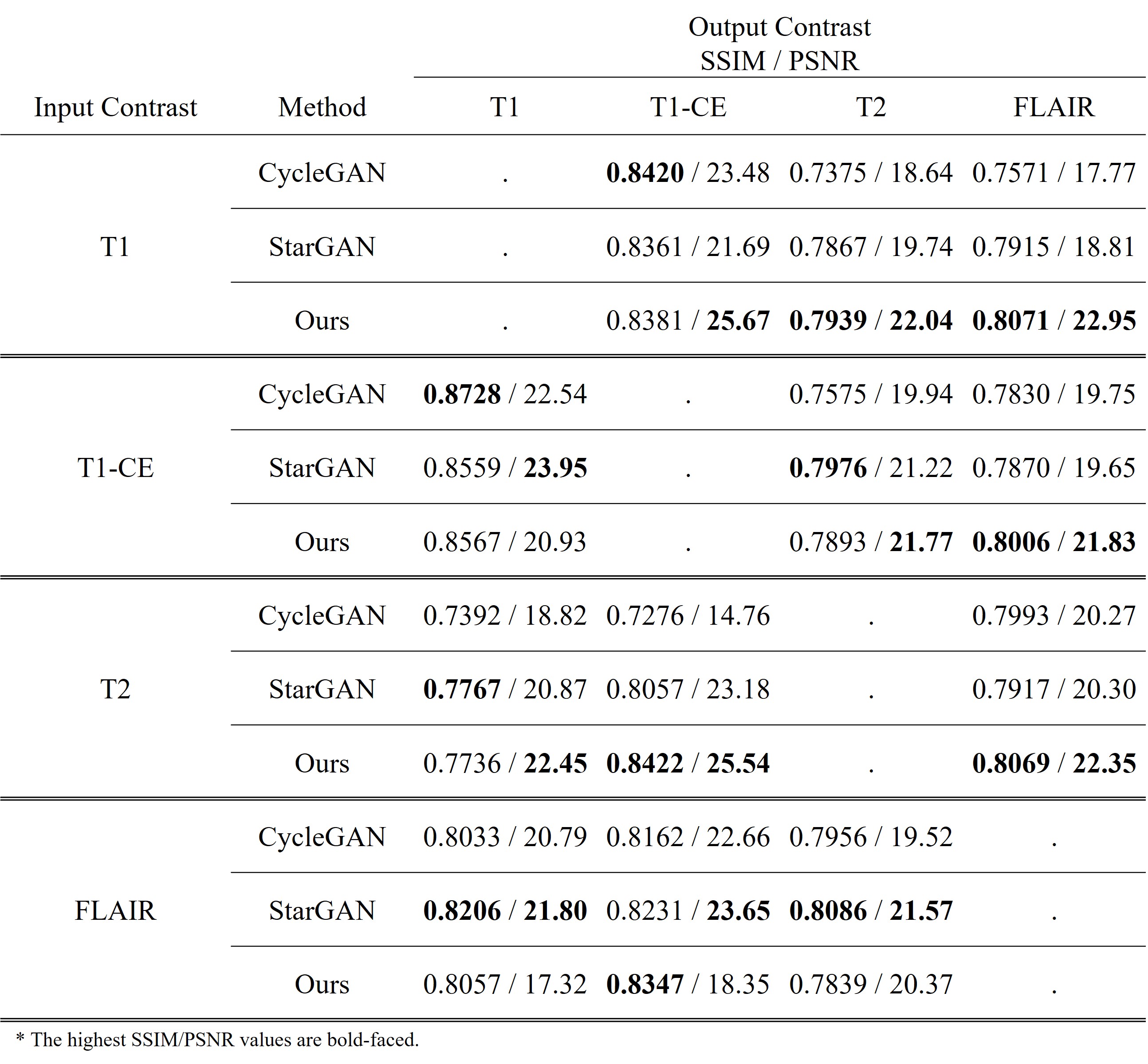
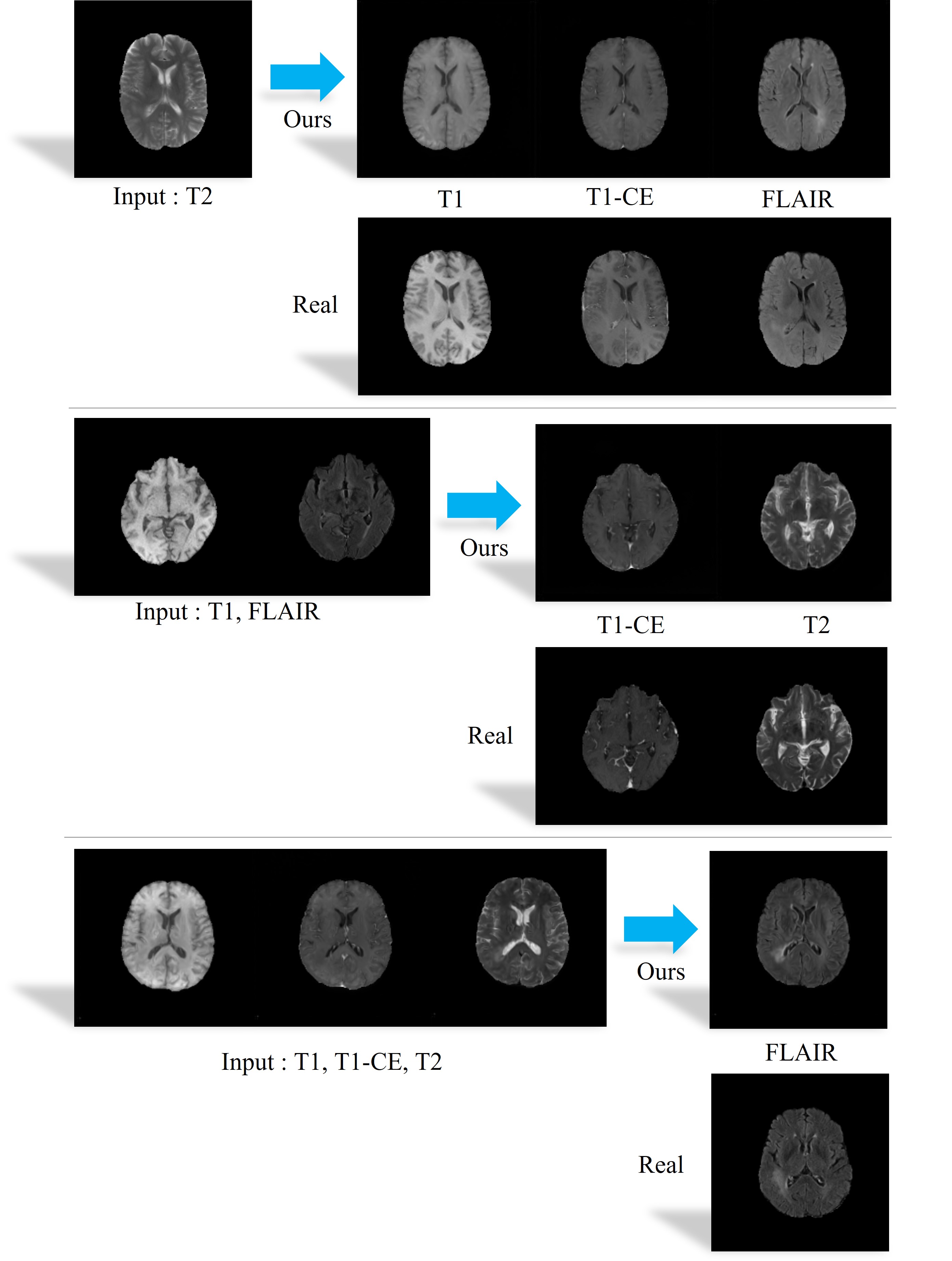
We used the BraTS1812-14 dataset and extract each slice to 2D images. Each slice consists of 4 types of contrast (T1, T1-CE, T2, and FLAIR). There are 210 patient datasets, and we use 90% (199 patients) for train and 10% for testing (21 patients). PSNR and SSIM were exploited for quantitative evaluation. The number of all possible input combinations is 14 for the given four contrasts, and our method predicts missing contrasts for all 14 cases without any additional training or fine tuning. As shown in Table 1, it shows the tendency that the imputation performance increases as the number of input images increase. Moreover, as shown in Table 2, the proposed method shows better performance than other methods. Consequently, the result suggests that the data distribution of different contrasts can be learned by our method as shown in Fig. 3.Conclusion
We propose a multi-contrast generative model with an inversion method based on SyleGAN2 and pSp encoder to impute missing contrast images when the input contrasts are arbitrary. Our proposed generative model can generate multi-contrast images that are missing in any case without any additional training or fine tuning.Acknowledgements
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Science and ICT, (2019R1A2B5B01070488, 2021R1A4A1031437 and 2021R1C1C2008773), and Y-BASE R&E Institute a Brain Korea 21, Yonsei University.References
1. ISOLA, Phillip, et al. Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. p. 1125-1134.
2. KARRAS, Tero, et al. Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. p. 8110-8119.
3. RICHARDSON, Elad, et al. Encoding in style: a stylegan encoder for image-to-image translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. p. 2287-2296.
4. Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han. On the variance of the adaptive learning rate and beyond. arXiv preprint arXiv:1908.03265, 2019.
5. Michael Zhang, James Lucas, Jimmy Ba, and Geoffrey E Hinton. Lookahead optimizer: k steps forward, 1 step back. In Advances in Neural Information Processing Systems, pages 9597–9608, 2019.
6. HE, Kaiming, et al. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. p. 770-778.
7. CHEN, Xinlei, et al. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
8. ZHU, Jun-Yan, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE international conference on computer vision. 2017. p. 2223-2232.
9. KIM, Sewon, et al. Deep‐learned short tau inversion recovery imaging using multi‐contrast MR images. Magnetic Resonance in Medicine, 2020, 84.6: 2994-3008.
10. CHOI, Yunjey, et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. p. 8789-8797.
11. LEE, Dongwook, et al. CollaGAN: Collaborative GAN for missing image data imputation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019. p. 2487-2496.
12. MENZE, Bjoern H., et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE transactions on medical imaging, 2014, 34.10: 1993-2024.
13. BAKAS, Spyridon, et al. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Scientific data, 2017, 4.1: 1-13.
14. BAKAS, Spyridon, et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv preprint arXiv:1811.02629, 2018.
Figures