3460
Using deep learning to generate missing anatomical imaging contrasts required for lesion segmentation in patients with glioma.1University of California San Francisco, San Francisco, CA, United States, 2Johnson & Johnson, San Francisco, CA, United States
Synopsis
Missing value imputation is an important concept in statistical analyses. We utilized conditional GAN based deep learning models to learn missing contrasts in MR images. We trained two deep learning models (FSE to FLAIR and T1 post GAD to T1 pre-GAD) for MR image conversion for missing value imputation. The model performances are evaluated by visual examination and comparing SSIM values. We observed that these models can learn the output contrast.
Introduction
The majority of deep learning models for glioma segmentation rely on four image contrasts (T2-weigthed, T2-FLAIR, and T1-weighted images pre- and post- injection of gadolinium-based contrast agent) in order to segment the contrast-enhancing, necrotic, and T2-hyperintensity regions of these tumors. Radiomics and multi-parametric intensity based analyses of these images also typically require all four image contrasts to achieve higher accuracy predictions of mutational status, subgrouping, and grading within molecular subtypes. However, especially in retrospective larger datasets that are used in training of these models and span multiple institutions over time, one or more of these sequences are often either missing, acquired in a different orientation or at a lower resolution, or are corrupted by motion, prohibiting their use as inputs to these models. Since high resolution, 3D T2-weighted fast spin echo (FSE) and T1-weighted post-contrast images are required for surgery, the goal of this study is to used deep learning with general adversarial networks (GANs) [1] to generate synthetic T2-FLAIR and pre-contrast T1-weighted images from T2-FSE and post-contrast T1-weighted images, respectively.Methods
Data: 416 patients about to undergo surgical resection for a glioma who had high quality 3D T2-FLAIR, T2-FSE, T1-weighted pre-contrast, and T1-weighted post-contrast images were utilized in this study. 265 scans were used in training, 67 of the scans for validation ,and 84 of the scans for testing the network performance. Each split contained an equal percentage of different glioma subtypes, grades, and presence of contrast enhancement.Network Structure: A 2D conditional GAN (cGAN) with pix2pix based architecture that maps an input image to an output image was utilized [2]. In a GAN architecture, a generator and a discriminator are trained simultaneously, whereby the generator tries to generate output images indistinguishable by the discriminator and the discriminator tries to distinguish the synthetic and real output modality image (Figure 1). ResNet [3] blocks were used to build generator model and a PatchGAN Model [2] was used in discriminator model.
Hyperparameter Tuning: Bayesian optimization was implemented for hyperparameter tuning of batch size, number of batch samples, learning rate, L1 loss coefficient, and lesion mask loss coefficient. Lesion mask loss was defined as mean absolute error between tumor masked target and masked predicted images and allowed for false predictions in the tumor area to be penalized more heavily than the rest of the image. The hyperparameter values that yielded the maximum mean Structural Similarity Index (SSIM) between predicted and original target images in the validation set were used in subsequent model training and evaluation.
Model Training & Evaluation: The models were trained using Adam optimizer and with adversarial loss, L1 loss, and lesion mask loss. We trained two different models for each image conversion task after selecting the best hyperparameters with Bayesian optimization; one with lesion mass loss, the other without. Each network was trained for 5000 iterations. Model performance was evaluated by visual inspection and comparing SSIM values between the predicted and real images.
Results and Discussion
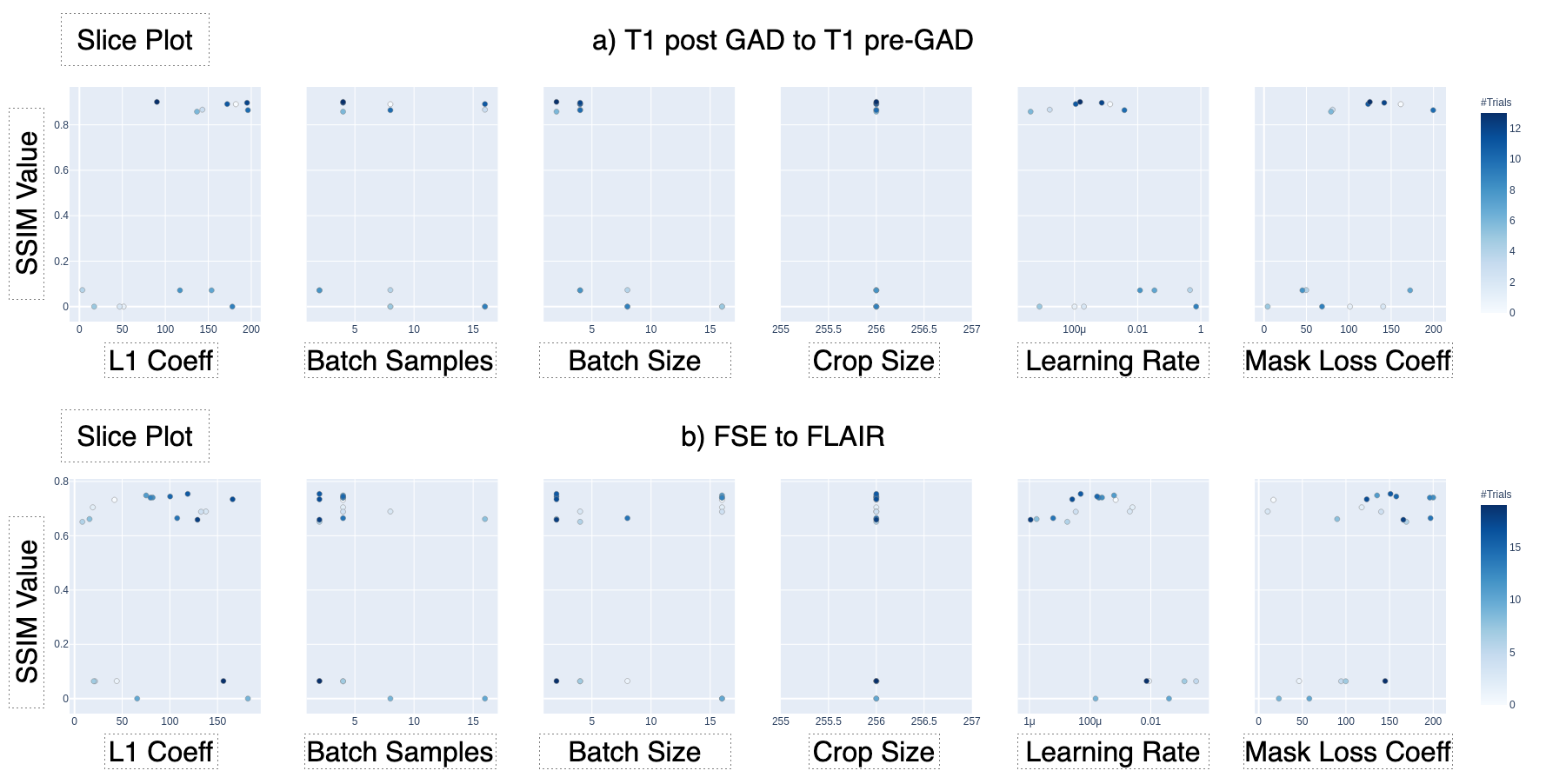
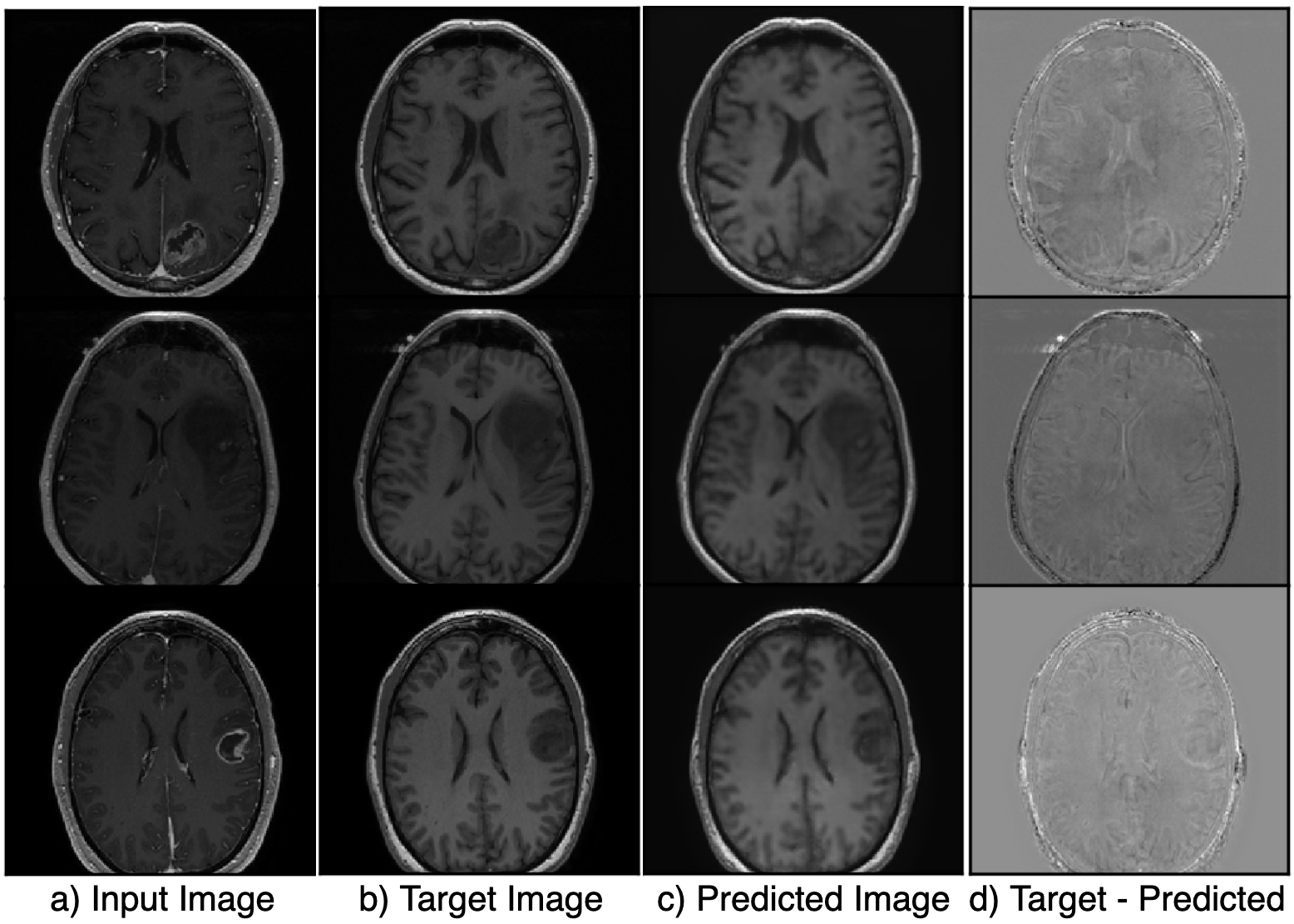
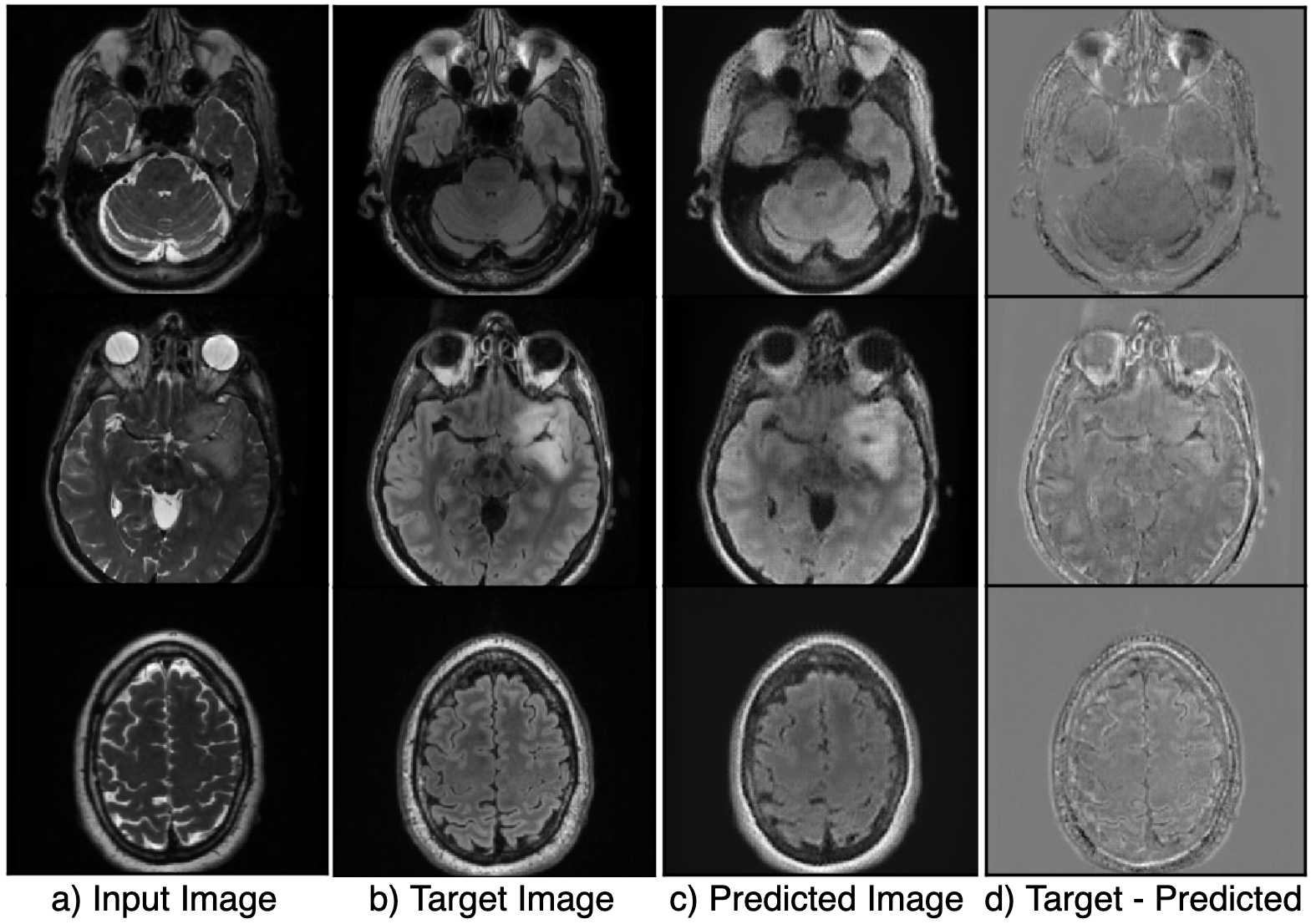
Figure 2 shows the results of the hyperparameter optimization, for T1 post-contrast to T1 pre-contrast image generation; (learning rate=0.000149, batch size=2, batch samples=4, L1 loss coefficient=90.24, mask loss coefficient=124.85) and for FSE to FLAIR image conversion (learning rate= 0.0000487, batch size=2, batch samples=2, L1 loss coefficient=118.74, mask loss coefficient=151.04).Figures 3 and 4 demonstrate the overall similarity between target and predicted images, although slight blurring is present in the predicted images. The post- to pre-contrast T1-weighted imaging network was able to correctly remove the presence of contrast enhancement within contrast-enhancing lesions (Figure 3, top and bottom rows), while simultaneously maintaining hypo-intense signal intensity of non-enhancing lesions (Figure 3; middle row).
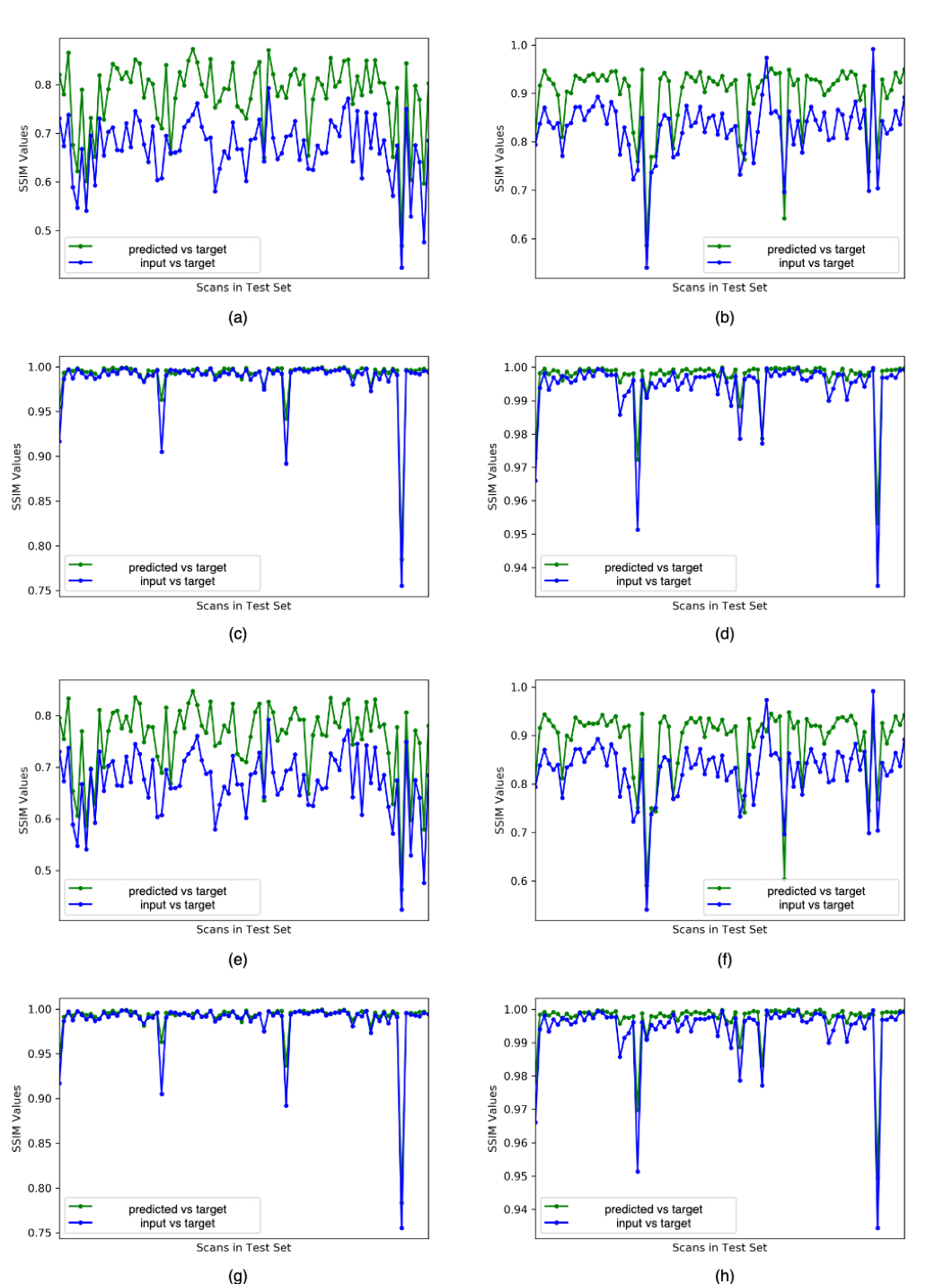
Overall image SSIM values for predicted vs target images were higher than the SSIM values between input vs target images for most of the scans (Figure 5), with mean SSIM of predicted image of 0.89 for the T1-weighted imaging model and 0.78 for the T2-weighted FSE to FLAIR model when a lesion mask loss function was employed. Although overall SSIM did not change with the addition of a lesion mask loss function, within the tumor lesion, which is the most relevant for segmentation and quantification of missing values, mean SSIM between target and predicted T2 FLAIR and T1 pre-contrast images was significantly increased to 0.990/0.991 and 0.994/0.986, respectively (with/without mask loss).
Conclusion
In conclusion, we trained two different models for image synthesis of missing anatomical image contrasts in patients with gliomas and demonstrated similar contrasts to the acquired images within the tumor lesion. Ongoing work is incorporating task-based validation based on accuracy of the resulting lesion segmentations.Acknowledgements
This research was supported by NIH grant P01CA118816.References
[1] I Goodfellow, J Pouget-Abadie, M Mirza Generative adversarial nets, Advances in neural information processing systems, 2014.
[2] P Isola, JY Zhu, T Zhou, AA Efros, Image-to-image translation with conditional adversarial networks, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
[3] K He, X Zhang, S Ren, J Sun, Deep residual learning for image recognition - Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
Figures