3194
Toward Universal Tumor Segmentation on Diffusion-Weighted MRI: Transfer Learning from Cervical Cancer to All Uterine Malignancies
Yu-Chun Lin1, Yenpo Lin1, Yen-Ling Huang1, Chih-Yi Ho1, and Gigin Lin1,2
1Department of Medical Imaging and Intervention, Chang Gung Memorial Hospital at Linkou, Chang Gung Memorial Hospital, Taoyuan, Taiwan, 2Clinical Metabolomics Core Laboratory, Chang Gung Memorial Hospital at Linkou, Taoyuan, Taiwan
1Department of Medical Imaging and Intervention, Chang Gung Memorial Hospital at Linkou, Chang Gung Memorial Hospital, Taoyuan, Taiwan, 2Clinical Metabolomics Core Laboratory, Chang Gung Memorial Hospital at Linkou, Taoyuan, Taiwan
Synopsis
This study retrospectively analyzed diffusion-weighted MRI in 320 patients with malignant uterine tumors (UT). A pretrained model was established for cervical cancer dataset. Transfer learning (TL) experiments were performed by adjusting fine-tuning layers and proportions of training data sizes. When using up to 50% of the training data, the TL models outperformed all the models. When the full dataset was used, the aggregated model exhibited the best performance, while the UT-only model exhibited the best in the UT dataset. TL of tumor segmentation on diffusion-weighted MRI for all uterine malignancy is feasible with limited case number.
Purpose
Deep convolutional neural networks have potential to automate the labor-intensive tumor segmentation on magnetic resonance (MR) imaging. However, building a model requires large training data which is challenging for a broad clinical application. The purpose of the study is to investigate how transfer learning (TL) can generalize accurate tumor segmentation from cervical cancer to all malignant uterine tumors (UT).Methods
This study retrospectively analyzed diffusion-weighted MRI in 320 patients with UT. The sagittal DW images and the corresponded ADC maps of each slice were used as input sources for training and testing. Regions of interest (ROIs) of tumor contours were delineated by the consensus of two gynecologic radiologist. The labeled ROIs were used as the ground truth for the model training.The pretrained model was established using DeepLab V3+ [2] for CX dataset (n = 144).For the TL experiment, we performed three combinations of model training and prediction: (a) UT-only model: training the model from scratch by using the UT dataset without TL from CX model; (b) TL model: Using the pretrained CX model and fine-tuning of certain layers based on the UT dataset; and (c) using the pretrained model of CX to apply directly to the UT dataset. To investigate the effect of freezing/tuning layers on TL performance, we examined three levels as the cutoff layers on the TL model. The layers before the identified layer were frozen, whereas those after that were fine-tuned based on the target domain data (Figure 1).
To assess the influence of data size on training performance, we examined different training data sizes through splitting the training dataset randomly with 2%, 5%, 10%, 20%, 50%, and 100% of patients. The various sizes of patient groups were used as datasets for training the UT-only model and TL models. An independent dataset (n = 64) was used for testing the performance of each group. An aggregated model was trained using the combined CX and UT datasets. The model performance was evaluated using the dice similarity coefficient (DSC) in independent datasets comprising UT (n = 64) and CX (n = 25).
Results
Figure 2 shows the performance of TL in various training combinations and under various sample sizes from the UT dataset. When applying the pretrained CX model directly to UT dataset, the DSC appeared to be the lowest of 0.30 (95% confidence interval [CI], 0.25–0.34). The DSC increased as the training data size of UT patient increased. The TL models with the fine-tuning level at L1 exhibited the highest DSCs compared with those at L2 and L3 (P < 0.05 for all data size subgroups). When the data size was small (<128, 50%), the TL model with the fine-tune level at L1 outperformed the UT-only model (P < 0.001 for sample sizes 5, 13, 26, and 51). However, as more data of the target dataset were used, the performance of the UT-only model increased. With the data size of 128, the DSC is not significantly different between the UT-only model and TL model of L1 level (DSC = 0.70 and 0.69, respectively, P = 0.12). With the full training size of 256 patients, the UT-only model exhibited the highest DSC of 0.79 (95% CI, 0.77–0.81) among all the combinations of training regardless of which TL model was used (DSC = 0.71, 0.67, and 0.63 for L1, L2, and L3 levels, respectively. P < 0.001).Figure 3 demonstrates a patient with endometrial cancer where tumor contours were generated using various training models and sample sizes. The pretrained CX model itself when not fine-tuned using UT data generated only a small part of the tumor with DSC = 0.18. The accuracy increased as more UT data were used for fine-tuning. The TL model outperformed the UT-only model when the fine-tuned data size was <128. The UT-only model exhibited the highest DSC of 0.92 when all patient data were used (n = 256).
Conclusions
The TL of tumor segmentation using diffusion MRI is feasible from cervical cancer to all uterine malignancies. The CX data can serve as the pretrained model that can be adopted to the target domain of uterine malignancy. The TL approach is advantageous when the data size of the target domain is limited. However, if large amounts of data are available and can be annotated, training from scratch using the target dataset appears to be a better option for specific disease. The aggregated model provides a potential universal solution for segmenting all uterine malignancies.Acknowledgements
This study was funded by Ministry of Science and Technology, Taiwan (grant no.: MOST 109-2628-B-182A-007 and MOST 109-2314-B-182A-045) and Chang Gung Medical Foundation grant CLRPG3K0021, CMRPG3J1631, CMRPG3I0141, and SMRPG3K0051. Chang Gung IRB 201702080A0C601, 201702204B0 and 201902082B0C601.References
- esion Segmentation, in Medical Image Computing and Computer Assisted Intervention − MICCAI 2017. 2017. p. 516-524.2.
- Chen, L.-C., et al. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv e-prints, 2018.
Figures
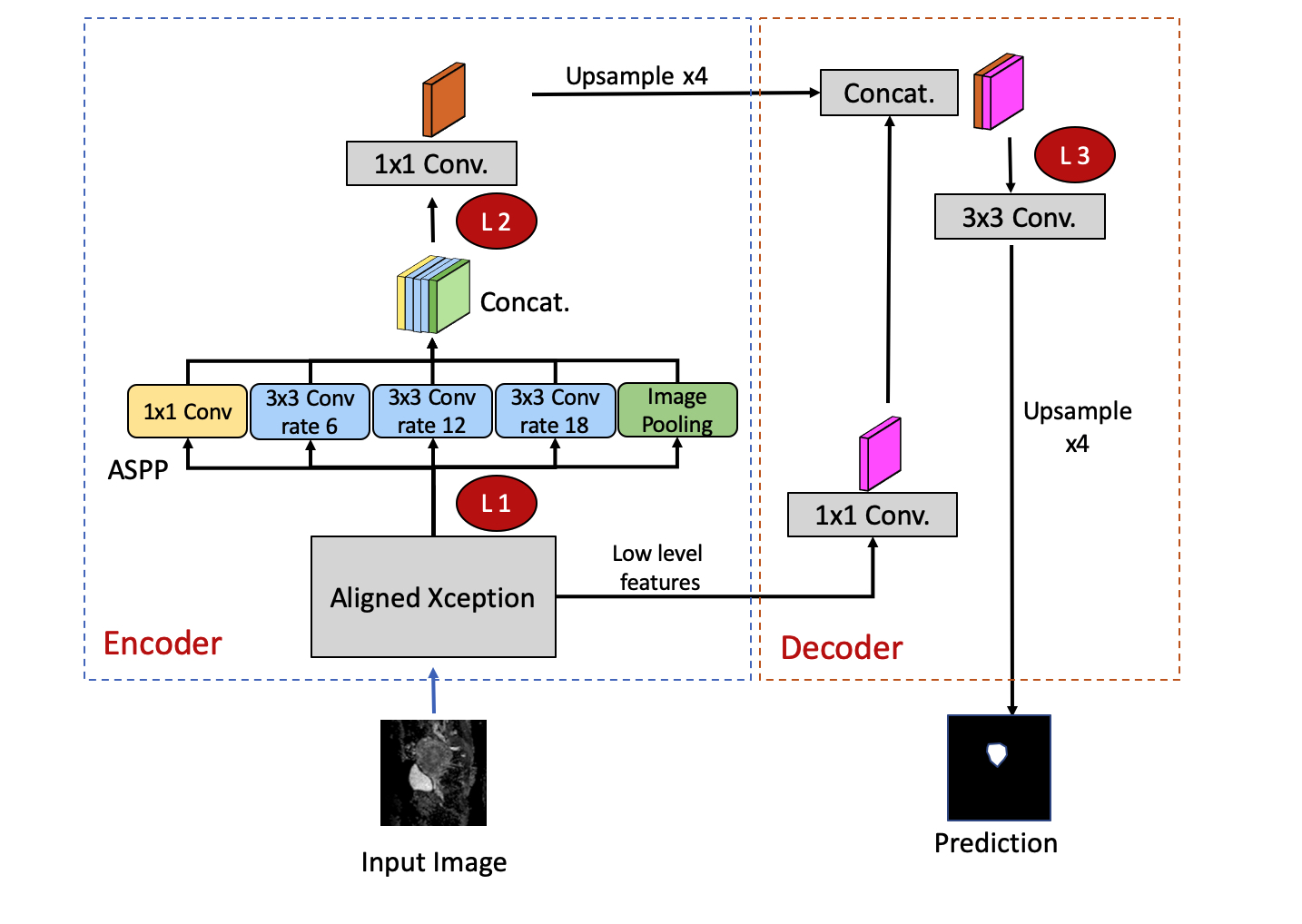
Figure 1: The DeepLab V3+ network architecture in the experiment. The red circle with annotations of L1, L2, and L3 denote the cutoff levels in which the previous layers are frozen, whereas the following layers are fine-tuned based on the target dataset. L1: an early layer in the encoder following the Xception model. L2: a deep layer following the ASPP at the end of the decoder. L3: the layer at decoder initiation. ASPP: Atrous Spatial Pyramid Pooling.
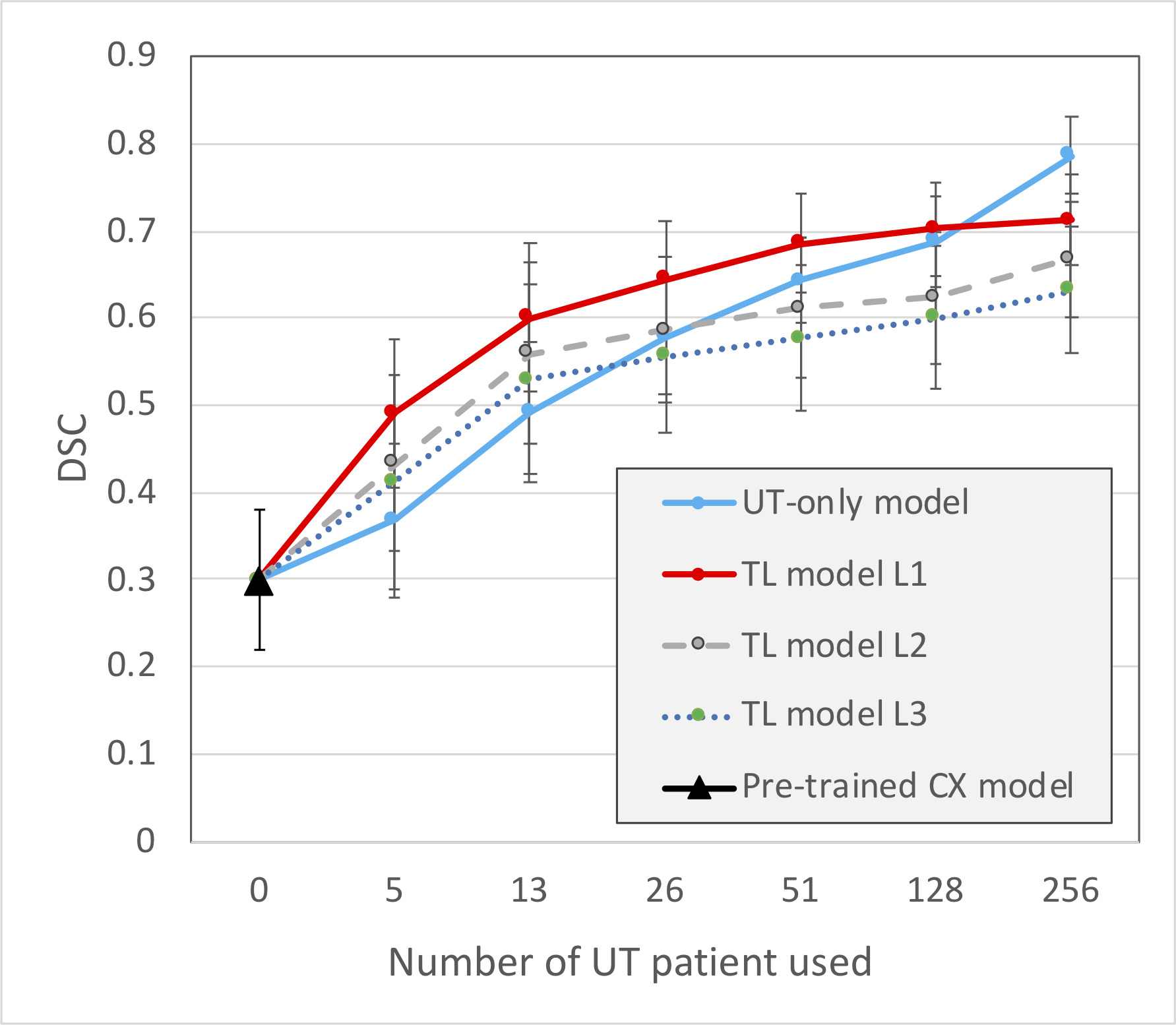
Figure 2: Performances of TL using various training combinations and sample sizes on the UT dataset. The blue line indicates the UT-only model, which was trained from scratch using the UT dataset. The black triangle indicates the prediction by the CX model directly without any contribution from UT data. The TL models indicate the TL experiments with fine-tune levels of L1, L2, and L3, as indicated in Figure 1. Data are expressed as means with error bars of standard deviation.

Figure 3: Demonstration of predicted tumor contours in a patient with endometrial cancer using various training combinations and sample sizes on the UT dataset. (A) The tumor contour was delineated manually (red contour) and overlaid on the ADC image. (B–D) Predicted tumor regions (blue contours) by using various combination of training models: (B) pretrained CX model; (C) UT-only model; (D) TL model with fine-tuned at level L1 by using the UT data. The numbers in white at the right bottom of each image indicate the DSC of the case.
DOI: https://doi.org/10.58530/2022/3194