3480
Memory Efficient Model Based Reconstruction for Volumetric Non-Cartesian Acquisitions using Gradient Checkpointing and Blockwise Learning
Zachary Miller1 and Kevin Johnson1
1University of Wisconsin-Madison, Madison, WI, United States
1University of Wisconsin-Madison, Madison, WI, United States
Synopsis
The goal of this work is to reconstruct high resolution, volumetric non-cartesian acquisitions using model based deep learning. This is a challenging problem because unlike cartesian acquisitions and hybrid trajectories like stack of spirals that can be decoupled into 2D sub problems, fully non-cartesian trajectories require the complete 3D volume for data-consistency pushing GPU memory capacity to its limits even using cluster computing. Here, we investigate blockwise learning, a method that has the memory saving benefits of patch-based methods while maintaining data-consistency in k-space. We demonstrate the feasibility of this method by reconstructing high resolution pulmonary non-contrast and MRA acquisitions.
Introduction
Fully non-Cartesian (NC) acquisitions offer many benefits over Cartesian methods as they sample k-space in all dimensions and offer intrinsic motion robustness. For these reasons, NC sampling is being developed for free-breathing body acquisitions. However, the clinical adoption of these techniques is limited by lengthy reconstruction times, especially when using iterative constrained reconstructions (1).Model based Deep Learning (MBDL) offers a technique for fast NC reconstructions that can outperform iterative methods. MBDL has been primarily applied to 2D Cartesian sampling and has consistently been faster and outperformed compressed sensing (CS) reconstructions (2). These methods, however, have seen limited application to the volumetric NC setting due to GPU memory limitations. Unlike volumetric cartesian acquisitions and hybrid trajectories like stack of spirals that can be decoupled into 2D sub-problems, fully NC trajectories require the complete 3D volume for data-consistency. With MBDL that alternates between regularizer and data-consistency steps, this means that the entire 3D volume must be passed through the DL regularizer prior to data-consistency during training. For high resolution volumetric acquisitions, MBDL reconstructions that use standard neural network architectures like U-nets or Res-nets require hundreds of gigabytes of GPU RAM. This makes fully non-cartesian model based reconstruction difficult on even state of the art GPU clusters.
In this work, we investigate block-wise learning (BWL), a MBDL reconstruction method that makes these high resolution, NC reconstructions feasible on a single GPU. This method has the memory-saving benefits of patch-based methods during the neural network step while maintaining data-consistency in k-space.This makes volumetric, fully non-Cartesian reconstructions feasible using MBDL. As proof of concept, we apply BWL to reconstruction of highly undersampled (5000 spokes), 32-channel high resolution pulmonary UTE datasets using a single 40 GB A100 GPU.
Methods
Block-wise Learning Algorithm: Patch based methods are popular for neural network training in image-space because they significantly reduce GPU memory load. But in these techniques, data is divided into patches during pre-processing and the neural network is trained directly on these patches. The challenge for MBDL with 3D NC data is that this type of pre-processing block division is impossible because the full volume is needed for k-space data consistency.BWL gets around these issues by decomposing the input volume into a series of blocks, pushing each block iteratively through the denoising network, and then recomposing the denoised volume for data-consistency. Combined with gradient checkpointing (3) in place of traditional backpropagation, GPU memory burden then becomes proportional to user-selected block size rather than full volume. For a single unroll, the algorithm is as follows:
- Gradient Checkpoint Unroll: Classical backprop saves each intermediate step in memory so iterating through blocks results in no memory savings. Instead, gradient checkpointing recomputes intermediates during backprop meaning GPU memory is proportional to block size.
- Decomposition: Decompose Np x Np x Np zero-padded input volume into a series of m x n x o blocks. Pass these blocks through the NN. Memory reduction then relative to full volume is $$$(Np)^{3}/{mno}$$$
- Recomposition: Blocks are then stitched back together into full volume. Zero padding at block edges means that passing the volume block-wise through the network is not equivalent to passing the whole volume through the network. We correct for these artifacts by passing a second set of blocks through the network with each new block centered at the edges of the original blocks. We then replace the edge artifacts with the center of denoised new blocks.
- Data Consistency: The denoised, corrected volume is then passed to a (NUFFT) data-consistency step
Training Data/Evaluation: We acquired 32-channel radial, pulmonary MRA volumes in eleven healthy volunteers during free breathing on a 3.0 T GE (Waukesha, WI) scanner. Data sets were coil compressed to 20 channels. We used the closest fifty thousand spokes to end-expiration based on respiratory bellows signal for supervision. To generate training data, we retrospectively undersampled along the spoke dimension to 5000 spokes. Five cases were used for training, one case was used for validation, and five cases were used for testing. We compared decomposition-recomposition to L1 wavelet CS reconstruction (sigpy, A100 GPU) based on reconstruction time and SSIM for pulmonary magnetic resonance angiography acquisitions (4). We tested model’s ability to generalize to breath held non-contrast lung acquisitions. Such breath held acquisitions could potentially be used for applications from placental imaging to rapid radiation free pulmonary embolism diagnosis
Results
MBDL with BWL reduces reconstruction time by 64 fold and results in improved SSIM when compared to CS methods (.94 vs .89) when reconstructing pulmonary MRA data (figure 2, table 3). Further, the model is able to generalize to significantly higher resolution, non-contrast data (figure 4).Conclusions
We demonstrate a method that allows for MBDL to reconstruct volumetric NC acquisitions. By both speeding up and improving reconstruction quality, this method may make these acquisitions easier to integrate into clinical workflows.Acknowledgements
NIH R01 HL136964, NIH R01 CA190298, and research support from GE HealthcareReferences
- Ong, Frank, Martin Uecker, and Michael Lustig. "Accelerating non-Cartesian MRI reconstruction convergence using k-space preconditioning." IEEE transactions on medical imaging 39.5 (2019): 1646-1654.
- Aggarwal, Hemant K., Merry P. Mani, and Mathews Jacob. "MoDL: Model-based deep learning architecture for inverse problems." IEEE transactions on medical imaging 38.2 (2018): 394-405.
- Sohoni, Nimit Sharad, et al. "Low-memory neural network training: A technical report." arXiv preprint arXiv:1904.10631 (2019).
- Ong, Frank, and Michael Lustig. "SigPy: a python package for high performance iterative reconstruction." Proceedings of the International Society of Magnetic Resonance in Medicine, Montréal, QC 4819 (2019).
Figures
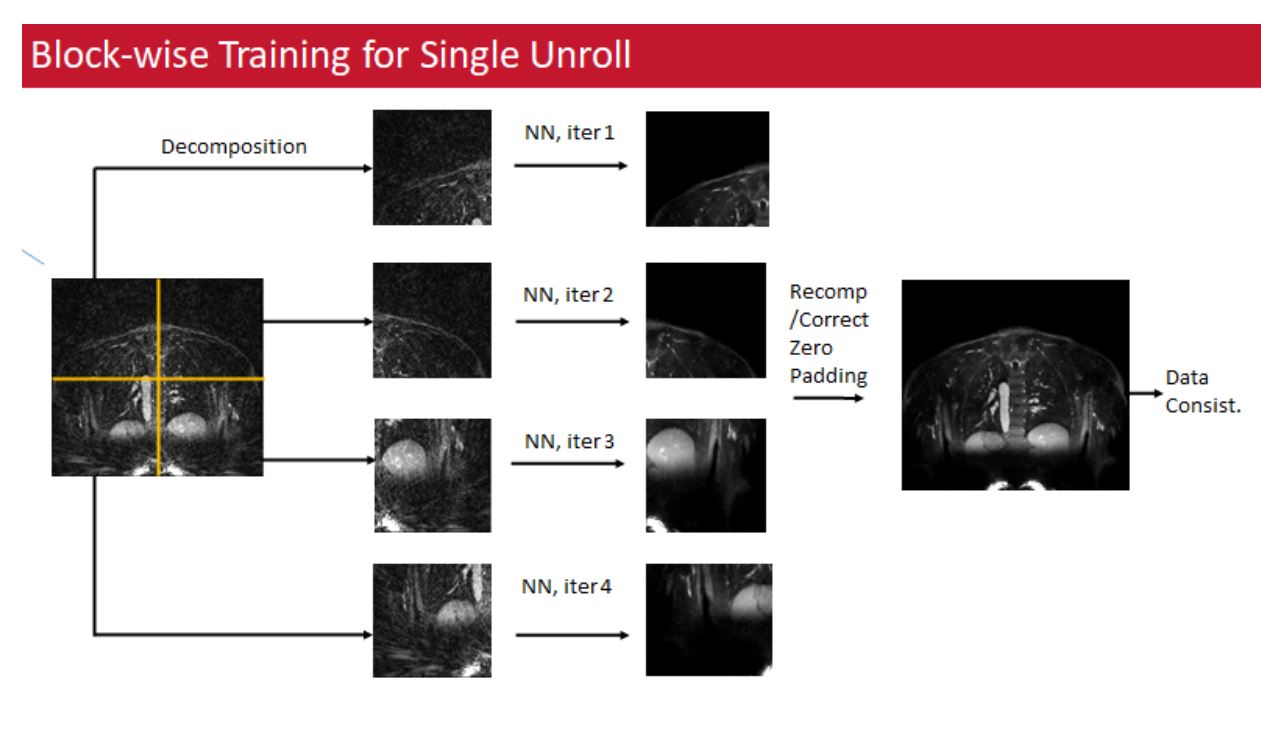
Single Unroll of Model-based DL using Blockwise learning: The incoming volume is decomposed into blocks (size selected by user) that are then iteratively passed through the neural network, recomposed into the full volume, padding errors at block edges are corrected, and then the full volume is passed to the data-consistency step. This method can be applied at each unroll, and the entire model can be trained end to end. For simplicity, we depict blockwise learning in 2D in the figure above.
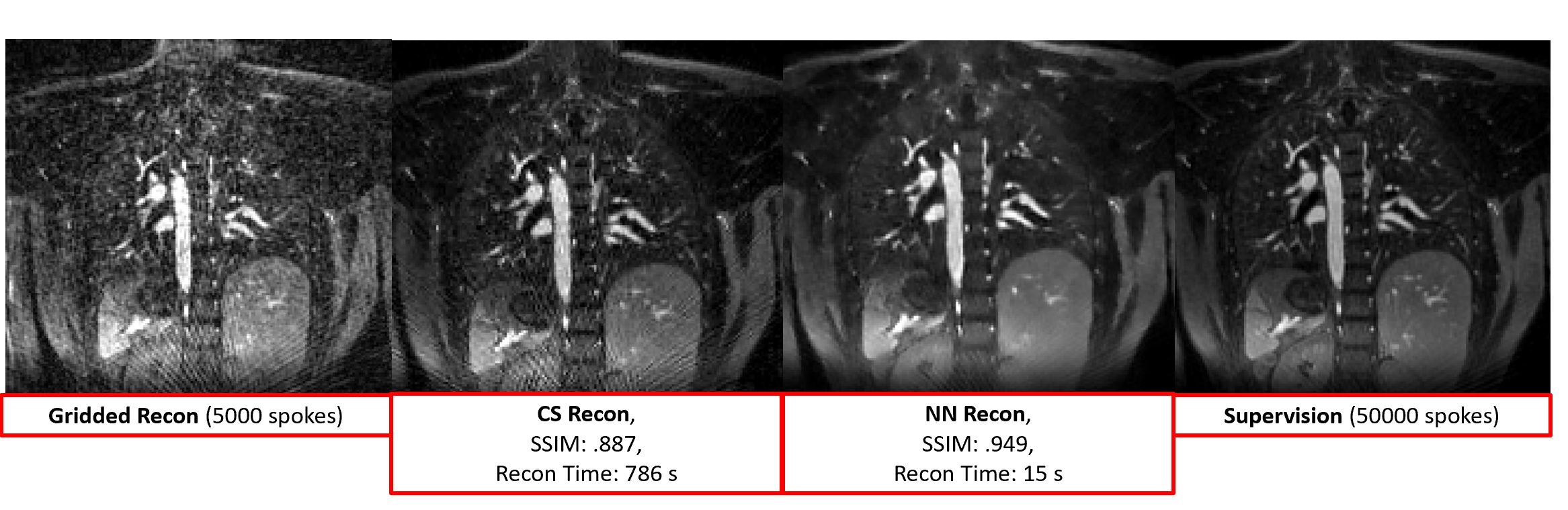
Example Reconstructions: Here we compare reconstruction quality between gridded, compressed sensing, NN block-wise learning and supervised data on a test case with matrix size: 268 x 118 x 279. The NN blockwise learning reconstruction has reduced undersampling artifact relative to the CS reconstruction while preserving fine features seen in the supervised image.
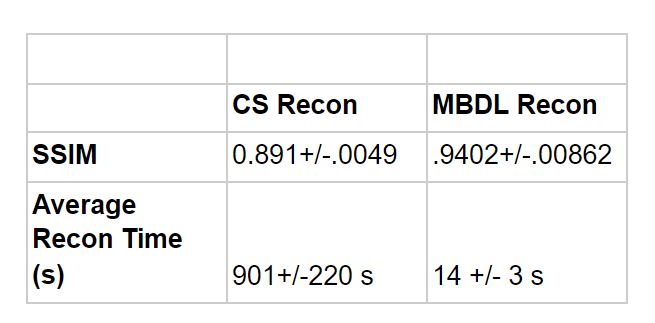
Table comparing quantitative reconstruction quality and reconstruction speed for CS vs. MBDL Recons across test cases (N=5): We calculated averaged reconstruction quality using structural similarity metric (SSIM). Reconstruction speed was compared on the same A100 GPU.
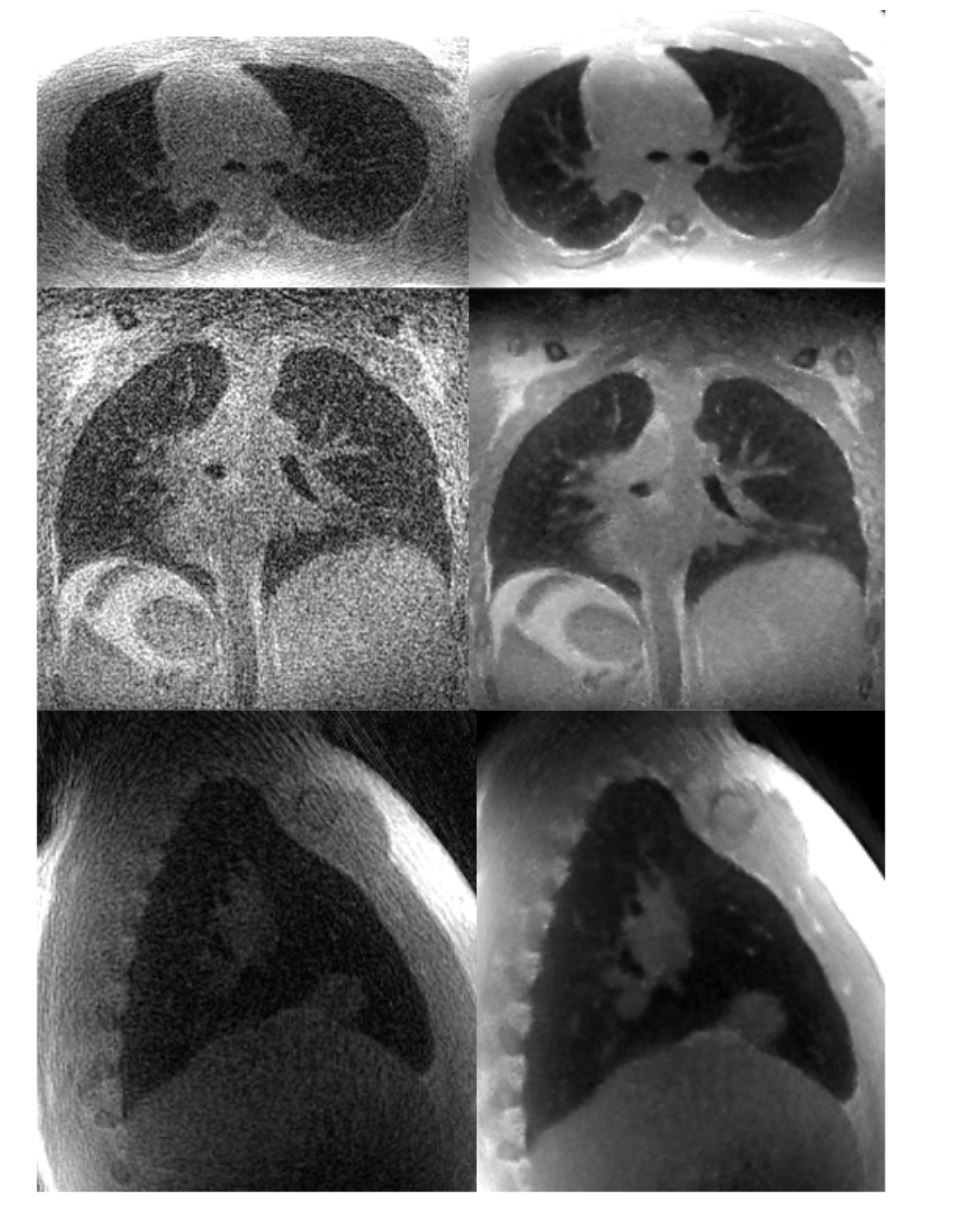
Breath Held Reconstruction (15 s of scan time): During inference, we reconstruct a breath held non-contrast radial acquisition with near 1 mm spatial resolution, matrix size: 512 x 496 x 496. We note that this acquisition varied significantly both in terms of contrast and resolution from the training data. The MBDL output (right) is significantly less noisy, and recovers bronchial branching and other parenchymal details. We note this reconstruction took 129 seconds.
DOI: https://doi.org/10.58530/2022/3480