3449
Adversarial Non-local Multi-modality MRI Aggregation for Directional DWI Synthesis1Dept. of Radiology, MGH and Harvard Medical School, Boston, MA, United States
Synopsis
Diffusion MRI is sensitive to subject motion, and with prolonged acquisition time, it suffers from motion corruption and artifacts. To address this, we present an adversarial non-local network-based multi-modality MRI fusion framework for directional DWI synthesis. Our framework is based on a generative model conditioned on a specified b-vector sampled in q-space, where it efficiently fuses information from multiple structural MRIs, including T1- and T2-weighted MRI, and B0 image, with an adaptive attention scheme. Experimental results, using a total of ten q-ball data, show its potential to synthesize high-fidelity DWIs at arbitrary q-space coordinates and facilitate quantification of diffusion parameters.
Introduction
Diffusion MRI (dMRI) plays an essential role in the estimation of neural connectivity and in vivo microstructure characterization in a non-invasive manner [1,2]. dMRI provides a variety of biomarkers for the diagnosis of brain disorders. dMRI data, however, are susceptible to subject motion and suffer from various artifacts, partly due to long acquisition time, leading to corruption of diffusion-weighted imaging (DWI) data.This work is aimed at correcting such corrupted DWIs via an adversarial non-local deep learning framework that is conditioned on q-space for directional DWI synthesis. Specifically, given structural MRIs, including T1- and T2-weighted MRI, and a non-diffusion weighted B0 image, our framework takes as input arbitrary combinations of structural MRIs and B0 image as well as specified b-vectors sampled in q-space to yield high-fidelity DWIs at arbitrary q-space coordinates.
Method
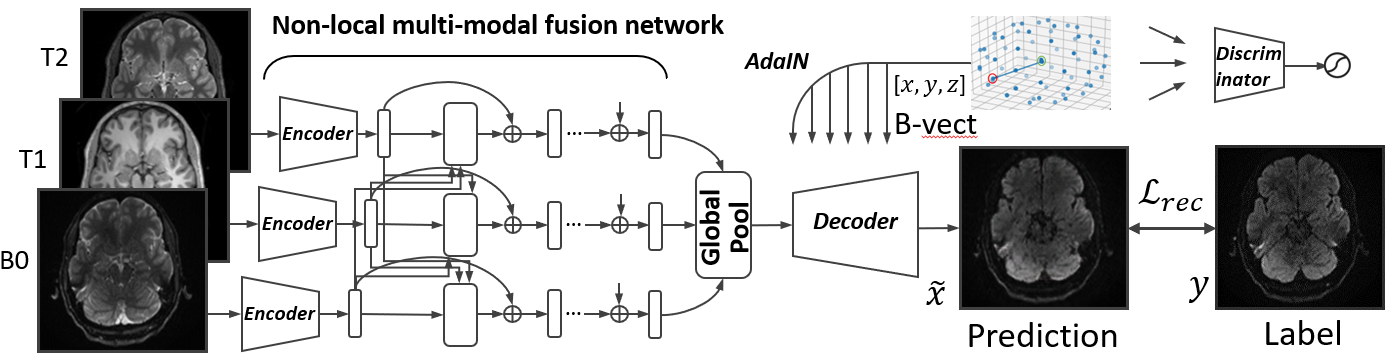
Given input data $x=\{B0,T1,T2\}$, and a target b-vector, we aim to synthesize the corresponding DWI associated with the b-vector, which is considered an inverse problem in the generative model. The b-vector is a unit vector for each shell, which provides the three-dimensional coordinate in q-space.Our adversarial non-local directional DWI synthesis framework is comprised of three modules, including (1) a non-local attention encoder for an arbitrary number of multi-modality aggregation; (2) a b-vector conditioned decoder with adaptive instance normalization (AdaIN) [3] for directional DWI synthesis; and (3) a discriminator for adversarial training to enrich the details of the synthesized DWI.
At the training stage, our non-local encoder network takes as input three 2D slices of the co-acquired and registered T1-, T2-weighted MRI, and B0 image. Instead of simply concatenating these modalities as a multi-channel sample [4], we process each of them with a shared fully convolutional network to extract features for each modality. Then, we exploit spatial-aware multi-modality correlations with a non-local attention scheme [5]. Each feature vector in a particular location interacts with another in all modalities to adaptively learn the aggregation signal. Since the added operation used in non-local blocks is essentially permutation invariant, the input can be arbitrary numbers (one to many) of images of the available co-acquired structure MRIs in random sequence [6]. We note that the input and output sizes of our non-local aggregation module are the same.
The adaptively learned features are aggregated with the global pooling layer [5]. After the information of multiple modalities is aggregated, the decoder is applied to generate the directional DWI conditioned on a b-vector. We also adopt AdaIN [3] after each convolution layer, similar to the prior work [5]. AdaIN injects a strong inductive bias of the b-vector into the decoder to indicate the to-be generated direction in q-space.
The generated DWIs are then compared against the ground truth dataset to calculate the L1 loss to supervise the training. In addition, adversarial training is added to further enrich realism of the synthesized DWI, as in [4]. The discriminator takes as input either generated DWIs or samples from real DWIs along with their corresponding B0, T1- and T2-weighted MR slices and predicts whether the input is real or generated. The overall network structure is detailed in Fig. 2. With the trained model, we are able to sample an arbitrary b-vector in a user-defined manner to correct for corrupted DWIs.
Results
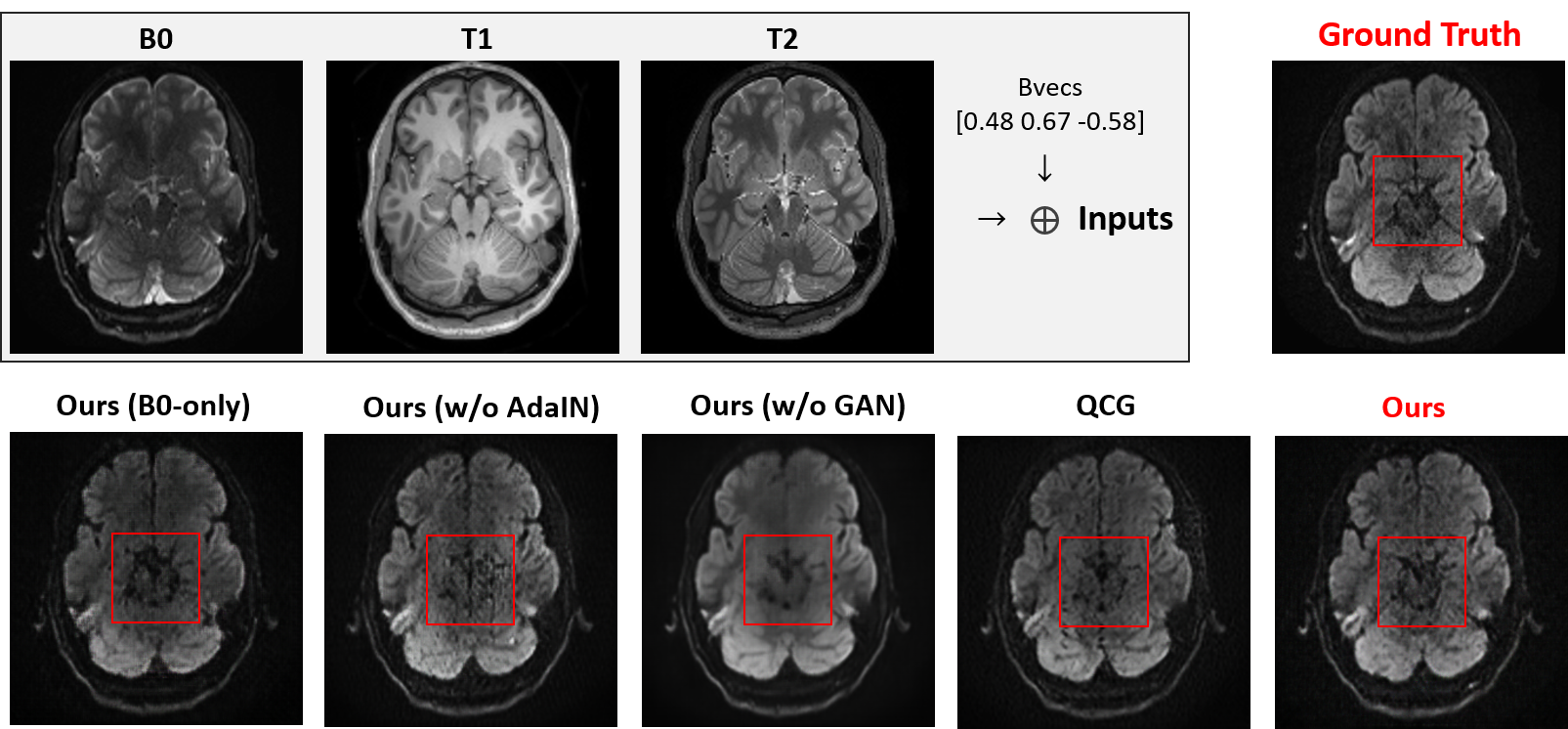
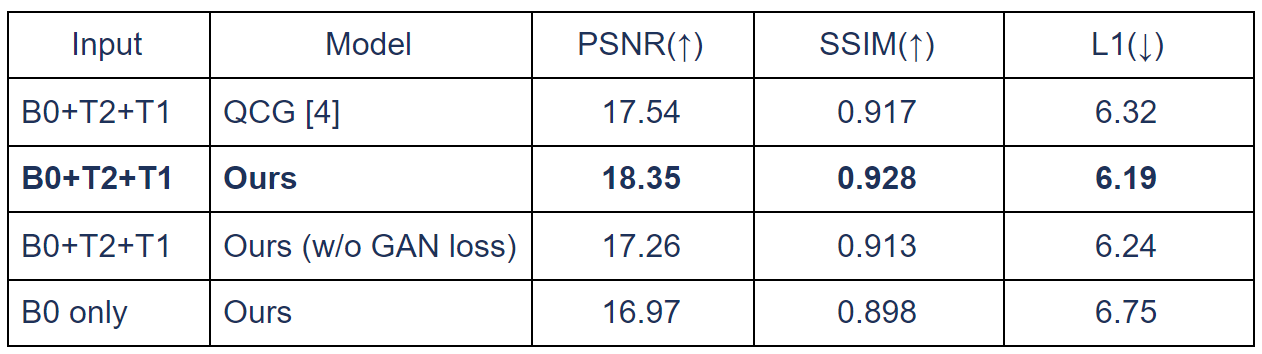
We evaluated the performance of our framework on the MGH Adult Diffusion Data acquired from healthy adults between the ages of 20 and 59 [7]. A total of eight and two subjects were used for training and testing, respectively. For each subject, both T1- and T2-weighted MRI were registered to the B0 image, and DWIs with a b-value of 1000 sec/mm2 were used in our experiments.Fig. 4 shows the quantitative comparison of the generated results of our framework and QCG [4]. With the non-local attention encoder, we were able to better maintain the anatomical structures, which is important for the subsequent analysis. In addition, we provided ablation studies w.r.t. the GAN loss and AdaIN. Without the GAN loss, the generated DWIs tend to be blurry, without retaining detailed textures. AdaIN can also yield better conditional DWI synthesis results than a prior concatenation approach. As shown in Fig. 5, we quantitatively evaluated the performance w.r.t. peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and L1 reconstruction loss. Our model outperformed QCG [4] consistently.
Discussion and Conclusion
This work presented an adversarial non-local multi-modality MRI fusion framework for DWI synthesis. To the best of our knowledge, this is the first attempt at exploring multi-modality correlations with a non-local model, generating DWIs with arbitrary combinations of structural MRIs and B0 images in a unified framework. In contrast with QCG, we exploited the global pixel-wise correlation, which is robust to potential misalignments between structural MRIs. Promising qualitative and quantitative results were achieved, thus showing the potential for our framework to be used for correcting corrupted DWIs or to achieve high angular resolution from lower angular resolution data. In our future work, we will further demonstrate its utility by quantifying scalar microstructure indices estimated from the synthesized images.Acknowledgements
This work was supported by NIH R01DC018511 and P41EB022544.References
[1] Wedeen, V.J., Rosene, D.L., Wang, R., Dai, G., Mortazavi, F., Hagmann, P., Kaas, J.H. and Tseng, W.Y.I., 2012. The geometric structure of the brain fiber pathways. Science, 335(6076), pp.1628-1634.
[2] Skudlarski, P., Jagannathan, K., Calhoun, V.D., Hampson, M., Skudlarska, B.A. and Pearlson, G., 2008. Measuring brain connectivity: diffusion tensor imaging validates resting state temporal correlations. Neuroimage, 43(3), pp.554-561.
[3] Huang, X. and Belongie, S., 2017. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (pp. 1501-1510).
[4] Ren, M., Kim, H., Dey, N. and Gerig, G., 2021, September. Q-space Conditioned Translation Networks for Directional Synthesis of Diffusion Weighted Images from Multi-modal Structural MRI. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 530-540). Springer, Cham.
[5] Liu, X., Che, T., Lu, Y., Yang, C., Li, S. and You, J., 2020. Auto3d: Novel view synthesis through unsupervisely learned variational viewpoint and global 3d representation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16 (pp. 52-71). Springer International Publishing.
[6] Liu, X., Guo, Z., Li, S., Kong, L., Jia, P., You, J. and Kumar, B.V.K., 2019. Permutation-invariant feature restructuring for correlation-aware image set-based recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4986-4996).
[7] Fan Q, Witzel T, Nummenmaa A, Van Dijk KR, Van Horn JD, Drews MK, Somerville LH, Sheridan MA, Santillana RM, Snyder J, Hedden T, Shaw EE, Hollinshead MO, Renvall V, Zanzonico R, Keil B, Cauley S, Polimeni JR, Tisdall D, Buckner RL, Wedeen VJ, Wald LL, Toga AW, Rosen BR. MGH-USC Human Connectome Project datasets with ultra-high b-value diffusion MRI. Neuroimage 2016;124(Pt B):1108-1114.
Figures