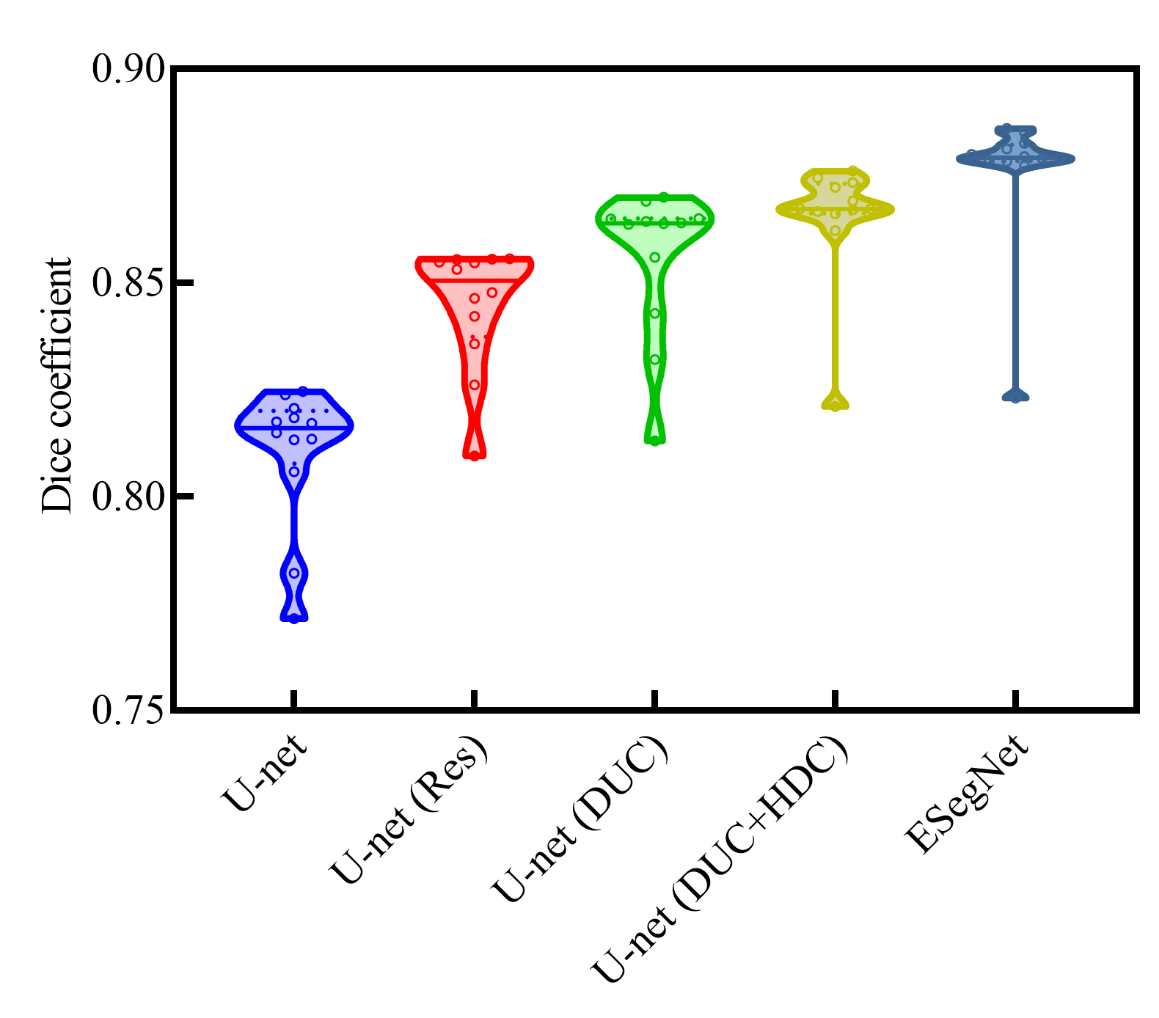3204
A Semantic Segmentation Method with Emphasizing Edge information for Automatic Vessel Wall Analysis1Faculty of Information Technology, Beijing University of Technology, Beijing, China, 2Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, Shenzhen, China, 3Department of Radiology, Peking university shenzhen hospital, Shenzhen, China, 4United Imaging Healthcare, Shanghai, China
Synopsis
Edge information is essential for medical image analysis, especially for image segmentation. This paper aims to develop a precise semantic segmentation method with emphasizing the edges for automated segmentation of arterial vessel wall and plaque based on the convolutional neural network (CNN) for facilitating the quantitative assessment of plaque in patients with ischemic stroke. An end-to-end architecture network that can emphasize the edge information is proposed. The results suggest that the proposed segmentation method improves segmentation accuracy effectively and will facilitate the quantitative assessment on atherosclerosis.
INTRODUCTION
One of the potential important applications of quantitative morphologic and signal measurements of the arterial vessel wall and plaques based on magnetic resonance vessel wall imaging (MRVWI) is to monitor intracranial atherosclerotic disease progression and regression [1]. Quantitative morphologic measurements require segmentation of arterial vessel wall [2]. However, the manual segmentation method is inefficient and costly and heavily depends on expert knowledge and experience. Therefore, a fast and precise computer-aided automatic segmentation method is potentially needed. However, the color, texture, and shapes are processed together in previous CNN approaches. The diverse type of information related to recognition may conduct unsatisfying results. Disentangling the edge information from the fused features is essential for improving the performance of the CNN architecture. In this work, we proposed a two-stream deep network architecture entitled EVSegNet, which emphasizes the use of edge information in vessel wall segmentation.METHODS
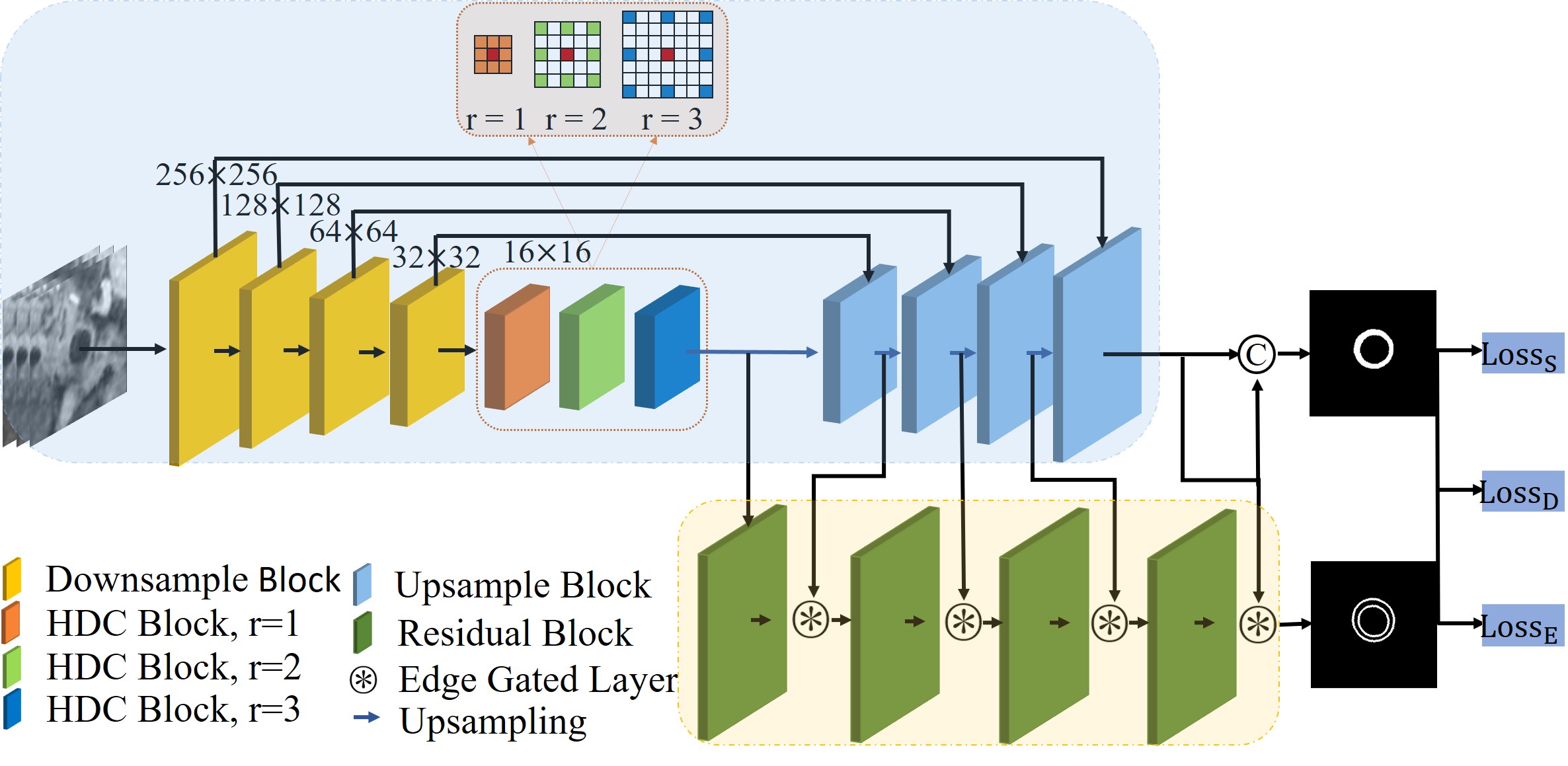
MRVWI images were acquired from 124 patients with the atherosclerotic disease on a 3-Tesla whole-body MR (uMR780, United Imaging Healthcare, Shanghai, China). The 2D slices reconstructed from the acquired MRVWI images were used for training (8377 slices), validation (4189 slices), and testing (1396 slices). A convolution network with highlighting edge information (EVSegNet) was proposed for arterial vessel wall and plaque segmentation. The architecture of EVSegNet is illustrated in Figure 1. It consists of a regular stream and an edge stream. Regular stream is an encoder-decoder architecture to process texture information. In the encoder, it combines a hybrid dilated convolution (HDC) [3] module which can effectively solve the information loss and precision reduction problem caused by the holes in dilated convolution kernels. In the decoder, we introduced a Dense Upsampling Convolution (DUC) [4] module to replace traditional bilinear interpolation upsampling which can capture and compensate for the fine-detailed information which is commonly missed in the bilinear interpolation operation to generate a dense pixel-wise prediction map and further final prediction. In the edge stream, we introduced a gated convolution layer (GCL), which is capable of filtering irrelevant information and focusing on partial information by providing a selection mechanism. In order to justify the effectiveness of the principal components of our network, i.e., DUC, HDC, and edge stream in the proposed EVSegNet. The ablation analysis was provided, the U-net was compared in the testing dataset with approaches involving additional components including Resnet, DUC, HDC, edge stream for further evaluations. The Dice, Recall, Precision, and Accuracy were calculated as evaluation metrics.RESULTS
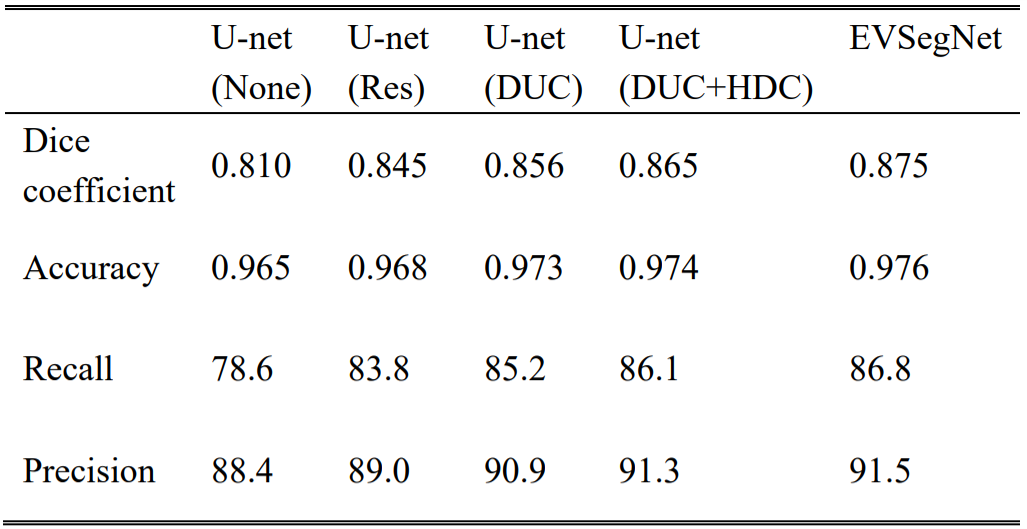
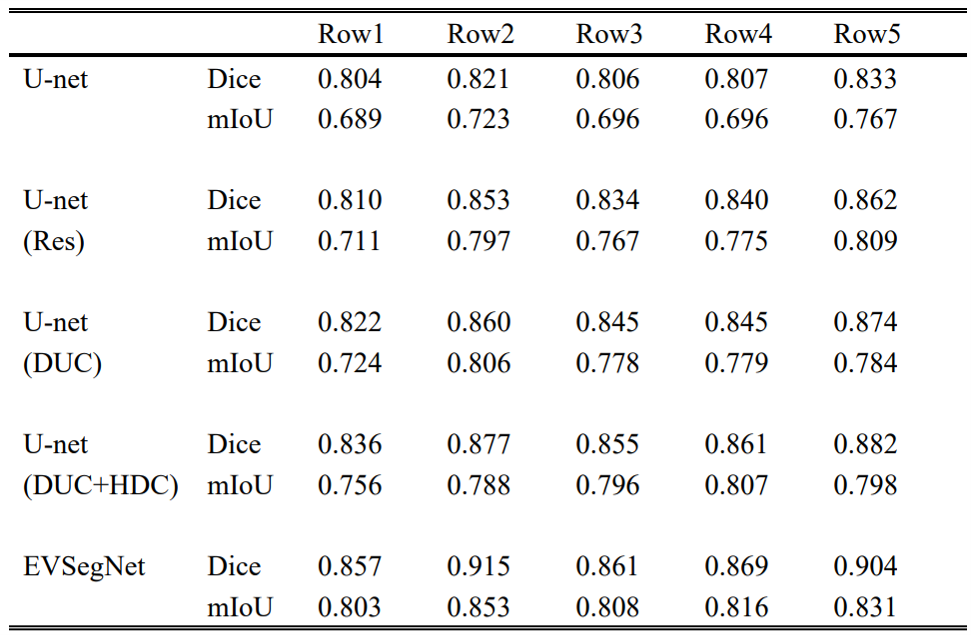
The segmentation results of different backbone architecture, including U-net (None), U-net (Res), U-net (DUC), U-net (DUC+HDC), and EVSegNet, on the same dataset are illustrated in Table 1. The baseline U-net achieved a Dice coefficient of 0.810 for the vessel wall segmentation and the performance kept improving when successively adding Resnet, DUC, HDC, and edgestream modules. As a result, the finalized network in this study for vessel wall segmentation included DUC, HDC, and edgestream modules. Compared to the other backbone architectures, the proposed network achieved the highest Dice, accuracy, most stable recall, and precision scores. Figure 2 shows the violin plot of the segmentation performance of U-net (Res), U-net (DUC), U-net (DUC+ HDC), and EVSegNet. the wider violin shape regions represent more aggregated values than those in the narrower zones. EVSegNet aggregates places with values larger than those aggregated by other methods. The representative segmentation results of the five different backbone architectures are shown in Figure 3 and the corresponding Dice (%) and mIoU (%) are summarized in Table 2. The segmentation results of EVSegNet are visually comparable to the ground truth for the depiction of vessel wall.DISCUSSION
In this study, we evaluated the EVSegNet through ablation study by adding Resnet, DUC, HDC, edge stream block for vessel wall segmentation. As can be seen from Figure 3 and Table 2, the EVSegNet achieved superior quantitative results than the other methods for the segmentation of the small size vessel walls in rows 1, 3, and 4, and overcomes discontinuous and large segmentation deviation cause by other Unet based networks. This proves our method has effectively learned the multiscale boundaries. More careful observation suggests that adding the edge stream as an auxiliary output for the vessel wall segmentation task is vital for improving the accuracy. The use of a subnetwork of edge stream before doing the segmentation is beneficial, this approach improves the shape accuracy of the resulting segmentation. Particularly, our edge stream does not require additional annotation, since edge information can be generated from the ground truth segmentation masks. It means that adding the edge module as prior knowledge into our method can further improve the segmentation accuracy by generating refined boundaries. Therefore, it improves the segmentation quality surrounding the edge, which results in the overall achieved better segmentation performance, our results are most consistent with ground truths.CONCLUSION
The proposed fully automatic vessel wall segmentation method which emphasizes the edges information can improve the segmentation accuracy by utilizing edge gated layers and combined with DUC and HDC modules. This will facilitate more accurate quantitative morphologic and signal measurements of arterial vessel wall and plaque.Acknowledgements
The study was partially supported by the National Natural Science Foundation of China (81830056), Key Laboratory for Magnetic Resonance and Multimodality Imaging of Guangdong Province (2020B1212060051), Shenzhen Basic Research Program (JCYJ20180302145700745 and KCXFZ202002011010360), and Guangdong Innovation Platform of Translational Research for Cerebrovascular Diseases.References
[1] Cogswell P M , Lants S K , Davis L T , et al. Vessel wall and lumen characteristics with age in healthy participants using 3T intracranial vessel wall magnetic resonance imaging[J]. Journal of Magnetic Resonance Imaging, 2019.
[2] Zhang N , Fan Z , Deng Z , et al. 3D whole-brain vessel wall cardiovascular magnetic resonance imaging: a study on the reliability in the quantification of intracranial vessel dimensions[J]. Journal of Cardiovascular Magnetic Resonance, 2018, 20(1):39-.
[3] Fang Y , Li Y , Tu X , et al. Face completion with Hybrid Dilated Convolution[J]. Signal Processing Image Communication, 2019, 80:115664.
[4] Wang P , Chen P , Yuan Y , et al. Understanding Convolution for Semantic Segmentation[C]// 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2018.
Figures