3517
Noise2DWI: Accelerating Diffusion Tensor Imaging with Self-Supervision and Fine Tuning1Electrical and Computer Engineering, University of Arizona, Tucson, AZ, United States, 2Biomedical Engineering, University of Arizona, Tucson, AZ, United States, 3Medical Imaging, University of Arizona, Tucson, AZ, United States, 4Applied Mathematics, University of Arizona, Tucson, AZ, United States
Synopsis
In this work we propose a novel algorithm of denoising accelerated diffusion weighted MRI (dMRI) acquisitions using deep learning and self-supervision. This method effectively enables the prediction of diffusion-weighted images (DWIs), without the need for large amounts of training data with high directional encodings. We demonstrate that accurate diffusion tensor metrics can be obtained with as few as 6 DWIs using only a few training datasets with high directional encodings.
Introduction
Diffusion tensor imaging (DTI)1 is a diffusion-weighted magnetic resonance imaging (dMRI) technique utilized to quantify and assess microstructural characteristics in tissue.2,3 DTI is used to study physiological and structural processes in neuronal connectivity4, as well as ischemia3 and response to therapy.5,6,7 One drawback of DTI is the long acquisition times required to obtain a large number of diffusion-weighted images (DWIs) for accurate estimation of the diffusion tensor. Recently, deep learning (DL) techniques have been introduced to overcome the limitations of DTI.8,9,10,11 These techniques utilize fully-supervised training with large DWI datasets acquired using long scans with many diffusion directions. Unfortunately, acquiring large amounts of high-quality DWI data for training is very challenging and expensive. In this work, we present a novel self-supervised deep learning (SSDL) framework, Noise2DWI, which relaxes the requirement of large training datasets.Methods
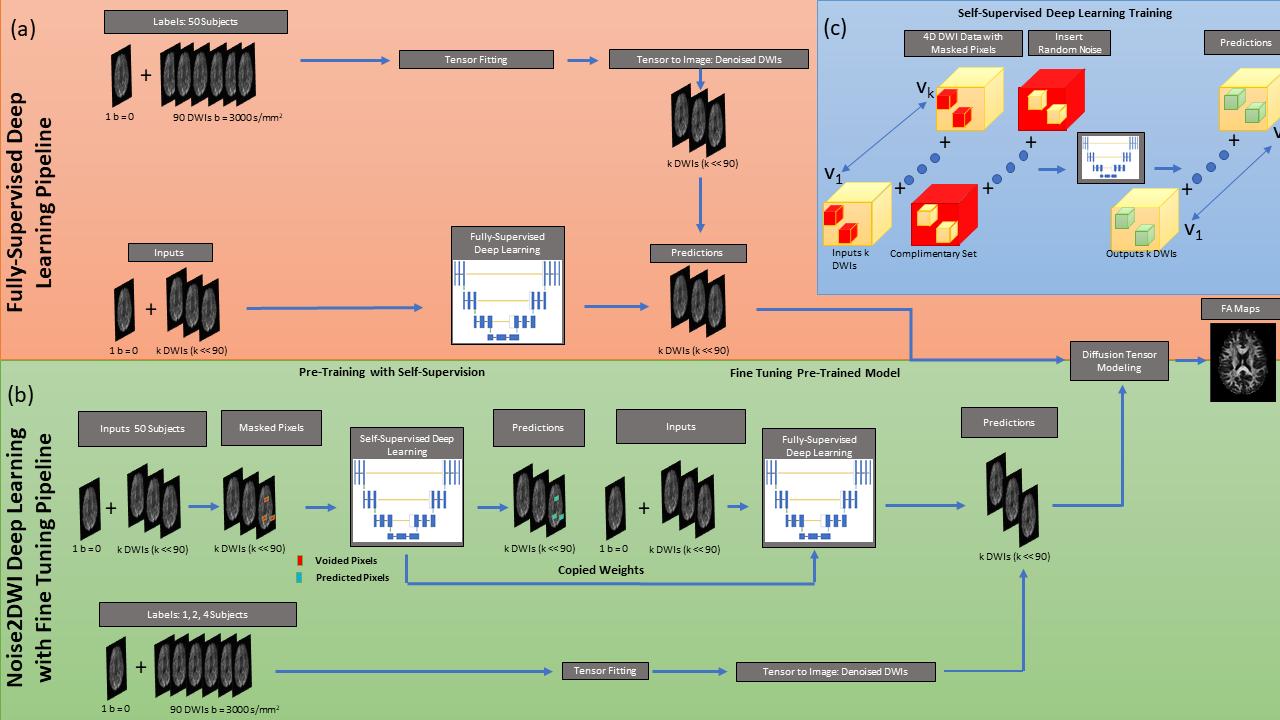
Datasets for 70 subjects from the Human Connectome Projects (HCP) public database12 were downloaded and split into 50, 10, and 10 datasets for training, validation, and testing, respectively. The first k=6 and k=12 DWIs of the 90 DWIs for the b = 3000 s/mm2 diffusion gradient weighting were used to simulate accelerated acquisitions. For fully-supervised training (Fig. 1a), k noisy DWIs, together with a single b=0 image, were used as input. To obtain the labels, tensor fitting was performed using 90 DWIs and the fitted tensor was used to generate denoised images along the first k diffusion directions using MRtrix software.13 These k denoised DWIs were used as labels during fully-supervised training with mean absolute error (MAE) loss.Noise2DWI (Fig. 1b) consists of pre-training with self-supervision followed by fully-supervised fine-tuning on a small number of datasets. During self-supervised pretraining, k noisy DWIs from 50 subjects were used as labels. The input to the network were generated by randomly replacing a small fraction of the pixels in each training sample with noise, using random complementary Poisson disc sampling to ensure neighboring pixels were not removed (Fig. 1c). A custom loss function was implemented to compute MAE only on the replaced pixels. During fine-tuning, the encoder weights of the pre-trained network were frozen and the decoder weights were fine-tuned using fully-supervised training with DTI-denoised data from a small number of subjects. The fine-tuning learning rate was an order of magnitude smaller than the one used during pre-training.
All networks were implemented in Python using Tensorflow/Keras and trained on an NVIDIA RTX 3090 GPU. All techniques used the same a UNet14 architecture with contracting and expanding paths, channel attention, residual layers, and skip connections. 64x64x5xk tensors, batch size of 128, and learning rate of 10-4, Adam optimizer with cosine weight decay, and a maximum of 100 epochs with early stopping were used during training.
The denoised DWIs were used for tensor fitting and tensor metrics were calculated using MRtrix. DWIs and tensor metrics obtained by tensor-fitting the 90 DWI dataset were considered as reference. Normalized Root Mean Squared Error (NRMSE) between the network predictions and reference DWIs were evaluated. Pearson Correlation Coefficients (PCCs) were used to compare the tensor metrics from accelerated acquisitions to the reference tensor metrics obtained using 90 DWIs. For comparative analysis, Marcenko-Pastur Principal Components Analysis (MP PCA) denoising15 was also performed on the accelerated datasets.
Results and Discussion
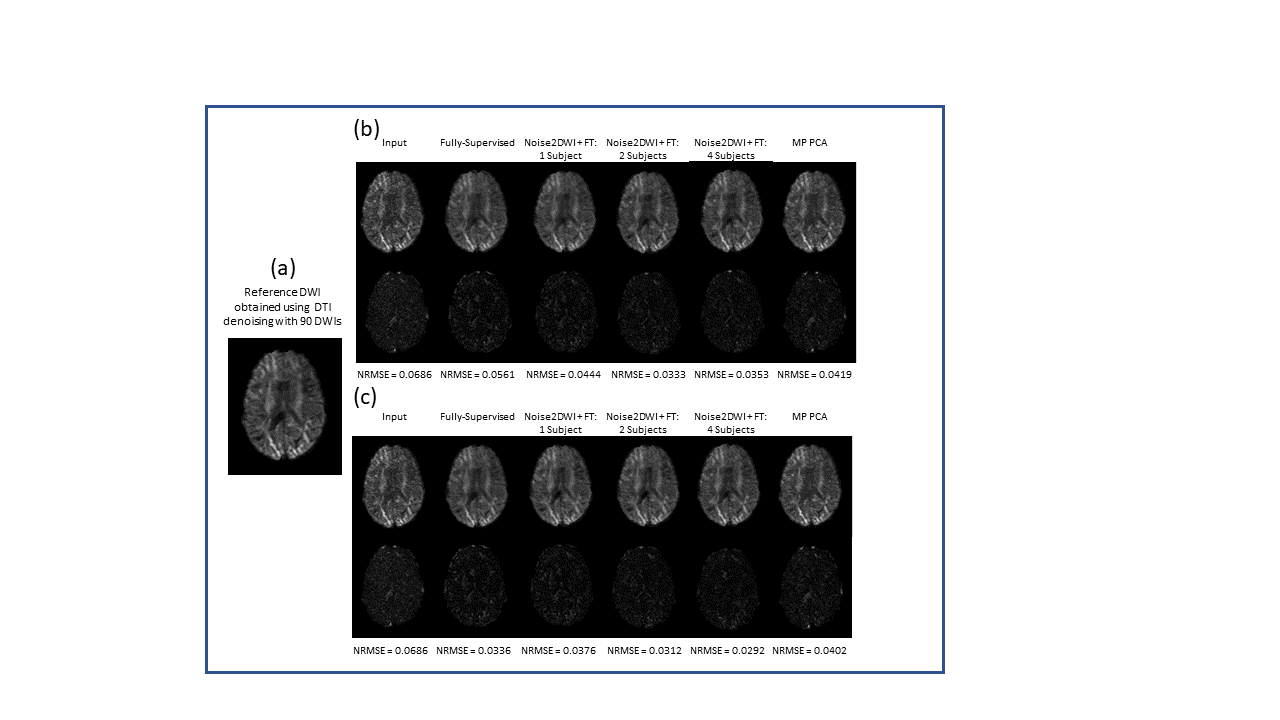
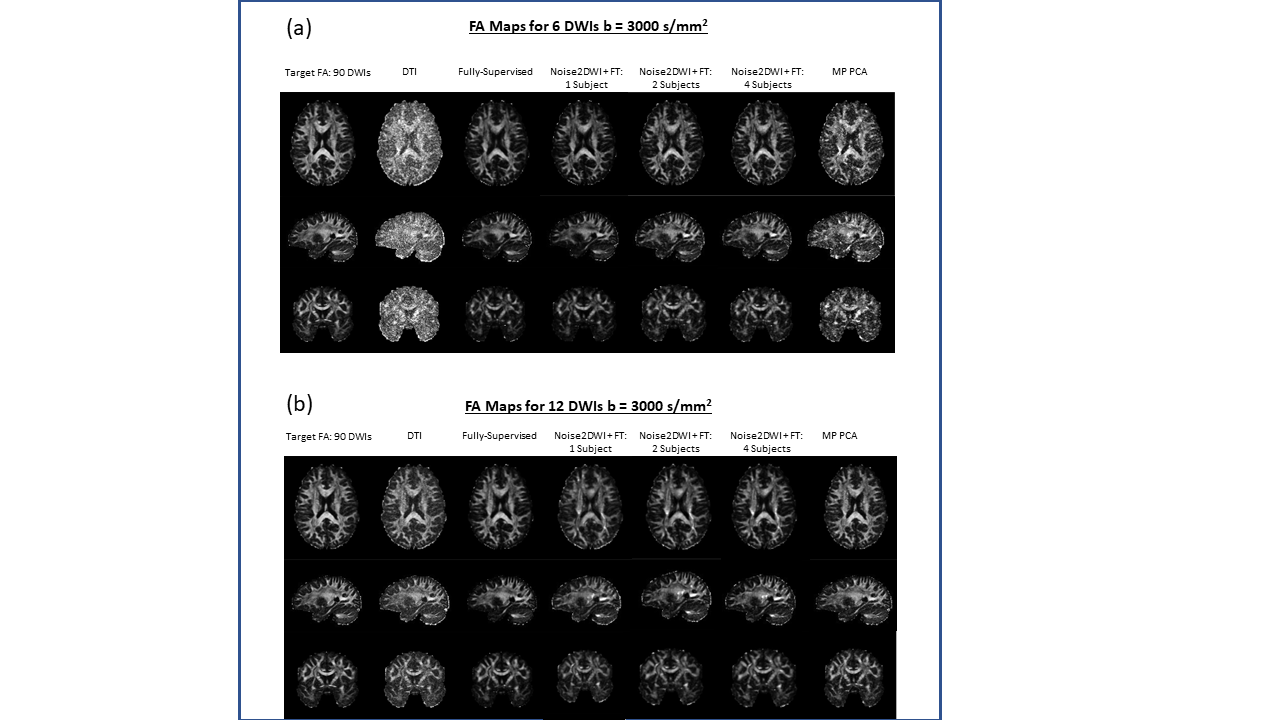
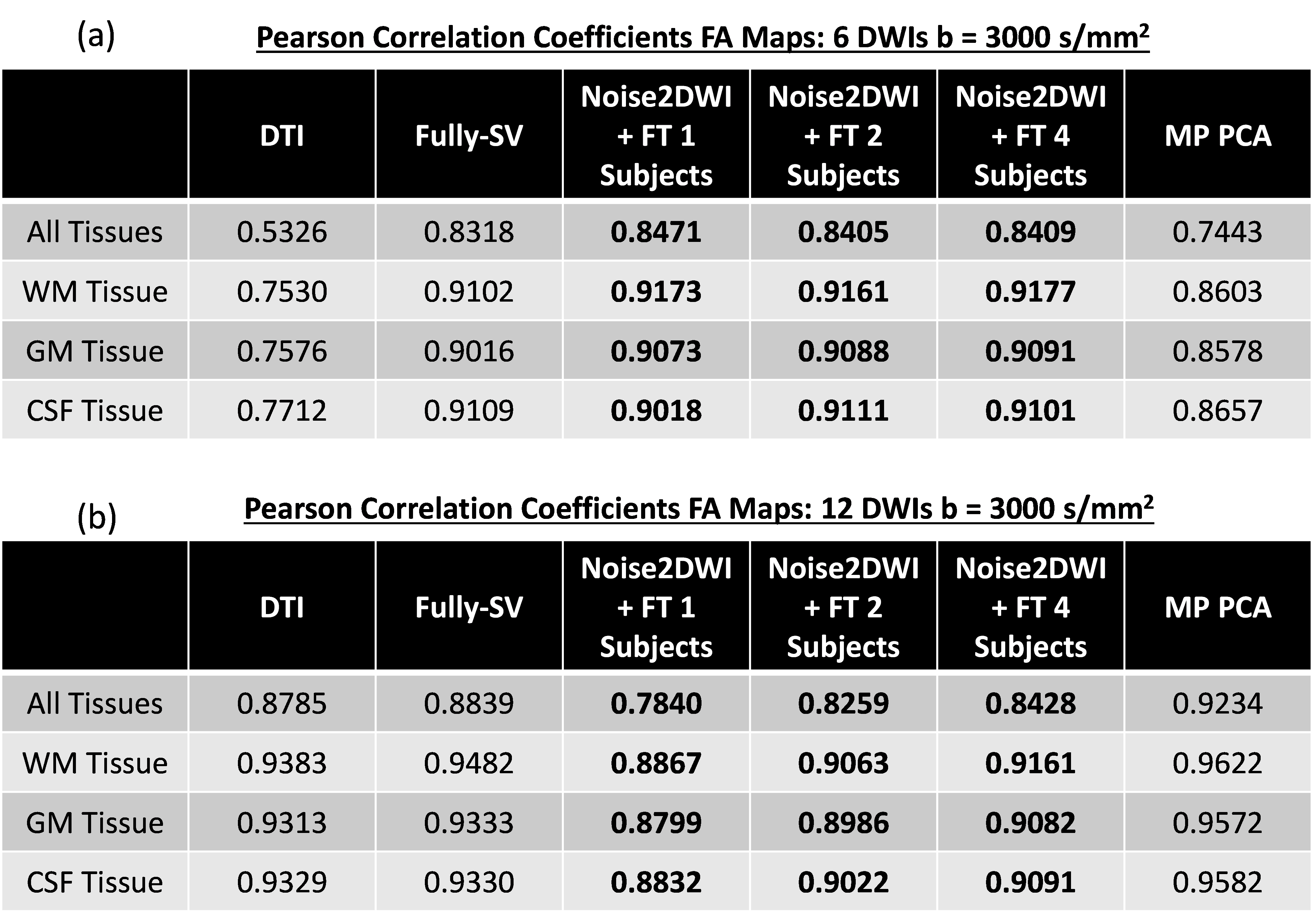
Fig. 2 shows DWIs predicted by different computational frameworks for two different acceleration factors (k=6 and k=12). The NRMSE performance of Noise2DWI generally improves with increasing number of fine-tuning subjects and number of diffusion orientations, and is superior to the NRMSE values obtained by the fully-supervised framework. Fig. 3 depicts DTI FA metrics obtained for the different computational frameworks. At k=6, MP-PCA is not able to effectively remove noise but the fully-supervised and Noise2DWI methods provide high-quality FA maps that are comparable to the reference FA maps. At k=12, Noise2DWI FA maps improve with increasing number of finetuning subjects. Fig. 4 shows plots of two-dimensional histograms comparing the predicted FA values for each computational framework to the reference FA values over the entire test cohort. The plots indicate increased overestimation of FA values with an increase in the acceleration factor for conventional DTI and MP PCA, while the DL frameworks present no significant over or under estimation.Table 1 presents PCCs between the predicted FA metrics for each framework and the reference FA metrics. At k = 6, PCCs acquired by DTI and MP PCA show considerably lower values. On the other hand, the DL frameworks show consistently high PCCs for the higher acceleration ratios.
Overall, results suggest that self-supervised pre-training followed by fine-tuning on a small number of subjects can yield performance similar to or better than fully-supervised training on a much larger cohort. This is particularly true at high acceleration rates. The proposed Noise2DWI approaches the performance of the fully-supervised DL framework for 12 DWIs and either matches or exceeds the fully-supervised framework for a higher acceleration factor of 6 DWIs.
Conclusions
We have demonstrated a novel SSDL technique, Noise2DWI, which enables high-accuracy predictions of DTI metrics from accelerated acquisitions. Noise2DWI can learn from accelerated acquisitions, significantly reducing the requirements of the number of datasets with high directional encodings needed full-supervised training.Acknowledgements
We would like to acknowledge grant support from the Arizona Biomedical Research Commission (CTR056039), Arizona Alzheimer’s Consortium, and the Technology and Research Initiative Fund Technology and Research Initiative Fund (TRIF).
References
1. Basser PJ, Mattiello J, LeBihan D. Estimation of the effective self-diffusion tensor from the NMR spin
echo. J Magn Reson B 1994;103:247–254.
2. Alexander AL, Lee JE, Lazar M, Field AS. Diffusion tensor imaging of the brain. Neurotherapeutics.
2007;4(3):316-329. doi:10.1016/j.nurt.2007.05.011
3. Tae WS. Ham BJ, Pyun SB, Kang SH, Kim BJ, Current Clinical Applications of Diffusion-Tensor Imaging in
Neruological Disorders. J Clin Neruol 2018; 14(2): 129-140.
4. Zeineh MM, Holdsworth S, Skare S, Atlas SW, Bammer R. Ultra-high resolution diffusion tensor
imaging of the microscopic pathways of the medial temporal lobe. Neuroimage 2012; 62: 2065-2082.
5. Jiang Q, Zhang ZG, Chopp M. MRI evaluation of white matter recovery after brain injury. Stroke 2010;
41: S112-S113.
6. Maller JJ, Thomson RH, Lewis PM, Rose SE, Pannek K, Fitzgerald PB. Traumatic brain injury, major
depression, and diffusion tensor imaging: making connections. Brain Res Rev 2010; 64: 213-240.
7. Schlaug G, Renga V, Nair D. Transcranial direct current stimulation in stroke recovery. Arch Neurol
2008; 65: 1571-1576.
8. Golkov V., et al., 2016. q-Space deep learning: twelve-fold shorter and model-free diffusion MRI scans.
IEEE Trans. Med. Imag. 35, 1344–1351.
9. Aliotta, E., Nourzadeh, H., Sanders, J., Muller, D., Ennis, D.B., 2019. Highly accelerated, model-free
diffusion tensor MRI reconstruction using neural networks. Med. Phys. 46, 1581–1591.
10. Tian Q, Bilgic B, Fan Q, Liao C, Ngamsombat C, Hu Y, Witzel T, Setsompop K, Polimeni JR, Huang SY.
DeepDTI: High-fidelity six-direction diffusion tensor imaging using deep learning. NeuroImage,
Volume 219: 117017, 2020. https://doi.org/10.1016/j.neuroimage.2020.117017.
11. Bilgin A, Do L, Martin P, et. al., Accelerating Diffusion Tensor Imaging of the Rat Brain using Deep
Learning. Proceedings of the 2021 Meeting of the ISMRM, Abstract 2444.
12. https://www.humanconnectome.org
13. Batson J., Loic R., Noise2Self: Blind Denoising by Self-Supervision. arXiv: 1901.11365 [cs.CV] (2019).
14. Tournier JD, Smith RE, Raffelt D, Tabbara R, Dhollander T, Pietsch M, Christiaens D, Jeurissen B, Yeh
C-H, and Connelly A. MRtrix3: A fast, flexible and open software framework for medical image
processing and visualisation. NeuroImage, 202 (2019), pp. 116–37.
15. Veraart J, Nvokov DS, Christiaens D, Ades-aron B, Sijbers J, Fieremans E, Denoising of diffusion MRI
using random matrix theory. NeuroImage 142 (2016) 394-406.
Figures