3503
Joint recovery of time aligned multi-slice dynamic speech MR images from under-sampled data using a deep generative manifold model1Roy J. Carver Department of Biomedical Engineering, The University of Iowa, Iowa City, IA, United States, 2Electrical and Computer Engineering, The University of Iowa, Iowa City, IA, United States, 3Department of Radiology, The University of Iowa, Iowa City, IA, United States
Synopsis
Dynamic speech MRI is a powerful tool to characterize complex speech articulations. Current accelerated 2D dynamic speech MRI schemes can achieve high time resolutions of the order of (10-20 ms) while sequentially acquiring multiple 2D slices. However, the complex articulatory motion is difficult to interpret jointly across the slices due to mis-alignment of motion patterns. Here, we apply a novel generative manifold model which reconstructs and generates a time aligned multi-slice 2D speech dataset at 18 ms/frame from under-sampled k-space v/s time data sequentially acquired from multiple 2D slices. We evaluate this scheme on two speakers producing repeated speech tasks.
Purpose
Dynamic speech MRI is a powerful tool to characterize complex speech articulations. It has several application areas such as understanding language production, assessing speech pre, and post tongue cancer treatment [1]. Several 2D dynamic speech MRI protocols based on sparse sampling and constrained reconstruction have evolved [2-5]. These schemes can achieve high time resolutions of the order of (10-20 ms) to sequentially acquire multiple 2D slices. However, the complex articulatory motion is difficult to interpret jointly across the slices due to misalignment of motion patterns. In this work, we apply a novel generative manifold model [6-7] which reconstructs and generates a time aligned multi-slice 2D speech dataset at a high time resolution (of 18 ms) from under-sampled k-space v/s time data sequentially acquired from multiple 2D slices. We evaluate this scheme on two speakers producing repeated speech tasks, and compare it against a previous manifold regularization approach [5,8].Methods
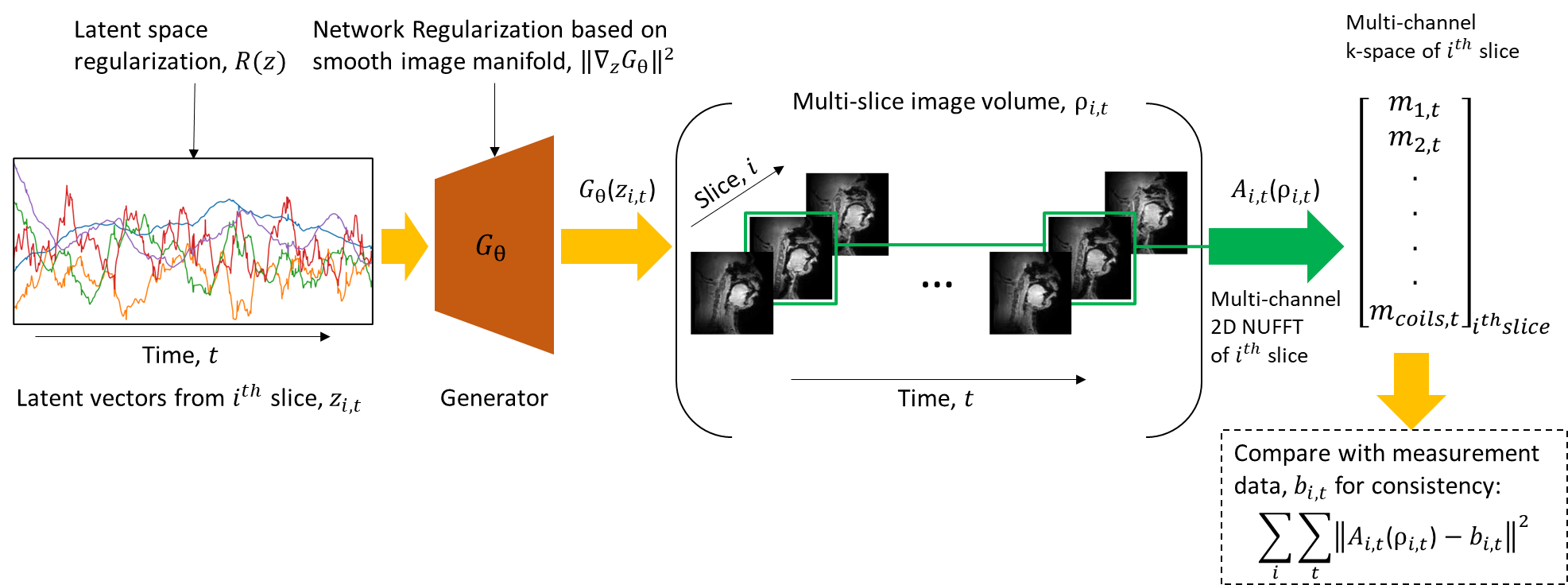
Acquisition: Experiments were performed on a 3T GE Premier scanner equipped with high performance gradients (80 mT/m amplitude and 150 mT/m/ms slew rate) using a 16 channel custom airway coil. A variable density spiral based gradient echo scheme with golden angle view ordering was used to sequentially acquire multiple 2D slices. Each slice was acquired for 16.2 secs, before moving to the next slice. Sequence parameters were: FOV: 20cmx20cm; spatial resolution: 2.4 mmx2.4 mm; flip angle: 5 degrees; TR= 6 ms; slice thickness= 6 mm; 27 spiral arms for Nyquist sampling; 335 readout points; readout duration =1.3 ms; 5 slices in the sagittal orientation).Reconstruction: Figure 1 depicts the proposed deep generative manifold method (aka generative-STORM) [6-7]. In the proposed model, the latent vectors of the $$$i^{th}$$$ slice $$${\boldsymbol{z}_{i,t}}$$$ are fed into the generator $$$G_{\theta}$$$. The output of the generator is 2D+time multi-slice image volume $$${\boldsymbol{\rho}_{i,t}}$$$ where i= 1,2,…,M is the slice number, and t is time. The forward operator $$${\boldsymbol{A}_{i,t}}$$$ extracts $$$i^{th}$$$ slice from the multi-slice image volume $$${\boldsymbol{\rho}_{i,t}}$$$ and performs multi-channel 2D NUFFT on the $$$i^{th}$$$ slice. The resulting network generated multichannel k-space data, $$${\boldsymbol{m}_{i,t}}$$$ from the $$$i^{th}$$$ slice is compared with the corresponding multichannel measurement data $$${\boldsymbol{b}_{i,t}}$$$ for data consistency. The assumption is that the images to be reconstructed lie as points on a smooth manifold surface. The finite gradient $$$\boldsymbol{\nabla}_{\boldsymbol{z}}G_{\theta}$$$ enforces the latent vectors to maintain the same neighborhood relationship as the corresponding neighborhood relationship of the point images on the manifold. Moreover, to ensure the latent vectors vary smoothly along time, we used a temporal smoothness penalty on the latent vectors. Finally, we jointly estimate the latent vectors $$${\boldsymbol{z}_{i,t}}$$$ of the multiple slices and the generator parameter θ by minimizing the cost function given by,
\begin{equation} \mathcal{C}(\boldsymbol{z},\theta)= \sum_{i=1}^{M} \sum_{t=1}^{N}\|\boldsymbol{A}_{i,t}(G_{\theta}[\boldsymbol{z}_{i,t}])-\boldsymbol{b}_{i,t}\|_{2}^{2} + \lambda_{1} \hspace{.05cm} \| \boldsymbol{\nabla}_{\boldsymbol{z}}G_{\theta} \|_{2}^{2} \hspace{.1cm}+ \lambda_{2}\| \boldsymbol{\nabla}_{t}\boldsymbol{z}_{i,t} \|_{2}^{2} \end{equation}
Where M and N are respectively the number of slices, and the number of time frames; and $$$G_{\theta}[\boldsymbol{z}_{i,t}]$$$ generates the time aligned multi-slice image time series $$${\boldsymbol{\rho}_{i,t}}$$$. Moreover, deep convolutional neural networks are known for their ability to provide implicit spatial regularization on the images.
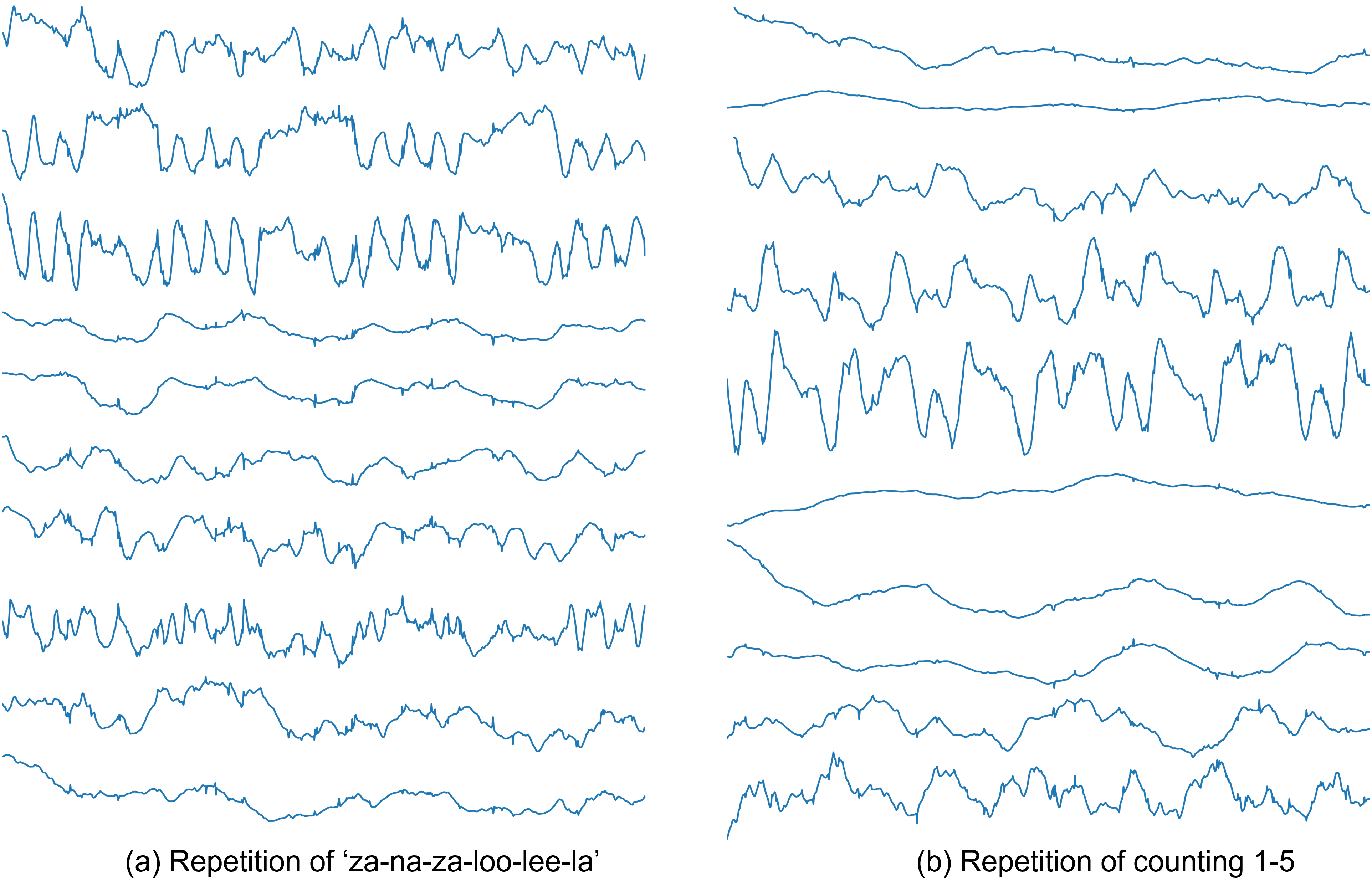
Experiments: we acquired data from two adult subjects performing two different tasks: a) repetition of the phrase ‘za-na-za-loo-lee-la’, and b) repeated counting of numbers from 1 to 5. Image reconstruction was performed using 3 spiral arms/frame which is equivalent to 18 ms temporal resolution using both the proposed deep generative manifold model, and the previous kernel based manifold regularization approach (aka l2-STORM) [5,8]. The proposed method simultaneously reconstructed all the five slices, while l2 STORM reconstructed the slices independently. We choose the dimension of latent vector space as 20 in order to effectively the model complex articulatory motion. The network was trained in two stages. In the first stage, only the generator is trained for 70 epochs keeping the latent vectors fixed, and in the second stage, we perform joint training of the generator as well as the latent vectors for about 250 epochs. The reconstruction image matrix size was 168x168.
Results
Figure 2 compares temporal profiles of l2 SToRM against the proposed deep generative manifold method for the task of repetition of the phrase ‘za-na-za-loo-lee-la’. Since the five slices were acquired sequentially, l2 SToRM reconstructions were naturally out of synchronization along time; while the generative manifold method produced time aligned slices, which is also evident from the yellow vertical lines. Moreover, temporal profiles of the generative manifold reconstructions are sharper with improved fidelity, and also improved artifact suppression compared to l2 SToRM. Figure 3 shows representative 10 of the 20 latent vectors for the two tasks. We observe quasiperiodic oscillations in most of the latent vectors in both tasks. The animations in figure 4 and figure 5 highlight the improved reconstruction quality and the time alignment of the slices in the deep generative manifold for the two speech tasks.Conclusion
We proposed a novel deep generative manifold model that jointly reconstructs sequentially acquired multiple 2D slices in dynamic speech MRI at 18 ms/frame. The reconstructions depict synchronized motion across slices, superior temporal fidelity and artifact suppression compared to previous l2-STORM. Future work includes leveraging additional spatial regularization, and concurrently acquired speech audio data, and adaptation to more speech tasks.Acknowledgements
This work was conducted on an MRI instrument funded by 1S10OD025025-01.
References
[1] Lingala, S. G., Sutton, B. P., Miquel, M. E., & Nayak, K. S. (2016). Recommendations for real‐time speech MRI. Journal of Magnetic Resonance Imaging, 43(1), 28-44.
[2] Lingala,
S. G., Zhu, Y., Kim, Y. C., Toutios, A., Narayanan, S., & Nayak, K. S.
(2017). A fast and flexible MRI system for the study of dynamic vocal tract
shaping. Magnetic resonance in medicine, 77(1),
112-125.
[3] Niebergall, A., Zhang, S., Kunay, E., Keydana, G., Job, M., Uecker, M., & Frahm, J. (2013). Real‐time MRI of speaking at a resolution of 33 ms: undersampled radial FLASH with nonlinear inverse reconstruction. Magnetic Resonance in Medicine, 69(2), 477-485.
[4] Fu, M., Zhao, B., Carignan, C., Shosted, R. K., Perry, J. L., Kuehn, D. P., ... & Sutton, B. P. (2015). High‐resolution dynamic speech imaging with joint low‐rank and sparsity constraints. Magnetic Resonance in Medicine, 73(5), 1820-1832.
[5] Rusho, R, Alam, W, Ahmed, A, Kruger, S, Jacob, M, Lingala, S.G, Rapid dynamic speech imaging at 3T using combination of a custom airway coil, variable density spirals, and manifold regularization", annual meeting of ISMRM, May 2021.
[6] Zou, Q., Ahmed, A. H., Nagpal, P., Priya, S., Schulte,
R., & Jacob, M. (2021). Variational manifold learning from incomplete data:
application to multislice dynamic MRI. IEEE Transactions on Medical Imaging, in
press.
[7] Zou, Q., Ahmed, A. H., Nagpal, P., Priya, S., Schulte, R., & Jacob, M., Alignment & joint recovery of multi-slice cine MRI data using deep generative manifold model. annual meeting of ISMRM, May 2021.
[8] Ahmed, A. H., Zhou, R., Yang, Y., Nagpal, P., Salerno, M., & Jacob, M. (2020). Free-breathing and ungated dynamic mri using navigator-less spiral storm. IEEE Transactions on Medical Imaging, 39(12), 3933-3943.
Figures