1966
Deep Learning with Perceptual Loss Enables Super-Resolution in 7T Diffusion Images of the Human Brain1Chair of Cellular and Molecular Imaging, Comprehensive Heart Failure Center (CHFC), Würzburg, Germany, 2Department of Internal Medicine I, University Hospital Würzburg, Würzburg, Germany
Synopsis
Diffusion weighted imaging has become a key imaging modality for the assessment of brain connectivity as well as the structural integrity, but the method is limited by low SNR and long scan times. In this study we demonstrate that AI models trained on a moderate number of publicly available 7T datasets (n=12) are able to enhance image resolutions in diffusion MRI up to 25 times. The applied NoGAN model performs well for smaller resolution enhancements (4- and 9-fold), but generates "hyper" realistic images for higher enhancements (16- and 25-fold). Models trained using perceptual loss seem to avoid this limitation.
Introduction
Diffusion weighted imaging has become a key imaging modality for the assessment of brain connectivity as well as the structural integrity of nervous and muscle tissue. Due to intrinsically low SNR and limited scan times, spatial resolutions in clinical diffusion MRI have remained low. In recent years, artificial intelligence has become state-of-the-art for a wide variety of MR related computer vision tasks[1, 2] and also artificial enhancements of image resolutions have been attempted.[3-6] Super-resolution based on generative adversarial networks or pixel-wise loss, has been shown to hallucinate features that are not supported by the training data. In this study we assess perceptual loss[7] as a means to introduce data consistency by forcing our models to retain essential image representations during the enhancement process.Methods
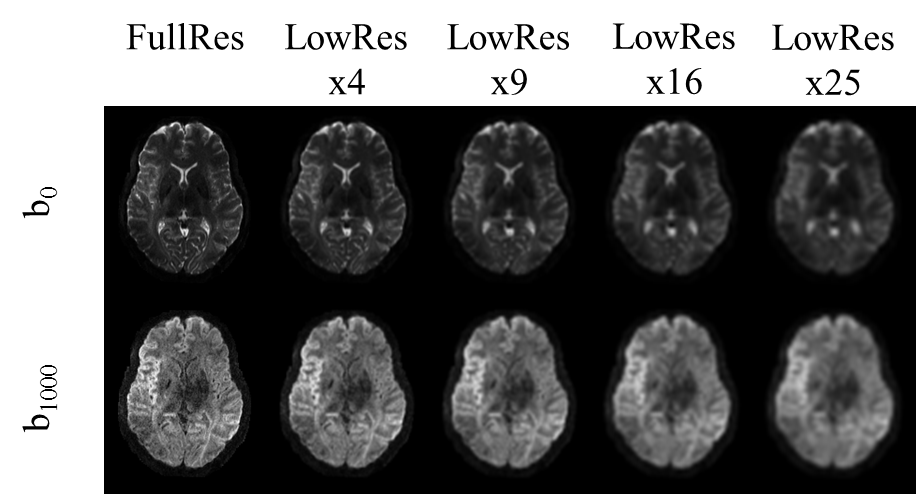
All training, validation, and testing of AI models was done using fastAI[8], the young adult data set (7T, 1.25 mm isotropic resolution) of the human connectome project (https://www.humanconnectome.org/study/hcp-young-adult) and two NVIDIA GeForce 2080 Ti (11 GB). For training and validation of models we used n=12 data sets (296868 images, 9:1 split) and testing was done on an additional n=4 datasets. Two different approaches were examined to achieve 4-, 9-, 16-, and 25-fold in-plane resolution enhancement: a NoGAN[9] (Generative Adversarial Model) and a model based on perceptual loss. The latter was tested for convolutional parts of two different architectures, namely VGG16 and ResNet34. Images were converted to png format and downsampled, creating respective image pairs of low and high resolution (Figure 1). All training steps applied fastAIs one cycle policy[10] with batch size = 12.For the NoGAN we applied three steps: pre-train an image generator for artificial high resolution images 2) use artificial and real images to pre-train a binary critic, 3) combine the models for GAN-like training (15 epochs). Training of all models using perceptual loss was done for 30 epochs (15 frozen, 15 unfrozen). MR parameters of the 7T HCP data were TE/TR: 71.2/7000 ms, 1.0mm isotropic voxels, 6 reference images, 64 directions (b=1000s/mm2, b=2000s/mm2), 6-fold acceleration (RMultiband=2, RGRAPPA=3). Final images were calculated based on two scans with inverse phase encoding. For training of our models we used the processed HCP data.
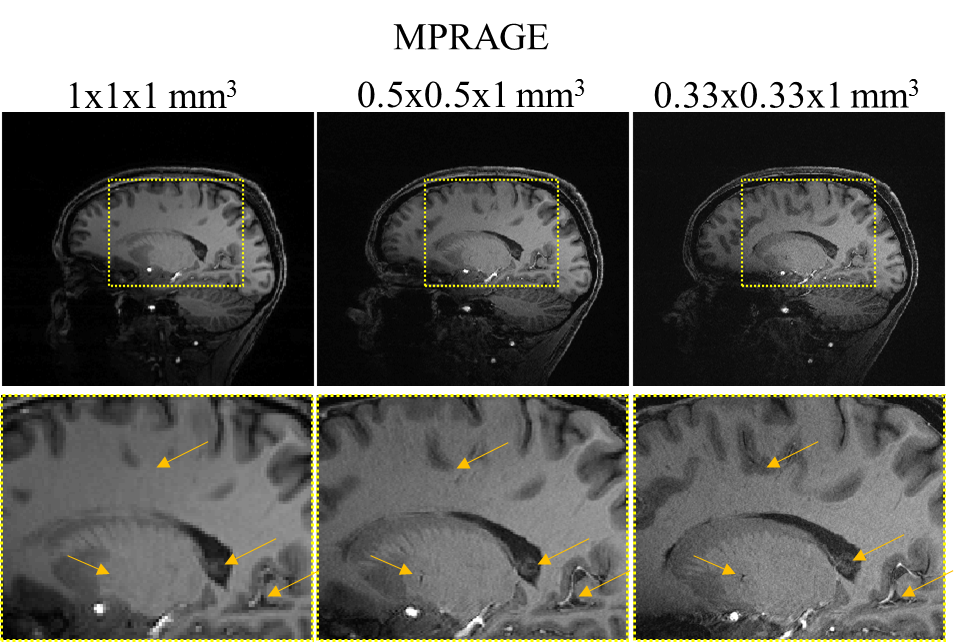
For further validation of our models, we acquired DTI data in n=4 volunteers using a 7T Terra system (Siemens Healthineers, Erlangen) and a 1TX/32RX head coil (Noval Medical). Parameters for the ground truth high resolution scan were TE/TR: 63/5800ms, 1.3mm isotropic voxels, 6 reference images, 64 directions (b=1000 s/mm2), 6-fold acceleration (RSMS=2, RGRAPPA=3). The same protocol with TE/TR: 55/4000ms was run at lower resolution (2.5mm isotropic voxels) as well. Complete data sets were acquired with inverse phase encoding for post processing. Scan times at high and low resolution were 7:36min and 5:04min, respectively. Denoising of our data was done using overcomplete local PCA.[11] MPRAGE images were acquired with varying spatial resolution (1mm x 1mm x 1mm, 0.5mm x 0.5mm x 1mm, 0.33mm x 0.33mm x 1mm,) to provide data for co-registration and to assess potential resolution increases at 7T in anatomical scans.
Results
Figure 2 shows representative MPRAGE images acquired using the 7T Terra system. We found that increasing the in-plane resolution by factors of 4 and 9 compared to 1mm isotropic resolution already enables the depiction and delineation of smaller structures, vessels and cavities in anatomical images.We performed DTI reconstructions for data measured on the 7T Terra system and the HCP data. Representative FA maps for two slices are shown in Figure 3. Increases in spatial resolution are clearly visible and enabled reconstructions of finer pathways.
For perceptual loss we fed input and output of our model through a VGG16 or a ResNet34 and we grabbed the activations or feature maps directly before the pooling layer, providing us with three feature maps for the VGG16 and five feature maps for the ResNet34. Flattened feature maps were used to create gram matrices, which basically represent the style of our images. L1 losses between feature maps and L1 losses between gram matrices were applied during model training.
The training process exemplary for 9-fold resolution enhancement is plotted in Figure 4, where feature loss and gram loss are split in the individual components. Training durations were consistent within a model type, despite different target resolutions. In total training of a single NoGAN and perceptual loss (VGG16, ResNet34) model required ~70 hours, ~31 hours, and ~23 hours, respectively.
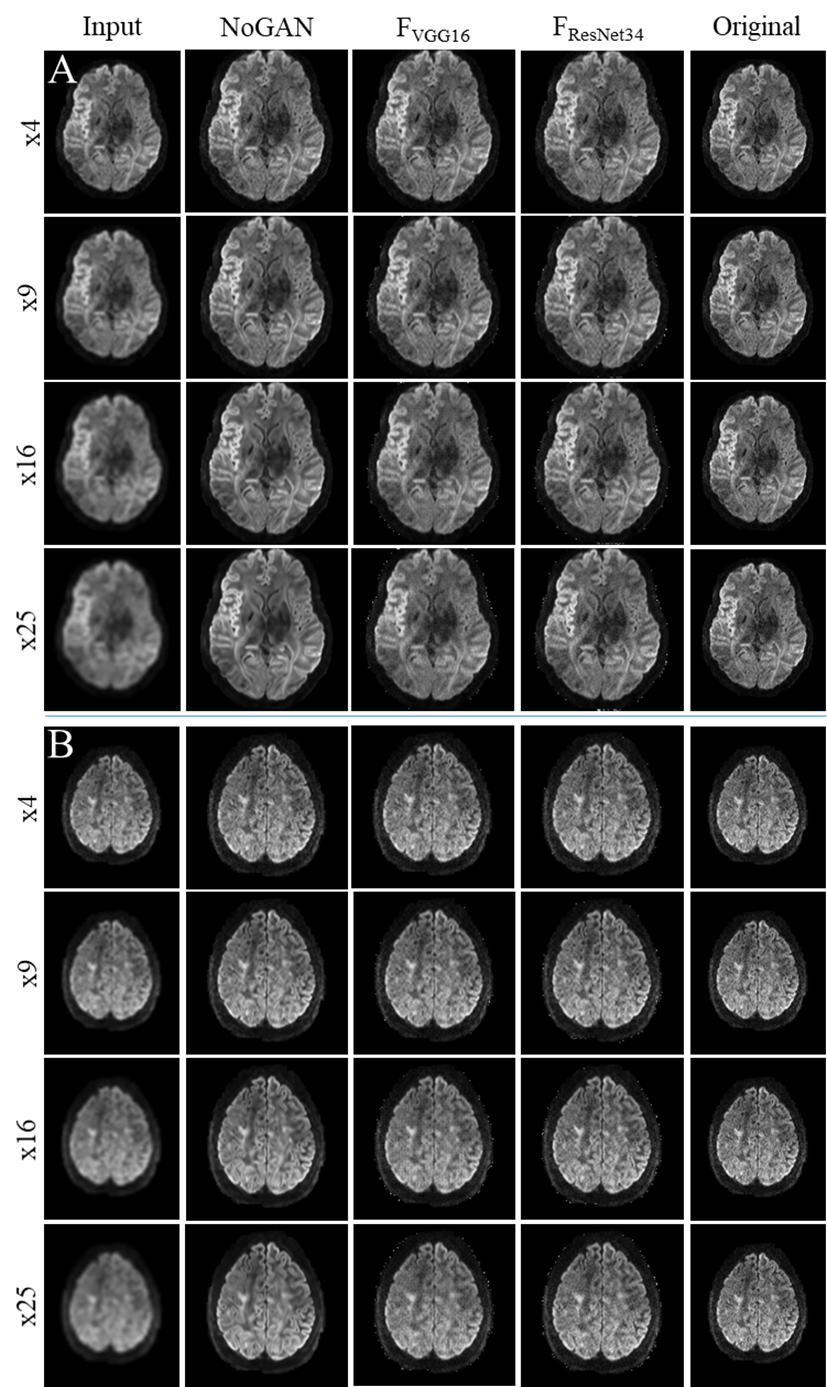
Quality of resolution enhancements achievable with the various models is demonstrated in Figure 5.
Discussion
We successfully used publicly available data from the human connectome project to train multiple models for resolution enhancement of 7T diffusion images of the brain. Lower input resolutions (16-, and 25-fold) led to "hyper" realistic (smooth, noise free) images in NoGAN enhancement, while both models based on perceptual loss seem to retain features common to MR images, such as noise. Future DTI reconstructions will show, whether upsampled images also retain their diffusion information and whether models are applicable to the 7T Terra data.Conclusion
In this study we demonstrate that AI models trained on a moderate number of datasets (n=12) are able to enhance image resolutions in diffusion MRI up to 25 times.Acknowledgements
Financial support: German Ministry of Education and Research (BMBF, grant: 01E1O1504). We thank Markus J Ankenbrand for support regarding model predictions.References
1. Akkus, Z., et al., Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions. Journal of Digital Imaging, 2017. 30(4): p. 449-459.
2. Zhu, G., et al., Applications of Deep Learning to Neuro-Imaging Techniques. Frontiers in Neurology, 2019. 10(869).
3. Lyu, Q., H. Shan, and G. Wang MRI Super-Resolution with Ensemble Learning and Complementary Priors. arXiv e-prints, 2019.
4. Chen, Y., et al. MRI Super-Resolution with GAN and 3D Multi-Level DenseNet: Smaller, Faster, and Better. arXiv e-prints, 2020. arXiv:2003.01217.
5. Chen, Y., et al. Brain MRI Super Resolution Using 3D Deep Densely Connected Neural Networks. arXiv e-prints, 2018.
6. Alexander, D.C., et al., Image quality transfer and applications in diffusion MRI. NeuroImage, 2017. 152: p. 283-298.
7. Johnson, J., A. Alahi, and L. Fei-Fei Perceptual Losses for Real-Time Style Transfer and Super-Resolution. 2016. arXiv:1603.08155.
8. Howard, J. and S. Gugger, Fastai: A Layered API for Deep Learning. Information, 2020. 11(2): p. 108.
9. Antic, J., J. Howard, and U. Manor, Decrappification, Deoldification, and super resolution. 2019. 10. 10. Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1 -- learning rate, batch size, momentum, and weight decay. 2018. arXiv:1803.09820.
11. Manjon, J.V., et al., Diffusion Weighted Image Denoising Using Overcomplete Local PCA. PLoS One, 2013. 8(9).
Figures