2157
Reducing the impact of texture on deep-learning brain tissue segmentation networks trained with simulated MR images1Biomedical Engineering, Eindhoven University of Technology, Eindhoven, Netherlands, 2Philips Research Laboratories, Hamburg, Germany, 3Philips Healthcare, MR R&D - Clinical Science, Best, Netherlands
Synopsis
Deep learning-based segmentation algorithms largely rely on the availability of extensive, clinically representative data. While collecting such data requires vast resources, image simulation has the potential of generating realistic data reproducing a wide range of scanner sequences or parameters. In this work, we present an MR image simulation pipeline and evaluate its potential for training a deep-learning network for segmenting several brain structures in T1-weighted images acquired from real scanners. We additionally demonstrate how to prevent performance degradation from the lack of tissue texture in simulated images by combining statistical texture analysis and filtering on the evaluation image set.
Introduction
Magnetic resonance imaging (MRI) is a commonly used technique for the diagnosis of neurodegenerative disorders1. An accurate segmentation of brain tissues2, such as gray matter (GM), white matter (WM) and cerebrospinal fluid (CSF), is a crucial step for diagnosis. With the emergence of deep learning (DL) techniques, numerous automated segmentation methods have been developed, reaching a competitive performance almost on par to human experts3. However, most DL-based methods rely on the availability of an extensive number of datasets with accurate tissue labels, containing representative variation in terms of tissue contrast, anatomy and artifacts, to achieve a robust performance4. Collecting such datasets has so far proven to be challenging, hampering the use of automated methods in clinical settings. Image simulation allows the generation of realistic MRI data with features reproducing variable scanner or sequence parameters, without expanding a vast amount of resources to acquire data5. In this work we study the feasibility of utilizing such data for the training of DL-based segmentation algorithms.Methods
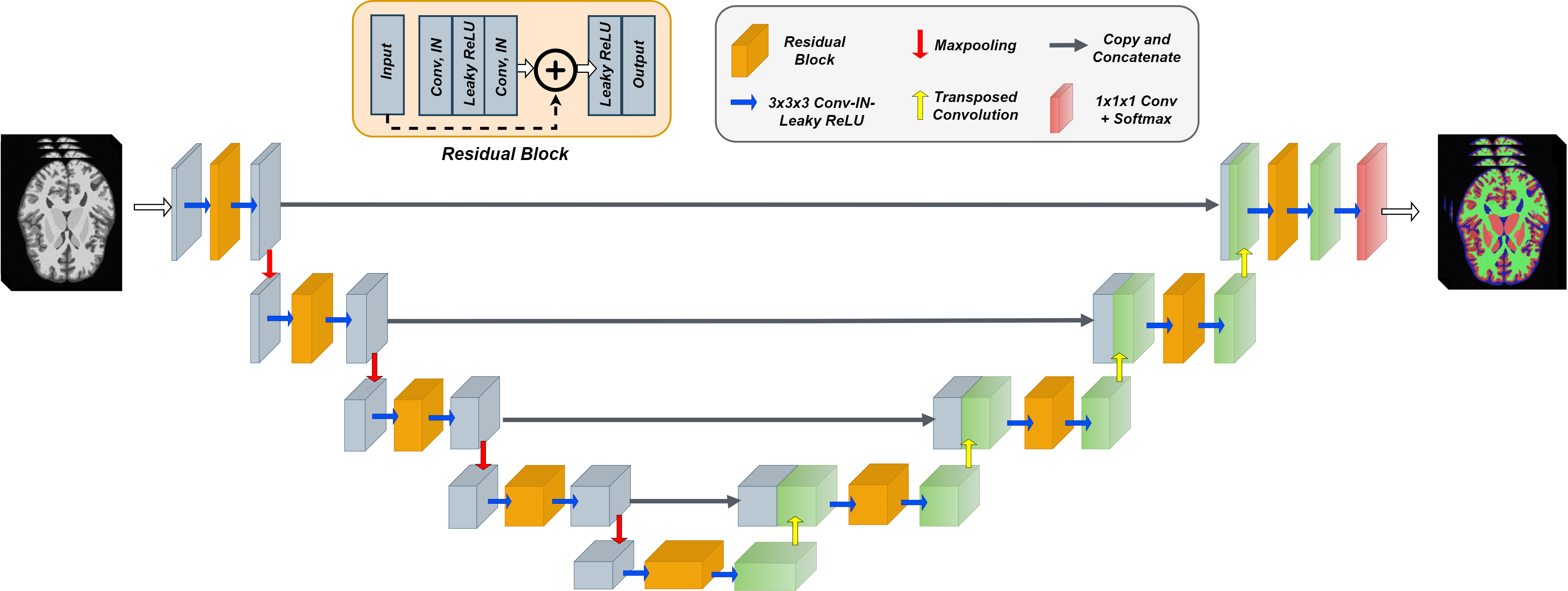
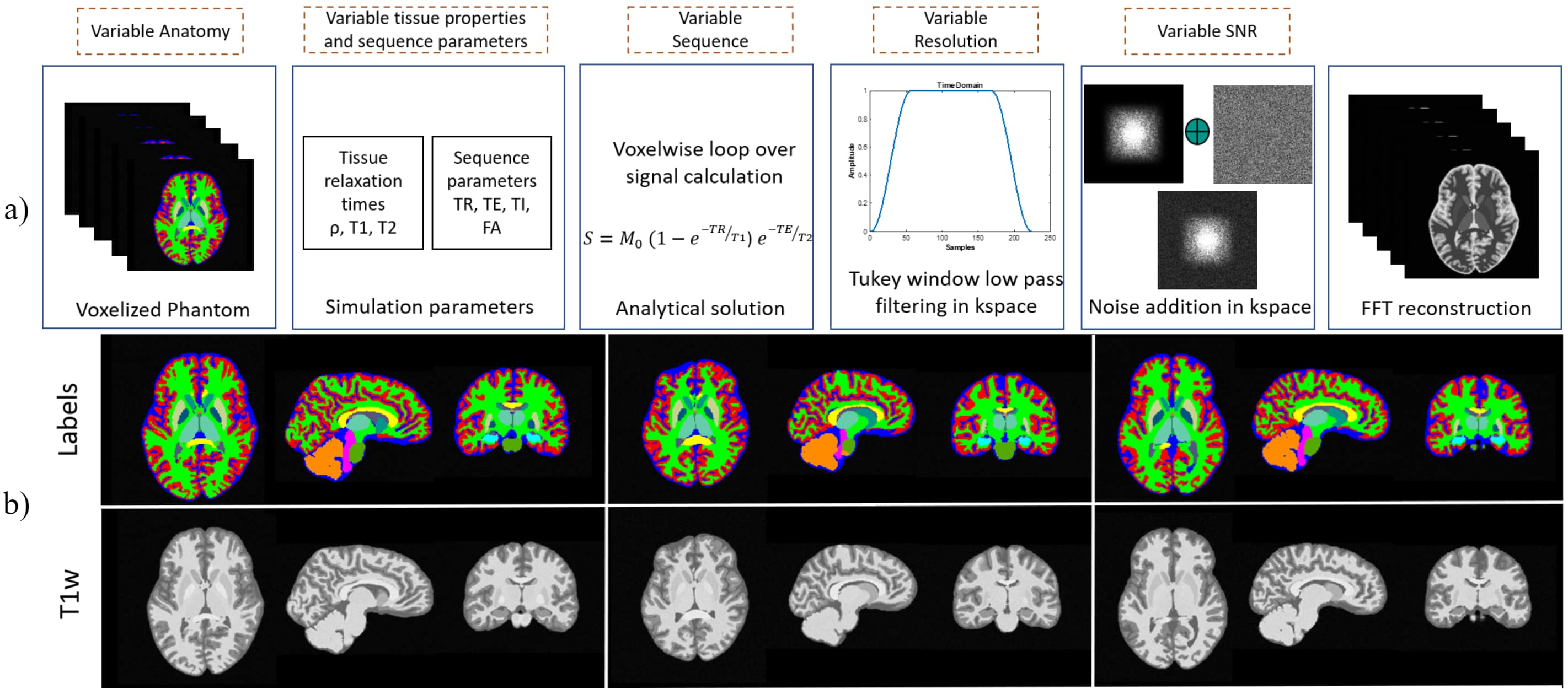
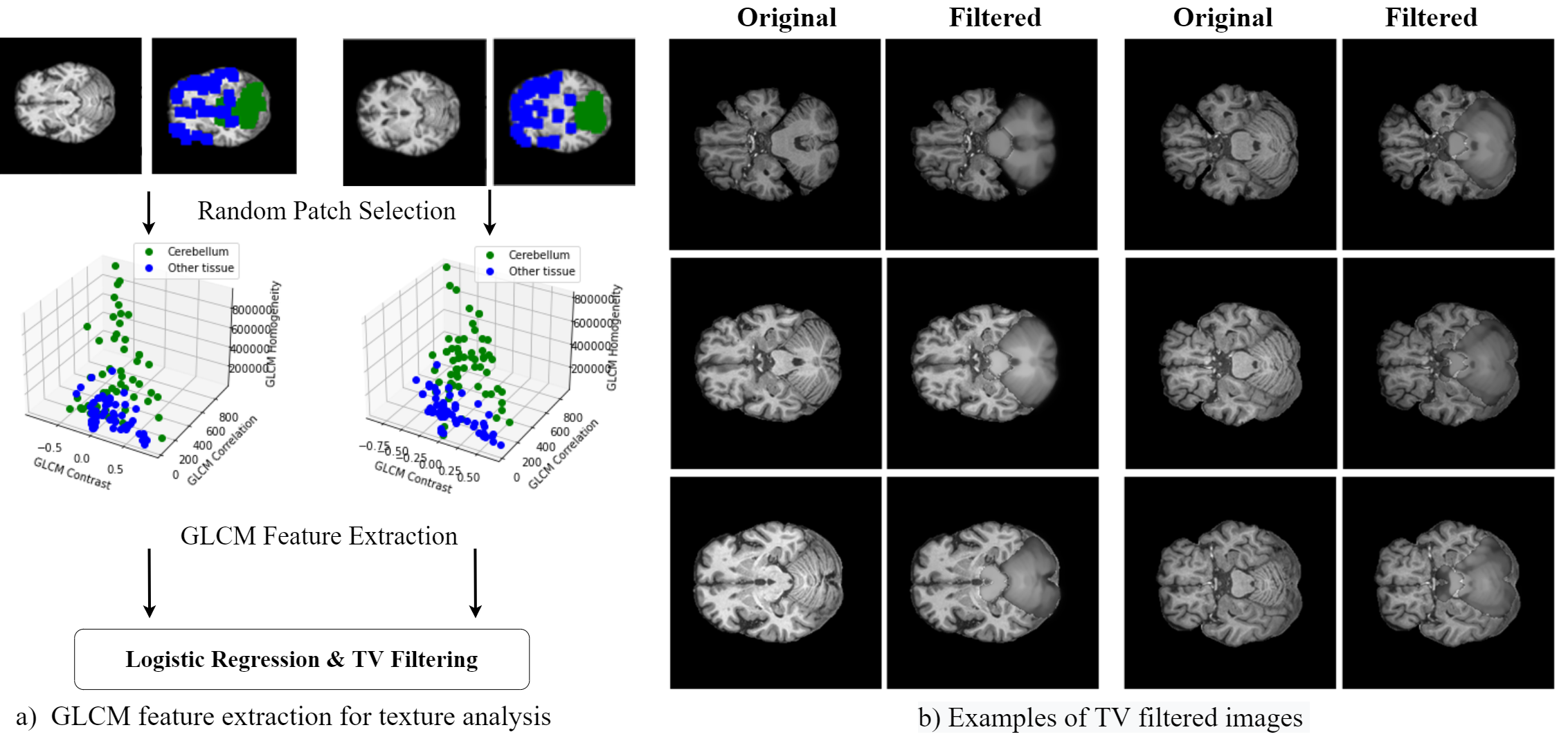
We adopt a residual 3D U-Net6 ,7 for the segmentation task, illustrated in Fig. 1. During training, we optimize a weighted sum of cross-entropy, Dice and Tversky losses8 for better handling of false positive and negative predictions. The network is trained to segment five tissue classes in total, consisting of GM, WM, CSF, cerebellum, and brain stem, utilizing a set of 200 simulated T1-weighted (T1w) brain images. Our simulation framework (Fig.2) is adapted to brain MRI with 200 patient-specific brain phantoms of variable anatomy, derived from the HCP9 database and simulated for T1w MRI. Both tissue properties and sequence parameters are varied to provide a realistic variance of brain anatomy and contrast, as well as image quality and resolution. Once trained, the segmentation network is evaluated on testing data extracted from the MRBrainS1810 segmentation challenge, where we utilize 7 annotated T1w volumes, which include both healthy and diseased subjects. Both training and testing data are pre-processed according to the pipelines described in Table 1, which additionally outlines the acquisition parameters and image characteristics of each dataset.While real MRI images contain rapid changes in intensity and texture in and around certain tissues, such as cerebellum, these textural changes are challenging to simulate using the proposed pipeline. This leads to a degradation in performance on real MR images, where the network falsely assigns parts of the cerebellum to the WM or GM class. To address this issue, we propose to reduce the bias towards texture and increase the relative importance of shape in real MR images by applying feature preserving smoothing in the form of total variation (TV) based filtering11. To restrict the filter to only the areas with high changes in texture, we first perform texture analysis using the gray-level co-occurrence matrix (GLCM)12 over each volume. We derive several statistical measures from the GLCM, such as contrast, correlation, and homogeneity, further used to train a logistic regression model and determine patches of the volume with significant levels of textural change (Fig.3). The extracted patches are subsequently TV filtered, producing new images with reduced noise and high-frequency textural features, further used for evaluation.
Results and Discussion
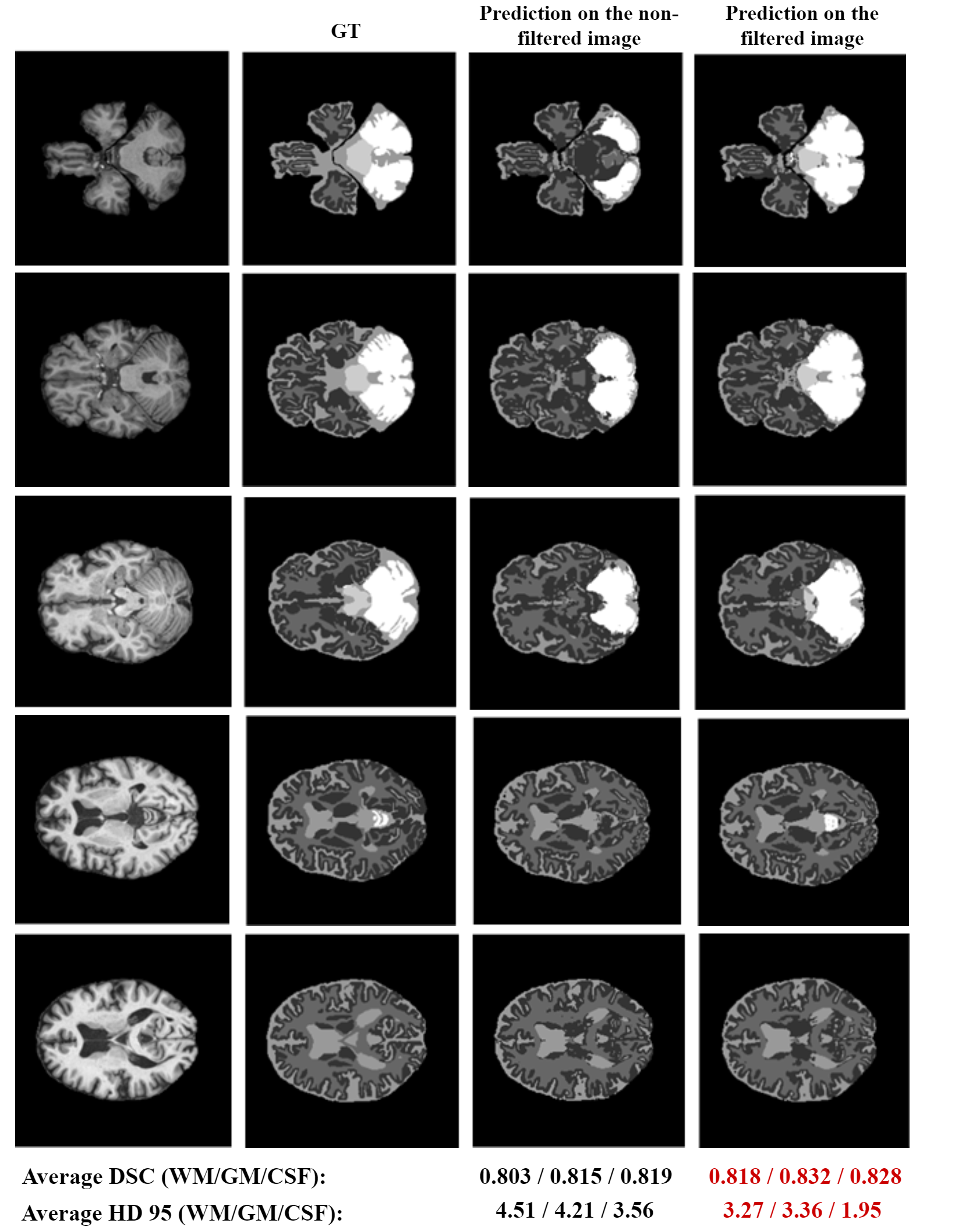
Fig.4 depicts the segmentation performance on several examples extracted from the test set, utilizing both non-filtered and filtered images. We can visually observe an improvement in performance when the model is tested on filtered images, particularly in the area around the cerebellum. Both the average Dice score (DSC) and the 95th percentile Hausdorff distance (HD 95) suggest a substantial improvement in performance across WM, GM and CSF when applying the GLCM-based filtering procedure. We additionally observe a significant effect for the area of cerebellum, where an initial performance of 0.43 and 17.81 in terms of DSC and HD 95 is improved up to 0.853 and 3.71, respectively. However, brain stem segmentation is still sub-par, achieving average scores of 0.62 and 11.21 in terms of DSC and HD 95. Results obtained in this study suggest a promising potential of simulated data to aid the training of neural networks for medical image segmentation tasks. In fact, we show that such networks already achieve comparable performance to those trained with real data and identify that the lack of texture in simulated images causes a performance drop on data acquired from real MRI scanners. While we showcase a way to handle the lack of texture for larger regions, such as cerebellum, we still observe reduced accuracy in segmenting smaller brain structures. Future work involves improving the texture feature extraction and evaluation of the proposed method on a bigger dataset, as well as extension of the method to other modalities.Conclusion
This study demonstrates a promising solution to address the lack of medical data, crucial for obtaining robust DL-based segmentation methods for inclusion in clinical routines, by utilizing simulated images with accurate “ground-truths” for training. Our results additionally suggest that handling texture in training images is critical for improving the performance of DL segmentation networks trained on simulated data. In conclusion, the overall method can serve as a better and more realistic data augmentation strategy, as well as improve the applications of transfer learning and domain adaptation in medical image analysis tasks.Acknowledgements
This research is a part of the OpenGTN project, supported by the European Union in the Marie Curie Innovative Training Networks (ITN) fellowship program under project No. 764465.References
1. Smith-Bindman, R., Miglioretti, D.L., Johnson, E., Lee, C., Feigelson, H.S., Flynn, M., Greenlee, R.T., Kruger, R.L., Hornbrook, M.C., Roblin, D. and Solberg, L.I., 2012. Use of diagnostic imaging studies and associated radiation exposure for patients enrolled in large integrated health care systems, 1996-2010. Jama, 307(22), pp.2400-2409.
2. de Bresser, J., Portegies, M.P., Leemans, A., Biessels, G.J., Kappelle, L.J. and Viergever, M.A., 2011. A comparison of MR based segmentation methods for measuring brain atrophy progression. Neuroimage, 54(2), pp.760-768.
3. Despotović, I., Goossens, B. and Philips, W., 2015. MRI segmentation of the human brain: challenges, methods, and applications. Computational and mathematical methods in medicine, 2015.
4. Mårtensson, G., Ferreira, D., Granberg, T., Cavallin, L., Oppedal, K., Padovani, A., Rektorova, I., Bonanni, L., Pardini, M., Kramberger, M.G. and Taylor, J.P., 2020. The reliability of a deep learning model in clinical out-of-distribution MRI data: a multicohort study. Medical Image Analysis, 66, p.101714..
5. Frangi, A.F., Tsaftaris, S.A. and Prince, J.L., 2018. Simulation and synthesis in medical imaging. IEEE transactions on medical imaging, 37(3), pp.673-679.
6. Çiçek, Ö., Abdulkadir, A., Lienkamp, S.S., Brox, T. and Ronneberger, O., 2016, October. 3D U-Net: learning dense volumetric segmentation from sparse annotation. In International conference on medical image computing and computer-assisted intervention (pp. 424-432). Springer, Cham.
7. He, K., Zhang, X., Ren, S. and Sun, J., 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
8. Salehi, S.S.M., Erdogmus, D. and Gholipour, A., 2017, September. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In International workshop on machine learning in medical imaging (pp. 379-387). Springer, Cham.
9. Van Essen, D.C., Smith, S.M., Barch, D.M., Behrens, T.E., Yacoub, E., Ugurbil, K. and Wu-Minn HCP Consortium, 2013. The WU-Minn human connectome project: an overview. Neuroimage, 80, pp.62-79.
10. Grand Challenge on MR Brain Segmentation 2018. (MRBrainS18). https://mrbrains18.isi.uu.nl/
11. Getreuer, P., 2012. Rudin-Osher-Fatemi total variation denoising using split Bregman. Image Processing On Line, 2, pp.74-95.
12. Haralick, R.M., Shanmugam, K. and Dinstein, I.H., 1973. Textural features for image classification. IEEE Transactions on systems, man, and cybernetics, (6), pp.610-621.
Figures