2348
Low Latency Real-Time MRI at 0.55T using Self-Calibrating Through-Time GRAPPA1Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, United States
Synopsis
Real-time MRI (RT-MRI) captures movements and dynamic processes in the human body as they occur, without reliance on any repetition or synchronization. Many applications of RT-MRI require low-latency reconstruction for feedback or interventions (typically <200ms). Here, we investigate self-calibrating spiral Through-Time GRAPPA at 0.55T and compare its performance against viewsharing and constrained reconstruction methods. We use longer readouts, which can be used at low-field due to reduced off-resonance effects. We demonstrate RT-MRI of speech production with 13.09ms temporal resolution and 25ms reconstruction latency (after a 30s pre-computed calibration step).
Introduction
We apply Through-Time generalized autocalibrating partial parallel acquisition (TT-GRAPPA) at 0.55T in the context of human speech production1. This work is motivated by the fact that 1) lower field strengths2 allow for longer spiral readouts from reduced off-resonance effects3 and 2) latency is often an issue in real-time applications, such as the guidance of interventional procedures4. We characterize the reconstruction speed of TT-GRAPPA and show faster reconstruction than those of traditional compressed sensing iterative approaches5. Note that TT-GRAPPA does not require estimation of coil sensitivity maps or any iteration6,7.Methods
Image Acquisition:Experiments were performed using a whole body 0.55T system (prototype MAGNETOM Aera, Siemens Healthineers, Erlangen, Germany) equipped with high-performance shielded gradients (45 mT/m amplitude, 200 T/m/s slew rate). The RTHawk system (HeartVista, Menlo Park, California) was used for real-time image acquisition8. Three through six interleaf linear-order spiral acquisitions were acquired using a custom 8-element upper-airway coil. Acquisition parameters are described in Table 1. The gradient impulse response function (GIRF) was estimated9,10 from a phantom-based measurement11 and used to correct linear eddy current artifacts for spiral trajectories prior to reconstruction.
Image Reconstruction:
Figure 1 illustrates the TT-GRAPPA method along with the inherent temporal resolution and latency, compared with view sharing (VS). TT-GRAPPA weights are computed by calibrating fully sampled multiple time frame “blocks” in a calibration phase. Then, using the weights, we estimate missing k-space samples for each coil, reconstruct images using the nonuniform fast Fourier transform12 and combine using a sum-of-squares approach. We use a linear-ordered acquisition to acquire k-space spirals that are close to each other as the subject moves, making the system motion-robust.13 After this calibration, TT-GRAPPA reconstructs new k-space after every TR, whereas VS uses a sliding window approach that requires multiple TRs to form a complete k-space.
The segment size of the GRAPPA weights calibrated is of length 3 along the readout and 90 along the temporal directions. These parameters, along with the undersampling factor were determined by visually inspecting output reconstructions and their corresponding intensity-vs-time plots.
Data Analysis:
TT-GRAPPA results were compared against a constrained iterative temporal finite difference-based reconstruction (TFD) 5 and a traditional VS reconstruction (step size 1 TR, native time resolution of 39.27ms, frame rate 76 frames per second). Performance was measured quantitatively on speed of reconstruction and temporal resolution of acquisition. Calibration and reconstruction times for GRAPPA and VS reconstructions were measured on an 8-core Intel core i9 CPU processor. TFD reconstruction time was measured on GPUs using a Lambda Hyperplane server (32 CPU cores, 4 NVIDIA A100 SXM2 GPU Tensor Core GPUs). Furthermore, intensity vs. time plots were analyzed to validate the true temporal resolution benefits of TT-GRAPPA.
Results
Figure 2 describes the effect of undersampling at higher rates by comparing TT-GRAPPA at 3, 4, 5, and 6 interleaves and respective undersampling factors R=3,4,5,6. As the undersampling factor increases, TT-GRAPPA results in increased blurring around boundaries despite the increase in temporal resolution. This is likely due to the lack of spatial coil sensitivity along with the reduced signal-to-noise ratio that comes from the shorter readout time. Thus, an undersampling factor of 3 with TT-GRAPPA was chosen for future analysis.Figure 3 shows qualitative results for speech TT-GRAPPA compared to VS and TFD reconstructions for a “count 1-10” stimulus at a normal rate. TT-GRAPPA reconstruction shows slight spatial blurring along the tongue and lips but resolves artifacts from undersampling.
Figure 4 shows the temporal resolution benefits of TT-GRAPPA speech over VS for a rapid speech “ala-ala” stimulus. TT-GRAPPA resolves rapid tongue motion in the vocal tract better than VS.
Reconstruction latency for a VS reconstruction of 3 arms was measured at ~35ms per frame, whereas GRAPPA reconstruction is ~25ms per frame (described as $$$T_V$$$ and $$$T_G$$$ in Figure 1 respectively). This reconstruction time is much faster than that of iterative reconstruction, which takes ~40 seconds, requires high-performance GPUs, and needs all frames to be acquired prior to reconstruction.
Discussion
TT-GRAPPA improves temporal resolution by only collecting undersampled k-space, but at a cost of some spatial blurring. Therefore, we recommend that TT-GRAPPA be used only in applications where high temporal resolution is required, such as speech. We suspect that parameters such as length of calibration readout, number of calibration TRs $$$N_{TR}$$$ can be optimized further to reduce this blurring.A limitation of this work is that we did not implement TT-GRAPPA in a real-time reconstruction pipeline and instead measured latency of reconstruction offline. Furthermore, calibration and reconstruction code were written in MATLAB and using a CPU as opposed to a compiled language such as C++ and using GPU. This change would reduce the 30 second calibration time $$$T_{CAL}$$$, making "online" reconstruction feasible. Another limitation is that for rapid stimulus (Figure 4) we were unable to achieve the expected result of high temporal resolution for the TFD reconstruction despite extensive regularization-term parameter tuning. These require additional exploration and remains future work.
Conclusion
We have demonstrated feasibility of self-calibrating TT-GRAPPA in speech RT-MRI at 0.55T. Results show improvement in resolving fast tongue motion. This can open new opportunities for the study of fast speech or interventional MRI.Acknowledgements
We acknowledge grant support from the National Science Foundation (#1828736) and National Institute of Health (R01-HL130494) and research support from Siemens Healthineers.References
1. Lingala SG, Sutton BP, Miquel ME, Nayak KS. Recommendations for real-time speech MRI. J Magn Reson Imaging. 2016;43(1):28-44. doi:10.1002/jmri.249972. Campbell-Washburn AE, Ramasawmy R, Restivo MC, et al. Opportunities in Interventional and Diagnostic Imaging by Using High-Performance Low-Field-Strength MRI. Radiology. 2019;293(2):384-393. doi:10.1148/radiol.2019190452
3. Bhattacharya I, et al. Dynamic speech imaging at 0.55T using single shot spirals for 11ms temporal resolution. Proc. ISMRM 27th Scientific Session, Montreal, May 2019. p0440.
4. Nayak KS, Lim Y, Campbell-Washburn AE, Steeden J. Real-Time Magnetic Resonance Imaging. J Magn Reson Imaging. 2020. Early view. doi:10.1002/jmri.27411
5. Lingala SG, Zhu Y, Kim YC, Toutios A, Narayanan S, Nayak KS. A fast and flexible MRI system for the study of dynamic vocal tract shaping. Magn Reson Med. 2017;77(1):112-125. doi:10.1002/mrm.26090
6. Griswold MA, Jakob PM, Heidemann RM, et al. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn Reson Med. 2002;47(6):1202-1210. doi:10.1002/mrm.10171
7. Wright KL, Hamilton JI, Griswold MA, Gulani V, Seiberlich N. Non-Cartesian parallel imaging reconstruction. J Magn Reson Imaging. 2014;40(5):1022-1040. doi:10.1002/jmri.24521
8. Santos JM, Wright GA, Pauly JM. Flexible real‐time magnetic resonance imaging framework. Conf Proc IEEE Eng Med Biol Soc. 2004;2:1048–1051.
9. Robison RK, Li Z, Wang D, Ooi MB, Pipe JG. Correction of B0 eddy current effects in spiral MRI. Magn Reson Med. 2019;81(4):2501–2513.
10. Campbell-Washburn AE, Xue H, Lederman RJ, Faranesh AZ, Hansen MS. Real-time distortion correction of spiral and echo planar images using the gradient system impulse response function. Magn Reson Med. 2016;75(6):2278-2285. doi:10.1002/mrm.25788
11. Bruijnen T, Stemkens B, van den Berg CAT, Tijssen RHN. Prospective GIRF-based RF phase cycling to reduce eddy current-induced steady-state disruption in bSSFP imaging. Magn Reson Med. 2020;84(1):115-127. doi:10.1002/mrm.28097
12. Fessler JA, Sutton BP. Nonuniform fast fourier transforms using min-max interpolation. IEEE Trans Signal Process. 2003;51(2):560-574. doi:10.1109/TSP.2002.807005
13. Lingala SG, Zhu Y, Lim Y, et al. Feasibility of through-time spiral generalized autocalibrating partial parallel acquisition for low latency accelerated real-time MRI of speech. Magn Reson Med. 2017;78(6):2275-2282. doi:10.1002/mrm.26611
Figures
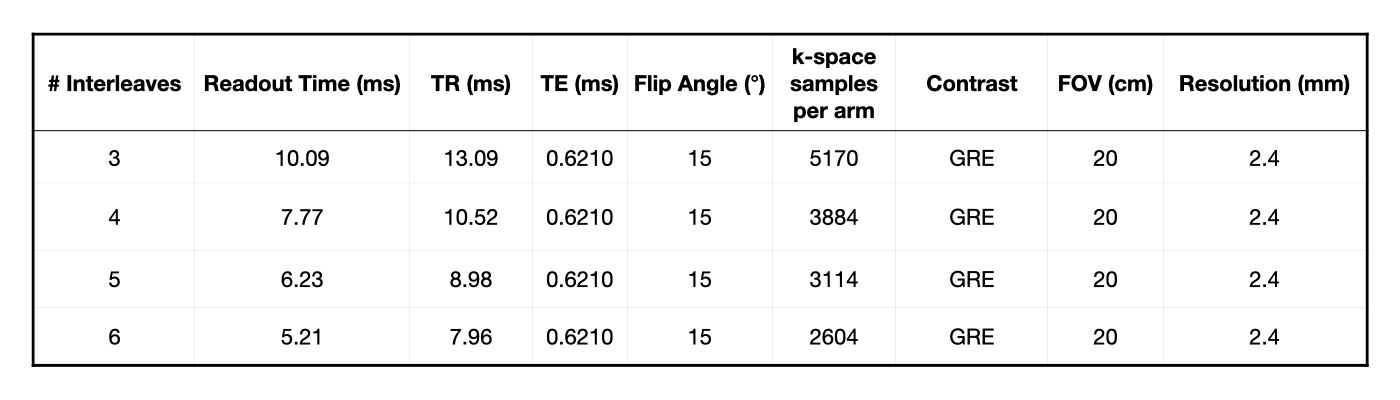
Table 1: Acquisition parameters for scans of the vocal tract. All scans are self-calibrating, and do not require separate calibration / acquisition scans. Scans were fixed with FOV of 20cm with a spatial resolution of 2.4mm, and a GRE contrast.
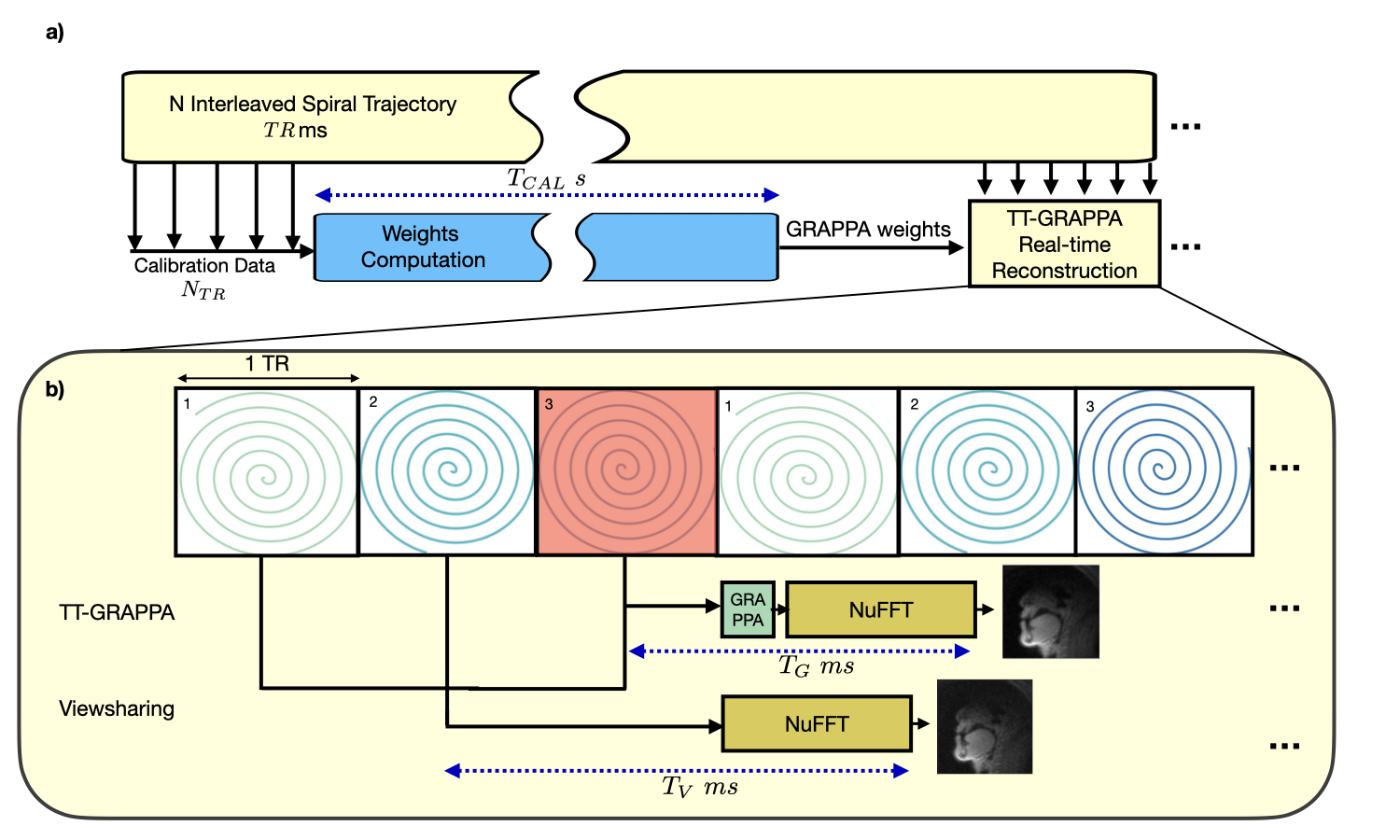
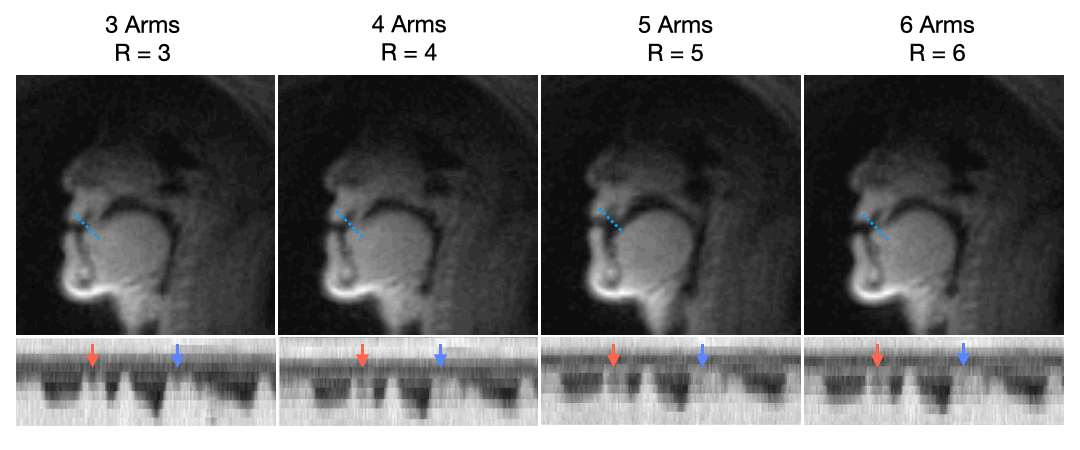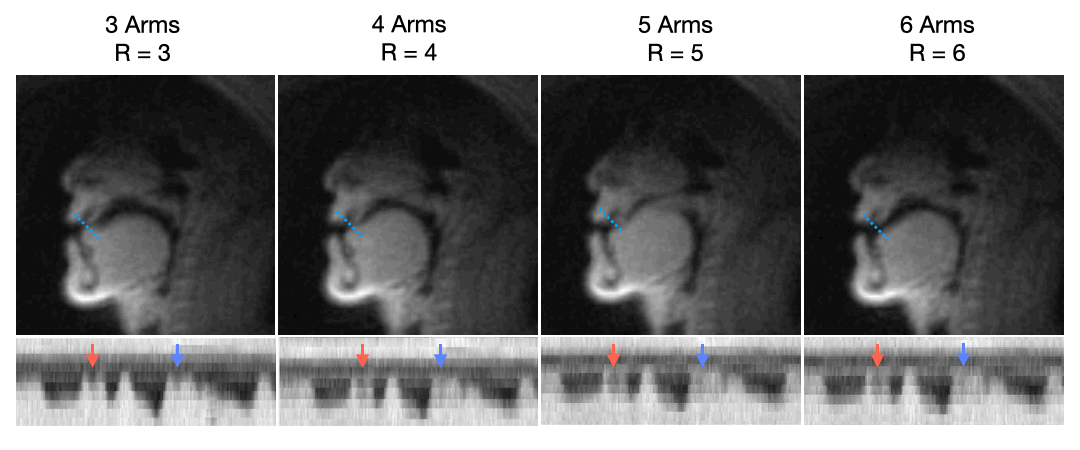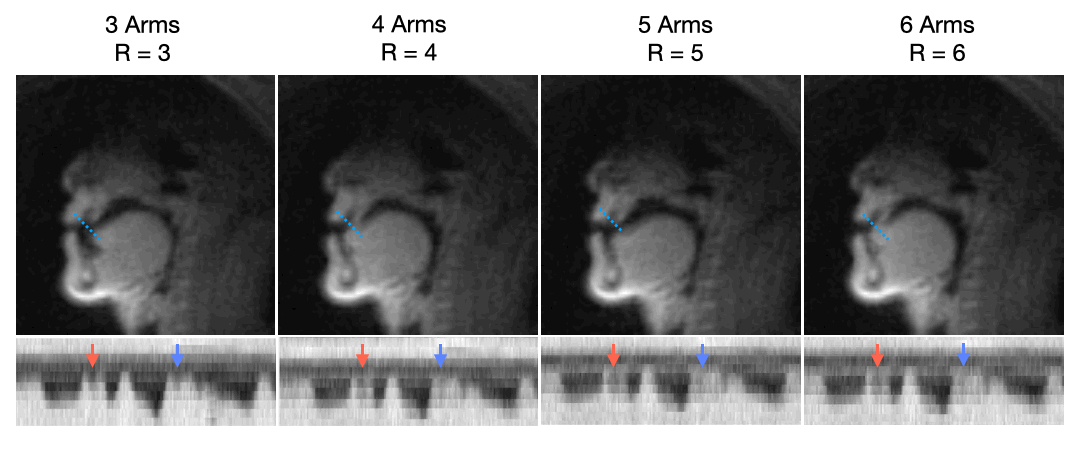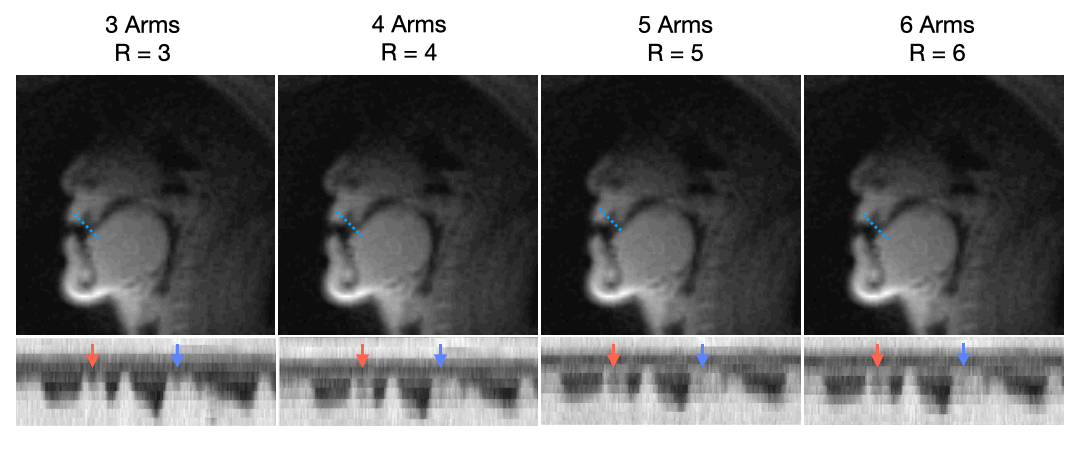
Figure 2. Through-time GRAPPA at different spiral # interleaves and respective undersampling factors (R=3, 4, 5, 6) with intensity vs. time plot of the tongue-lip boundary. The SNR is reduced at higher # interleaves and the tongue and lips are less pronounced. Tongue motion is not as pronounced and blurred (see arrows), due to the lack of coil diversity for higher undersampling factors.
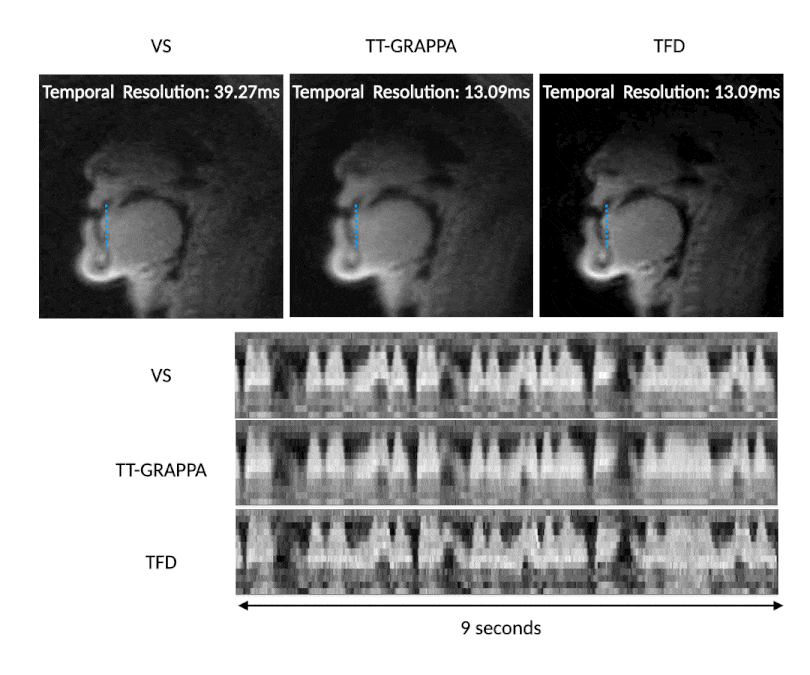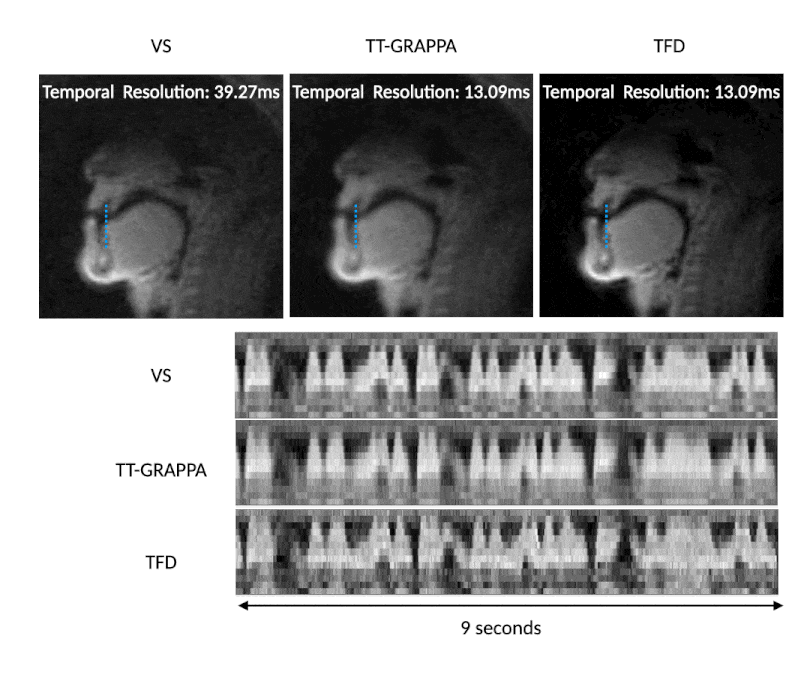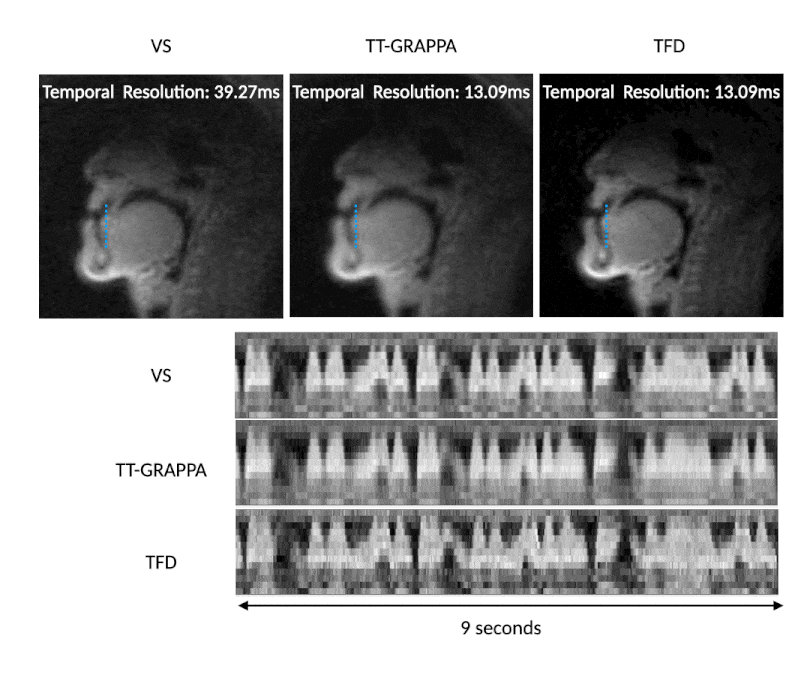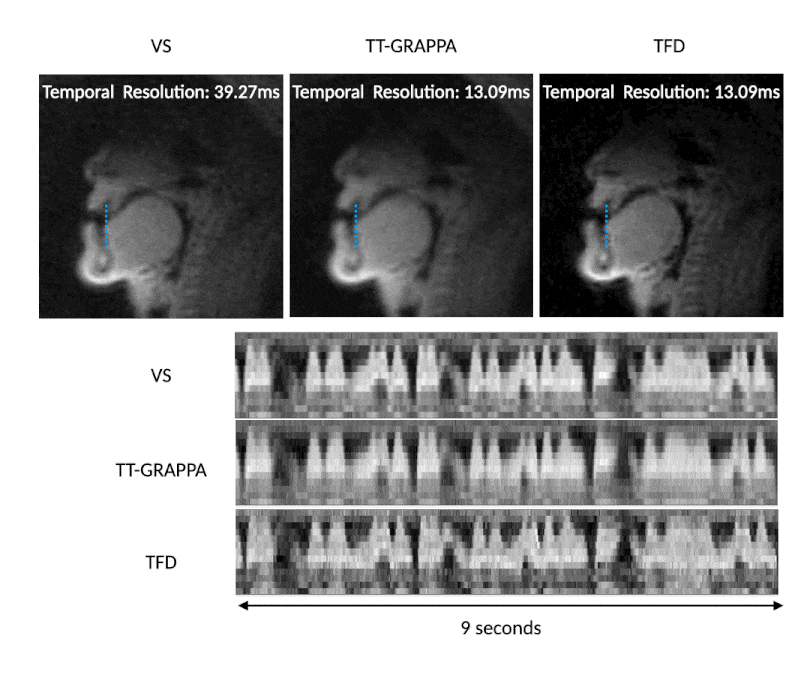
Figure 3. VS (step size 1 TR, native time resolution of 39.27ms, frame rate 76 frames per second), TT-GRAPPA, and TFD reconstructions reconstructing 3 spiral arms from 1 arm with an undersample factor of 3. The stimulus shown is the subject counting from 1 to 10 at a normal rate. TT-GRAPPA reconstruction recovers tongue and lip boundaries and achieves a higher temporal resolution than VS reconstruction at the cost of spatial blurring.
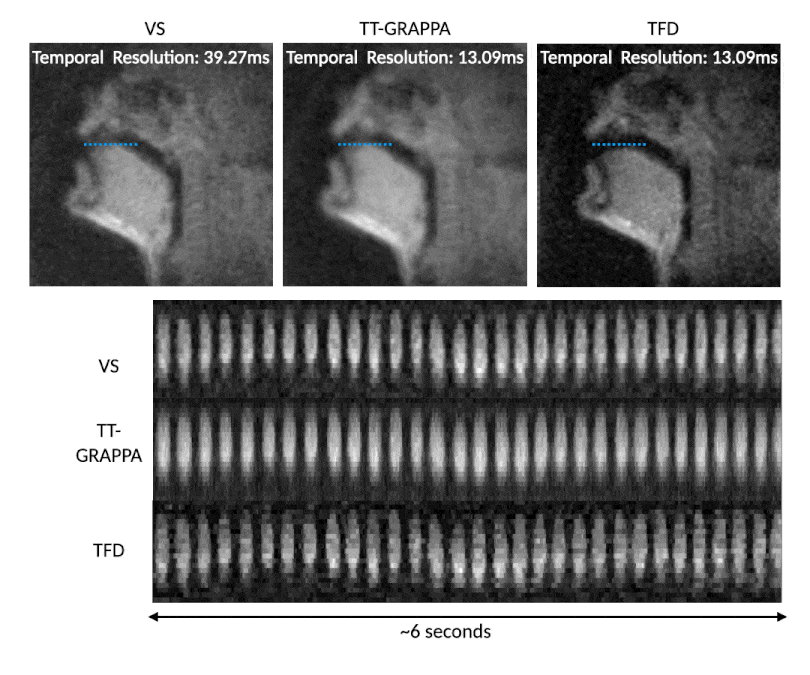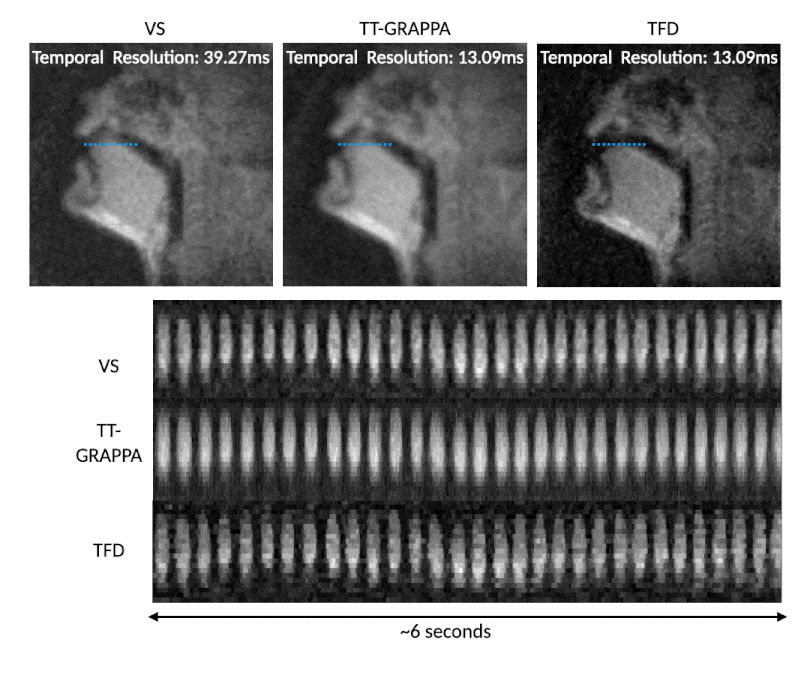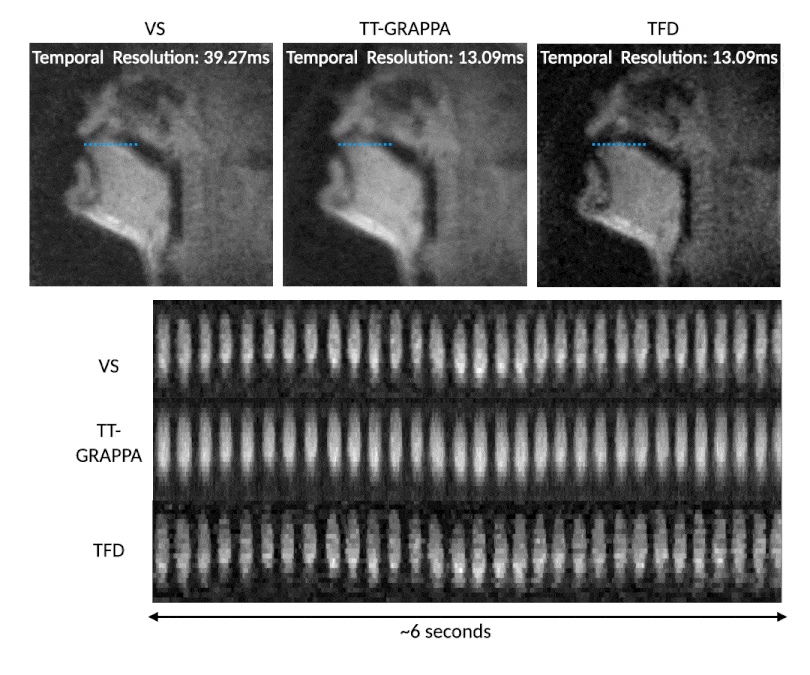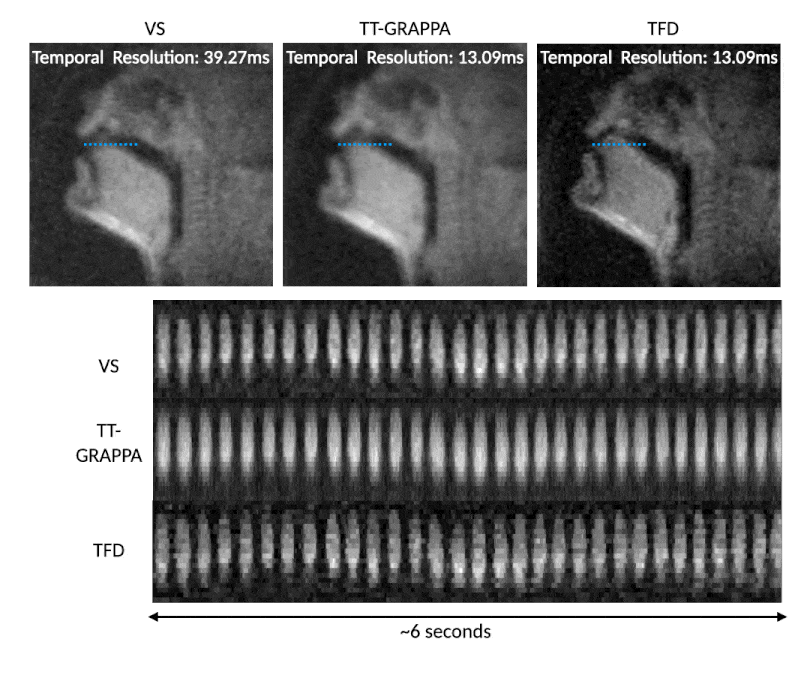
Figure 4: VS (step size 1 TR, native time resolution of 39.27ms, frame rate 76 frames per second), TT-GRAPPA, and TFD reconstructions reconstructing 3 spiral arms from 1 arm for a rapid “ala-ala” stimulus. TT-GRAPPA resolves the rapid motion at the tongue tip unlike VS but suffers from spatial blurring. The TFD reconstruction shows sharper features but suffers from an unexpected temporal blurring which requires further exploration (see discussion).