3459
Unsupervised Domain Adaptation for Neural Network Enhanced Turbo Spin Echo Imaging1Philips Research North America, Seattle, WA, United States, 2Philips Research Hamburg, Hamburg, Germany, 3Vascular Imaging Lab, University of Washington, Seattle, WA, United States
Synopsis
Supervised learning is widely used for deep learning based image quality enhancement for improved clinical diagnosis. However, the difficulties to acquire a large number of high-quality reference image for different MR applications can limit its generalization performance. An unsupervised domain adaptation (DA) approach is proposed and incorporated into the deep learning based image enhancement framework, which improves the performance of trained network on new datasets. Preliminary evaluation on point spread function enhanced turbo spin echo imaging has showed that the unsupervised DA approach can provide more stabilized image sharpness improvement without severe amplified noise.
Introduction
Deep learning based image enhancement techniques can retrospectively improve the image quality for better clinical diagnosis1. Typically, supervised learning with paired low- and high-quality images is used to train such neural network (NN) for image enhancement. Due to inter-scan motion, pixel-level misalignment between the two separate low-quality fast scan and high-quality scan raises challenges for this supervised learning framework. Given the high-quality image, simulation based image synthesis approach can be used to generate the co-registered low-quality image. However, the simulated noise pattern can be difficult to align with the realistic noise statistics particularly when fast imaging is applied, leading to deteriorated generalization performance of the trained NN. In addition, acquisition of a large number of high-quality reference images for the specific MR scans can be challenging due to the occurrence of motion in a prolonged scan. In this work, we leverage a domain adaptation (DA) approach2,3 to train a NN for enhanced 3D turbo spin echo (TSE) imaging4 by using a few sample low-quality 3D TSE images and some publicly available high-quality images, and we investigated whether DA can synthesize more realistic noise patterns and whether the trained NN with DA has more stabilized point spread function (PSF) enhancement performance for 3D TSE imaging in comparison to the trained NN without DA.Methods
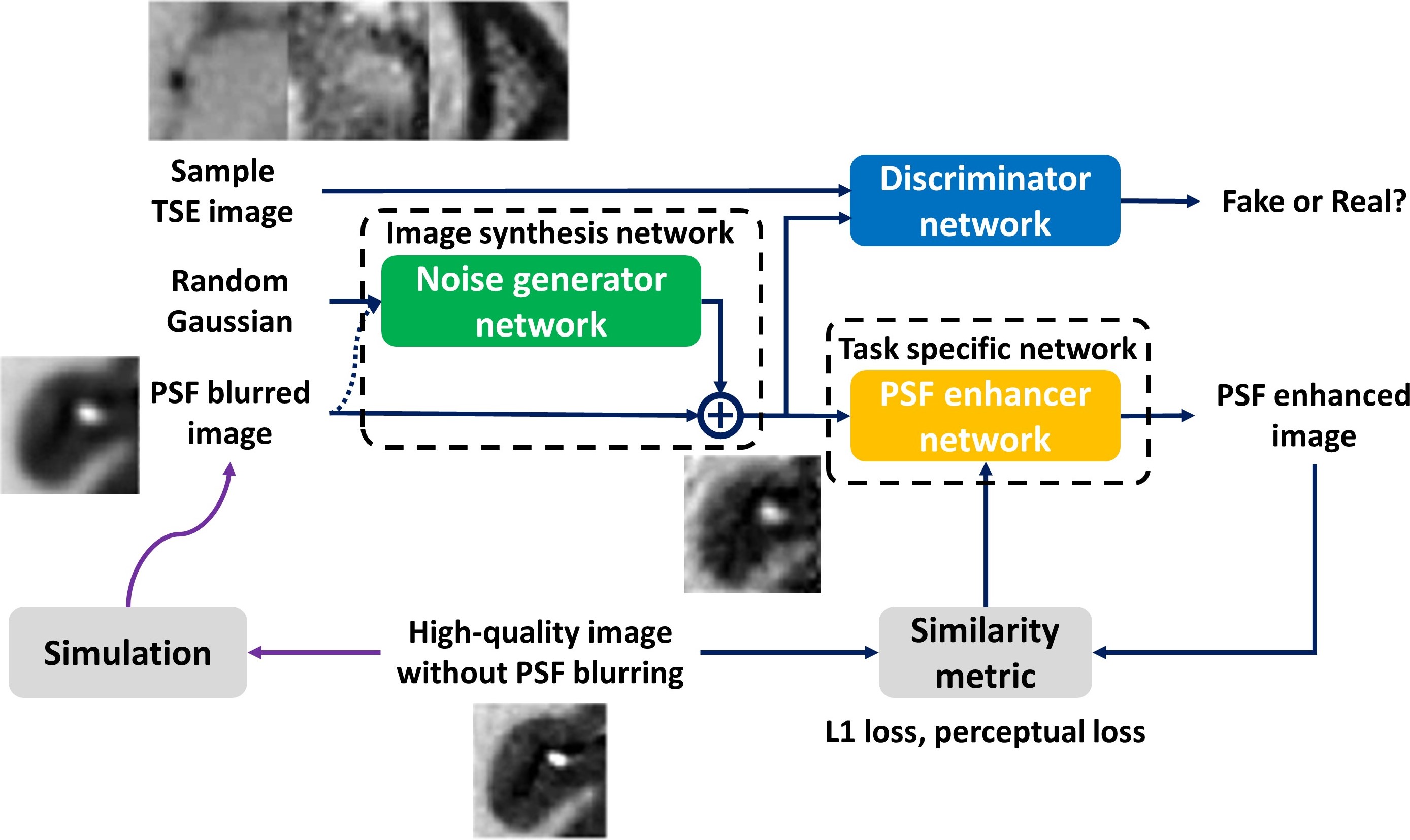
Network ArchitecturesFigure 1 shows the overall DA network structure for PSF enhanced 3D TSE image. The image synthesis network aims to generate noise patterns similar to the sample TSE image, where the similarity is measured by a discriminator network. To mitigate synthesis of new image structures, we enforced the output of image synthesis network to be unbiased or zero-mean. Likewise, the discriminator network mainly evaluates whether the synthesized noise pattern is similar to the distribution in the sample TSE images. Therefore, mean removal was applied to the input image patches of the discriminator network before measuring the similarity. The synthesized low-quality image and high-quality image were paired to train the task specific network for PSF enhanced TSE image (i.e. improve image sharpness without noise amplification). Since the high-quality 3D TSE images are not required to train the PSF enhancement NN, this DA approach is considered as unsupervised training.
Training and Loss Functions
All three networks were trained simultaneously in an end-to-end manner, where the adversarial loss was applied to train the image synthesis and discriminator networks. To further control the relative magnitude of synthesized noise pattern, a L2 loss on the output of noise generator network was also applied and empirically weighted against the adversarial loss. The pixel-level L1 loss and feature-level perceptual VGG loss were applied to train the task specific network.
MR Datasets
A publicly available high-resolution brain dataset5 was downloaded to train the DA network and evaluate its performance for PSF enhanced TSE image, which includes 2D T2* gradient echo (0.12x0.12x0.6mm3), 3D MPRAGE (isotropic 0.44mm) and 3D TOF (isotropic 0.2mm) images acquired at Siemens 7T from one subject. 3D TSE images were acquired on a Philips 3T scanner with 6-fold acceleration on 3 healthy subjects, where 2 cases were used to generate sample low-quality image patches during training and the other 1 was used for testing.
Results
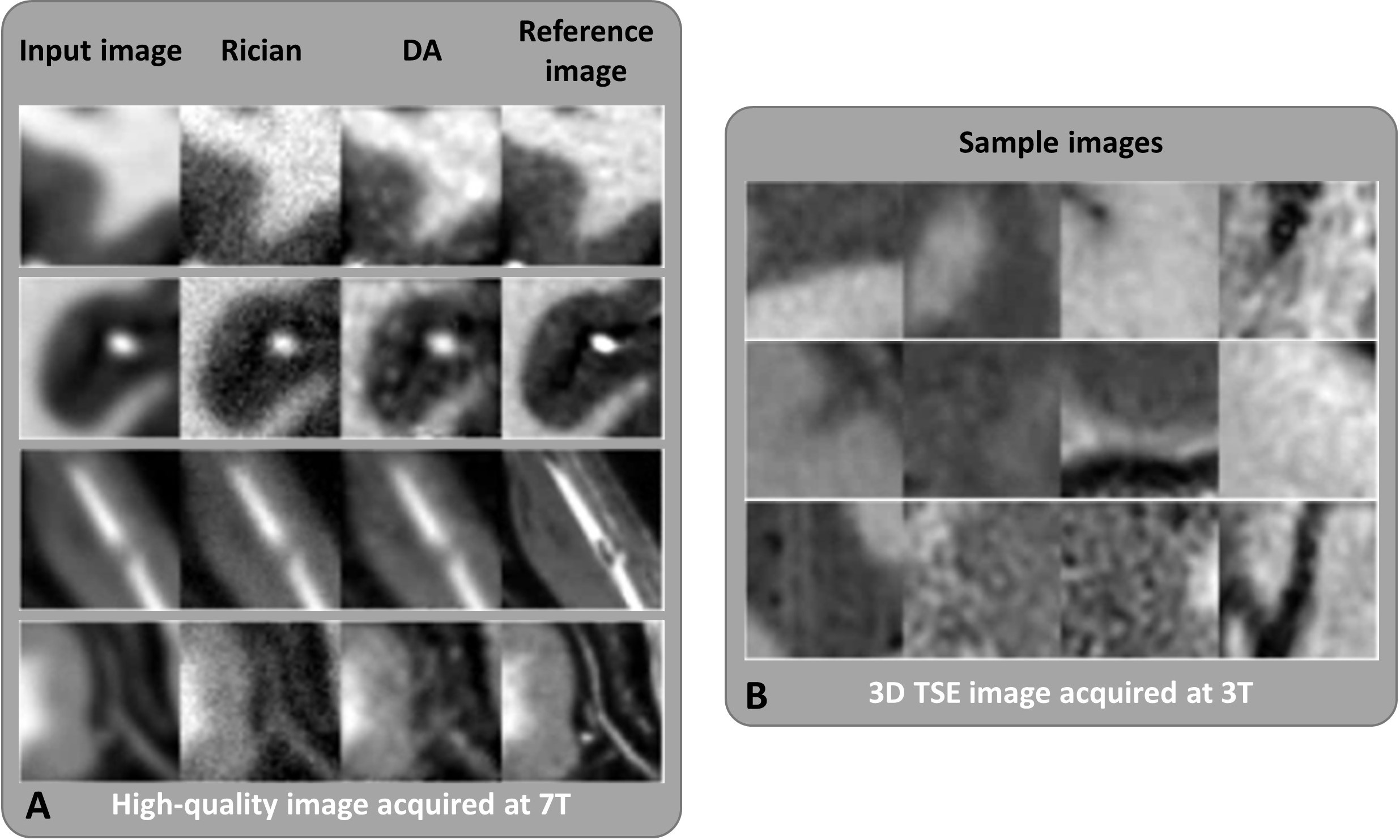
Comparison of synthesized imagesFigure 2 shows the comparison of synthesized image patches using the high-quality images with two different approaches. Comparing to the sample patches from the 3D TSE image (Fig.2 B), the proposed DA approach can synthesize more similar noise patterns compared to the traditional approach by simply adding Rician noise onto the input image. Therefore, the DA approach allows synthesis of a training dataset with spatially variant noise pattern which is much closer to the acquired low-quality 3D TSE image with imaging acceleration.
Comparison of PSF enhanced images
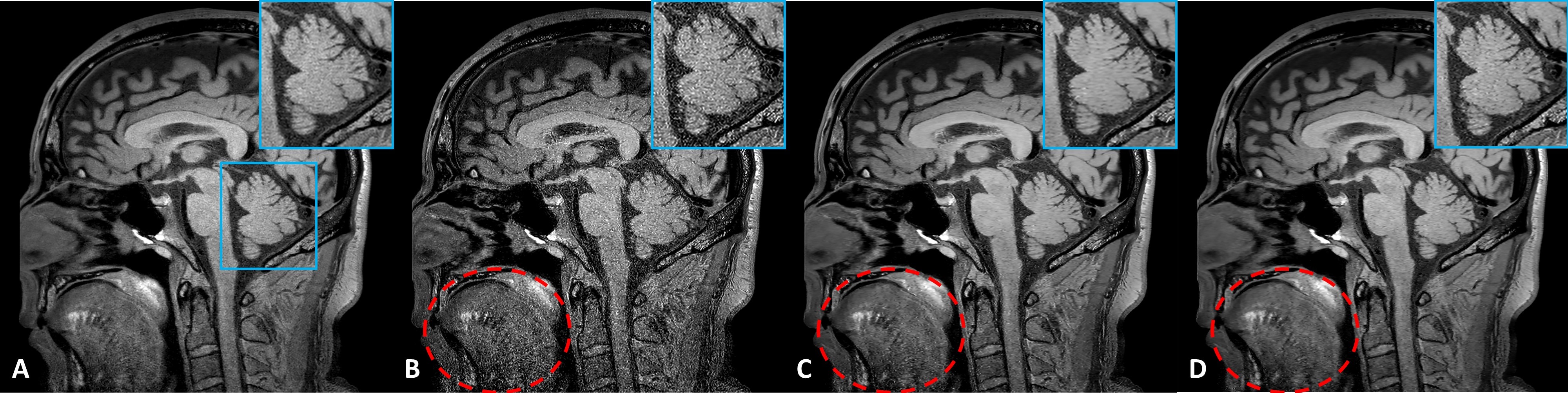
Figure 3 (B)-(D) compare the performance of PSF enhanced images from the acquired 3D TSE image with T1/T2 relaxometry induced blurring (A). NN trained on the Rician noise corrupted blurring images (without DA approach) can result in severe noise amplification during PSF enhancement (B). Fine-tuning on such training dataset can help to reduce such noise amplification (C), but the sharp boundary restoration (e.g. small structure in cerebellum region) and background noise suppression might be difficult to be well balanced. The proposed DA approach (D) provides more stable performance for PSF enhanced results without severe noise amplification while demonstrating improved noise suppression in relatively uniform regions (dotted circle in red). This DA approach provides a more automatic fine-tuning strategy to better adapt the NN performance to the new test data.
Discussion and Conclusion
Given a few low-quality images acquired with the targeted fast MR scan, the proposed DA approach provides an unsupervised learning framework to leverage publicly available high-quality data for synthesis of training dataset that can approximate the noise/artifact pattern in the targeted scan for improved image enhancement. This framework can be useful for image enhancement tasks when the high-quality images are difficult to acquire for supervised learning. Initial evaluation on PSF enhanced TSE imaging has showed that the DA approach can adaptively stabilize the image sharpness improvement without severe amplified noise.Acknowledgements
No acknowledgement found.References
1. Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, van der Laak JAWM, van Ginneken B, Sánchez CI. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42:60-88.
2. Ganin Y, Lempitsky V. Unsupervised domain adaptation by backpropagation. In International conference on machine learning 2015, pp. 1180-1189.
3. Bousmalis K, Silberman N, Dohan D, Erhan D, Krishnan D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition 2017, pp. 3722-3731.
4. Zhou Z, Chen S, Balu N, Chu B, Zhao X, Sun J, Mossa-Basha M, Hatsukami T, Börnert P, Yuan C. Neural network enhanced 3D turbo spin echo for MR intracranial vessel wall imaging. Magn Reson Imaging. 2021 May;78:7-17. doi: 10.1016/j.mri.2021.01.004. Epub 2021 Feb 4. PMID: 33548457; PMCID: PMC7979503.
5. Stucht D, Danishad K, Schulze P, Godenschweger F, Zaitsev M, Speck O. Highest Resolution In Vivo Human Brain MRI Using Prospective Motion Correction. PLoS One. 2015;10(7):e0133921.
Figures