3516
Self-Supervised Deep Learning for Highly Accelerated 3D Ultrashort Echo Time Pulmonary MRI1University of Wisconsin-Madison, Madison, WI, United States
Synopsis
The goal of this work is to reconstruct highly undersampled frames from dynamic Non-Cartesian acquisitions using deep learning. In this setting, supervised data is difficult to obtain due to organ motion necessitating self-supervision. The challenge is that acquisitions are often so data-starved that self-supervised reconstructions that use only spatial correlations fail to recover fine details. Here, we leverage correlations across time frames, and show that even when data is misaligned, it is possible to reconstruct highly accelerated frames using self-supervised methods. We demonstrate the feasibility of this technique by reconstructing end-inspiratory phase images from respiratory binned Pulmonary UTE acquisitions.
Introduction
Self-supervised model based deep learning (MBDL) (1) has been applied successfully to reconstruction of 2D Cartesian acquisitions, enabling deep learning image reconstruction in cases without a ground truth. In this approach, undersampled k-space is partitioned into two subsets, and a neural network is trained to start with data from one subset of k-space data and solve for the other. This is similar to noise2noise type reconstructions, but with data-consistency enforced in k-space (2).This approach is effective when partitioning moderately undersampled data; however, reconstructions are less than satisfying when partitioning highly accelerated data (>10 fold). This is a particular problem for 3D non-cartesian acquisitions acquired during motion. The high degree of undersampling in these acquisitions not only makes supervision difficult to obtain, but simultaneously makes self-supervised methods that rely solely on spatial correlations difficult to train. This, in addition to GPU memory consideration makes applying deep learning in this setting challenging.
During these acquisitions, we don’t just acquire one frame. Instead, we acquire a series of misaligned, but correlated, frames. We hypothesize that neural networks can leverage these correlations to significantly improve self-supervised single frame reconstructions for highly accelerated acquisitions even when loss is enforced on a single frame. This work investigates the reconstruction of highly undersampled 3D radial pulmonary UTE data during motion using MBDL.
Theory
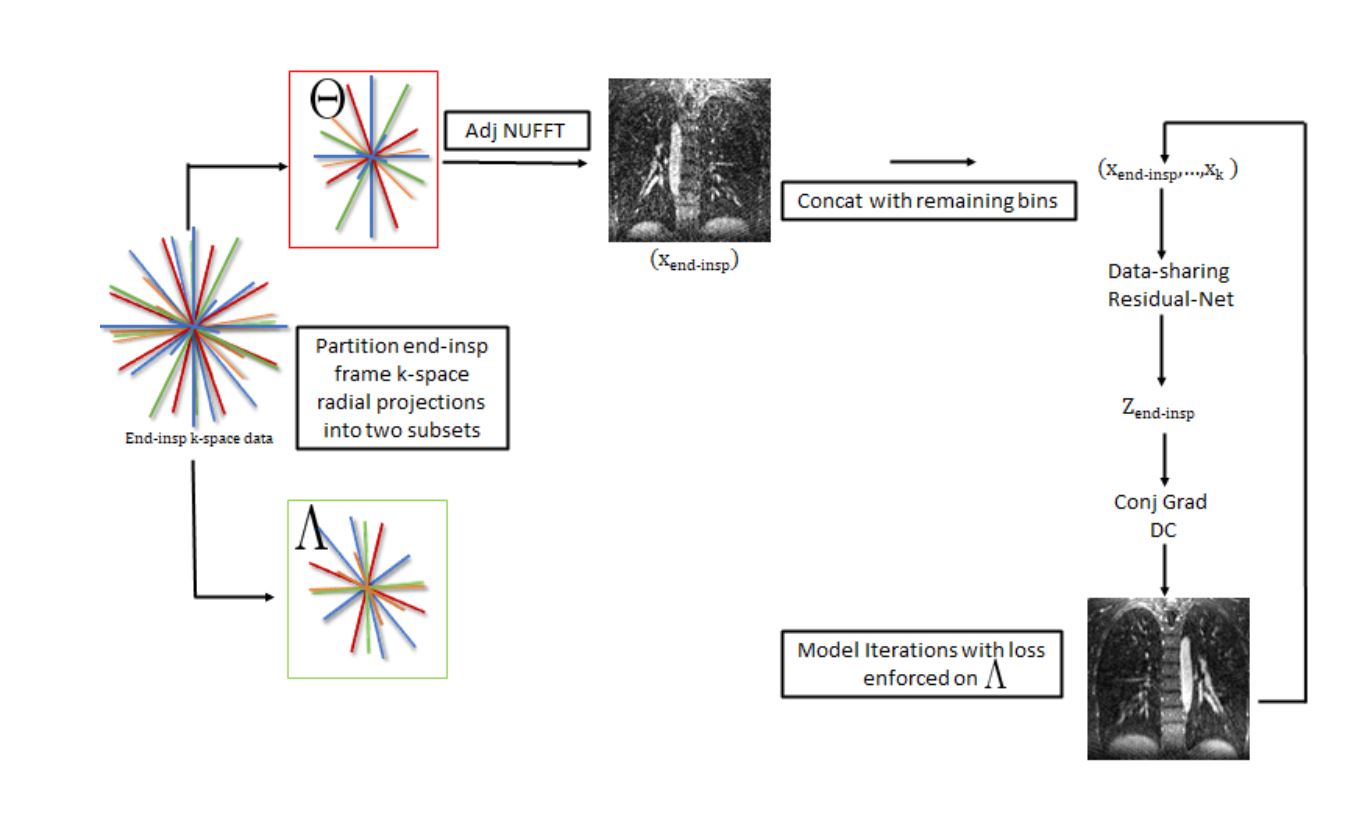
Self supervised learning as proposed by (1) takes sub-sampled k-space data $$$\Omega$$$, splits this data into two subsets such that $$$\Omega=\Lambda\cup\Theta$$$, and optimizes the neural network model such that $$\underset{\theta}{\mathrm{argmin}} \sum_{i=1}^{N} L(y_{\Lambda}^{i},f(x_{\Theta}^{i};\theta))$$Where $$$y_{\Lambda}$$$ is the subset of k-space data points belonging to $$$\Lambda$$$, $$$E$$$ is the the multi-channel SENSE NUFFT operator, $$$f$$$ is the neural network model, and $$$x_{\Theta}^{i}$$$ is the gridded data for the ith subject reconstructed from the subset of k-space data points belonging to $$$\Theta$$$.We modify this loss function so that the neural network $$$f:\mathbb{R}^{kmno} \rightarrow \mathbb{R}^{mno}$$$ accepts multi-valued inputs with $$$f(x_{\Theta,1},x_2,..,x_k) $$$ where $$$(x_1,...,x_k)$$$ represents the respiratory binned time series. We enforce the self-supervised loss only at the end-inspiratory frame.
Methods
Training Data: We acquired 32-channel radial, pulmonary MRA volumes in six healthy volunteers during free breathing on a 3.0 T GE (Waukesha, Wi) scanner. Data-sets were coil compressed to 20 channels, and binned into six respiratory phases using respiratory bellows signal. K-space in the end-inspiratory phase was randomly split into two subsets along the spoke dimension, no other respiratory phase k-space data was partitioned. We trained on 2 cases. One case was used for validation, and remaining cases were used for testing. Training was not slice-wise, but on full-volumes.Implementation: We unroll the algorithm proposed in (3) using a residual network at each regularizer step (figure 1). The network takes in 6 respiratory binned volumes as input stacked along the channel dimension and outputs the denoised end-inspiratory frame. We run 15 conjugate gradient steps in between each NN step. We use 5 unrolls, and train end-to-end in a self-supervised manner. Blockwise learning is used at each NN step and gradient checkpointing is used at each conjugate gradient step to reduce memory load. Blockwise learning reduces GPU memory use by decomposing the input volume into blocks, passing these blocks iteratively through the network, and the recomposing the blocks back into the full volume for data-consistency. The network was implemented in pytorch using NUFFT from SigPy with Pytorch wrapper and trained using a 40 GB A100 GPU.
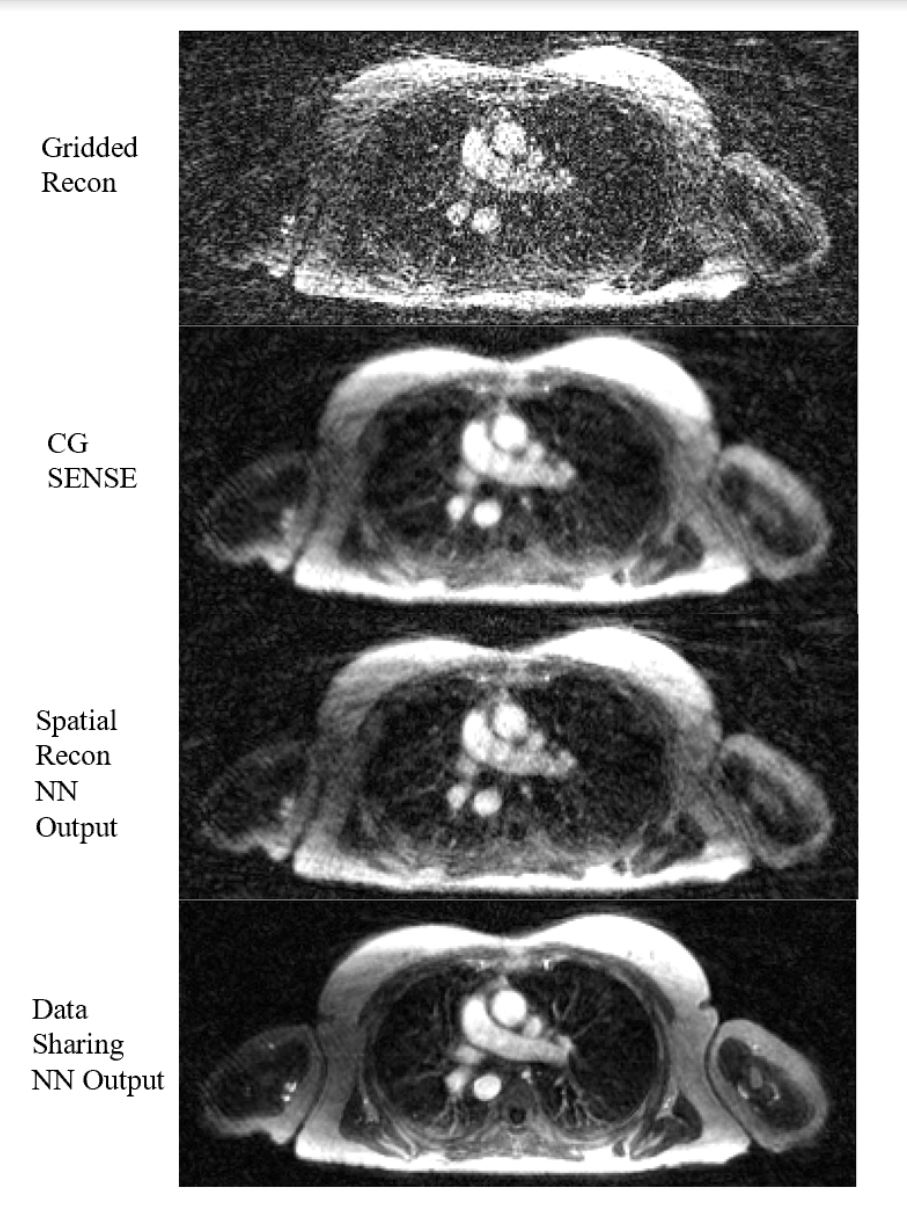
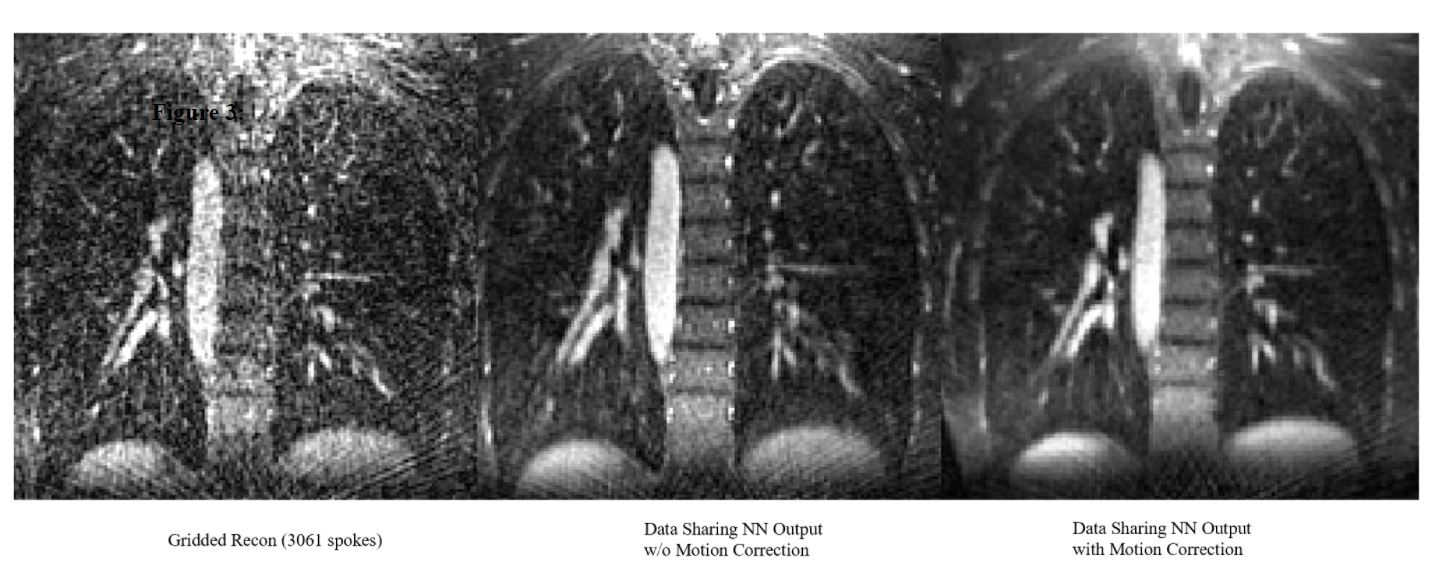
Evaluation: We compare self-supervised data-sharing reconstruction to self-supervised reconstructions without data sharing (spatial information only, 5 unrolls) and conjugate-gradient SENSE. Additionally, to further investigate how the network is sharing data across channels, we precompute motion fields directly on gridded data using a low rank group-wise registration algorithm similar to (4). As the frames reconstructed have between 800-3500 spokes (2.4-11 s of scan time), no supervision is available meaning PSNR/SSIM metrics cannot be calculated.
Results
Data sharing across time appears to significantly improve reconstruction quality over reconstructions that rely on spatial correlations only and CG-sense (see figure 2). Parenchymal details are resolved in the data sharing NN output case with significant denoising. We do note that regions with less motion (vertebrae, parts of the chest wall) are better resolved by our algorithm than regions with significant motion suggesting data sharing is a major source of improvement in reconstruction quality. Explicit motion correction across frames further improves image quality with bronchial branching clearly seen.Conclusions
We demonstrate that self-supervised DL can be applied to the highly accelerated setting by taking advantage of data correlations across bins. Next steps are to extend this work to the time resolved regime to attempt to reconstruct single frames with temporal resolution less than a second.Acknowledgements
NIH R01 HL136964, NIH R01 CA190298, and research support from GE Healthcare"References
1. Yaman, Burhaneddin, et al. "Self‐supervised learning of physics‐guided reconstruction neural networks without fully sampled reference data." Magnetic resonance in medicine 84.6 (2020): 3172-3191.
2.Lehtinen, Jaakko, et al. "Noise2noise: Learning image restoration without clean data." arXiv preprint arXiv:1803.04189 (2018).
3.Aggarwal, Hemant K., Merry P. Mani, and Mathews Jacob. "MoDL: Model-based deep learning architecture for inverse problems." IEEE transactions on medical imaging 38.2 (2018): 394-405.
4. Huizinga, Wyke, et al. "PCA-based groupwise image registration for quantitative MRI." Medical image analysis 29 (2016): 65-78.
Figures