4301
Memory-friendly and Robust Deep Learning Architecture for Accelerated MRI1Department of Electronic Science, Biomedical Intelligent Cloud R&D Center, Fujian Provincial Key Laboratory of Plasma and Magnetic Resonance, National Institute for Data Science in Health and Medicine, Xiamen University, Xiamen, China, 2School of Computer and Information Engineering, Xiamen University of Technology, Xiamen, China, 3United Imaging Research Institute of Intelligent Imaging, Beijing, China, 4Department of Nuclear Medicine, Nanjing First Hospital, Nanjing Medical University, Nanjing, China
Synopsis
Deep learning has shown astonishing performance in accelerated MRI. Most methods adopt the convolutional neural network and perform 2D convolution since many MR images or their corresponding k-space are in 2D. In this work, we try a different approach that explores the memory-friendly 1D convolution, making the deep network easier to be trained and generalized. Furthermore, a one-dimensional deep learning architecture (ODL) is proposed for MRI reconstruction. Results demonstrate that, the proposed ODL provides improved reconstructions than state-of-the-art methods and shows nice robustness to some mismatches between the training and test data.
Purpose
MRI plays an indispensable role in modern medical diagnosis[1]. Parallel imaging and sparse sampling are employed to shorten the scan time[2, 3], and image reconstruction is required. Recently, deep learning has shown astonishing potential with the powerful deep convolutional neural network (CNN)[4-7], but it is still limited by the lack of training subjects and robustness. As MR images or k-space are usually in 2D, most previous deep learning methods adopt 2D convolution. Here, we argue that there exists another effective scheme without considering spatial location information during the analysis, i.e., 1D CNN, which may address mentioned limitations. In this work, for the MRI reconstruction under the commonly used 1D phase encoding (PE) undersampling[2-3, 8-9], we propose a 1D learning scheme, and a memory-friendly deep learning architecture with nice robustness.Method
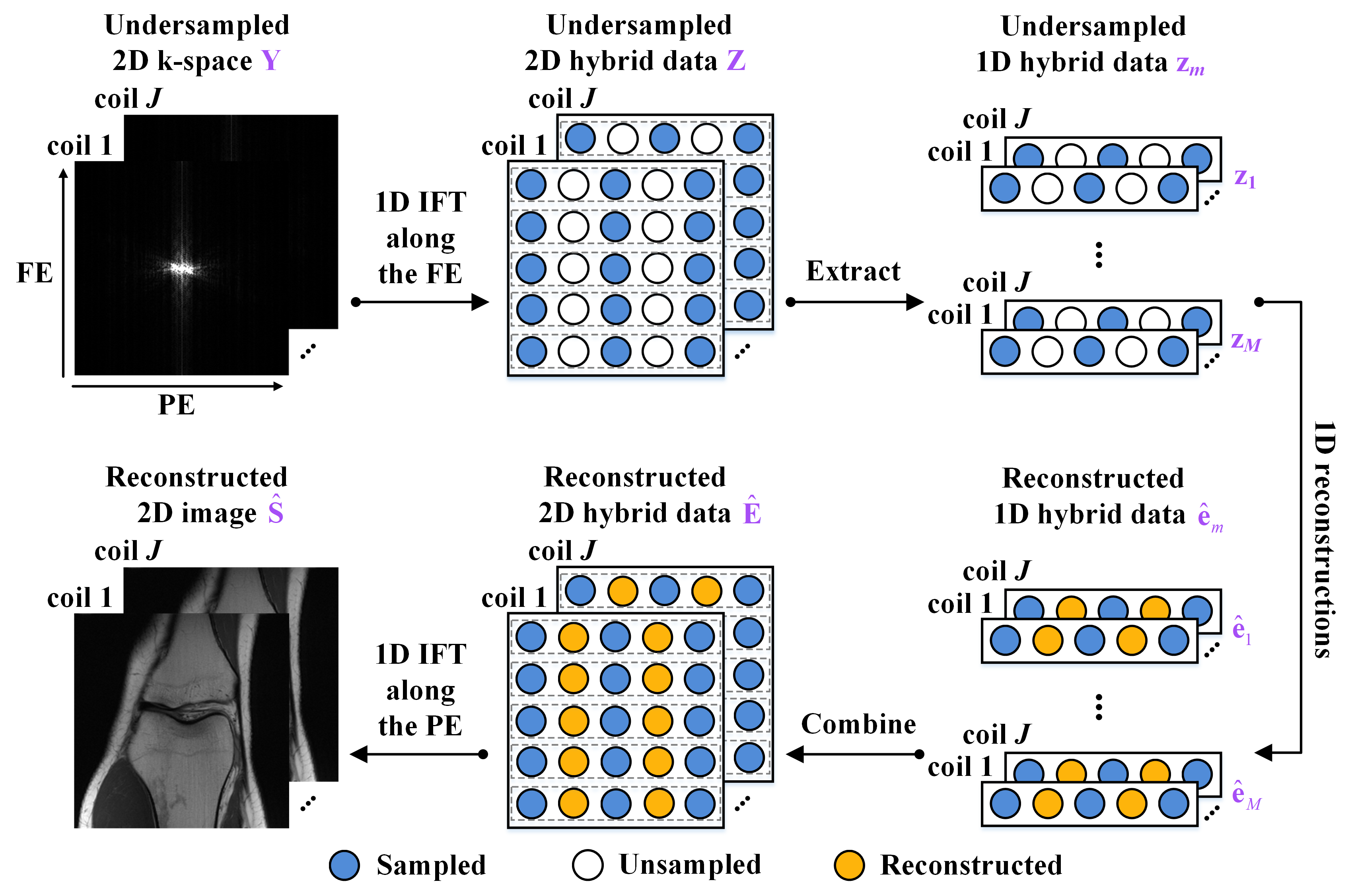
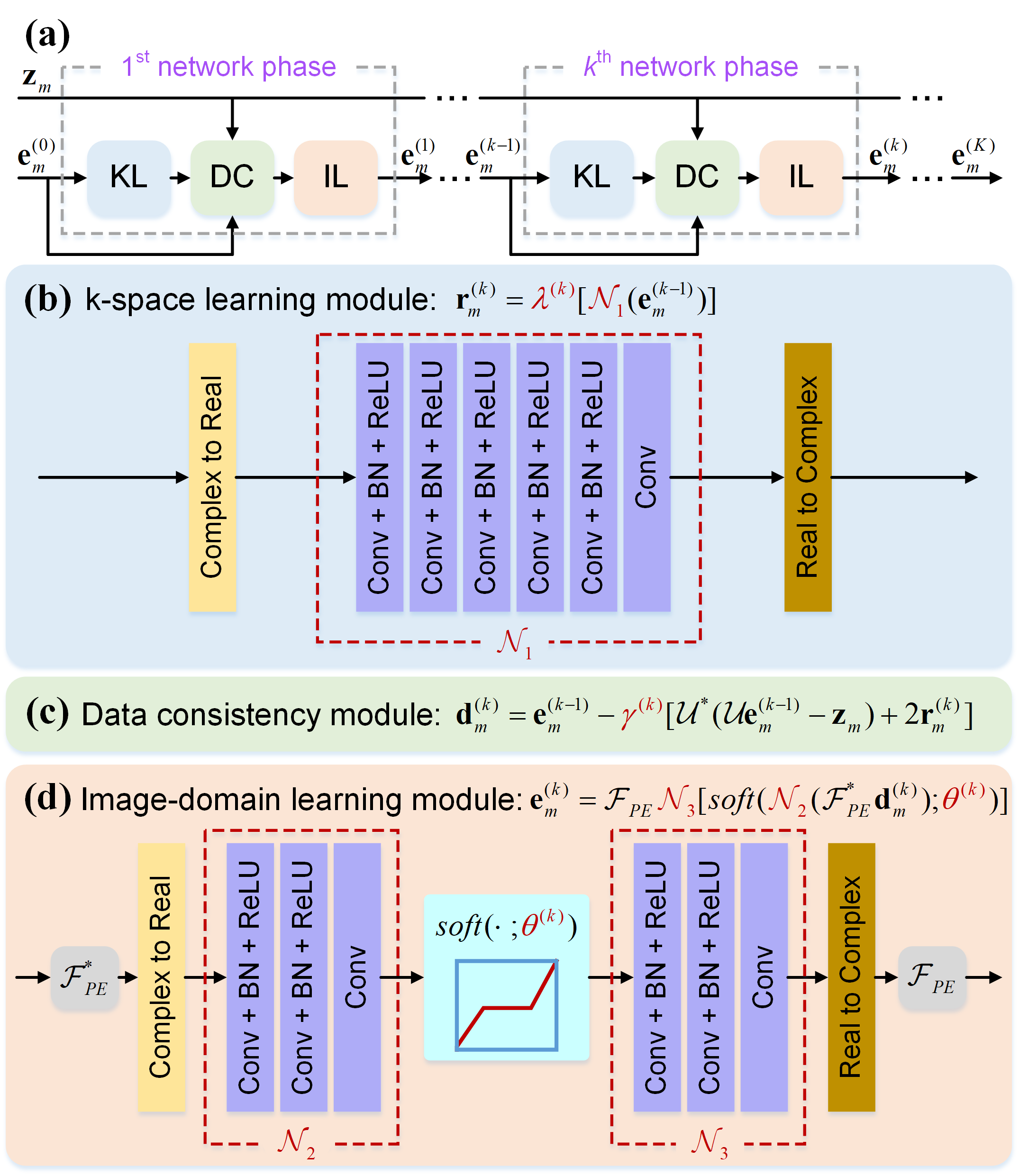
In the 1D PE undersampling, the k-space is fully- or non-sampled along the frequency encoding (FE). Thus, taking the 1D inverse Fourier transform (IFT) of the undersampled k-space along the FE can decouple the 2D k-space into $$$m$$$ independent 1D hybrid signals[10, 11], where $$$m (m=1,...,M)$$$ is the length of the FE direction. Decoupling allows us to reduce the dimension of reconstructed target signals from 2D to 1D, making the network training easier. Meanwhile, given the same number of available training subjects, decoupling provides abundant 1D hybrid signals as training samples, leading to the data augmentation of more than two orders of magnitude. Therefore, we propose a 1D learning scheme to promote better network training and generalization. Figure 1 shows the flowchart of the 1D reconstructions from the 1D PE undersampled k-space $$$\mathbf{z}_{m}$$$.Furthermore, we propose a One-dimensional Deep Learning architecture (ODL). Its unrolled reconstruction incorporates both k-space and image-domain priors. As shown in Figure 2, the $$$k^{th}(k=1,...,K)$$$ network phase is designed as
$$(k-space\ learning\ module):\ \mathbf{r}_{m}^{(k)}=\lambda^{(k)}[{{\mathcal{N}}_{1}}(\mathbf{e}_{m}^{(k-1)})],\ \tag {1}$$
$$(Data\ consistency\ module):\ \mathbf{d}_{m}^{(k)}=\mathbf{e}_{m}^{(k-1)}-{{\gamma }^{(k)}}[{{\mathcal{U}}^{\text{*}}}(\mathcal{U}\mathbf{e}_{m}^{(k-1)}-{{\mathbf{z}}_{m}})+2\mathbf{r}_{m}^{(k)}],\ \tag {2}$$
$$(Image-domain\ learning\ module):\ \mathbf{e}_{m}^{(k)}={{\mathcal{F}}_{PE}}{{\mathcal{N}}_{3}}[soft({{\mathcal{N}}_{2}}(\mathcal{F}_{PE}^{\text{*}}\mathbf{d}_{m}^{(k)});{{\theta }^{(k)}})],\ \tag {3}$$
where $$$e_{m}$$$ is the 1D hybrid data to be reconstructed, $$$\mathcal{U}$$$ is the undersampling operator with zero-filling, $$$\mathcal{F}_{PE}$$$ is the 1D FT along the PE, the superscript $$$*$$$ represents the inverse operation. $$${\lambda }^{(k)}$$$ and $$${\gamma }^{(k)}$$$ are learnable network parameters initialized to 0.001 and 1, respectively. $$${\mathcal{N}}_{1}$$$, $$${\mathcal{N}}_{2}$$$, and $$${\mathcal{N}}_{3}$$$ are multi-layer 1D CNNs, whose number of layers are 6, 3, and 3, respectively. Each convolutional layer contains 48 1D convolution filers of size 3, followed by the batch normalization[12] and ReLU. $$$soft(x;\rho )=\max \left\{ \left| x \right|-\rho \right\}\cdot {x}/{\left| x \right|}\;$$$ is the element-wise soft-thresholding, $$${\theta }^{(k)}$$$ is the learnable threshold initialized to 0.001. When $$$k=1$$$, the initialized network input $$$\mathbf{e}_{m}^{(0)}={{\mathsf{\mathcal{U}}}^{\text{*}}}{{\mathbf{z}}_{m}}$$$ is the zero-filled 1D hybrid data with strong artifacts. The overall number of network phase in our implementation is 10, i.e. $$$K=10$$$. We employ the proposed 1D learning scheme to train our network by minimizing the loss function (mean square error).
In the reconstruction stage, the 1D IFT along the FE is first performed on the undersampled k-space to obtain $$$\mathbf{Z}=\mathsf{\mathcal{F}}_{FE}^{\text{*}}\mathbf{Y}$$$, all rows of $$$\mathbf{Z}$$$ form a batch that is then reconstructed in parallel and stitched back together to yield the reconstructed hybrid data $$$\mathbf{\hat{E}}$$$. After performing the 1D IFT along the PE, we can obtain the final reconstructed image $$$\mathbf{\hat{S}}=\mathsf{\mathcal{F}}_{PE}^{\text{*}}\mathbf{\hat{E}}$$$, as shown in Figure 1.
Results
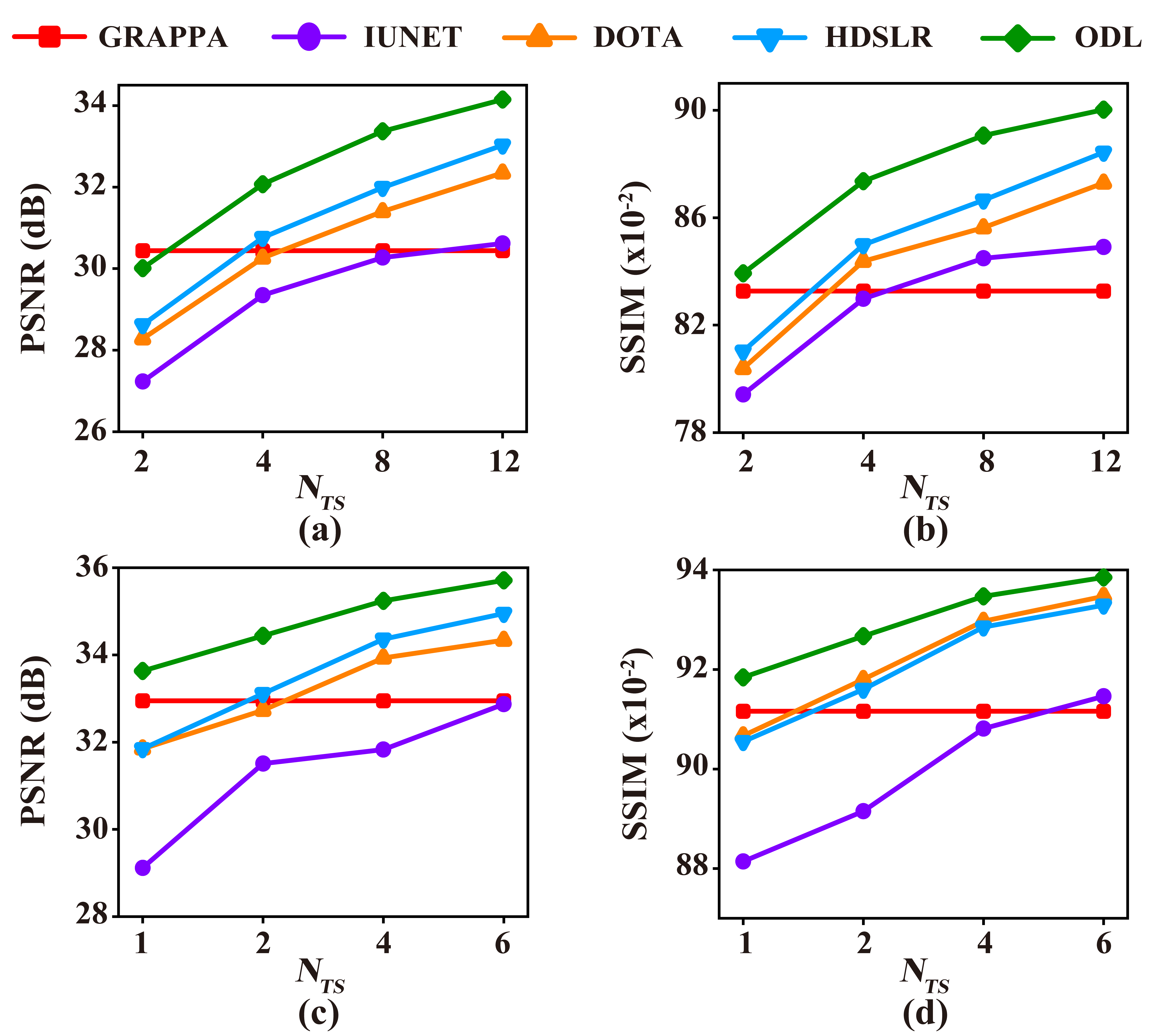
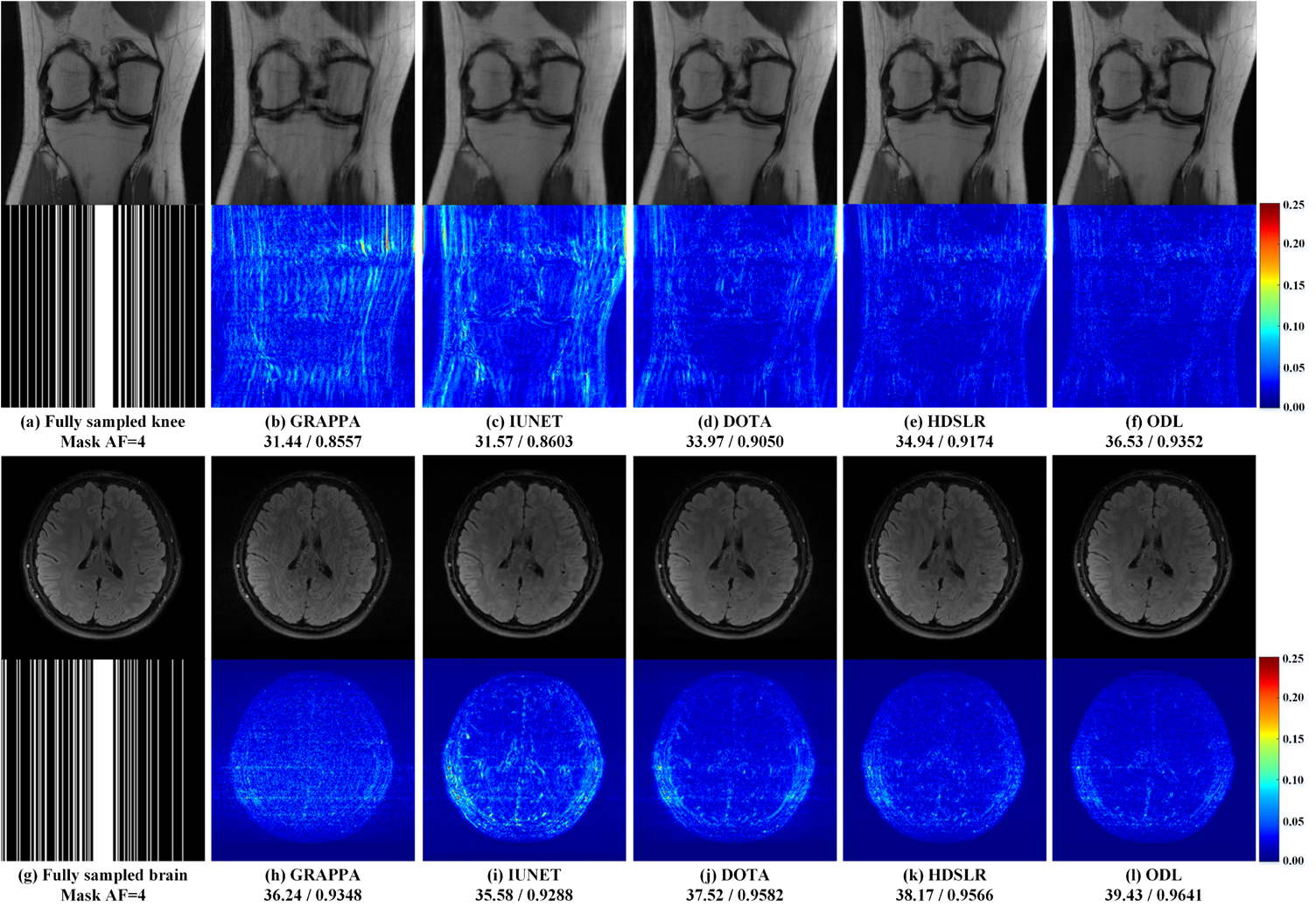
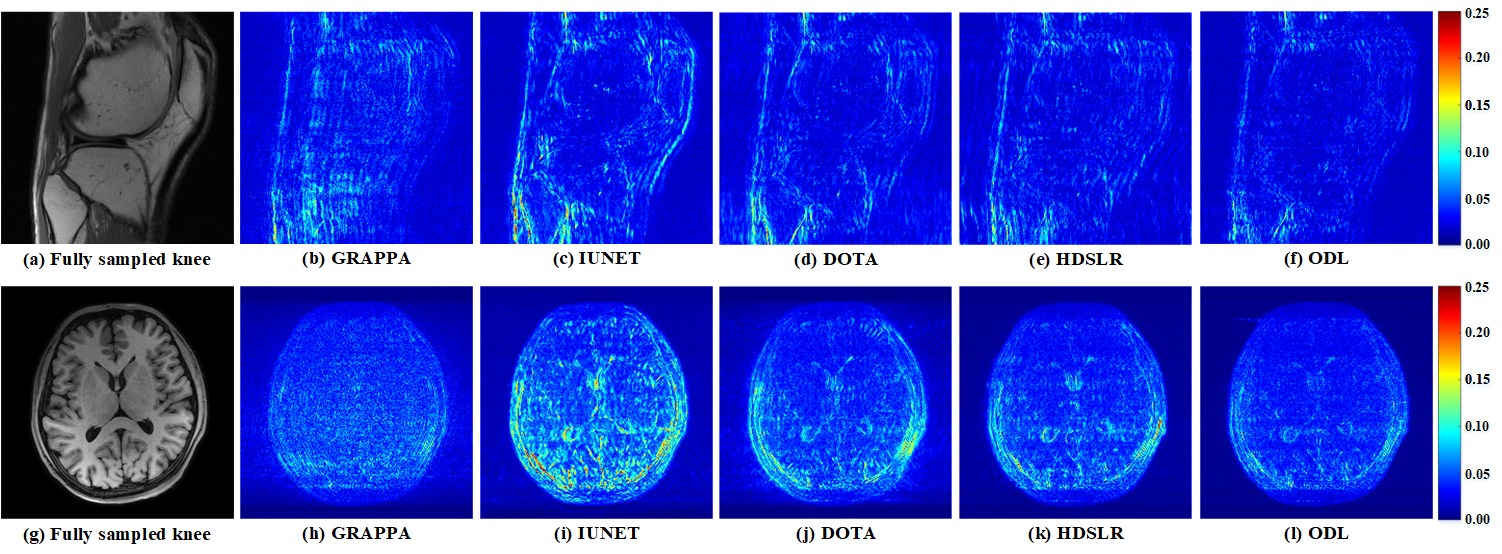
The knee[13] and brain (United Imaging collected) datasets are used in our experiments. The proposed ODL is compared with the state-of-the-art 2D CNN-based methods including IUNET[4], HDSLR[5], and DOTA[6]. GRAPPA[14] is used as the reconstruction baseline. To quantitatively evaluate the reconstruction performance, peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM)[15] are utilized. The higher PSNR and SSIM indicate less image distortions and better detail preservation in reconstructions, respectively.(i) Matched reconstruction: Figures 3 demonstrates that, for any number of training subjects NTS, the proposed ODL consistently outperforms other CNN-based methods in terms of PSNR and SSIM. Notably, the proposed ODL can already provide better reconstructions than the baseline GRAPPA when training subjects are very limited (NTS=2 or 1). These results imply that, the proposed method is suitable for the case of limited training subjects. Representative images in Figure 4 show that, ODL outperforms other methods both visually and quantitatively in two datasets, indicating the excellent ability of the artifact suppression and detail preservation.
(ii) Mismatched reconstruction: Mismatched reconstruction refers to utilizing a trained network to reconstruct test datasets which are different from the acquisition specification of training datasets. Here, we focus on the mismatch of the knee plane orientation (Train/reconstruct: Coronal/sagittal) and brain contrast weighting (Train/reconstruct: T2w/T1w). Figure 5 shows that, the proposed ODL not only outperforms other deep learning methods, but also is the only one with lower reconstruction errors than the baseline GRAPPA, indicating the nice robustness to some mismatches between the training and test data.
(iii) By virtue of 1D CNN, the proposed ODL has few trainable parameters (664350), about 3% of IUNET, 2% of DOTA, and 26% of HDSLR, thus it is memory-friendly.
Conclusion
We believe that the success of the 1D learning scheme and memory-friendly 1D deep learning architecture with nice robustness in fast MRI is of great significance for clinical applications, since the available training subjects and the machine memory are relatively limited.Acknowledgements
See more details in the full-length paper: https://csrc.xmu.edu.cn/. This work was supported in part by the National Natural Science Foundation of China under grants 62122064, 61971361, 61871341, and 61811530021, the National Key R&D Program of China under grant 2017YFC0108703, and the Xiamen University Nanqiang Outstanding Talents Program. The authors thank Xinlin Zhang and Jian Wu for assisting in data processing and helpful discussions. The authors thank Weiping He, Shaorong Fang, and Tianfu Wu from Information and Network Center of Xiamen University for the help with the GPU computing. The authors also thank Drs. Michael Lustig, Jong Chul Ye, Taejoon Eo, and Mathews Jacob for sharing their codes online.
The correspondence should be sent to Prof. Xiaobo Qu (Email: quxiaobo@xmu.edu.cn)
References
[1] G. Harisinghani Mukesh, A. O’Shea, and R. Weissleder, "Advances in clinical MRI technology," Science Translational Medicine, vol. 11, no. 523, p. eaba2591, 2019.
[2] M. Lustig, D. Donoho, and J. M. Pauly, "Sparse MRI: The application of compressed sensing for rapid MR imaging," Magnetic Resonance in Medicine, vol. 58, no. 6, pp. 1182-1195, 2007.
[3] F. Knoll et al., "Deep-learning methods for parallel magnetic resonance imaging reconstruction: A survey of the current approaches, trends, and issues," IEEE Signal Processing Magazine, vol. 37, no. 1, pp. 128-140, 2020.
[4] J. C. Ye, Y. Han, and E. Cha, "Deep convolutional framelets: A general deep learning framework for inverse problems," SIAM Journal on Imaging Sciences, vol. 11, no. 2, pp. 991-1048, 2018.
[5] A. Pramanik, H. Aggarwal, and M. Jacob, "Deep generalization of structured low-rank algorithms (Deep-SLR)," IEEE Transactions on Medical Imaging, vol. 39, no. 12, pp. 4186-4197, 2020.
[6] T. Eo, H. Shin, Y. Jun, T. Kim, and D. Hwang, "Accelerating Cartesian MRI by domain-transform manifold learning in phase-encoding direction," Medical Image Analysis, vol. 63, p. 101689, 2020.
[7] T. Lu et al., "pFISTA-SENSE-ResNet for parallel MRI reconstruction," Journal of Magnetic Resonance, vol. 318, p. 106790, 2020.
[8] D. C. Noll, D. G. Nishimura, and A. Macovski, "Homodyne detection in magnetic resonance imaging," IEEE Transactions on Medical Imaging, vol. 10, no. 2, pp. 154-163, 1991.
[9] K. P. Pruessmann, M. Weiger, M. B. Scheidegger, and P. Boesiger, "SENSE: Sensitivity encoding for fast MRI," Magnetic Resonance in Medicine, vol. 42, no. 5, pp. 952-962, 1999.
[10] Y. Yang, F. Liu, Z. Jin, and S. Crozier, "Aliasing artefact suppression in compressed sensing MRI for random phase-encode undersampling," IEEE Transactions on Biomedical Engineering, vol. 62, no. 9, pp. 2215-2223, 2015.
[11] X. Zhang et al., "Accelerated MRI reconstruction with separable and enhanced low-rank Hankel regularization," arXiv: 2107.11650, 2021.
[12] S. Ioffe and C. Szegedy, "Batch normalization: Accelerating deep network training by reducing internal covariate shift," arXiv: 1502.03167, 2015.
[13] K. Hammernik et al., "Learning a variational network for reconstruction of accelerated MRI data," Magnetic Resonance in Medicine, vol. 79, no. 6, pp. 3055-3071, 2018.
[14] M. A. Griswold et al., "Generalized autocalibrating partially parallel acquisitions (GRAPPA)," Magnetic Resonance in Medicine, vol. 47, no. 6, pp. 1202-1210, 2002.
[15] W. Zhou, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, "Image quality assessment: from error visibility to structural similarity," IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600-612, 2004.
Figures