1755
Late feature fusion and GAN-based augmentation for generalizable cardiac MRI segmentation1Biomedical Engineering, Eindhoven University of Technology, Eindhoven, Netherlands, 2Philips Research Laboratories, Hamburg, Germany, 3Philips Healthcare, MR R&D - Clinical Science, Best, Netherlands
Synopsis
While recent deep-learning-based approaches in automatic cardiac magnetic resonance image segmentation have shown great promise to alleviate the need for manual segmentation, most are not applicable to realistic clinical scenarios. This is largely due to training on mainly homogeneous datasets, without variation in acquisition parameters and pathology. In this work, we develop a model applicable in multi-center, multi-disease, and multi-view settings, where we combine heart region detection, augmentation through synthesis and multi-fusion segmentation to address various aspects of segmenting heterogeneous cardiac data. Our experiments demonstrate competitive results in both short-axis and long-axis MR images, without physically acquiring more training data.
Introduction
Cardiac magnetic resonance (CMR) imaging has become a standard tool in cardiac function assessment, providing an accurate computation of cardiac functional parameters in a noninvasive manner1. An accurate segmentation of the heart is a prerequisite to this assessment, particularly the right (RV) and left (LV) ventricular cavities, as well as the left ventricular myocardium (MYO)2. Despite recent developments, automated segmentation using deep learning (DL) approaches remains challenging, especially considering limited data availability and privacy concerns3. Algorithms trained and evaluated on samples from single centers often fail to adapt to variations in tissue contrast and intensity, as well as the field of view (FOV) arising due to different acquisition parameters across sites4. Additional challenges related to CMR segmentation arise due to complex heart motion and anatomy, as well as pathology, manifesting in unclear cavity borders, presence of trabeculations in the cavity and complex RV shape5. We propose a long-axis (LA) and short-axis (SA) CMR synthesis and segmentation pipeline designed to address the challenges of multi-site and multi-vendor data.Methods
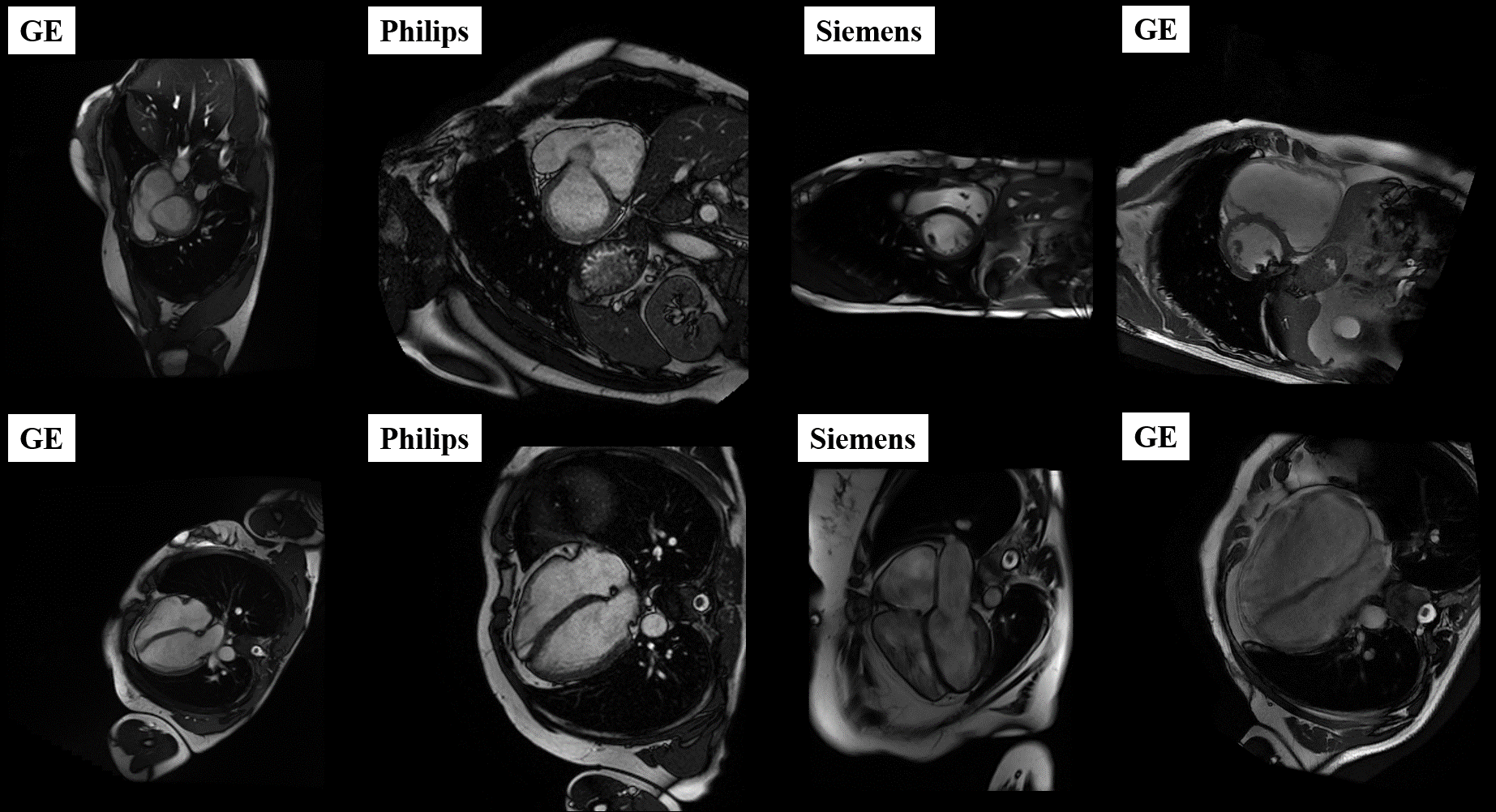
Our approach is developed and evaluated on the M&Ms-26 challenge data, comprised of 360 subjects with various RV and LV pathologies, as well as healthy subjects, with expert annotations of RV, LV and MYO (see Fig.1). A total of 160 cases are used for training, and 40 cases for algorithm validation. The final algorithm is evaluated on an unknown test set containing 160 cases, with pathologies outlined in Table 1a.The proposed pipeline is depicted in Fig. 2a, consisting of region of interest (ROI) detection, conditional image synthesis for data augmentation, and segmentation through late fusion, utilizing transformed versions of input images during training. The first stage utilizes a regression-based 5-layer convolutional neural network (CNN) trained to detect a bounding box encompassing the complete heart in SA images and the region of LV cavity, myocardium, and RV cavity in LA images. The detected bounding boxes are then used to crop the input images of the heart at segmentation inference time.
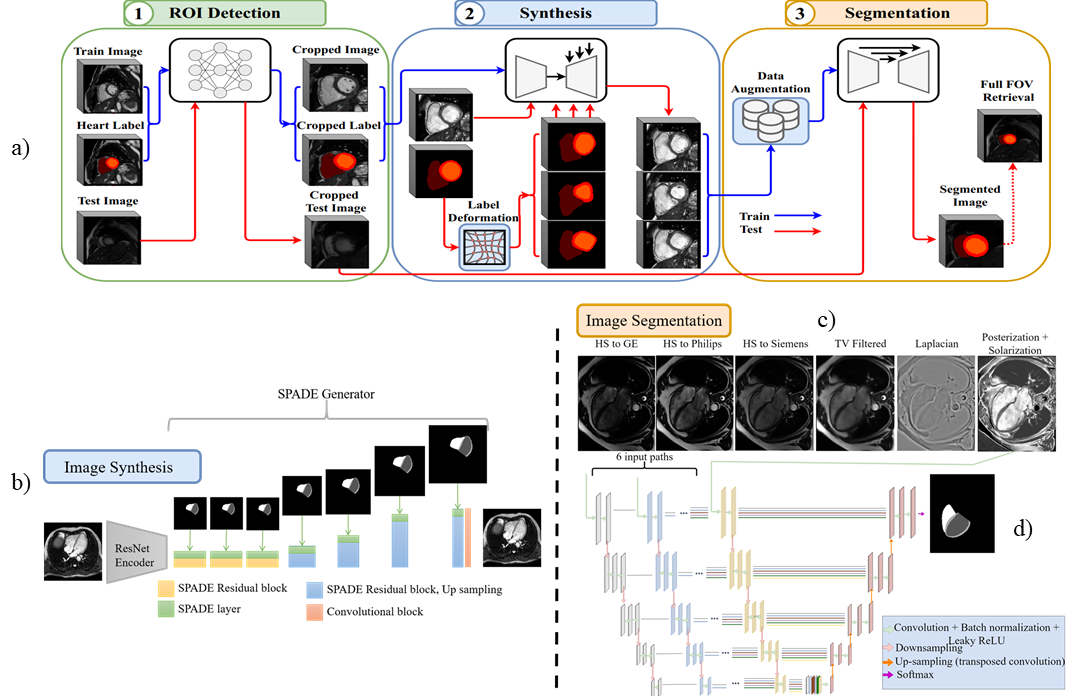
The training data for LA and SA segmentation is further boosted using the image synthesis module depicted in Fig. 2b. This module includes a ResNet-based encoder7 for image style extraction, coupled with a mask-conditional generator that uses SPADE8,9,10 normalization layers to preserve the content of the input label map. To address the imbalanced number of cases per vendor in the real train set, we generate 1000 synthesized cases per vendor with elastically and morphologically deformed labels. For each vendor-specific subset, we further identify the outlier cases based on the end-diastolic or end-systolic volume for the RV calculated using the ground truth label of the SA images (Fig.3). Our experiments show that these outliers are difficult to segment as they significantly differ in anatomy compared to other subject, caused by the presence of severe pathology. We use the detected outliers for image synthesis by applying random label deformations. A similar approach is applied to synthesize basal slices in the SA stacks, which may not be frequently seen during segmentation training.
To address variations in contrast and intensity homogeneity, we generate six contrast-transformed versions per training image (Fig. 2c), using histogram standardization, edge preserving filtering, solarization and posterization, and a Laplacian filter. Inspired by multi-modal CNNs and late fusion approaches, we modify a typical U-Net to include multiple encoder layers processing each transformed image fed at the input (Fig. 2d), whose outputs are fused in the bottleneck. This allows the network to learn complementary information between different transformations of each image. as well as a better representation of their interrelationships. Both models for SA and LA segmentation are designed in a 2D fashion according to nnUNet11 guidelines, with extensions to achieve a multi-encoder setup.
Results and Discussion
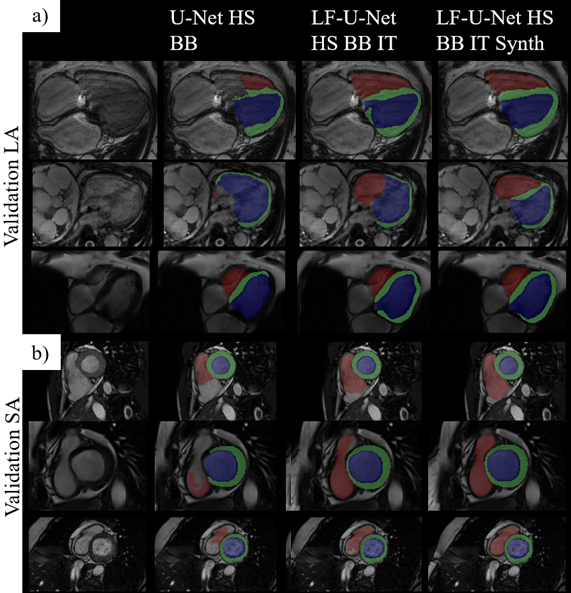
We compare the proposed approach to several models containing a different set of pipeline components, outlined in Table 1b, on the performance scores obtained from the challenge submission platform (Dice and Hausdorff distance (HD) on the validation set). Fig.4 shows segmentation results obtained by different models on some of the examples in the validation set. We observe that the addition of transformations and synthetic data helps the model in handling examples with unclear boundaries, low tissue contrast and distinct presence of pathology. However, the major improvements are seen with the employment of the late-fusion model combined with synthetic data, which allows the model to extract more variable image features through different encoding paths processing different representations of each image. The addition of synthetic images introduces more examples of hard cases and helps with network regularization and generalization. On the unseen test set, the model yields scores of 0.912 and 0.895 in terms of Dice and 11.74 and 7.85 in terms of HD, for SA and LA images respectively.Conclusion
This study demonstrates that having a diverse training dataset plays the main role in obtaining a robust and generalizable segmentation model. However, since this is typically not possible, especially with pathology, we present an approach that utilizes recent advances in image synthesis and classical pre-processing methods, which positively impacts network performance in challenging scenarios, without needing to physically acquire more data.Acknowledgements
This research is a part of the OpenGTN project, supported by the European Union in the Marie Curie Innovative Training Networks (ITN) fellowship program under project No. 76446.References
1. Attili, A.K., Schuster, A., Nagel, E., Reiber, J.H. and Van der Geest, R.J., 2010. Quantification in cardiac MRI: advances in image acquisition and processing. The international journal of cardiovascular imaging, 26(1), pp.27-40.
2. Chen, C., Qin, C., Qiu, H., Tarroni, G., Duan, J., Bai, W. and Rueckert, D., 2020. Deep learning for cardiac image segmentation: a review. Frontiers in Cardiovascular Medicine, 7, p.25.
3. Rumsfeld, J.S., Joynt, K.E. and Maddox, T.M., 2016. Big data analytics to improve cardiovascular care: promise and challenges. Nature Reviews Cardiology, 13(6), pp.350-359.
4. Campello, V.M., Gkontra, P., Izquierdo, C., Martín-Isla, C., Sojoudi, A., Full, P.M., Maier-Hein, K., Zhang, Y., He, Z., Ma, J. and Parreño, M., 2021. Multi-Centre, Multi-Vendor and Multi-Disease Cardiac Segmentation: The M&Ms Challenge. IEEE Transactions on Medical Imaging.
5. Grosgeorge, D., Petitjean, C., Caudron, J., Fares, J. and Dacher, J.N., 2011. Automatic cardiac ventricle segmentation in MR images: a validation study. International journal of computer assisted radiology and surgery, 6(5), pp.573-581.
6. Multi-Disease, Multi-View & Multi-Center Right Ventricular Segmentation in Cardiac MRI (M&Ms-2), STACOM2021, MICCAI2021. https://www.ub.edu/mnms-2/.
7. He, K., Zhang, X., Ren, S. and Sun, J., 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
8. Park, T., Liu, M.Y., Wang, T.C. and Zhu, J.Y., 2019. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2337-2346).
9. Abbasi-Sureshjani, S., Amirrajab, S., Lorenz, C., Weese, J., Pluim, J. and Breeuwer, M., 2020. 4D semantic cardiac magnetic resonance image synthesis on XCAT anatomical model. In Medical Imaging with Deep Learning (pp. 6-18). Proceedings of the Third Conference on Medical Imaging with Deep Learning, PMLR 121
10. Amirrajab, S., Abbasi-Sureshjani, S., Al Khalil, Y., Lorenz, C., Weese, J., Pluim, J. and Breeuwer, M., 2020. Xcat-gan for synthesizing 3d consistent labeled cardiac mr images on anatomically variable xcat phantoms. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 128-137). Springer, Cham.
11. Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J. and Maier-Hein, K.H., 2021. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2), pp.203-211.
Figures