2434
Multi-contrast Multi-scale vision Transformers (MMT) for MRI Contrast Synthesis1Department of Electrical and Computer Engineering, Johns Hopkins University, Baltimore, MD, United States, 2R&D, Subtle Medical Inc, Menlo Park, CA, United States
Synopsis
Complementary information from multi-modal MRI is widely used in clinical practice for disease diagnosis. Due to scan time limitations, image corruptions, and different acquisition protocols, one or more contrasts may be missing or unusable. Recently developed CNN models for contrast synthesis are unable to capture the intricate dependencies between input contrasts and are not dynamic to the varying number of inputs. This work proposes a novel Multi-contrast and Multi-scale vision Transformer (MMT) that can take any number and combination of input sequences and synthesize the missing contrasts.
Introduction
Complementary information from multiple MRI contrasts (T1, T2, FLAIR, PD etc.) is widely used in clinical practice. However, due to scan time limitations, image corruptions due to motion and artifacts, and different acquisition protocols, one or more contrasts may be missing or unusable. CNN models designed for contrast synthesis work only with a fixed number of inputs and do not capture the long-range dependencies between different contrasts. This work proposes a novel Multi-contrast and Multi-scale vision Transformer (MMT) that can take any number and combination of input sequences and synthesize the missing contrasts.Methods
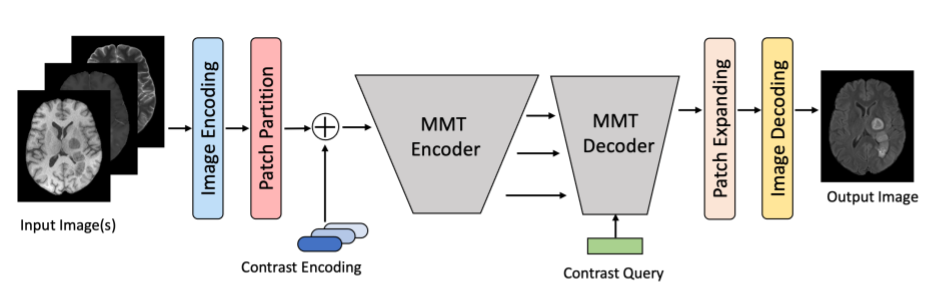
MMT architectureThe architecture overview of MMT is shown in Fig1. The input image(s) were first processed through a series of small CNN encoders (5 layers) to increase the receptive field. The feature map was then partitioned into small patches (4x4) to make the computation tractable, as transformer models require a lot of memory. These small patches were then combined with the contrast encodings and input to the MMT-encoder. MMT-encoder generated feature maps at different scales which the MMT-decoder consumed to output patches of feature maps. The MMT-decoder was also trained to take a “contrast query” as an input so that it can generate the feature maps of the required contrast images. These feature maps were upsampled by the “Patch-Expanding” blocks followed by a series of small CNN decoders to synthesize the corresponding image(s).
Encoder
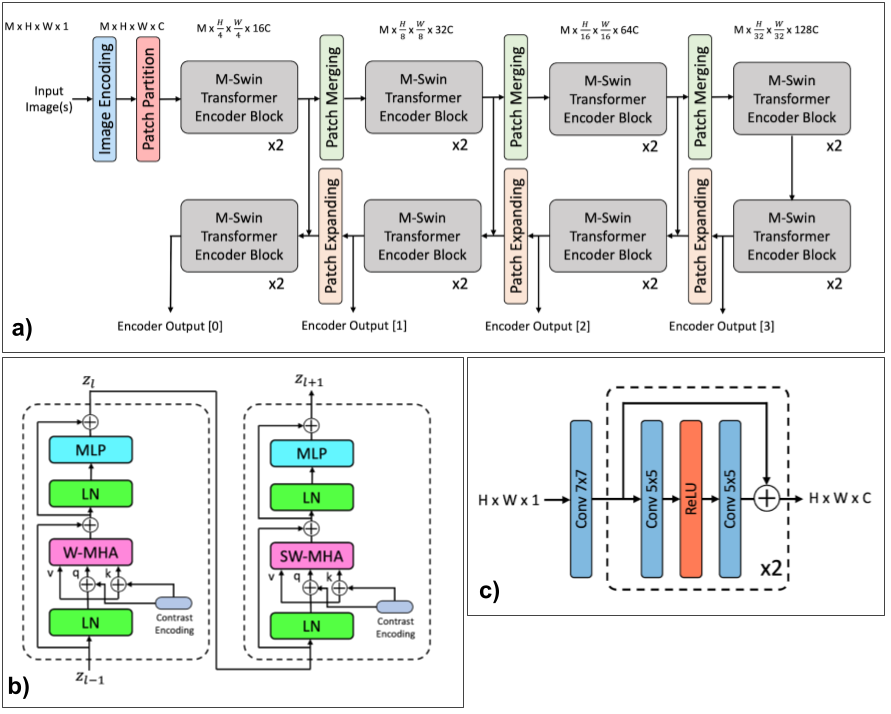
The detailed architecture of the MMT-encoder is shown in Fig2a. The encoder was designed similar to a U-Net architecture in order to generate multi-scale representations of the input images. The encoder performed joint encoding of multi-contrast input to capture inter- and intra-contrast dependencies. The downsampling part of the encoder consisted of a series of multi-contrast (M-Swin) transformer encoder blocks[1]. Two successive encoder blocks were followed by a patch merging layer[2]. Fig2b shows the detailed representation of the paired encoder block setup.
Decoder
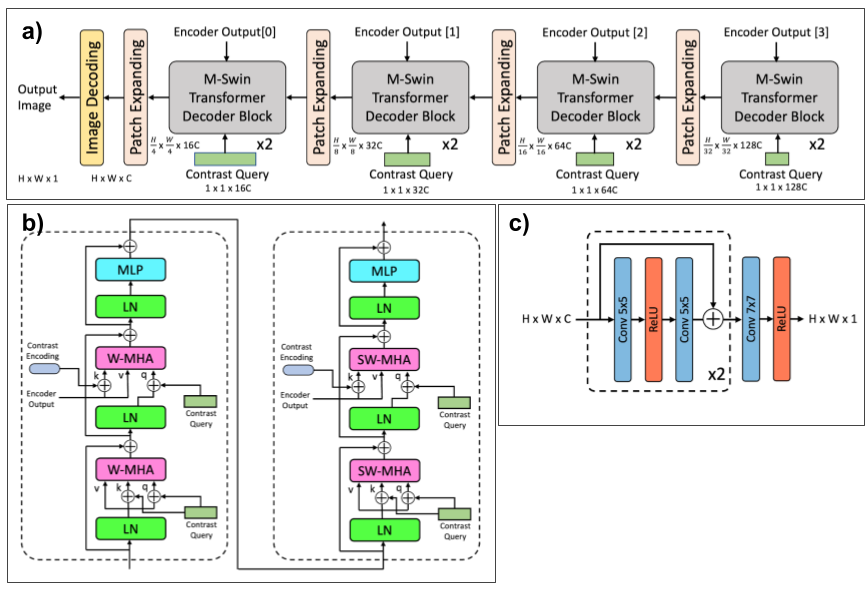
Fig3a shows the detailed representation of a MMT-decoder. The MMT-decoder generates target output based on a contrast query. The decoder blocks progressively decode the encoder outputs at different scales and generates the desired output(s). Similar to the encoder, the MMT-decoder was designed with a paired setup of M-Swin Transformer Decoder blocks followed by a patch-expanding (upsampling) layer. The detailed representation of the paired setup of the decoder blocks is shown in Fig 3b.
Hybrid model
In order to combine the best of both worlds, we use a transformer+CNN hybrid model in the form of small CNN networks before and after the MMT-encoder and decoder. We use separate encoding/decoding pathways for each contrast. Figs2c,3c show the CNN encoder and decoder.
Adversarial training
In order to further improve the perceptual quality of the synthesized missing contrasts, we use adversarial training in the form of a least-squared GAN[3].
Loss Functions
Let $$$x^i$$$ be the i-th input contrast, $$$\hat{x}^i$$$ be the i-th reconstructed input contrast, $$$y^i$$$ be the j-th target contrast and $$$\hat{y}^j$$$ be the j-th output contrast (i=1, ..., M; j=1, ..., N). The loss function for the model training has three components:
(1) Synthesis Loss:
$$\mathcal{L}_s = \frac{1}{N}\sum_{j=1}^{N} \Vert y^j - \hat{y}^j \Vert_1$$
(2) Self-reconstruction Loss:
$$\mathcal{L}_r = \frac{1}{M}\sum_{i=1}^{M} \Vert x^i - \hat{x}^i \Vert_1$$
(3) Adversarial Loss:
$$\mathcal{L}_{adv} = \frac{1}{N}\sum_{j=1}^{N} \{ (D_j(\hat{y}^j) - Label_f)^2 + (D_j(y^j) - Label_r)^2 \}$$
(4) Total Loss:
$$\mathcal{L}_G = \lambda_r \mathcal{L}_r + \lambda_s \mathcal{L}_s + \lambda_{adv} \mathcal{L}_{adv}$$
where $$$\lambda_r = 5$$$, $$$\lambda_s = 20$$$ and $$$\lambda_{adv} = 0.1$$$.
Dataset
We used the publicly available BRATS 2021 dataset [4-6] which consisted of 1251 cases with T1, T1Gd (post contrast), T2 and FLAIR images. The brain images were skull-stripped and pre-registered to an anatomical template. We use a train/validation/test split of 1123/63/63 cases.
Experiments
We trained the MMT-random model which is a model trained with random missing inputs (M=1,2 or 3) which we compare against a CNN baseline[7]. We also trained the MMT-zerogad which is a specific case of synthesizing T1Gd images with T1, T2 and FLAIR as inputs.
Results
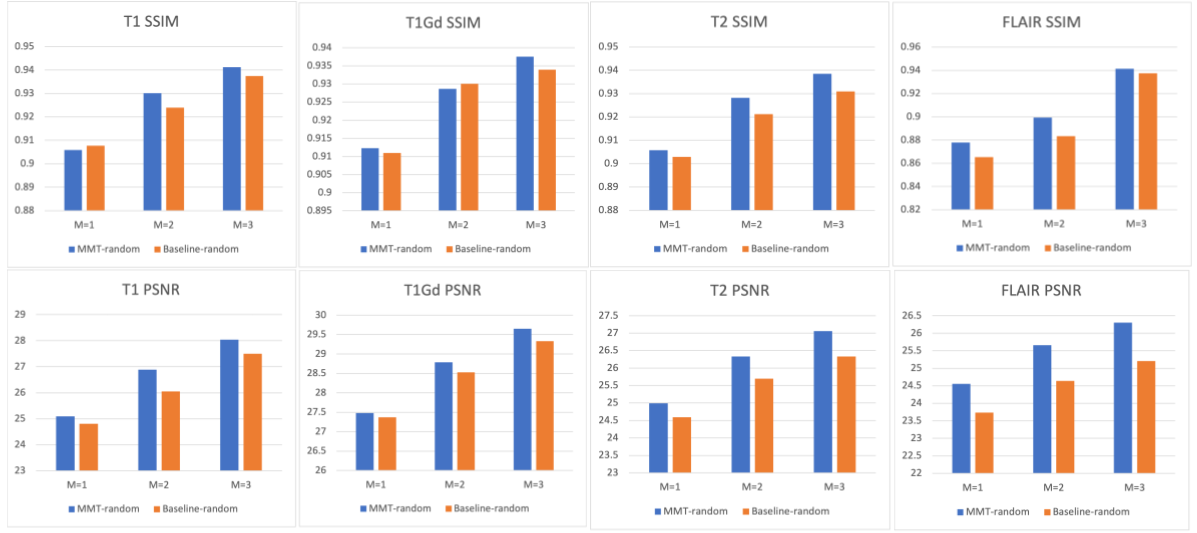
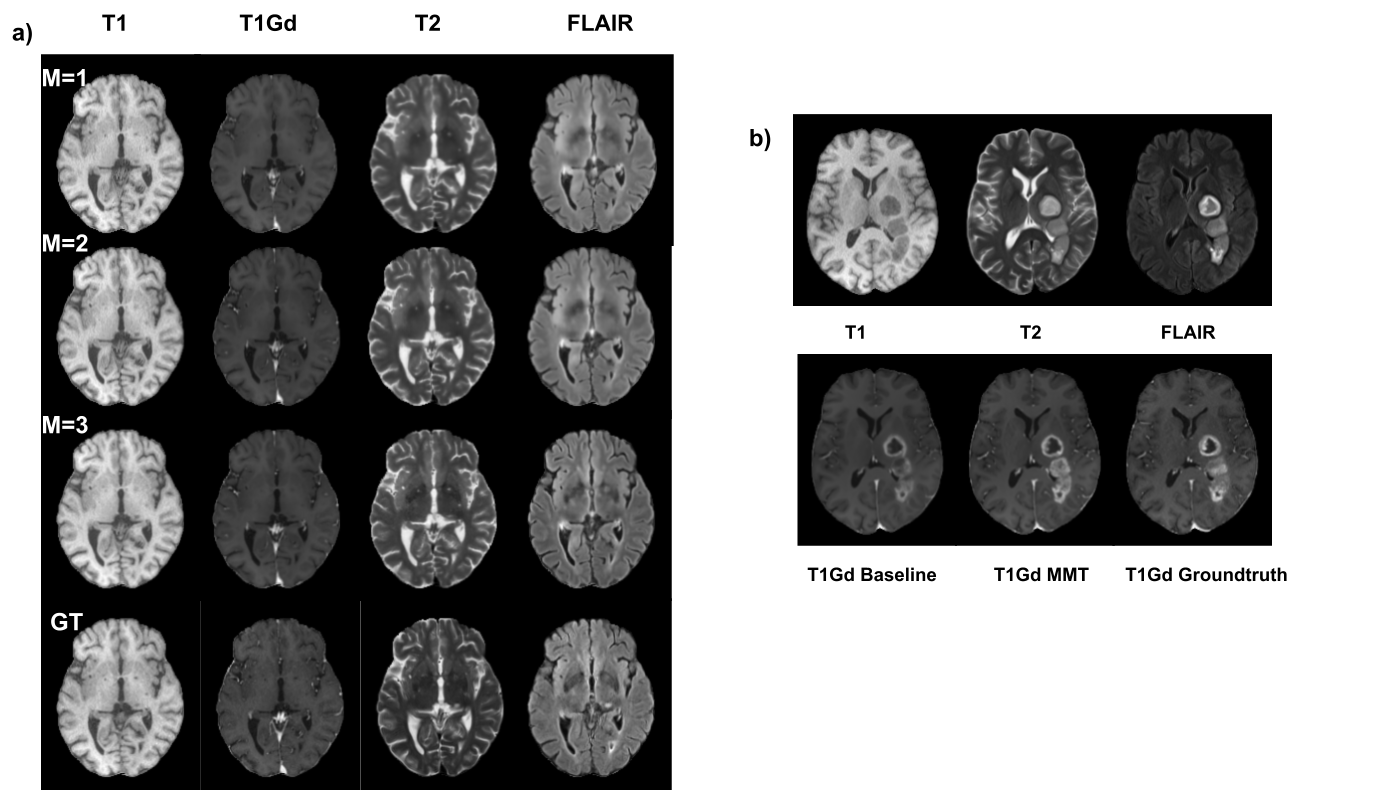
Fig4 shows the quantitative performance of MMT-random when compared with the CNN baseline model. Fig 5a shows the qualitative performance of the MMT-random model and Fig 5b shows the performance of the zero-gad model.Discussions
Based on the quantitative and qualitative results we have shown that vision transformer models can be effectively used for contrast synthesis. The MMT-model can support any combination of inputs and outputs which simplifies and improves the efficiency of model deployment in real-world clinical settings. When compared to a CNN-baseline[7], the proposed model outperforms in almost all cases. The proposed model has the ability to replace bad quality contrasts without the need for rescanning. The model can also be used as a Zero-Gad algorithm for contrast synthesis without use of any contrast agent.Conclusion
A novel Multi-contrast Multi-scale vision Transformer (MMT) is presented that can take any number and combination of input sequences and synthesize missing contrasts. The proposed model has the ability to synthesize complementary contrasts thus reducing the overall scan time.Acknowledgements
We would like to acknowledge the grant support of NIH R44EB027560.References
Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030; 2021.
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin. Attention Is All You Need. arXiv 1706.03762; 2017
Xudong Mao and Qing Li and Haoran Xie and Raymond Y. K. Lau and Zhen Wang and Stephen Paul Smolley. Least Squares Generative Adversarial Networks. arXiv 1611.04076; 2017
U.Baid, et al The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification. arXiv:2107.02314, 2021.
B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS), IEEE Transactions on Medical Imaging 34(10), 1993-2024 (2015) DOI: 10.1109/TMI.2014.2377694
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J.S. Kirby, et al., Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features, Nature Scientific Data, 4:170117 (2017) DOI: 10.1038/sdata.2017.117
Chartsias, Agisilaos and Joyce, Thomas and Giuffrida, Mario Valerio and Tsaftaris, Sotirios A. Multimodal MR Synthesis via Modality-Invariant Latent Representation. IEEE Transactions on Medical Imaging. 2018;37-3; 803-814
Figures