3914
Learning to segment with limited annotations: Self-supervised pretraining with Regression and Contrastive loss in MRI1Department of Electrical and Computer Engineering, University of Arizona, Tucson, AZ, United States, 2Department of Medical Imaging, University of Arizona, Tucson, AZ, United States, 3Department of Radiology, Houston Methodist Hospital, Houston, TX, United States, 4Department of Biomedical Engineering, University of Arizona, Tucson, AZ, United States, 5Program in Applied Mathematics, University of Arizona, Tucson, AZ, United States
Synopsis
The availability of large unlabeled datasets compared to labeled ones motivate the use of self-supervised pretraining to initialize deep learning models for subsequent segmentation tasks. We consider two pre-training approaches for driving a CNN to learn different representations using: a) a reconstruction loss that exploits spatial dependencies and b) a contrastive loss that exploits semantic similarity. The techniques are evaluated in two MR segmentation applications: a) liver and b) prostate segmentation in T2-weighted images. We observed that CNNs pretrained using self-supervision can be finetuned for comparable performance with fewer labeled datasets.
Motivation: Self-supervised Learning
Supervised deep-learning (DL) models, trained on large labeled datasets, have shown state-of-the-art performance in several medical image segmentation tasks1. However, obtaining manual annotations for supervised training of convolutional neural networks (CNNs) can be labor-intensive, requiring countless expert hours. Although obtaining large annotated datasets can be challenging in MR imaging applications, the availability of large unlabeled datasets motivates the use of self-supervised learning (SSL) techniques that have shown promising results in image segmentation tasks without the need for extensive labeling2,3. By learning representations, driven by the choice of an appropriate loss function, SSL can provide a suitable initialization for the data-hungry DL models. These learned representations can be used subsequently for a variety of tasks including image segmentation with few labeled data. In this work, we explore two different SSL approaches for driving a CNN to learn different representations: a) an image reconstruction loss (regression task) to exploit spatial context in images and b) a contrastive loss to exploit semantic similarity in images. The pretraining techniques are evaluated in two different MR applications: a) liver segmentation in T2-weighted radial fast spin echo images and b) prostate segmentation in T2-weighted images of the prostate. We perform experiments to evaluate the performance of the techniques under limited labeled data conditions in comparison to a supervised baseline trained on all available labeled data.Methods: Self-supervised Loss Functions
Regression-lossThe regression-based pretraining uses an image reconstruction loss to generate representations that exploit the spatial dependencies between pixels, similar to self-supervised denoising auto-encoder methods (e.g. Noise2Void4). Figure-1(left) shows an illustration of the learning strategy as well as the loss function used. Here, using a mask M, a percentage of the pixels in the input image are replaced by Gaussian noise. The objective is to minimize the L1 reconstruction loss evaluated only at corrupted pixels to prevent the CNN from learning identity relationship.
Contrastive-loss
Figure-1(right) shows an illustration of the contrastive loss based pretraining as well as the equation for contrastive loss. A form of representational learning, contrastive loss5,6 learns representations/features that approximate the semantic similarity between pairs of images. Using a cosine similarity distance metric, this loss function pulls representations of similar images closer (e.g. an image with two different data augmentation schemes or two images with similar anatomical content) while pushing away the representations of dissimilar images. During the subsequent fine-tuning stage, these clustered representations of images are further separated using a supervised loss function, such as dice loss. In this work, the encoder is first trained to contrast global representations of images6, followed by training the decoder to contrast representations of local patches in image7.
Methods: Downstream Segmentation Task
Once the CNN is pretrained, a limited number of labeled datasets are used to finetune the model (Figure-2). In this work, we evaluate the SSL pretraining techniques in two different image segmentation problems: a) liver and b) prostate segmentation.T2w Abdominal MR images: Images acquired at 1.5T on 138 subjects were de-streaked using either CACTUS8 or manual removal of streak inducing coils. 31 of these datasets were labeled for a previous liver segmentation study9 and were used here again for finetuning/testing.
T2w prostate MR images: 2D T2-weighted images of the prostate, from the Medical Decathlon Segmentation Challenge10, consisted of 48 volumes. The contours for peripheral zone and transition zone were combined to form the prostate mask. The details of these datasets are tabulated in Table 1.
Methods: Experiments
A UNET-like11 architecture was pretrained using the two self-supervised learning approaches with unlabeled images for the two segmentation tasks. Once pretrained, the CNNs were finetuned for the subsequent image segmentation task, using a Dice loss metric, by varying the number of labeled training images for each case (N=1, 2, 4 etc.). The performance of the CNN was evaluated on the test cohorts using Dice scores. A supervised baseline performance for each segmentation task was obtained by training the CNN using all available labeled training images and extensive data augmentation.Results
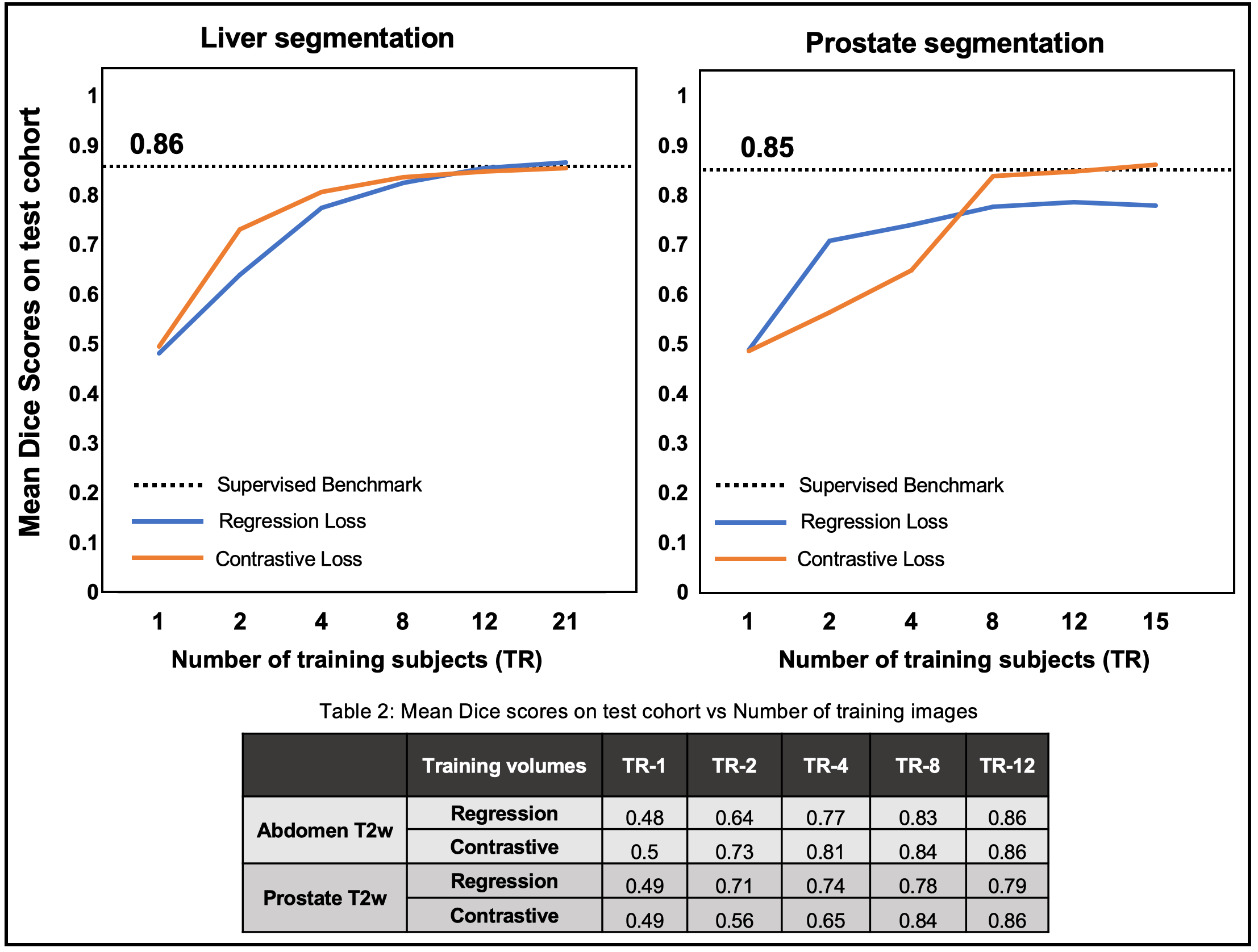
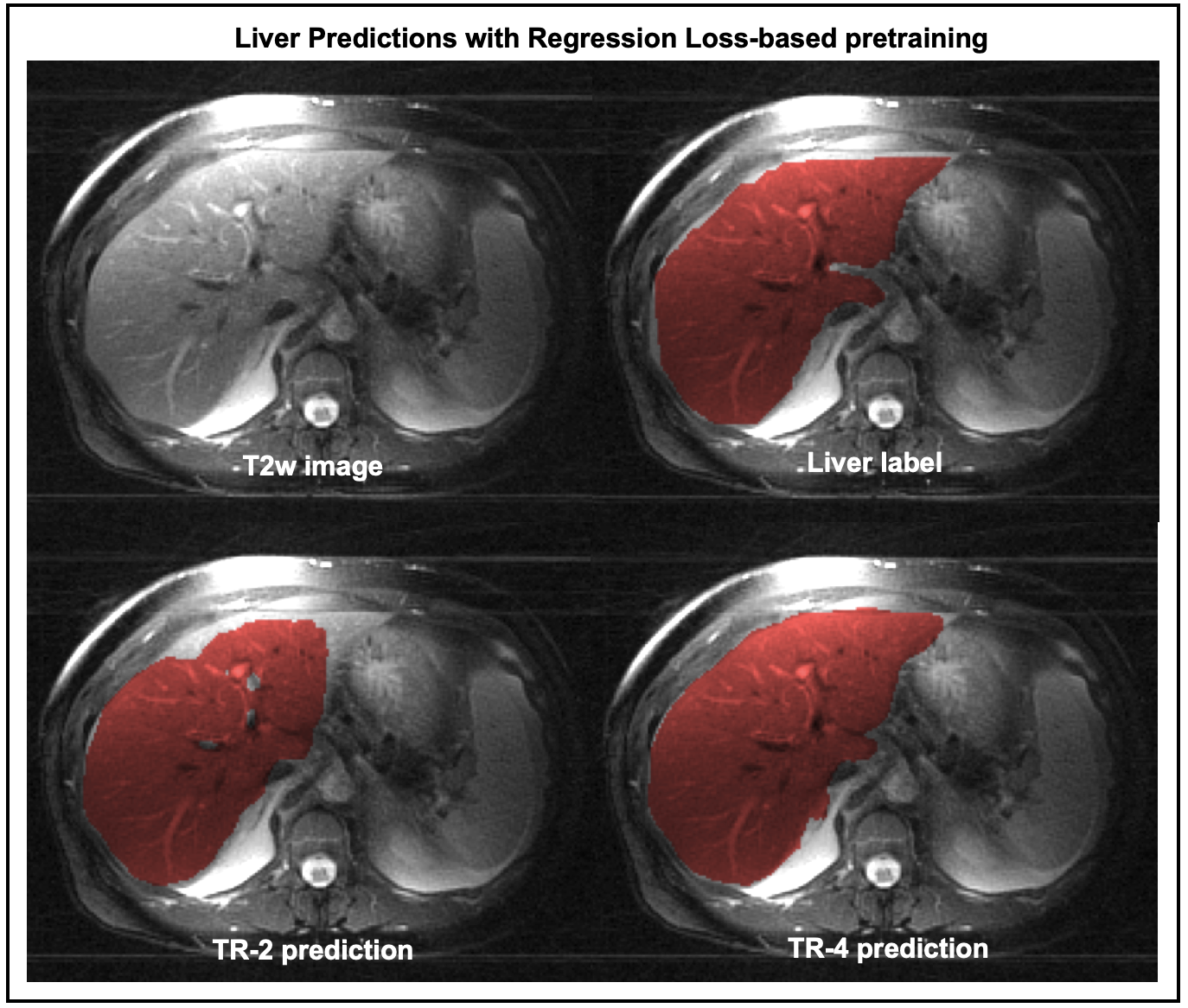
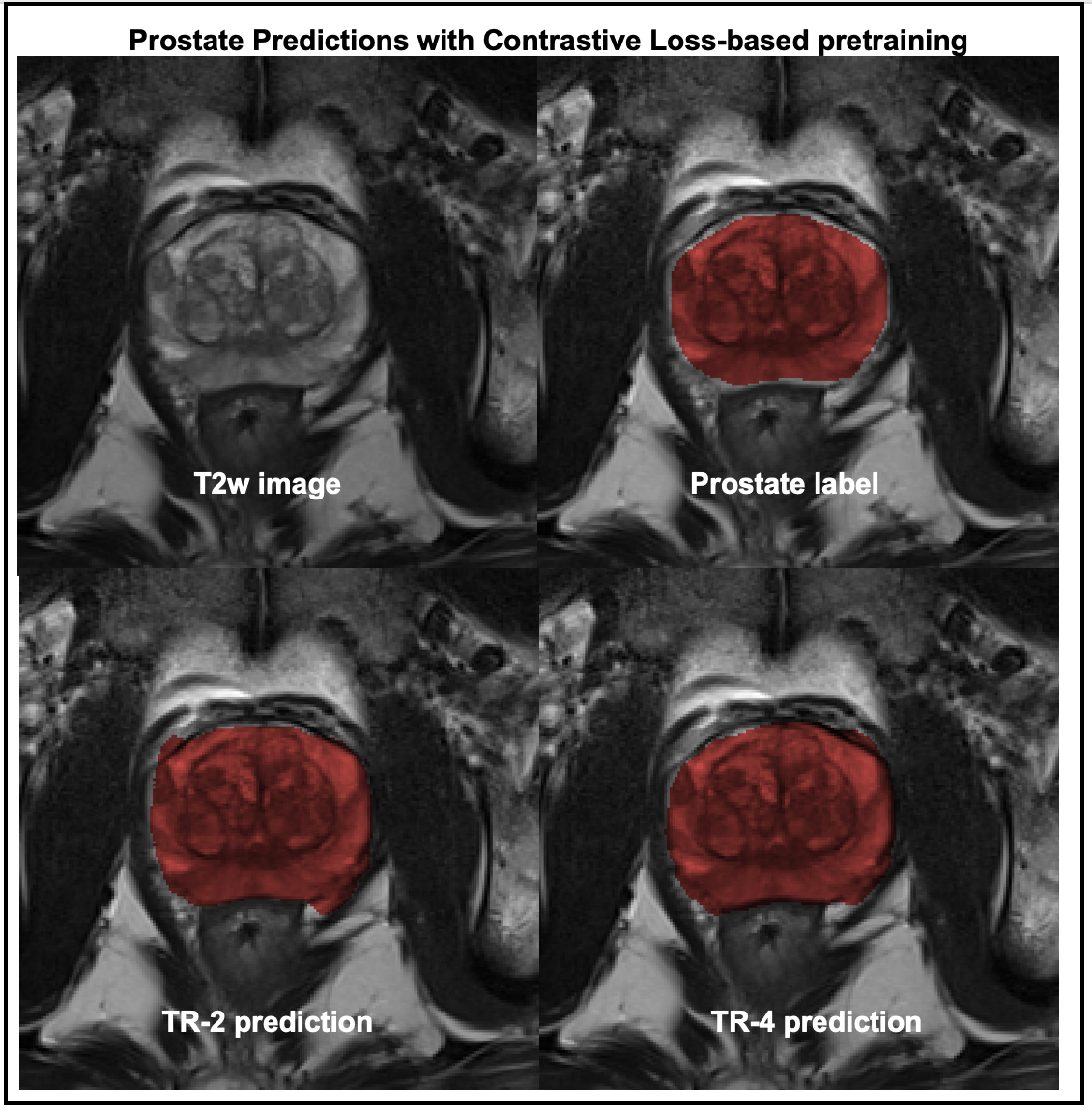
Figure-3 compares the segmentation performances of the regression- and the contrastive-loss based pretraining on the two test cohorts, as the number of training subjects are varied. We observe that the proposed self-supervised pretraining methods approach the performance of the supervised benchmark with very few labeled datasets. With only 4 annotated volumes, the proposed methods achieve mean dice scores of 0.81 and 0.74 on the liver and prostate tasks, respectively, as compared to the mean dice scores of 0.86 and 0.85 for the supervised benchmarks. On the prostate segmentation task, the contrastive-loss pretraining achieves mean dice scores equivalent to the supervised benchmark using only 8 annotated volumes.A qualitative comparison of segmentation maps are provided for the liver (Figure-4) and prostate (Figure-5) segmentation tasks. Even with two annotated subjects, the proposed technique provides prostate masks that are very close to the ground truth annotations.
Discussion and Conclusion
In this work, we explored the potential of SSL pretraining with large unlabeled images using two different loss functions, each designed to affect the representations generated by the CNN in different ways. We observed that self-supervised pretraining mechanisms can reduce the requirements for expensive image annotations in MR imaging applications (abdomen and prostate)Acknowledgements
The authors would like to acknowledge grant support from NIH (CA245920), the Arizona Biomedical Research Commission (CTR056039), and the Technology and Research Initiative Fund Technology and Research Initiative Fund (TRIF).References
[1] Litjens G, Kooi T, Bejnordi BE, et al. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42(December 2012):60-88.
[2] Bai, W., Chen, C., Tarroni, G., Duan, J., Guitton, F., Petersen, S.E., Guo, Y., Matthews, P.M., Rueckert, D.: Self-supervised learning for cardiac mr image segmentation by anatomical position prediction. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 541–549. Springer (2019)
[3] Jamaludin, A., Kadir, T., Zisserman, A.: Self-supervised learning for spinal mris. In: Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pp. 294–302. Springer (2017)
[4] A. Krull, T. Buchholz and F. Jug, "Noise2Void - Learning Denoising From Single Noisy Images," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 2124-2132, doi: 10.1109/CVPR.2019.00223.
[5] Hadsell R, Chopra S, LeCun Y. Dimensionality reduction by learning an invariant mapping. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Vol 2. ; 2006. doi:10.1109/CVPR.2006.100
[6] Chen T, Kornblith S, Norouzi M, Hinton G. A Simple Framework for Contrastive Learning of Visual Representations. PMLR; 2020. https://github.com/google-research/simclr. Accessed January 18, 2021.
[7] Chaitanya K, Erdil E, Karani N, Konukoglu E. Contrastive learning of global and local features for medical image segmentation with limited annotations. arXiv Prepr arXiv200610511. 2020.
[8] Fu, Z., Altbach, I.M., & Bilgin, A. (2021). Cancellation of streak artifacts using the interference null space (CACTUS) for radial abdominal imaging. In Proceedings of the 29th Annual Meeting of ISMRM (0670)
[9] Umapathy L, Keerthivasan MB, Galons JP, et al. A comparison of deep learning convolution neural networks for liver segmentation in radial turbo spin echo images. In: Proceedings of International Society for Magnetic Resonance in Medicine. ; 2018:2729. https://arxiv.org/abs/2004.05731.
[10] (http://medicaldecathlon.com)[11] Ronneberger, Olaf, Philipp Fischer and Thomas Brox. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” MICCAI (2015).
Figures
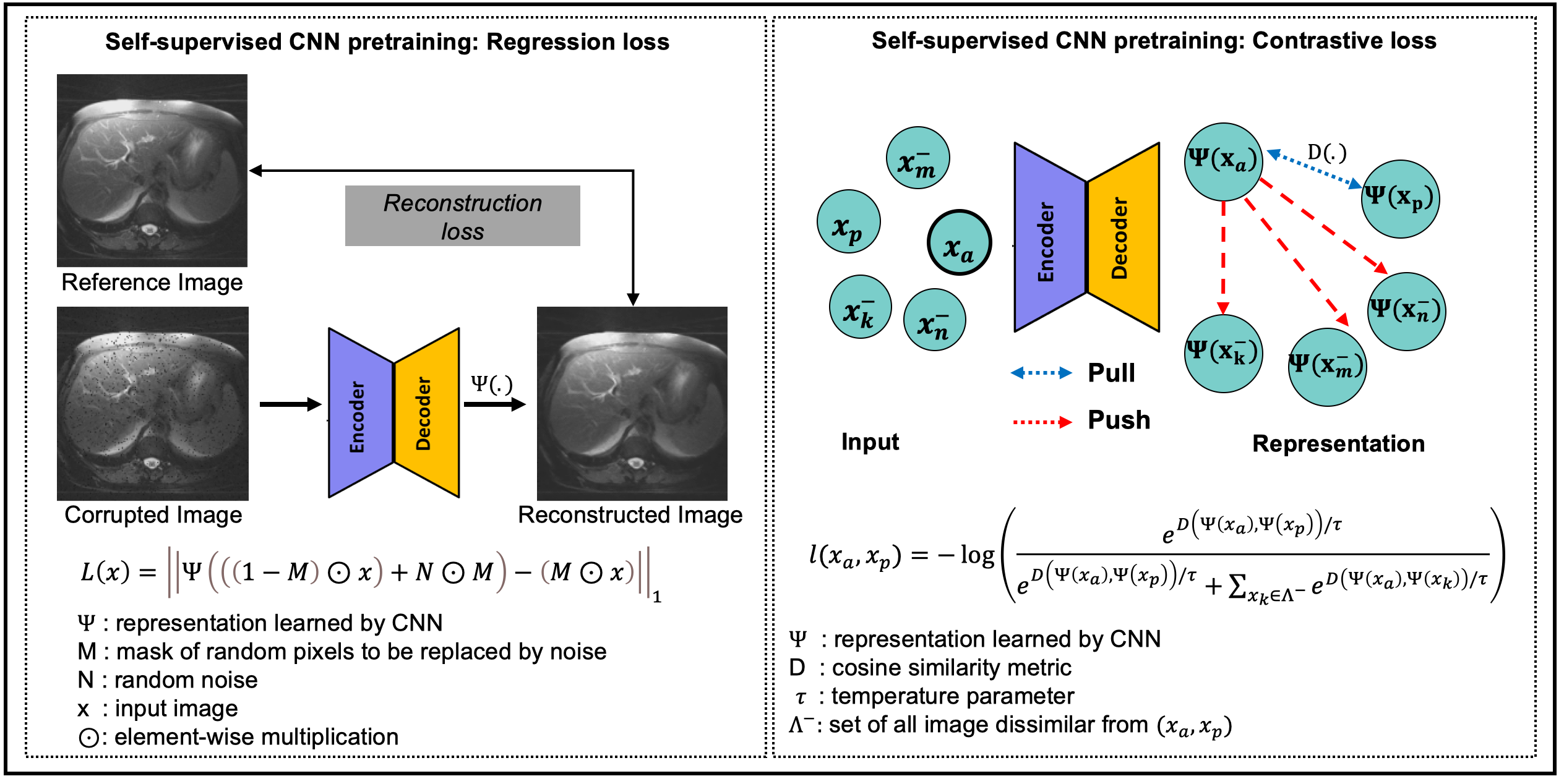
Figure 1: Illustration of self-supervised pretraining of a CNN with unlabeled images using regression loss (left) and contrastive loss (right). Regression loss: A mask M is used to randomly replace pixels in image x with random noise. The CNN is trained to minimize reconstruction error at the corrupted pixel locations. Contrastive loss: The CNN is trained to pull feature representations of similar images closer to each other, while pushing the representations of dissimilar images away. A cosine similarity metric is used to measure the distance in the representation space.
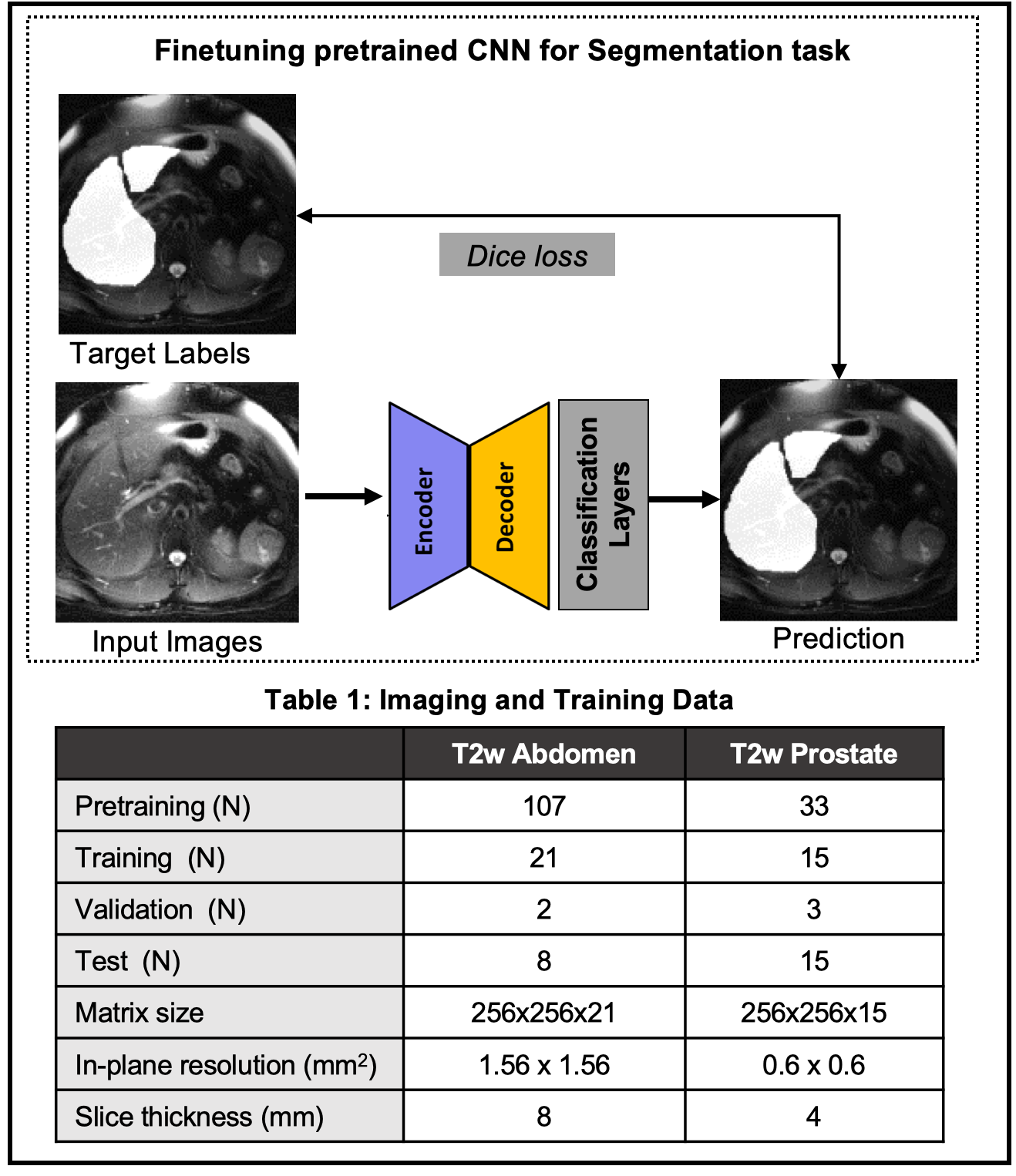
Figure 2: (Top) Finetuning the pretrained CNN with a supervised loss and limited labels. Two different image segmentation tasks are evaluated: liver segmentation in T2w images of the abdomen and prostate segmentation in T2w images of the prostate. (Bottom) Table 1 shows the number of subjects used for the pre-training as well as subsequent segmentation tasks.