1510
All you need are DICOM images1University Medical Center Göttingen, Göttingen, Germany, 2German Centre for Cardiovascular Research (DZHK), Partner Site Göttingen, Göttingen, Germany, 3Institute of Medical Imaging, Graz University of Technology, Graz, Austria, 4Cluster of Excellence "Multiscale Bioimaging: from Molecular Machines to Networks of Excitable Cells'' (MBExC), University of Göttingen, Göttingen, Germany
Synopsis
Most deep-learning-based reconstructions methods need predefined sampling patterns and precomputed coil sensitivities for supervised training, limiting their later use in applications under different conditions. Furthermore, only the magnitude images are always stored in DICOM format in the Picture Archiving and Communication System (PACS) of a typical radiology department. That means that raw k-space data is usually not available. This work focuses on how to extract prior knowledge from magnitude images (DICOM) and how to apply the extracted prior to reconstruct images from k-space multi-channel data sampled with different schemes.
Introduction
Reconstruction methods for parallel imaging with deep learning were shown to outperformed conventional methods, benefiting from the learnt information. However, most of them need predefined sampling patterns and precomputed coil sensitivities for supervised training, limiting their flexibility in applications. Furthermore, only the magnitude images are always stored in DICOM format with the Picture Archiving and Communication System (PACS). That means that collecting raw k-space data or complex-valued images is inconvenient in practice. This work focuses on how to extract prior knowledge from magnitude images (DICOM) and how to apply the extracted prior to reconstruct images from k-space multi-channel data sampled using different sampling schemes. The two main contributions of this work are: 1) the learned prior can be used as a regularization term on image content in non-linear inversion independent from sampling scheme and coil sensitivities; and 2) the prior knowledge can be extracted from magnitude images.Theory
Parallel MR imaging can be formulated as a nonlinear inverse problem as follow $$F(\rho, c):=(\mathcal{F}_S(\rho\cdot c_1), \cdots, \mathcal{F}_S(\rho\cdot c_N)) = {y},$$ where $$$\mathcal{F}$$$ is sampling operator and the corresponding k-space data is $$${y} = (y_1, \cdots, y_N)^T$$$, and the spin density $$$\rho$$$ and the coil sensitivities $$${c}=(c_1, \cdots, c_N)^T$$$. As proposed in the nonlinear inverse reconstruction (nlinv)1, this problem can be solved with the Iterative Gauss Newton Method (IRGNM) by estimating $$$\delta m:=(\delta \rho, \delta c)$$$ in each step $$$k$$$ for given $$$m^k:=(\rho^k, c^k)$$$ with the following minimization problem $$ \underset{\delta x}{\min} \frac{1}{2}\|F'(m^k)\delta x+F(m^k) - \boldsymbol{y}\|_2^2 + \frac{\alpha_k}{2}\mathcal{W}(\boldsymbol{c}+\delta c) + \beta_k{R}(\rho^k+\delta \rho), \quad (1)$$ where $$$\mathcal{W}({c})=\|W{c}\|^2=\|w\cdot\mathcal{F}{c}\|$$$ is a penalty on the high Fourier coefficients of the coil sensitivities and $$$R$$$ is a regularization term on $$$\rho$$$. The $$$\alpha_k$$$ and $$$\beta_k$$$ decay based on reduction factor over iteration steps. In this work, the neural network based log-likelihood prior2 was investigated, formulated with following joint distribution \begin{equation*} \log P(\hat{\Theta}, \boldsymbol{x}) = p(\boldsymbol{x};\mathtt{NET}(\hat{\Theta}, \boldsymbol{x}))=p(x^{(1)})\prod_{i=2}^{n^2} p(x^{(i)}\mid x^{(1)},..,x^{(i-1)}), \quad (2) \end{equation*} where the neural network $$$\mathtt{NET}(\hat{\Theta}, \boldsymbol{x})$$$ is a PixelCNN++ model which outputs the distribution parameters of the mixture of logistic distribution which are used to model images. For each step, the fast iterative gradient descent method (FISTA)3 is used to minimize Eq (1). The proximal operation on $$$\log P(\hat{\Theta}, \boldsymbol{x})$$$ was approximated using gradient updates. The gradient of $$$\log P(\hat{\Theta}, \boldsymbol{x})$$$ is computed via backpropagation.Methods
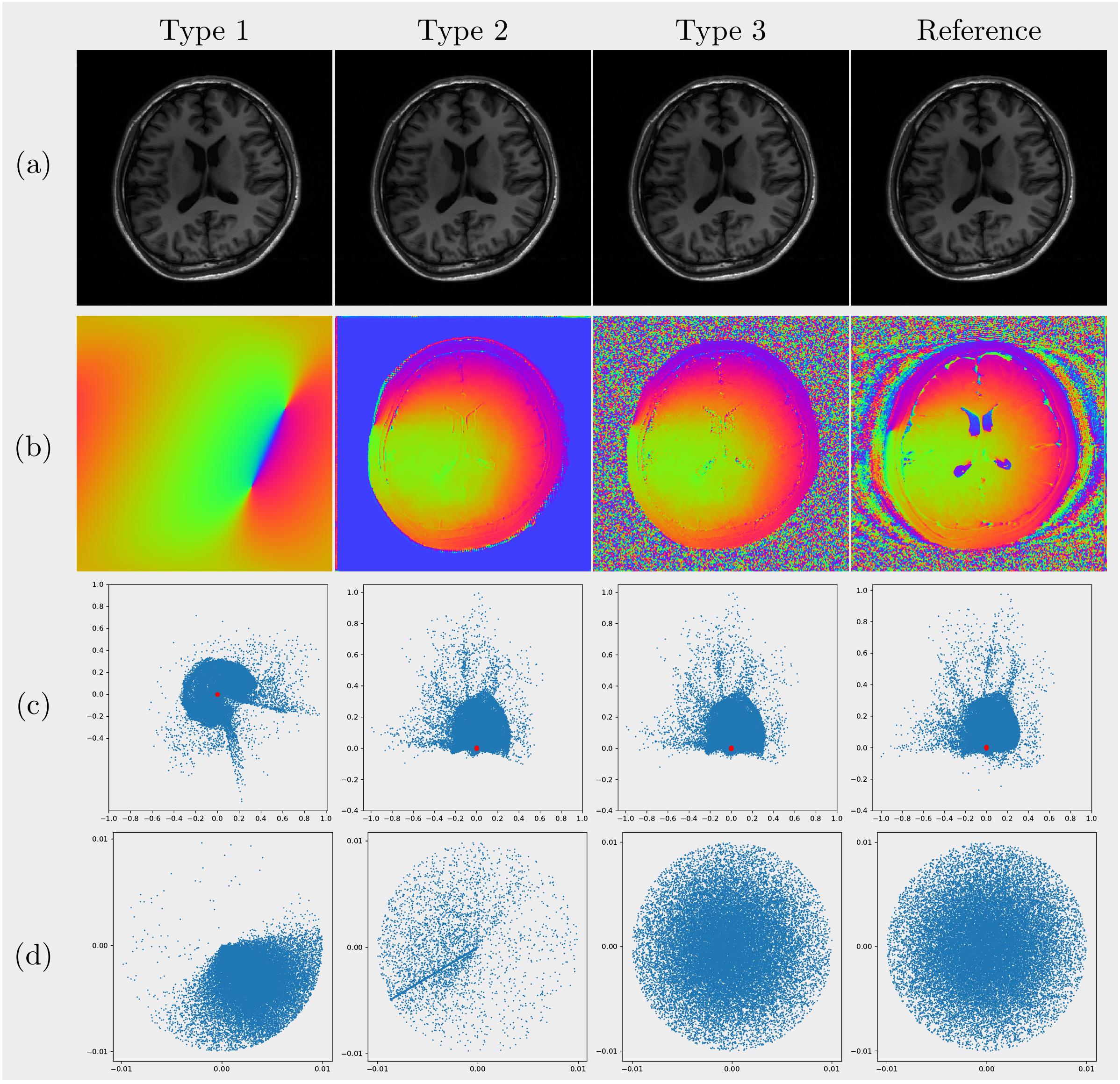
Phase augmentation: The loss of phase information in DICOM images leads to the trained prior having no knowledge about the relationship between real and imaginary channels. To deal with this problem, we tried 3 approaches to obtain phase maps for magnitude images.- For random phase simulation a 2x2 matrix of random complex numbers is transformed into a complex image of a specified size using the inverse Fast Fourier transform, the phase of which is then applied to a DICOM image.
- A U-Net is trained to predict complex images given DICOM images. The complex images in [2] are used as labels.
- The predicted phase from 2. is almost constant in the background, which distorts the distribution of pixels, as shown in Figure 2 where a certain number of pixels align on a line instead of being distributed roughly evenly in a circle. To compensate for this, we add a very small amount of Gaussian noise to the prediction and then extract the phase.
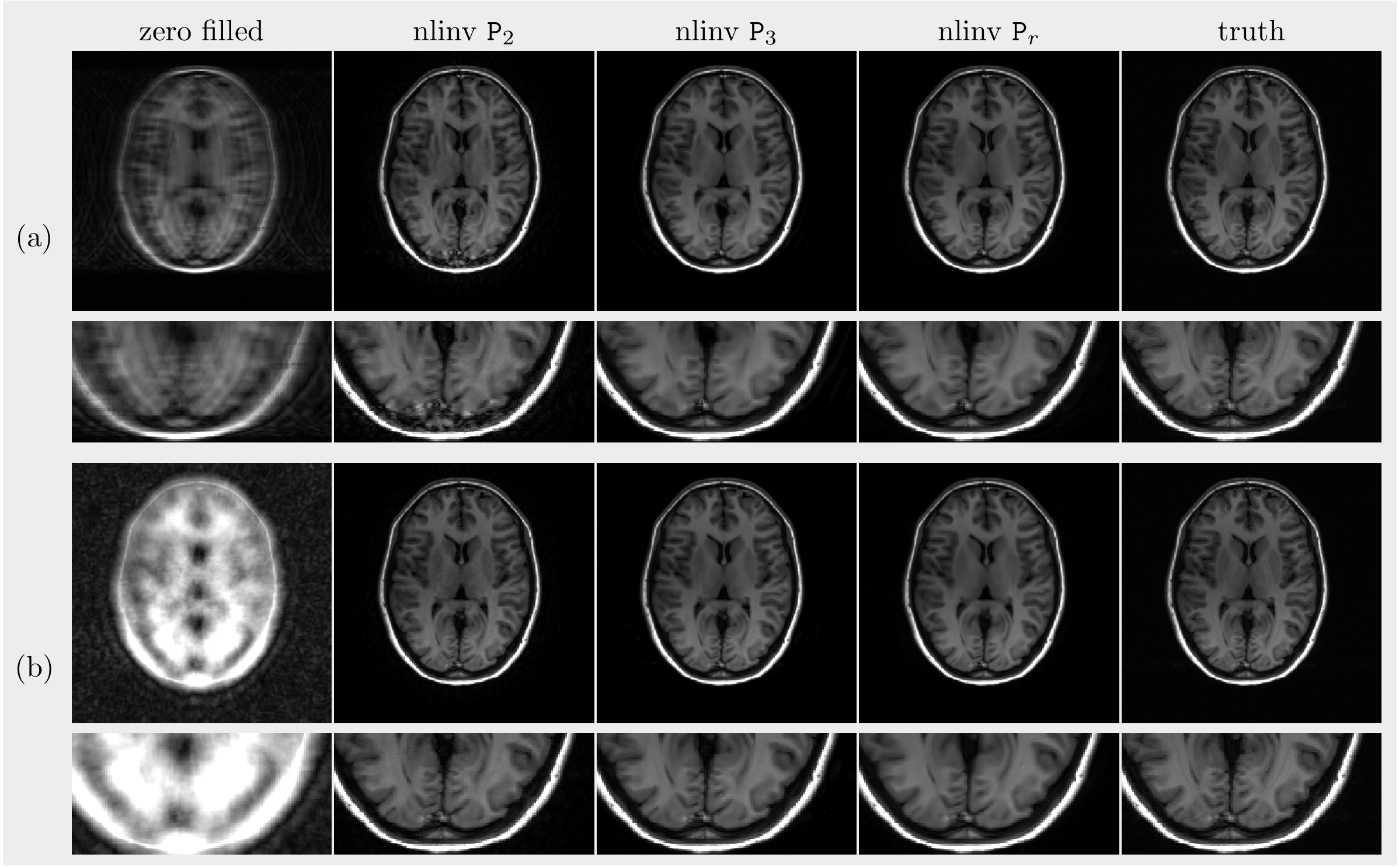
Retrospective experiment: To compare the three trained priors, we reconstructed images from the k-space data acquired with different schemes, using them as regularization terms. For the optimization in Eq (1), the algorithm was implemented within the BART toolbox4 with the nonlinear operator framework.
Results and Discussion
Phase augmentation: As shown in Figure 2, the simulated phase is smooth in the field of view and independent of the image content. Because of this independence, the scatter plot of the correspondingly augmented complex image over real and imaginary channels is distorted. The U-Net provides the content-depended phase but the clean phase aligns most background pixels along a line. The perturbed predicted phase give the most realistic complex image.Retrospective experiment: Since Eq. (2) models the relationship between real and imaginary channels as investigated in [2], it is expected to see that $$$\mathtt{P}_2$$$ performs worse than $$$\mathtt{P}_3$$$ and $$$\mathtt{P}_r$$$, especially in the case of the large number of missing phase encoding lines with many folding artifacts remaining. As can be seen, $$$\mathtt{P}_3$$$ performs almost as well as $$$\mathtt{P}_r$$$.
Conclusion
We demonstrated how a learned log-likelihood prior trained from DICOM images can be incorporated into calibration-less parallel imaging reconstruction using nonlinear inversion. There are two advantages of the proposed method: 1) having more access to training data; and 2) being able to apply the same prior for image reconstruction from the k-space aquired with different sampling patterns or with different receive coils.Acknowledgements
We acknowledge funding by the "Niedersächsisches Vorab" funding line of the Volkswagen Foundation.References
[1] Uecker M et al., "Image reconstruction by regularized nonlinear inversion—joint estimation of coil sensitivities and image content." Magnetic Resonance in Medicine 60.3 (2008): 674-682.
[2] Luo G et al., "MRI reconstruction using deep Bayesian estimation." Magnetic Resonance in Medicine 84.4 (2020): 2246-2261.
[3] Beck A et al., "A fast iterative shrinkage-thresholding algorithm for linear inverse problems." SIAM journal on imaging sciences 2.1 (2009): 183-202.
[4] Uecker M et al., BART Toolbox for Computational Magnetic Resonance Imaging, DOI:10.5281/zenodo.592960
Figures