1837
Semantic CMR Synthesis: Generating Coherent Short- and Long-Axis Images with Corresponding Multi-Class Anatomical Labels1University and ETH Zurich, Zurich, Switzerland
Synopsis
We propose to use a combination of the StyleGAN2, ADA and DatasetGAN methods to produce synthetic short- and long-axis view cardiac magnetic resonance (CMR) images accompanied with corresponding 11-class tissue masks. The image generator networks are trained on datasets of approximately 1850 and 5000 unlabelled images, for short- and long-axis images respectively. The segmentation networks are trained on only 30 manually annotated synthetic images in total. We further demonstrate a proof-of-concept method for generating coherent long- and short-axis images of the same synthetic patient.
Introduction
Synthetic magnetic resonance (MR) images are of growing importance in MR research. Such images can be used to expand existing datasets, to address particular data imbalances, and to provide data with rich ground truth information. Previous approaches generally generate short-axis images conditioned on input segmentation masks1-3. Here we present a method for generating realistic synthetic exams, consisting of both short- and long-axis images of synthetic patients. Additionally, all synthesised images have corresponding segmentation masks consisting of 11 classes.Methods and Results
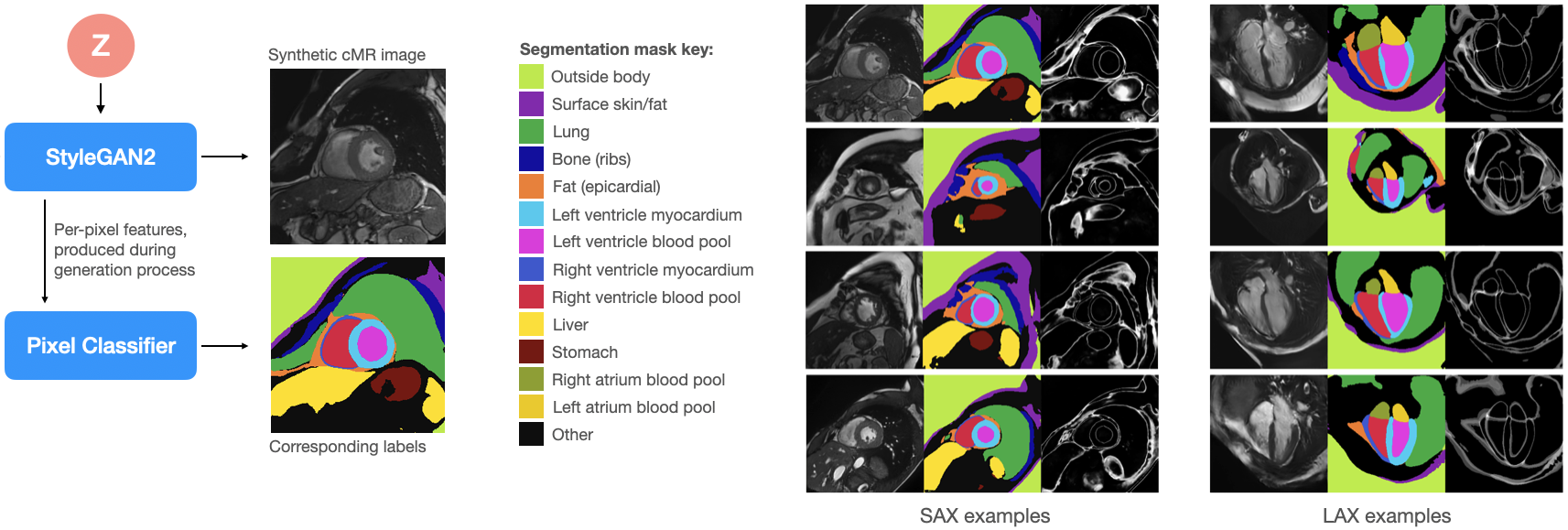
We make use of state-of-the-art methods to produce high quality synthetic images from relatively low numbers of real images. Specifically, we use SyleGAN24 with ADA5 to train two separate generative models: one for short-axis (SAX) and one for long-axis (LAX) images. We train on 256x256 pixel images resampled to 1mm isotropic resolution and rotated to a standard view. The SAX/LAX models were trained on 1841 SAX images from ACDC6 and 4935 LAX images from Kaggle7 and the M&M challenge8.After training the StyleGANs we follow the method proposed in DatasetGAN9. Specifically, we train a network that classifies pixels in the generated image based on the intermediate features produced in the generator network during image generation. Thus, whenever an image is generated, a corresponding segmentation mask is also produced. To this end, a small number of generated images must be segmented for training. We hand-labelled 20 SAX and 10 LAX images with 11 classes each (9 of which are shared between the two views), plus an “other” class as a catch-all for unlabelled pixels (Figure 1 top).
As in DatasetGAN9, we train an ensemble of 10 segmentation networks, enabling the production of a confidence score for every pixel, based on the agreement between the 10 classifiers (we are less “confident” about pixels where the classifiers disagree). This confidence mask can be seen as a measure of the label certainty, and also as a proxy for the synthetic image quality overall, as low quality synthesised images tend to result in more disagreement between classifiers (Figure 1 bottom).
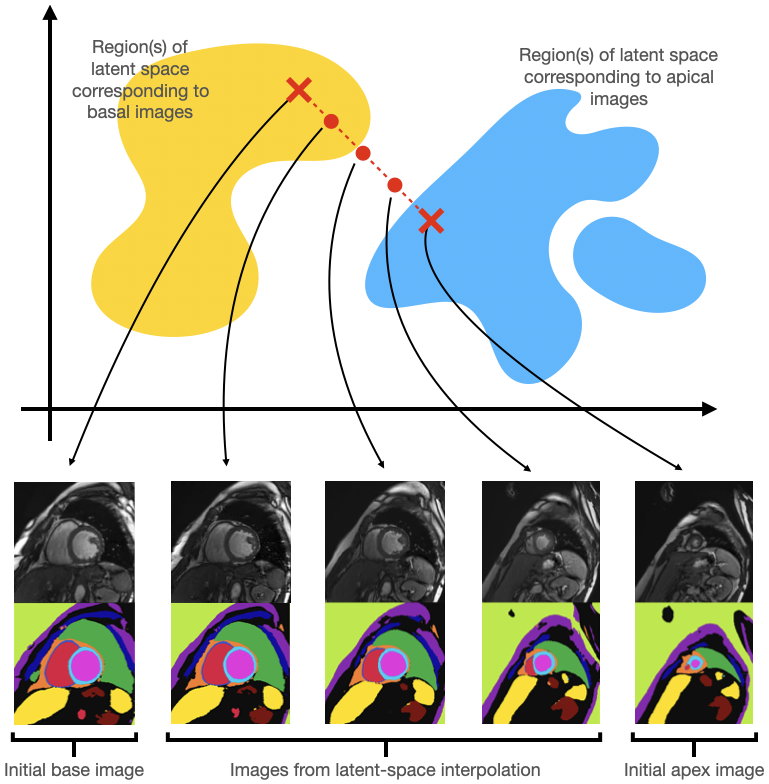
Our generators yield individual labelled SAX and LAX images. We next explore how a coherent set of SAX slices can be generated to emulate a standard multi-slice acquisition. First, we generate 200 random SAX images and heuristically classify each image, using its accompanying segmentation mask, as either basal (large amount of ventricles and lung visible), apical (small amount of ventricles and lung visible) or mid-ventricular (all other images). By choosing a basal and apical image at random, and interpolating between their latent representations, we can use these intermediate latent representations to generate “intermediate” images. These intermediate images in fact provide a good approximation to moving the SAX plane along the long axis of the left ventricle (LV) from the initial basal slice towards the apical slice, see Figure 2.
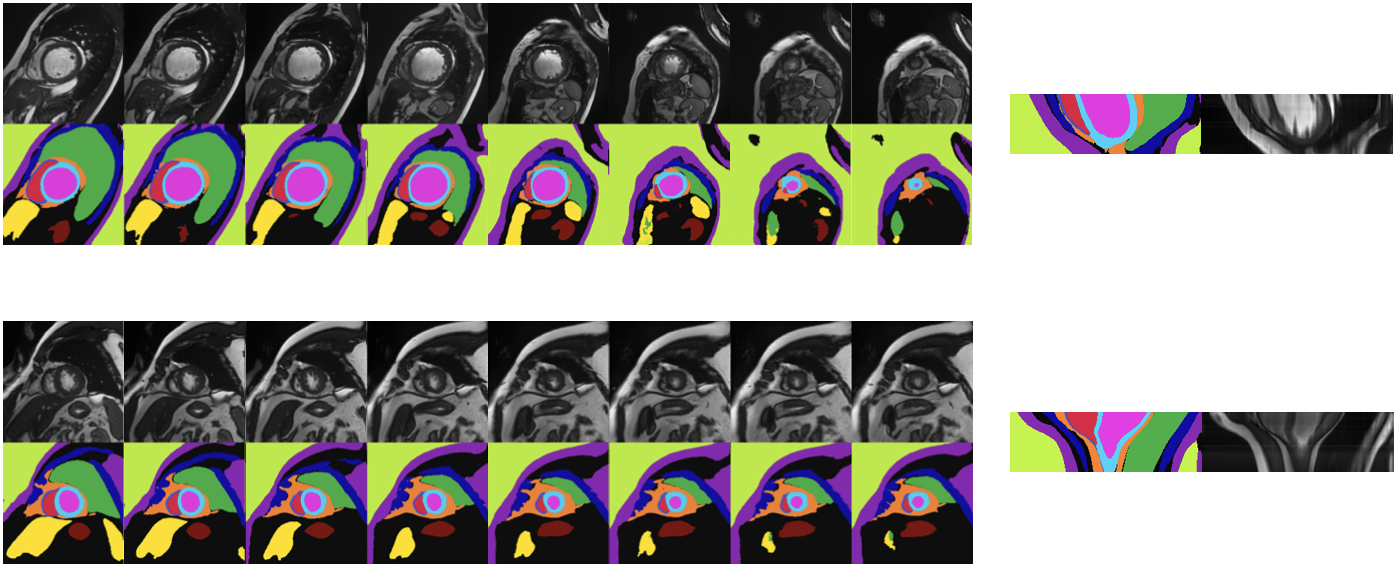
This technique allows us to generate a “stack” of SAX images, with the image content changing smoothly as we move through the stack, slowly transitioning from a basal to an apical image. However, taking a long-axis slice through the centre of these stacks reveals that a smooth transition between base and apex is not alone sufficient to create a realistic stack of SAX images. In particular, the LV structure in the long-axis direction is often non-physiological, see Figure 3.
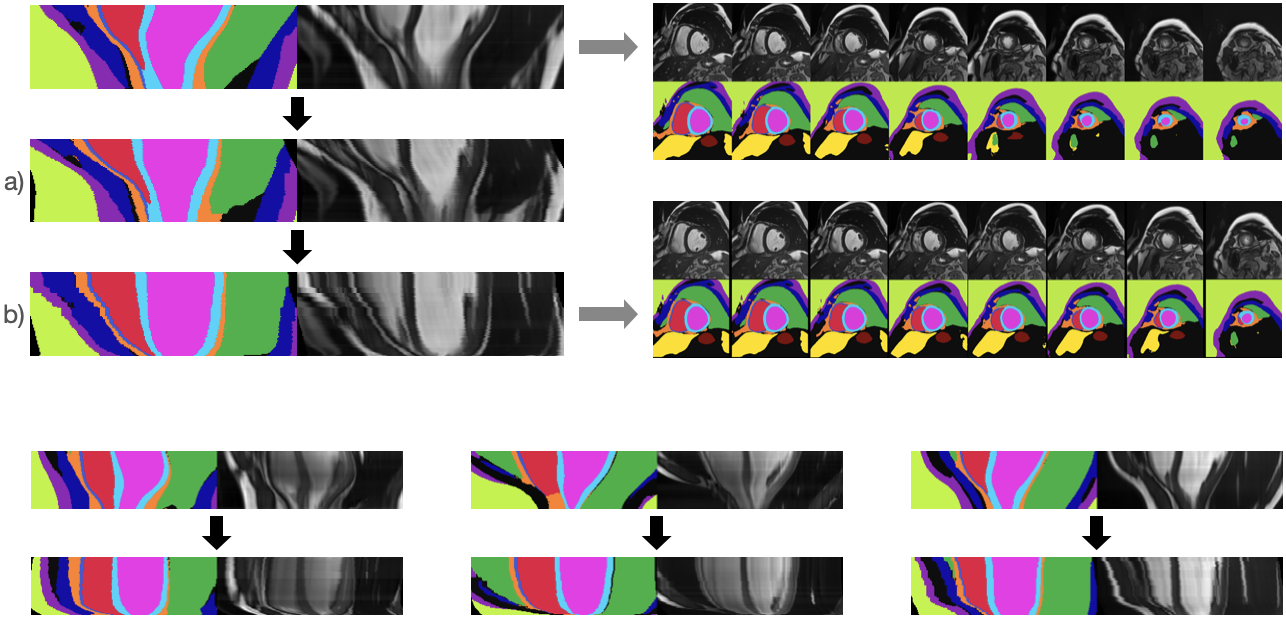
To overcome this, we make two adjustments to the way we generate SAX image stacks: Firstly, we shift the generated SAX images in-plane so as to create a straight LV. Secondly, rather than sampling uniformly between the latent representations of the basal and apical images to generate intermediate slices, we instead sample such that the change in LV width as we move down through the SAX image stack matches the change seen in a template LAX image (e.g. from the LAX image generator). In practice, this means that rather than the LV width decreasing approximately linearly as we move down the long-axis, instead the width decreases slowly for the first ~75% of the LV’s length, and decreases rapidly thereafter. Results of these corrections are shown in Figure 4.
Given the resulting SAX stacks with improved physiological plausibility, we lastly show a proof-of-concept for the potential to find a synthetic LAX images that matches the anatomy seen in our synthesised SAX stacks, Figure 5.
Discussion and Conclusion
We have demonstrated generation of realistic labelled SAX image stacks, and corresponding labelled LAX images. These synthetic images could be combined with a bio-mechanical mesh model, as in Joyce et al10, and then deformed based on simulated mesh deformation to generate multi-slice/multi-view temporal data with known underlying cardiac dynamics. A shape model could also be used to more rigorously correct the long-axis LV shape.When generating coherent SAX/LAX images, agreement on the heart itself is good. We believe overall agreement could be improved by also matching segmentation masks when generating the LAX view.
Lastly, the synthetic images have many more label classes than existing datasets (such as ACDC6), and could be used to train multi-class segmentation networks, allowing the prediction of detailed anatomical labels for real images. These could in turn be used to improve conditional synthesis approaches1,2, or for quantitate evaluation of MR simulation methodologies.
Acknowledgements
We would like to acknowledge that the first two authors contributed equally to the work presented in this abstract. Funding of the Swiss National Science Foundation, grant 325230-197702, is gratefully acknowledged.References
1. Amirrajab, Sina, et al. "Xcat-gan for synthesizing 3d consistent labeled cardiac mr images on anatomically variable xcat phantoms." International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2020.
2. Abbasi-Sureshjani, Samaneh, et al. "4D semantic cardiac magnetic resonance image synthesis on XCAT anatomical model." Medical Imaging with Deep Learning. PMLR, 2020.
3. Joyce, Thomas, and Sebastian Kozerke. "3D medical image synthesis by factorised representation and deformable model learning." International Workshop on Simulation and Synthesis in Medical Imaging. Springer, Cham, 2019.
4. Karras, Tero, et al. "Analyzing and improving the image quality of stylegan." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
5. Karras, Tero, et al. "Training generative adversarial networks with limited data." arXiv preprint arXiv:2006.06676 (2020).
6. Bernard, Olivier, et al. "Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved?." IEEE transactions on medical imaging 37.11 (2018): 2514-2525.
7. Data Science Bowl Cardiac Challenge Data, https://www.kaggle.com/c/second-annual-data-science-bowl/
8. Campello, Víctor M., et al. "Multi-Centre, Multi-Vendor and Multi-Disease Cardiac Segmentation: The M&Ms Challenge." IEEE Transactions on Medical Imaging (2021)
9. Zhang, Yuxuan, et al. "Datasetgan: Efficient labeled data factory with minimal human effort." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
10. Joyce, Thomas, et al, "Rapid Personalisation of Left Ventricular Meshes using Differentiable Rendering" ISMRM 2021, digital poster 2900.
Figures