3512
Improving Synthetic MRI from Estimated Quantitative Maps with Deep Learning1Electrical and Computer Engineering, University of Texas at Austin, Austin, TX, United States, 2Oden Institute for Computational Engineering and Sciences, University of Texas at Austin, Austin, TX, United States, 3Department of Diagnostic Medicine, University of Texas at Austin, Austin, TX, United States
Synopsis
Synthetic MRI has emerged as a tool for retrospectively generating contrast weightings from tissue parameter maps, but the generated contrasts can show mismatch due to unmodeled effects. We looked into the feasibility of refining arbitrary synthetic MRI contrasts using conditional GANs. To achieve this objective we trained a GAN on different experimentally obtained inversion recovery contrast images. As a proof of principle, the RefineNet is able to correct the contrast while losing out on finer structural details due to limited training data.
Introduction
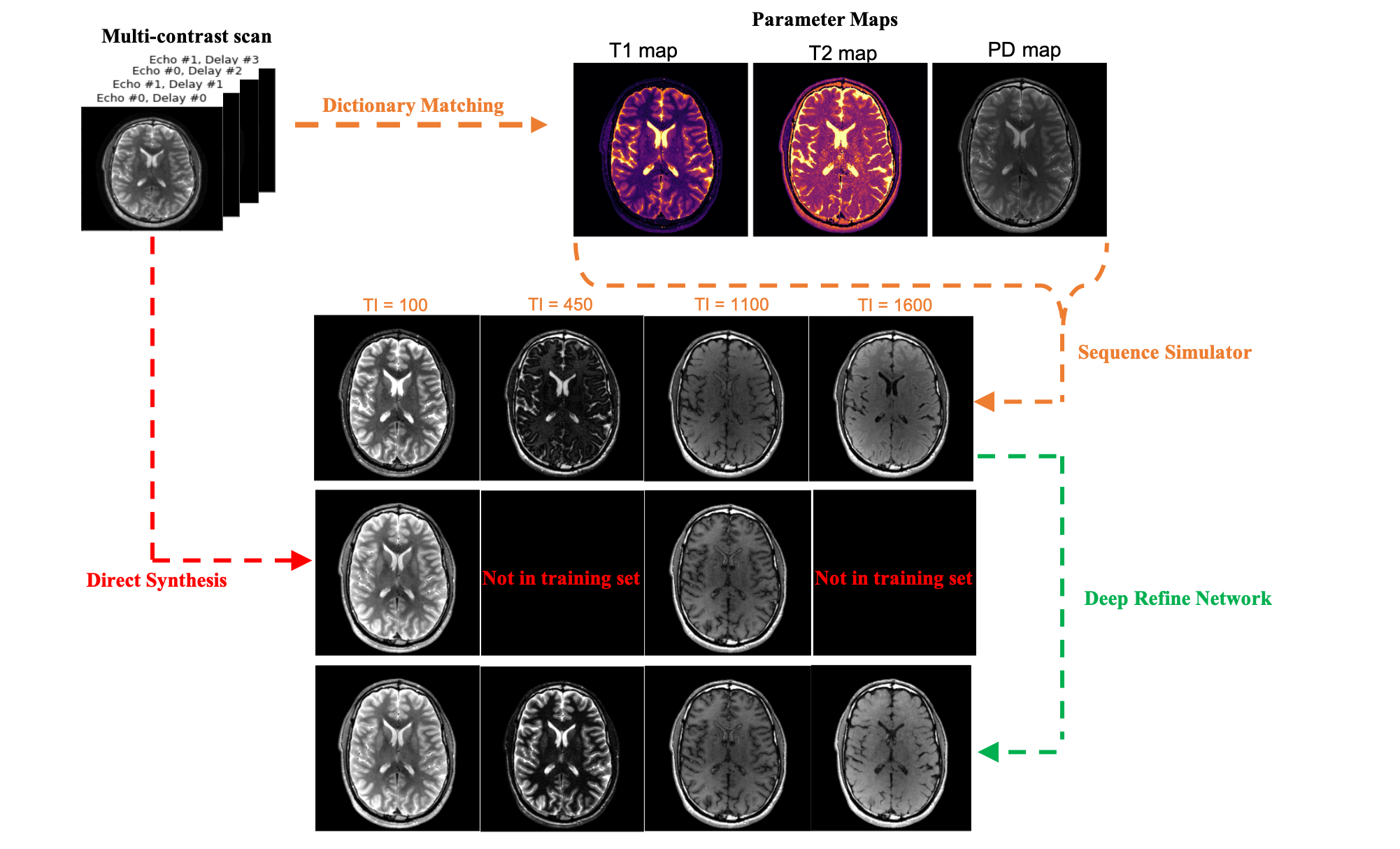
Synthetic MRI provides the ability to generate arbitrary contrast-weighted images from a fast multi-contrast protocol$$$^1$$$. Often, the image contrasts are derived from quantitative maps that are estimated from the data by curve fitting$$$^1$$$ or through dictionary matching$$$^2$$$. Arbitrary contrasts are generated from these estimated maps using a sequence simulator or analytical expressions based on the Bloch equations by changing the repetition, echo, and inversion times. For some contrasts such as inversion recovery$$$^3$$$, however, generated contrasts often show contrast mismatch for some tissue types. The discrepancy arises because of unmodeled effects including partial voluming, magnetization transfer, diffusion effects, susceptibility, and more. While it is possible to build a sequence protocol that incorporates these effects, it would take too long to acquire in practice.Recently, researchers have employed deep learning techniques to overcome these issues$$$^{3-5}$$$; however, these methods typically correct a specific set of contrast weightings corresponding to the training set which limits the ability to synthesize new contrast images. Here we propose a deep learning framework to correct Synthetic MR contrasts for arbitrarily chosen scan parameters (Figure 1).
Methods
We use a conditional generative adversarial network (GAN) that takes as input the synthetic contrast images derived from the signal equations and outputs a corresponding “refined” contrast (Figure 1). Physical models alone cannot capture all underlying physics of the scanner; therefore, we use a convolutional neural network (CNN), which we call a RefineNet, to capture the unmodeled effects with appropriate training, similar to capturing the unmodeled effects in other black-box imaging systems$$$^6$$$.Our GAN is based on the pix2pix framework$$$^7$$$. We use a U-Net-based CNN for our generator, G$$$^8$$$; whereas, we used a VGG-type$$$^9$$$ network with a single channel input and a binary classification output as the discriminator, D. The reason behind using a VGG-type network as discriminator instead of pix2pix discriminator is that MR images have very similar features which need to be distinguished whereas general computer vision style transfer tasks have easily detectable features$$$^{10}$$$. First, D is trained for 20 epochs, and then G is trained for 10 epochs; and this alternating training is performed for 10 overall iterations. The learning rates for G and D are $$$10^{-4}$$$ and $$$10^{-5}$$$ respectively. The loss function for G is a linear combination of $$$L_1$$$ loss between the ground truth images and the corrected synthesized images and the adversarial loss $$$L_{adv}$$$ given by the discriminator through binary cross-entropy.
Since the RefineNet is a conditional GAN, its output will depend on the scan parameters. By collecting training data corresponding to different contrast images, we hypothesize that it is possible to learn the mapping between synthetic contrast images and acquired scans over a range of scan parameters (Figure 2), and therefore generalize to contrast images not seen in the training set.
Data Preparation
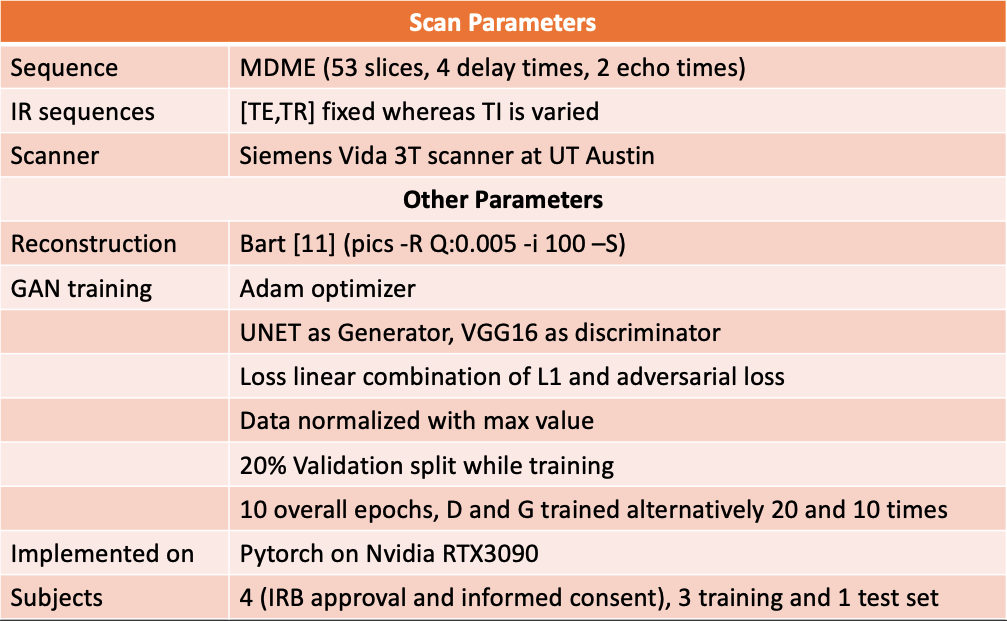
A 2D multi-delay multi-echo (MDME) fast spin-echo sequence (FSE)$$$^1$$$ was used to obtain multicontrast data. The data were collected at two different echoes to encode T2 information and four different delay times to encode T1 information with an acceleration factor of 3. Following parallel imaging reconstruction$$$^{12,13}$$$, parameter maps were estimated using dictionary fitting$$$^2$$$. Four volunteers were scanned with a brain protocol on a Seimens 3T Vida scanner (Siemens Healthineers, Erlangen, Germany) with IRB approval and informed consent. For each subject, 53 slices were acquired, and 45 brain tissue containing slices were used for training. For each subject, along with the MDME sequence, multiple inversion-recovery FSE contrasts were captured at different inversion times. Three datasets were set aside for training and the remaining one for testing. Network training was applied to the absolute value of the reconstruction, and each slice was normalized by its max value. Figure 2 summarizes the scanning and training parameters.Results and Discussion
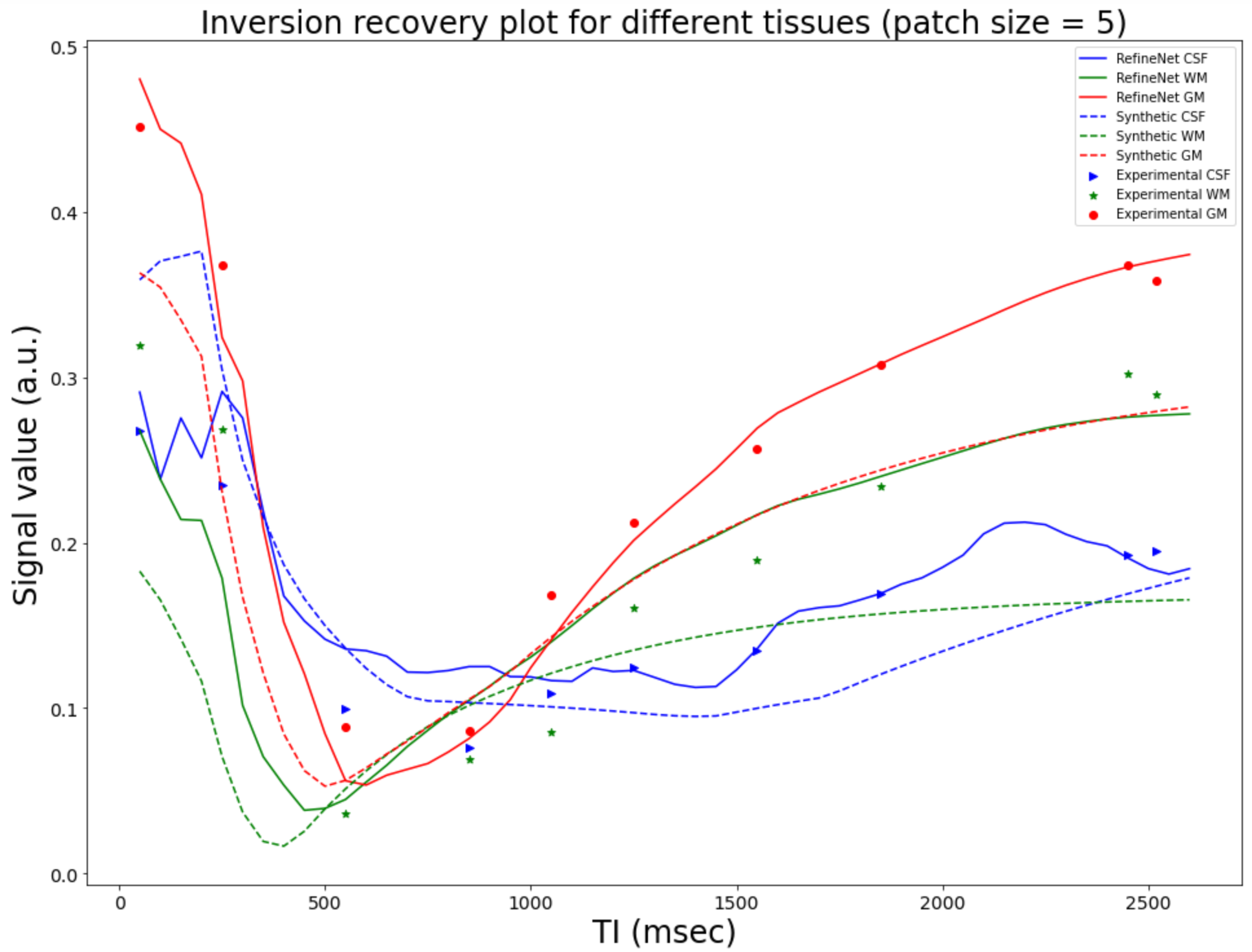
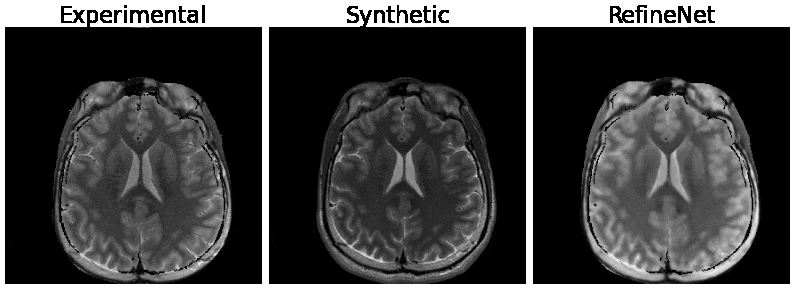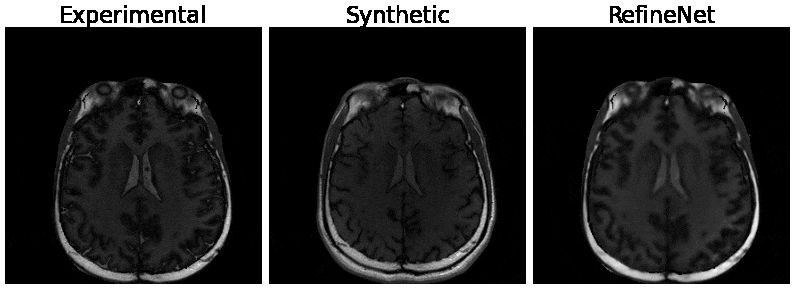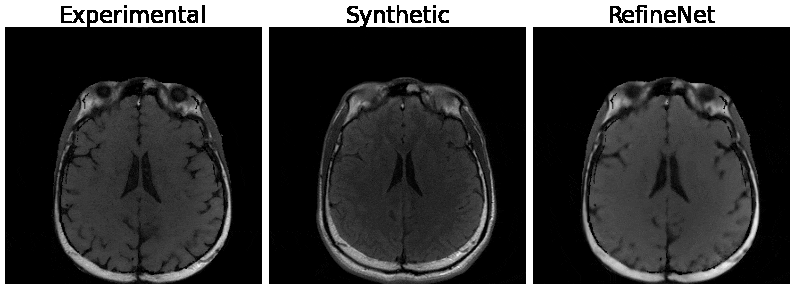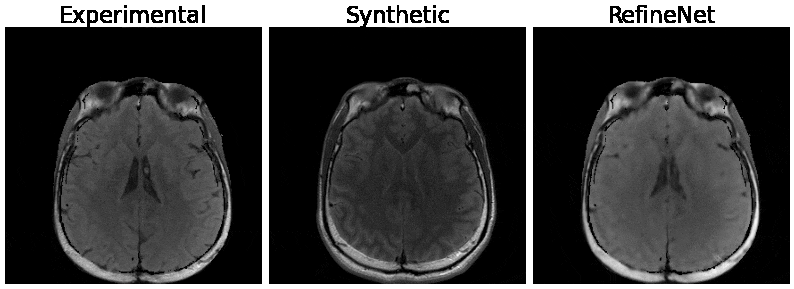
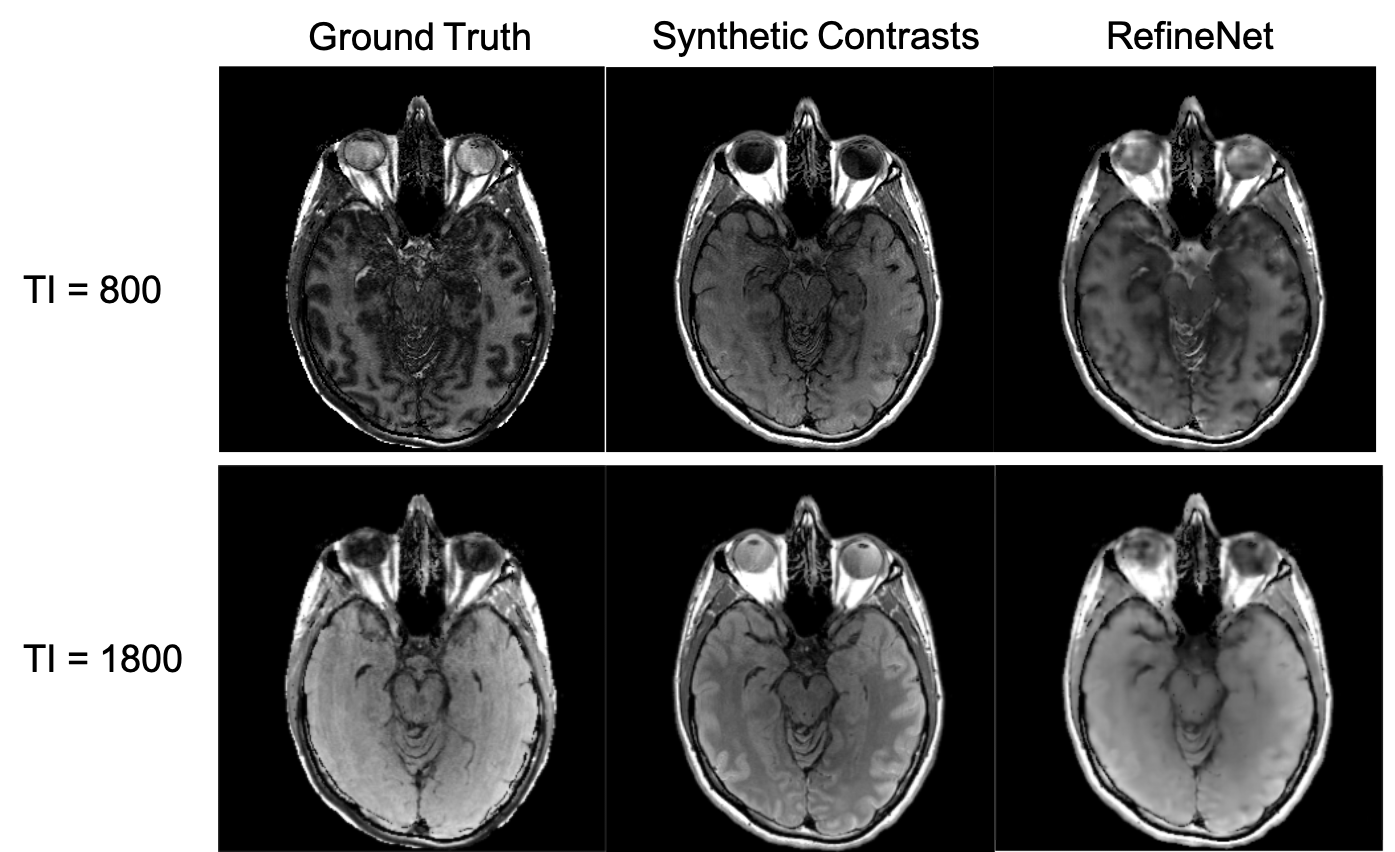
Figure 3 and 4 were evaluated on the training dataset to show feasibility of the concept. Figure 3 shows inversion recovery curves for three different tissue types over a range of synthesized image contrasts, which are evaluated by averaging over a 5-by-5 region-of-interest. The RefineNet better matches the experimentally observed data points compared to the synthetic MR contrasts on the inversion recovery curve. Notably, the curves are not smooth, indicating overfitting may be occurring. Figure 4 shows different contrasts as the inversion time is varied. Figure 5 shows the comparison between the ground truth contrasts, synthetic contrasts, and contrasts from the RefineNet. The synthetic contrast differs from the ground truth contrast due to unmodeled effects. The RefineNet was able to correct the contrast; however the finer structural details are missing, likely because of limited training data and no perceptual loss to account for high resolution details$$$^{14}$$$.Conclusion
In this work, we demonstrated that a GAN-based method can correct the generated contrasts for arbitrary scan parameters, keeping the original premise of synthetic MRI. While the results here were shown for the case of MDME sequence, a similar procedure can be followed for other multi-contrast sequences. In the future, we intend to further improve the models to also preserve the fine high-frequency features and to expand our experiments by conducting more training scans.Acknowledgements
No acknowledgement found.References
[1] Warntjes, J. B. Dahlqvist, O. & Lundberg, P. “Novel method for rapid, simultaneous T1, T*2, and proton density quantification”. Magn. Reson. Med.57,528–537 (2007).
[2] D. Ma, V. Gulani, N. Seiberlich, K. Liu, J. L. Sunshine, J. L. Duerk, M. A. Griswold, “Magnetic Resonance Fingerprinting,” Nature, vol. 495, no. 7440, pp. 187–192, 2013
[3] G. Wang et. al, "Synthesize High-quality Multi-contrast Magnetic Resonance Imaging from Multi-echo Acquisition Using Multi-task Deep Generative Model." IEEE Trans. on Med. Imag., April, 2020.
[4] Wang, K. et. al., High fidelity direct-contrast synthesis from magnetic resonance fingerprinting in diagnostic imaging. In: Proc Intl Soc Magn Res Med. p. 864 (2020)
[5] Hagiwara, A. et al. Improving the Quality of Synthetic FLAIR Images with Deep Learning Using a Conditional Generative Adversarial Network for Pixel-by-Pixel Image Translation. Am. J. Neuroradiol. 2019, 40, 224–230
[6] Ethan Tseng, Felix Yu, Yuting Yang, Fahim Mannan, Karl ST Arnaud, Derek Nowrouzezahrai, Jean-François Lalonde, and Felix Heide. 2019. Hyperparameter optimization in black-box image processing using differentiable proxies. ACM Trans. Graph. (SIGGRAPH) 38, 4 (2019), 1–14
[7] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Imageto-image translation with conditional adversarial networks. arXiv:1611.07004, 2016.
[8] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent. Munich, Germany: Springer, 2015, pp. 234–241.
[9] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014
[10] Arjovsky, Martin and Bottou, Leon. Towards principled methods for training generative adversarial networks. In International Conference on Learning Representations, 2017.
[11] BART Toolbox for Computational Magnetic Resonance Imaging, doh: 10.5281/zenodo.592960
[12] Pruessmann KP, Weiger M, Scheidegger MB, Boesiger P. SENSE: sensitivity encoding for fast MRI. Magn Reson Med 1999;42:952–962.
[13] Uecker M, Lai P, Murphy MJ, Virtue P, Elad M, Pauly JM, Vasanawala SS, Lustig M. ESPIRiT–an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magn Reson Med 2014;71:990–1001.
[14] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham, ´ A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802, 2016
Figures